Data wrangling with Apache Spark pools (deprecated)
APPLIES TO:  Python SDK azureml v1
Python SDK azureml v1
Warning
The Azure Synapse Analytics integration with Azure Machine Learning, available in Python SDK v1, is deprecated. Users can still use Synapse workspace, registered with Azure Machine Learning, as a linked service. However, a new Synapse workspace can no longer be registered with Azure Machine Learning as a linked service. We recommend use of serverless Spark compute and attached Synapse Spark pools, available in CLI v2 and Python SDK v2. For more information, visit https://aka.ms/aml-spark.
In this article, you learn how to interactively perform data wrangling tasks within a dedicated Synapse session, powered by Azure Synapse Analytics, in a Jupyter notebook. These tasks rely on the Azure Machine Learning Python SDK. For more information about Azure Machine Learning pipelines, visit How to use Apache Spark (powered by Azure Synapse Analytics) in your machine learning pipeline (preview). For more information about how to use Azure Synapse Analytics with a Synapse workspace, visit the Azure Synapse Analytics get started series.
Azure Machine Learning and Azure Synapse Analytics integration
With the Azure Synapse Analytics integration with Azure Machine Learning (preview), you can attach an Apache Spark pool, backed by Azure Synapse, for interactive data exploration and preparation. With this integration, you can have a dedicated compute resource for data wrangling at scale, all within the same Python notebook you use to train your machine learning models.
Prerequisites
Configure your development environment to install the Azure Machine Learning SDK, or use an Azure Machine Learning compute instance with the SDK already installed
Install the Azure Machine Learning Python SDK
Create an Apache Spark pool using Azure portal, web tools, or Synapse Studio
Install the
azureml-synapsepackage (preview) with this code:pip install azureml-synapseLink your Azure Machine Learning workspace and Azure Synapse Analytics workspace with the Azure Machine Learning Python SDK or with the Azure Machine Learning studio
Attach a Synapse Spark pool as a compute target
Launch Synapse Spark pool for data wrangling tasks
To start the data preparation with the Apache Spark pool, specify the attached Spark Synapse compute name. You can find this name with the Azure Machine Learning studio under the Attached computes tab.
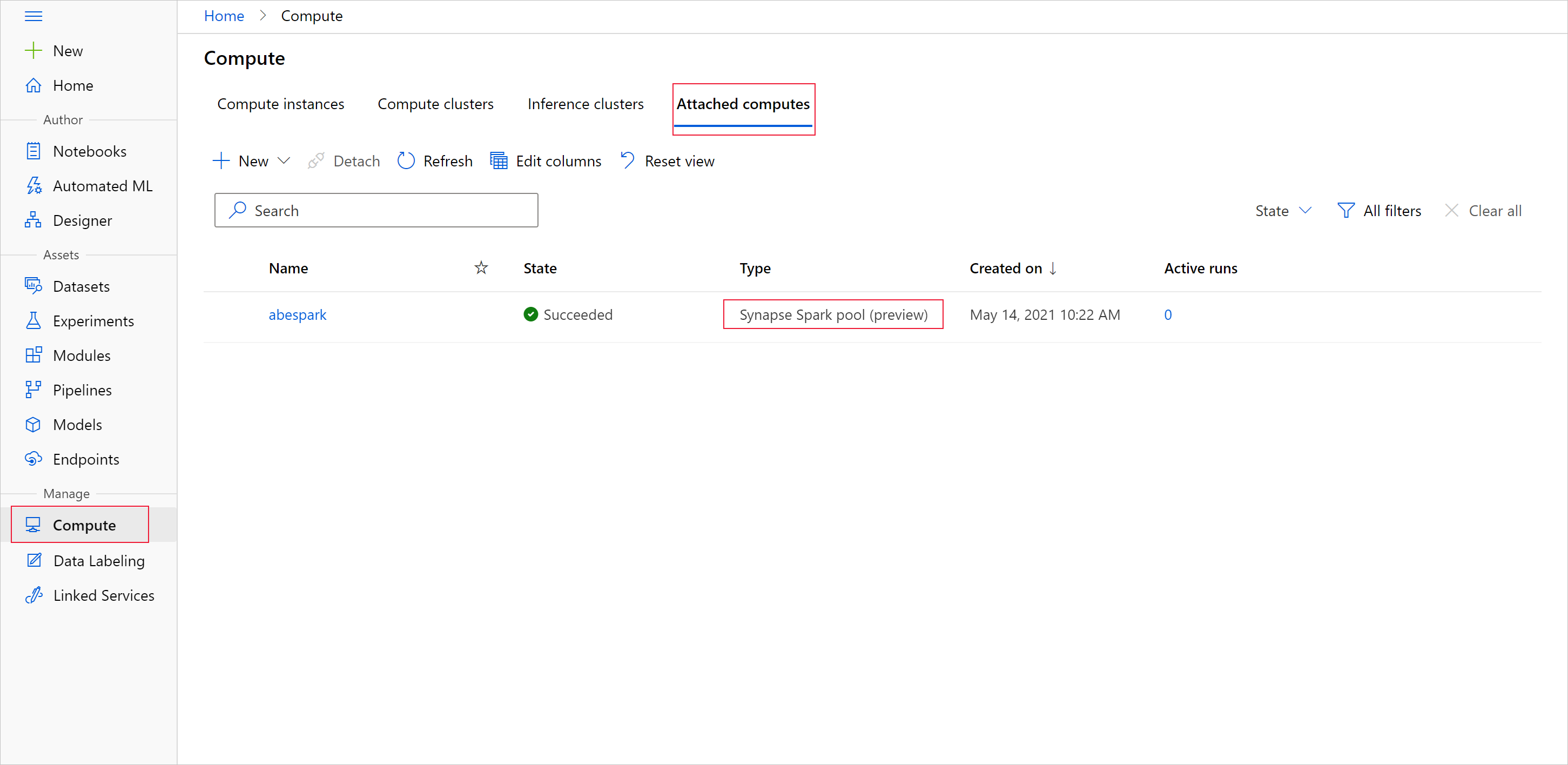
Important
To continue use of Apache Spark pool, you must indicate which compute resource to use throughout your data wrangling tasks. Use %synapse for single lines of code, and %%synapse for multiple lines:
%synapse start -c SynapseSparkPoolAlias
After the session starts, you can check the session's metadata:
%synapse meta
You can specify an Azure Machine Learning environment to use during your Apache Spark session. Only Conda dependencies specified in the environment will take effect. Docker images aren't supported.
Warning
Python dependencies specified in environment Conda dependencies are not supported in Apache Spark pools. Currently, only fixed Python versions are supported
Include sys.version_info in your script to check your Python version
This code creates themyenv environment variable, to install azureml-core version 1.20.0 and numpy version 1.17.0 before the session starts. You can then include this environment in your Apache Spark session start statement.
from azureml.core import Workspace, Environment
# creates environment with numpy and azureml-core dependencies
ws = Workspace.from_config()
env = Environment(name="myenv")
env.python.conda_dependencies.add_pip_package("azureml-core==1.20.0")
env.python.conda_dependencies.add_conda_package("numpy==1.17.0")
env.register(workspace=ws)
To start data preparation with the Apache Spark pool in your custom environment, specify both the Apache Spark pool name and the environment to use during the Apache Spark session. You can provide your subscription ID, the machine learning workspace resource group, and the name of the machine learning workspace.
%synapse start -c SynapseSparkPoolAlias -e myenv -s AzureMLworkspaceSubscriptionID -r AzureMLworkspaceResourceGroupName -w AzureMLworkspaceName
Load data from storage
After the Apache Spark session starts, read in the data that you wish to prepare. Data loading is supported for Azure Blob storage and Azure Data Lake Storage Generations 1 and 2.
You have two options to load data from these storage services:
Directly load data from storage with its Hadoop Distributed Files System (HDFS) path
Read in data from an existing Azure Machine Learning dataset
To access these storage services, you need Storage Blob Data Reader permissions. To write data back to these storage services, you need Storage Blob Data Contributor permissions. Learn more about storage permissions and roles.
Load data with Hadoop Distributed Files System (HDFS) path
To load and read data from storage with the corresponding HDFS path, you need your data access authentication credentials available. These credentials differ depending on your storage type. This code sample shows how to read data from an Azure Blob storage into a Spark dataframe with either your shared access signature (SAS) token or access key:
%%synapse
# setup access key or SAS token
sc._jsc.hadoopConfiguration().set("fs.azure.account.key.<storage account name>.blob.core.windows.net", "<access key>")
sc._jsc.hadoopConfiguration().set("fs.azure.sas.<container name>.<storage account name>.blob.core.windows.net", "<sas token>")
# read from blob
df = spark.read.option("header", "true").csv("wasbs://demo@dprepdata.blob.core.windows.net/Titanic.csv")
This code sample shows how to read data from Azure Data Lake Storage Generation 1 (ADLS Gen 1) with your service principal credentials:
%%synapse
# setup service principal which has access of the data
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.access.token.provider.type","ClientCredential")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.client.id", "<client id>")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.credential", "<client secret>")
sc._jsc.hadoopConfiguration().set("fs.adl.account.<storage account name>.oauth2.refresh.url",
"https://login.microsoftonline.com/<tenant id>/oauth2/token")
df = spark.read.csv("adl://<storage account name>.azuredatalakestore.net/<path>")
This code sample shows how to read data in from Azure Data Lake Storage Generation 2 (ADLS Gen 2) with your service principal credentials:
%%synapse
# setup service principal which has access of the data
sc._jsc.hadoopConfiguration().set("fs.azure.account.auth.type.<storage account name>.dfs.core.windows.net","OAuth")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth.provider.type.<storage account name>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.id.<storage account name>.dfs.core.windows.net", "<client id>")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.secret.<storage account name>.dfs.core.windows.net", "<client secret>")
sc._jsc.hadoopConfiguration().set("fs.azure.account.oauth2.client.endpoint.<storage account name>.dfs.core.windows.net",
"https://login.microsoftonline.com/<tenant id>/oauth2/token")
df = spark.read.csv("abfss://<container name>@<storage account>.dfs.core.windows.net/<path>")
Read in data from registered datasets
You can also place an existing registered dataset in your workspace, and perform data preparation on it, if you convert it into a spark dataframe. This example authenticates to the workspace, obtains a registered TabularDataset -blob_dset - that references files in blob storage, and converts that TabularDataset to a Spark dataframe. When you convert your datasets to Spark dataframeS, you can use pyspark data exploration and preparation libraries.
%%synapse
from azureml.core import Workspace, Dataset
subscription_id = "<enter your subscription ID>"
resource_group = "<enter your resource group>"
workspace_name = "<enter your workspace name>"
ws = Workspace(workspace_name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group)
dset = Dataset.get_by_name(ws, "blob_dset")
spark_df = dset.to_spark_dataframe()
Perform data wrangling tasks
After you retrieve and explore your data, you can perform data wrangling tasks. This code sample expands upon the HDFS example in the previous section. Based on the Survivor column, it filters the data in spark dataframe df and groups that list by Age:
%%synapse
from pyspark.sql.functions import col, desc
df.filter(col('Survived') == 1).groupBy('Age').count().orderBy(desc('count')).show(10)
df.show()
Save data to storage and stop spark session
Once your data exploration and preparation is complete, store your prepared data for later use in your storage account on Azure. In this code sample, the prepared data is written back to Azure Blob storage, overwriting the original Titanic.csv file in the training_data directory. To write back to storage, you need Storage Blob Data Contributor permissions. For more information, visit Assign an Azure role for access to blob data.
%% synapse
df.write.format("csv").mode("overwrite").save("wasbs://demo@dprepdata.blob.core.windows.net/training_data/Titanic.csv")
After you complete the data preparation, and you save your prepared data to storage, end the use of your Apache Spark pool with this command:
%synapse stop
Create a dataset, to represent prepared data
When you're ready to consume your prepared data for model training, connect to your storage with an Azure Machine Learning datastore, and specify the file or file you want to use with an Azure Machine Learning dataset.
This code example
- Assumes you already created a datastore that connects to the storage service where you saved your prepared data
- Retrieves that existing datastore -
mydatastore- from workspacewswith the get() method. - Creates a FileDataset,
train_ds, to reference the prepared data files located in themydatastoretraining_datadirectory - Creates variable
input1. At a later time, this variable can make the data files of thetrain_dsdataset available to a compute target for your training tasks.
from azureml.core import Datastore, Dataset
datastore = Datastore.get(ws, datastore_name='mydatastore')
datastore_paths = [(datastore, '/training_data/')]
train_ds = Dataset.File.from_files(path=datastore_paths, validate=True)
input1 = train_ds.as_mount()
Use a ScriptRunConfig to submit an experiment run to a Synapse Spark pool
If you're ready to automate and productionize your data wrangling tasks, you can submit an experiment run to an attached Synapse Spark pool with the ScriptRunConfig object. In a similar way, if you have an Azure Machine Learning pipeline, you can use the SynapseSparkStep to specify your Synapse Spark pool as the compute target for the data preparation step in your pipeline. Availability of your data to the Synapse Spark pool depends on your dataset type.
- For a FileDataset, you can use the
as_hdfs()method. When the run is submitted, the dataset is made available to the Synapse Spark pool as a Hadoop distributed file system (HFDS) - For a TabularDataset, you can use the
as_named_input()method
The following code sample
- Creates variable
input2from the FileDatasettrain_ds, itself created in the previous code example - Creates variable
outputwith theHDFSOutputDatasetConfigurationclass. After the run is complete, this class allows us to save the output of the run as the dataset,testin themydatastoredatastore. In the Azure Machine Learning workspace, thetestdataset is registered under the nameregistered_dataset - Configures settings the run should use to perform on the Synapse Spark pool
- Defines the ScriptRunConfig parameters to
- Use the
dataprep.pyscript for the run - Specify the data to use as input, and how to make that data available to the Synapse Spark pool
- Specify where to store the
outputoutput data
- Use the
from azureml.core import Dataset, HDFSOutputDatasetConfig
from azureml.core.environment import CondaDependencies
from azureml.core import RunConfiguration
from azureml.core import ScriptRunConfig
from azureml.core import Experiment
input2 = train_ds.as_hdfs()
output = HDFSOutputDatasetConfig(destination=(datastore, "test").register_on_complete(name="registered_dataset")
run_config = RunConfiguration(framework="pyspark")
run_config.target = synapse_compute_name
run_config.spark.configuration["spark.driver.memory"] = "1g"
run_config.spark.configuration["spark.driver.cores"] = 2
run_config.spark.configuration["spark.executor.memory"] = "1g"
run_config.spark.configuration["spark.executor.cores"] = 1
run_config.spark.configuration["spark.executor.instances"] = 1
conda_dep = CondaDependencies()
conda_dep.add_pip_package("azureml-core==1.20.0")
run_config.environment.python.conda_dependencies = conda_dep
script_run_config = ScriptRunConfig(source_directory = './code',
script= 'dataprep.py',
arguments = ["--file_input", input2,
"--output_dir", output],
run_config = run_config)
For more information about run_config.spark.configuration and general Spark configuration, visit SparkConfiguration Class and Apache Spark's configuration documentation.
Once you set up your ScriptRunConfig object, you can submit the run.
from azureml.core import Experiment
exp = Experiment(workspace=ws, name="synapse-spark")
run = exp.submit(config=script_run_config)
run
For more information, including information about the dataprep.py script used in this example, see the example notebook.
After you prepare your data, you can use it as input for your training jobs. In the code example above, you would specify the registered_dataset as your input data for training jobs.
Example notebooks
Review these example notebooks for more concepts and demonstrations of the Azure Synapse Analytics and Azure Machine Learning integration capabilities:
- Run an interactive Spark session from a notebook in your Azure Machine Learning workspace.
- Submit an Azure Machine Learning experiment run with a Synapse Spark pool as your compute target.