How to create custom Spark pools in Microsoft Fabric
In this document, we explain how to create custom Apache Spark pools in Microsoft Fabric for your analytics workloads. Apache Spark pools enable users to create tailored compute environments based on their specific requirements, ensuring optimal performance and resource utilization.
You specify the minimum and maximum nodes for autoscaling. Based on those values, the system dynamically acquires and retires nodes as the job's compute requirements change, which results in efficient scaling and improved performance. The dynamic allocation of executors in Spark pools also alleviates the need for manual executor configuration. Instead, the system adjusts the number of executors depending on the data volume and job-level compute needs. This process enables you to focus on your workloads without worrying about performance optimization and resource management.
Note
To create a custom Spark pool, you need admin access to the workspace. The capacity admin must enable the Customized workspace pools option in the Spark Compute section of Capacity Admin settings. To learn more, see Spark Compute Settings for Fabric Capacities.
Create custom Spark pools
To create or manage the Spark pool associated with your workspace:
Go to your workspace and select Workspace settings.
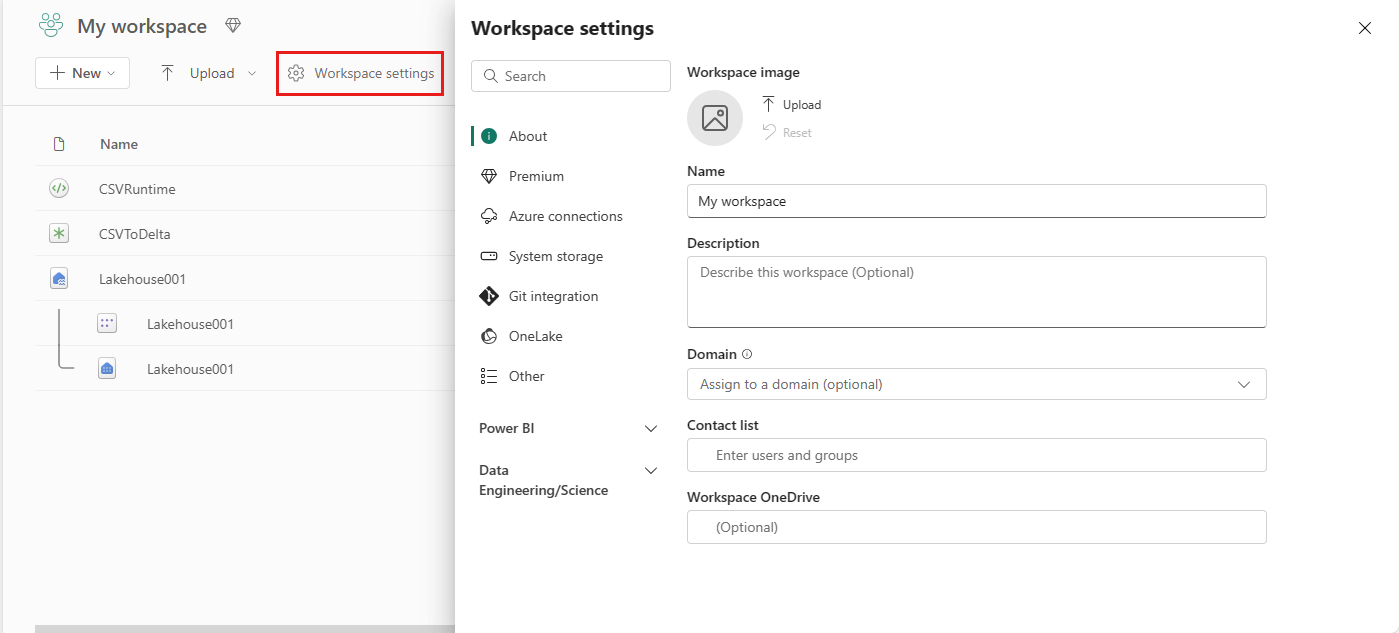
Select the Data Engineering/Science option to expand the menu and then select Spark Compute.
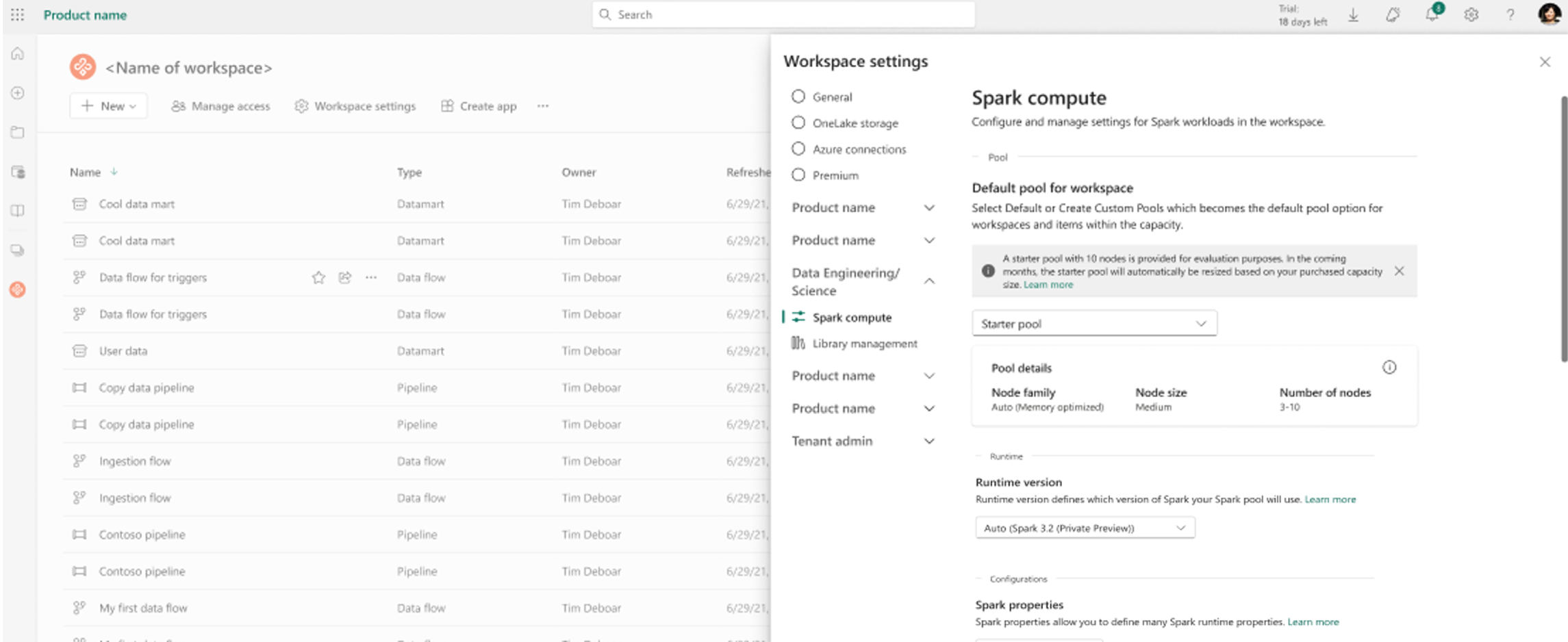
Select the New Pool option. In the Create Pool screen, name your Spark pool. Also choose the Node family, and select a Node size from the available sizes (Small, Medium, Large, X-Large, and XX-Large) based on compute requirements for your workloads.
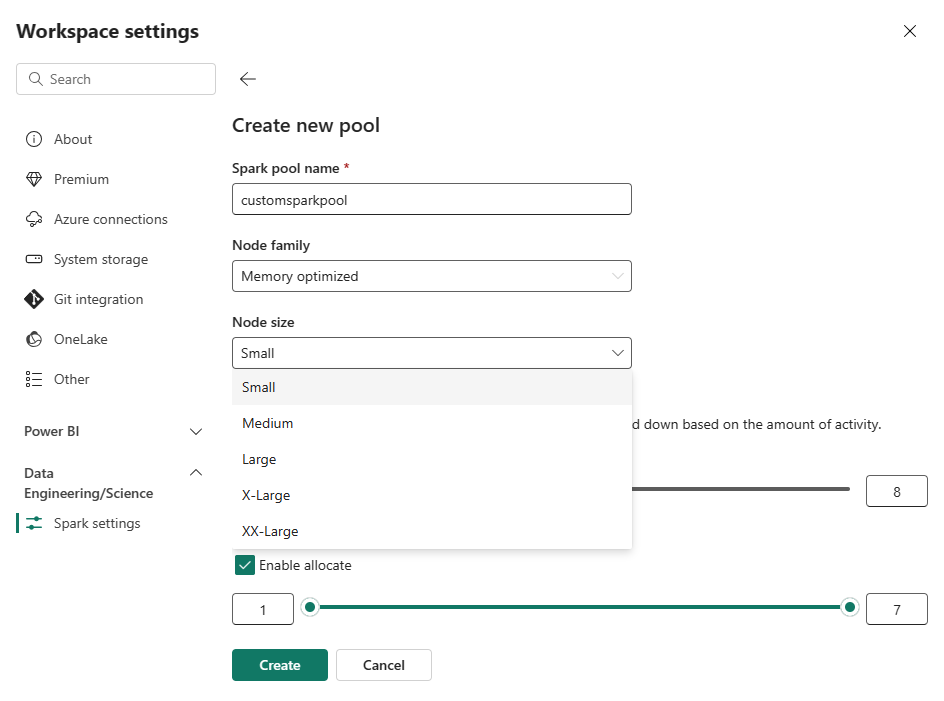
You can set the minimum node configuration for your custom pools to 1. Because Fabric Spark provides restorable availability for clusters with a single node, you don't have to worry about job failures, loss of session during failures, or over paying on compute for smaller Spark jobs.
You can enable or disable autoscaling for your custom Spark pools. When autoscaling is enabled, the pool will dynamically acquire new nodes up to the maximum node limit specified by the user, and then retire them after job execution. This feature ensures better performance by adjusting resources based on the job requirements. You're allowed to size the nodes, which fit within the capacity units purchased as part of the Fabric capacity SKU.
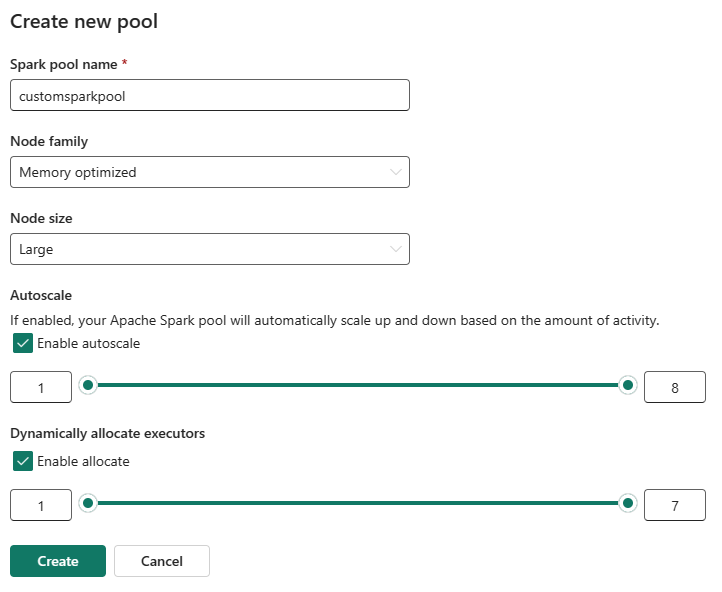
You can also choose to enable dynamic executor allocation for your Spark pool, which automatically determines the optimal number of executors within the user-specified maximum bound. This feature adjusts the number of executors based on data volume, resulting in improved performance and resource utilization.

These custom pools have a default autopause duration of 2 minutes. Once the autopause duration is reached, the session expires and the clusters are unallocated. You're charged based on the number of nodes and the duration for which the custom Spark pools are used.
Related content
- Learn more from the Apache Spark public documentation.
- Get started with Spark workspace administration settings in Microsoft Fabric.
Maklum balas
Akan datang: Sepanjang 2024, kami akan menghentikan secara berperingkat Isu GitHub sebagai kaedah maklum balas untuk kandungan dan menggantikannya dengan sistem maklum balas baharu. Untuk mendapatkan maklumat lanjut lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat maklum balas untuk