Slik oppretter du egendefinerte Spark-bassenger i Microsoft Fabric
I dette dokumentet forklarer vi hvordan du oppretter egendefinerte Apache Spark-bassenger i Microsoft Fabric for analysearbeidsbelastningene dine. Apache Spark-bassenger gjør det mulig for brukere å opprette skreddersydde databehandlingsmiljøer basert på deres spesifikke krav, noe som sikrer optimal ytelse og ressursutnyttelse.
Du angir minimums- og maksimumsnodene for autoskalering. Basert på disse verdiene henter og trekker systemet dynamisk tilbake noder etter hvert som jobbens beregningskrav endres, noe som resulterer i effektiv skalering og forbedret ytelse. Den dynamiske tildelingen av eksekutorer i Spark-bassenger lindrer også behovet for manuell executor-konfigurasjon. I stedet justerer systemet antallet eksekutorer avhengig av datavolumet og databehandlingsbehovene på jobbnivå. Denne prosessen gjør det mulig å fokusere på arbeidsbelastningene dine uten å bekymre deg for ytelsesoptimalisering og ressursadministrasjon.
Merk
Hvis du vil opprette et egendefinert Spark-utvalg, trenger du administratortilgang til arbeidsområdet. Kapasitetsadministratoren må aktivere alternativet Egendefinerte arbeidsområdeutvalg i Spark Compute-delen av innstillingene for kapasitetsadministrator. Hvis du vil ha mer informasjon, kan du se Spark Compute Innstillinger for Fabric Capacities.
Opprette egendefinerte Spark-bassenger
Slik oppretter eller administrerer du Spark-utvalget som er knyttet til arbeidsområdet:
Gå til arbeidsområdet, og velg innstillinger for arbeidsområde.
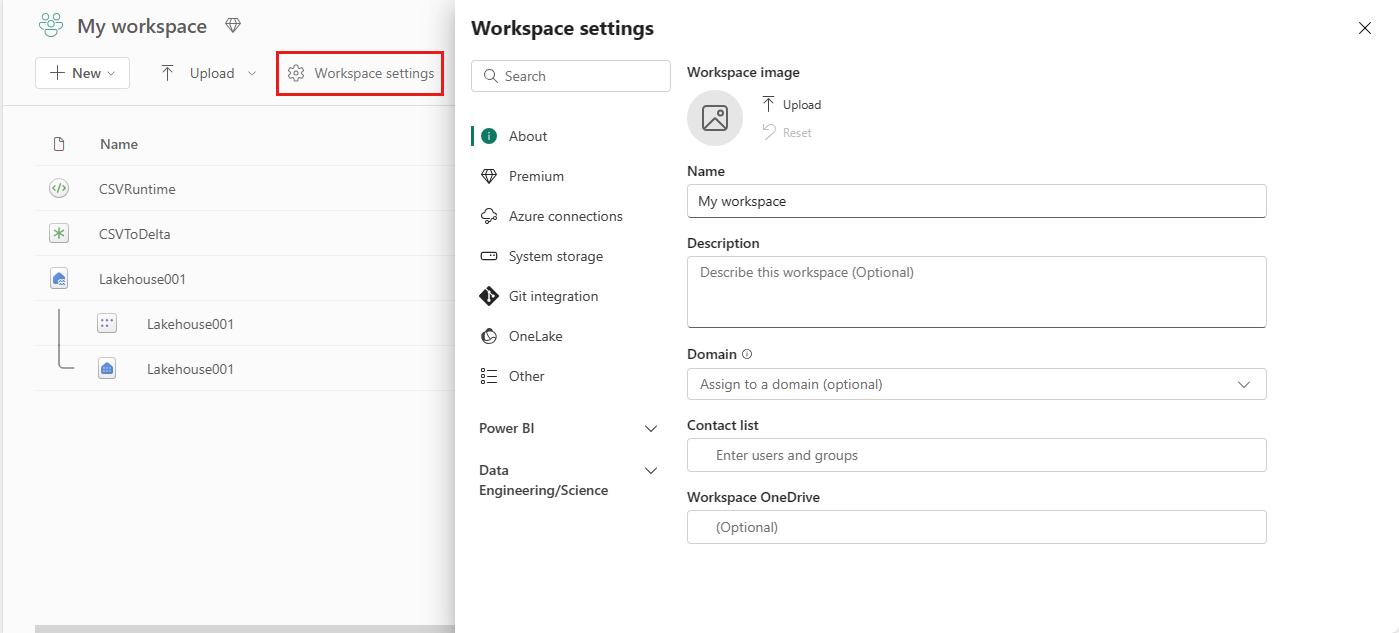
Velg alternativet Dataingeniør ing/vitenskap for å utvide menyen, og velg deretter Spark Compute.

Velg alternativet Nytt utvalg . Gi spark-utvalget et navn i skjermbildet Opprett utvalg. Velg også Node-familien, og velg en nodestørrelse fra de tilgjengelige størrelsene (Liten, Middels, Stor, X-Stor og XX-Large) basert på beregningskrav for arbeidsbelastningene dine.
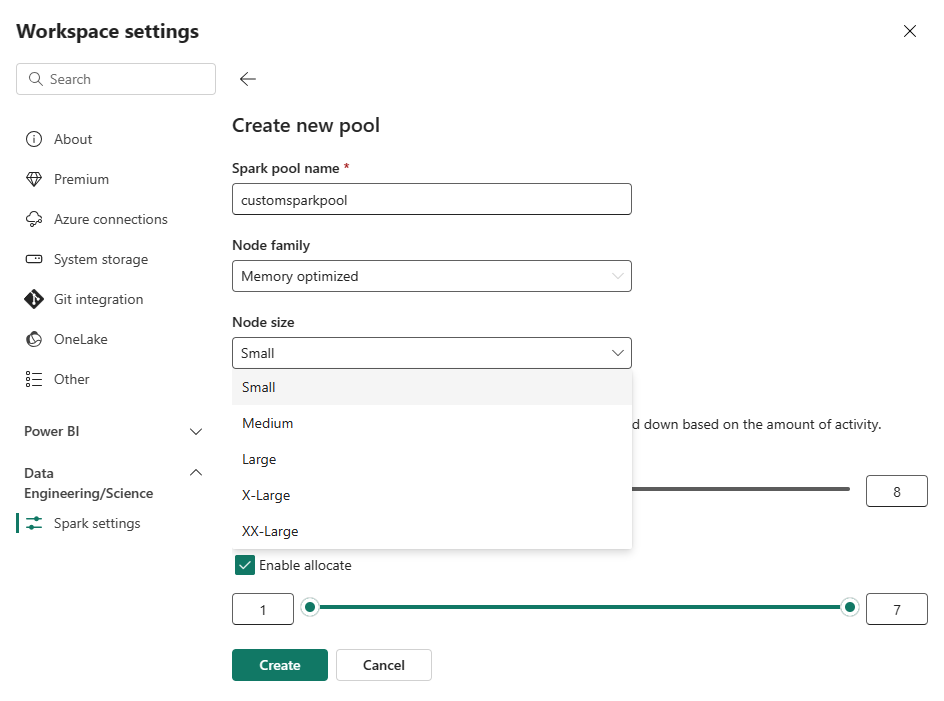
Du kan angi minimum nodekonfigurasjonen for de egendefinerte utvalgene til 1. Fordi Fabric Spark gir gjenopprettelig tilgjengelighet for klynger med én enkelt node, trenger du ikke å bekymre deg for jobbfeil, tap av økt under feil eller over betaling på databehandling for mindre Spark-jobber.
Du kan aktivere eller deaktivere autoskalering for egendefinerte Spark-bassenger. Når autoskalering er aktivert, henter utvalget dynamisk nye noder opp til den maksimale nodegrensen som er angitt av brukeren, og trekker dem deretter tilbake etter jobbkjøring. Denne funksjonen sikrer bedre ytelse ved å justere ressurser basert på jobbkravene. Du har tillatelse til å endre størrelsen på nodene, som passer inn i kapasitetsenhetene som er kjøpt som en del av SKU-en for stoffkapasitet.
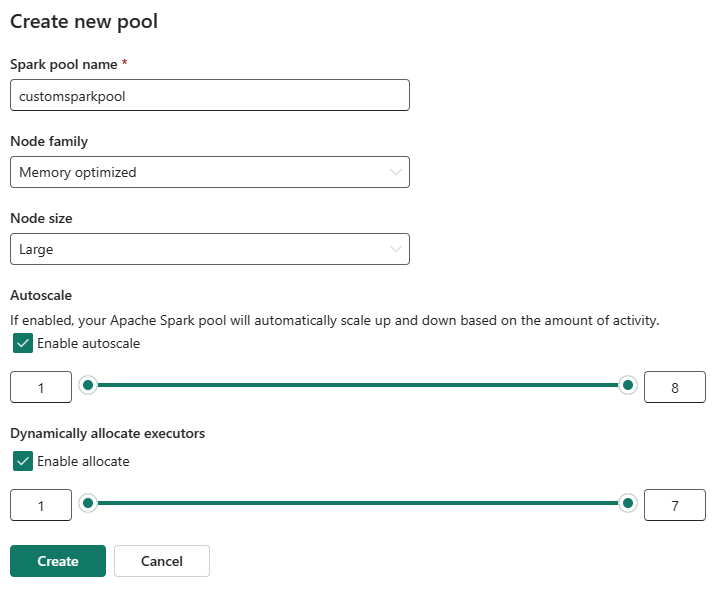
Du kan også velge å aktivere dynamisk eksekutortildeling for Spark-utvalget, som automatisk bestemmer det optimale antallet eksekutorer innenfor den brukerangitte maksimumsgrensen. Denne funksjonen justerer antallet eksekutorer basert på datavolum, noe som resulterer i forbedret ytelse og ressursutnyttelse.

Disse egendefinerte utvalgene har en standard autopausevarighet på 2 minutter. Når autopausevarigheten er nådd, utløper økten, og klyngene er ikke allokert. Du belastes basert på antall noder og varigheten som de egendefinerte Spark-bassengene brukes for.
Relatert innhold
- Mer informasjon fra den offentlige Apache Spark-dokumentasjonen.
- Kom i gang med administrasjonsinnstillingene for Spark-arbeidsområdet i Microsoft Fabric.
Tilbakemeldinger
Kommer snart: Gjennom 2024 faser vi ut GitHub Issues som tilbakemeldingsmekanisme for innhold, og erstatter det med et nytt system for tilbakemeldinger. Hvis du vil ha mer informasjon, kan du se: https://aka.ms/ContentUserFeedback.
Send inn og vis tilbakemelding for