Bruk AI Builder-modell i Power Apps
Ved hjelp av Power Fx, åpen kildekode med lavkodeformer, kan du legge til kraftigere og mer fleksible integreringer av modeller for kunstig intelligens i Power App. Prediksjonsformler for modeller for kunstig intelligens kan integreres med alle kontroller i lerretsappen. Du kan for eksempel registrere tekstspråket i en tekstinnskrivingskontroll og sende resultatene til en etikettkontroll, som du kan se i delen Bruk en modell med kontroller nedenfor.
Forutsetninger
Hvis du vil bruke Power Fx i AI Builder-modeller, må du ha:
Tilgang til et Microsoft Power Platform-miljø med en database.
AI Builder-lisens (prøveversjon eller betalt). Gå til AI Builder-lisensiering for å finne ut mer.
Velg en modell i lerretsapper
Hvis du vil bruke en modell for kunstig intelligens med Power Fx, må du opprette en lerretsapp, velge en kontroll og tilordne uttrykk til kontrollegenskaper.
Merk
Hvis du vil se en liste over AI Builder-modeller du kan bruke, kan du se Modeller for kunstig intelligens og forretningsscenarioer. Du kan også konsumere modeller som er innebygd i Microsoft Azure Machine Learning med funksjonen ta med din egen modell.
Opprett en app. Mer informasjon: Opprette en tom lerretsapp fra grunnen av.
Velg Data>Legg til data>AI-modeller.
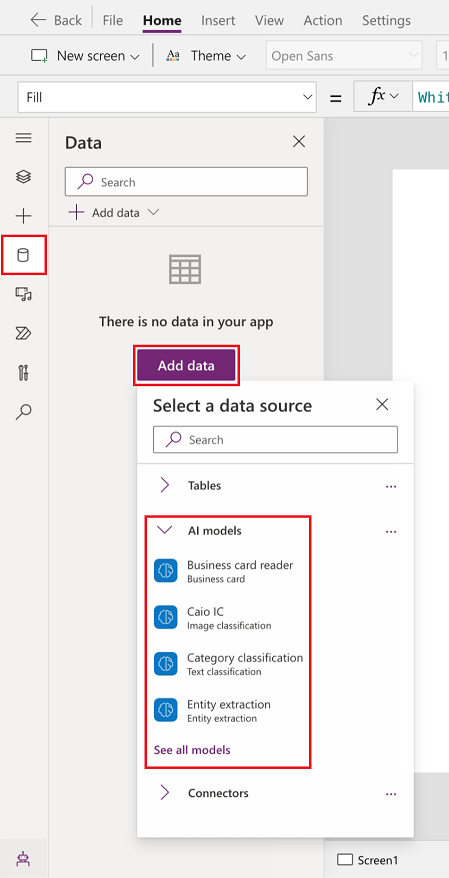
Velge én eller flere modeller å legge til.
Hvis du ikke ser modellen i listen, har du kanskje ikke tillatelse til å bruke den i Power Apps. Kontakt administrator for å løse dette problemet.
Bruke en modell med kontroller
Nå som du har lagt til modellen for kunstig intelligens i lerretsappen, kan du se hvordan du kaller en AI Builder-modell fra en kontroll.
I eksemplet nedenfor skal vi bygge en app som kan registrere språket som er angitt av en bruker i appen.
Opprett en app. Mer informasjon: Opprette en tom lerretsapp fra grunnen av.
Velg Data>Legg til data>AI-modeller.
Søk etter, og velg modellen for kunstig intelligens Språkgjenkjenning.

Merk
Du må manuelt legge til modellen i appen igjen i det nye miljøet når du flytter appen mellom miljøer.
Velg + fra den venstre ruten og velg Tekstinndata-kontrollen.
Gjenta det forrige trinnet for å legge til en Tekstetikett-kontroll.
Endre navnet på tekstetiketten til Språk.
Legg til en ny tekstetikett ved siden av Språk-etiketten.

Velg tekstetiketten som er lagt til i forrige trinn.
Angi følgende formel på formellinjen for tekstetikettens Tekst-egenskap.
'Language detection'.Predict(TextInput1.Text).LanguageEtiketten endres til språkkoden basert på nasjonal innstilling. For dette eksemplet en (engelsk).

Forhåndsvis appen ved å velge Spill av-knappen øverst til høyre på skjermen.

Skriv inn
bonjouri tekstboksen. Legg merke til at språket for fransk (fr) vises under tekstboksen.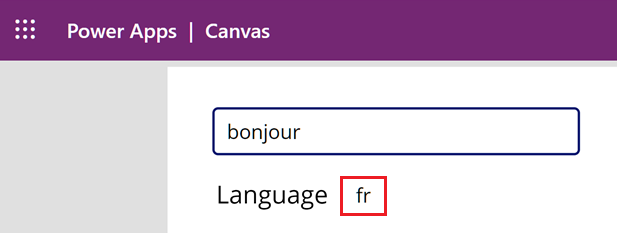
Prøv på samme måte en annen språktekst. Du kan for eksempel angi
guten tag-endringer i det registrerte språket i de for tysk.
Beste fremgangsmåter
Prøv å utløse modellprediksjon fra entallshandlinger, for eksempel OnClick, ved å bruke en knapp i stedet for OnChange-handlingen på en tekstinnskriving for å sikre effektiv bruk av AI Builder-kreditter.
Hvis du vil spare tid og ressurser, lagrer du resultatet av et modellkall, slik at du kan bruke det flere steder. Du kan lagre en utdata i en global variabel. Etter at du har lagret modellresultatet, kan du bruke språket andre steder i appen til å vise det identifiserte språket og konfidenspoengsummen i to forskjellige etiketter.
Set(lang, 'Language detection'.Predict("bonjour").Language)
Inndata og utdata etter modelltype
Denne delen inneholder inndata og utganger for egendefinerte og forhåndsbygde modeller etter modelltype.
Egendefinerte modeller
| Modelltype | Syntaks | Utdata |
|---|---|---|
| Kategoriklassifisering | 'Custom text classification model name'.Predict(Text: String, Language?: Optional String) |
{AllClasses: {Name: String, Confidence: Number}[],TopClass: {Name: String,Confidence: Number}} |
| Enhetsuttrekking | 'Custom entity extraction model name’.Predict(Text: String,Language?:String(Optional)) |
{Entities:[{Type: "name",Value: "Bill", StartIndex: 22, Length: 4, Confidence: .996, }, { Type: "name", Value: "Gwen", StartIndex: 6, Length: 4, Confidence: .821, }]} |
| Objektgjenkjenning | 'Custom object detection model name'.Predict(Image: Image) |
{ Objects: { Name: String, Confidence: Number, BoundingBox: { Left: Number, Top: Number, Width: Number, Height: Number }}[]} |
Forhåndsbygde modeller
Merk
Forhåndsbygde modellnavn vises i miljøets nasjonale innstilling. Eksemplene nedenfor viser modellnavnene for engelsk (en).
| Modelltype | Syntaks | Utdata |
|---|---|---|
| Visittkortleser | ‘Business card reader’.Predict( Document: Base64 encoded image ) |
{ Fields: { FieldName: { FieldType: "text", Value: { Text: String, BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number }}}}} |
| Kategoriklassifisering | 'Category classification'.Predict( Text: String,Language?: Optional String, ) |
{ AllClasses: { Name: String, Confidence: Number }[], TopClass: { Name: String, Confidence: Number }} |
| Identitetsdokumentleser | ‘Identity document reader’.Predict( Document: Base64 encoded image ) |
{ Context: { Type: String, TypeConfidence: Number }, Fields: { FieldName: { FieldType: "text", Confidence: Number, Value: { Text: String, BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number }}}}} |
| Fakturabehandling | ‘Invoice processing’.Predict( Document: Base64 encoded image ) |
{ Fields: { FieldName: { FieldType: "text" | "date" | "number", Confidence: Number,Value: { Text: String, [Date: Date] | [Number: Number], BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number } } } }, Tables: { Items: { Rows: { FieldName: { FieldType: "text" | "date" | "number", Confidence: Number, Key: { Name: String, }, Value: { Text: String, [Date: Date] | [Number: Number], BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number } } } }[] } }} |
| Uttrekking av nøkkeluttrykk | 'Key phrase extraction'.Predict(Text: String, Language?: Optional String)) |
{ Phrases: String[]} |
| Språkregistrering | 'Language Detection'.Predict(Text: String) |
{ Language: String, Confidence: Number} |
| Behandling av kvitteringer | ‘Receipt processing’.Predict( Document: Base64 encoded image) |
{ Context: { Type: String, TypeConfidence: Number }, Fields: { FieldName: { FieldType: "text" | "date" | "number", Confidence: Number, Value: { Text: String, [Date: Date] | [Number: Number], BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number } } } }, Tables: {Items: {Rows: {FieldName: { FieldType: "text" | "date" | "number", Confidence: Number, Key: { Name: String, }, Value: { Text: String, [Date: Date] | [Number: Number], BoundingBox: { Top: Number, Left: Number, Height: Number, Width: Number } } } }[] } } } |
| Sentimentanalyse | 'Sentiment analysis'.Predict( Text: String, Language?: Optional String ) |
{ Document: { AllSentiments: [ { Name: "Positive", Confidence: Number }, { Name: "Neutral", Confidence: Number }, { Name: "Negative", Confidence: Number } ], TopSentiment: { Name: "Positive" | "Neutral" | "Negative", Confidence: Number } } Sentences: { StartIndex: Number, Length: Number, AllSentiments: [ { Name: "Positive", Confidence: Number }, { Name: "Neutral", Confidence: Number }, { Name: "Negative", Confidence: Number } ], TopSentiment: { Name: "Positive" | "Neutral" | "Negative", Confidence: Number } }[]} |
| Tekstgjenkjenning | 'Text recognition'.Predict( Document: Base64 encoded image) |
{Pages: {Page: Number,Lines: { Text: String, BoundingBox: { Left: Number, Top: Number, Width: Number, Height: Number }, Confidence: Number }[] }[]} |
| Tekstoversettelse | 'Text translation'.Predict( Text: String, TranslateTo?: String, TranslateFrom?: String) |
{ Text: String, // Translated text DetectedLanguage?: String, DetectedLanguageConfidence: Number} } |
Eksempler
Hver modell startes ved hjelp av prediksjonsverbet. En språkgjenkjenningsmodell tar for eksempel tekst som inndata og returnerer en tabell over mulige språk, sortert etter dette språkets poengsum. Poengsummen indikerer hvor trygg modellen er med prediksjonen.
| Inndata | Utdata |
|---|---|
'Language detection'.Predict("bonjour") |
{ Language: “fr”, Confidence: 1} |
‘Text Recognition’.Predict(Image1.Image) |
{ Pages: [ {Page: 1, Lines: [ { Text: "Contoso account", BoundingBox: { Left: .15, Top: .05, Width: .8, Height: .10 }, Confidence: .97 }, { Text: "Premium service", BoundingBox: { Left: .15, Top: .20, Width: .8, Height: .10 }, Confidence: .96 }, { Text: "Paid in full", BoundingBox: { Left: .15, Top: .35, Width: .8, Height: .10 }, Confidence: .99 } } ] } |