Slik oppretter du en Apache Spark-jobbdefinisjon i Fabric
I denne opplæringen kan du lære hvordan du oppretter en Spark-jobbdefinisjon i Microsoft Fabric.
Forutsetning
Før du kommer i gang, trenger du:
- En Fabric-leierkonto med et aktivt abonnement. Opprett en konto gratis.
Tips
Hvis du vil kjøre spark-jobbdefinisjonselementet, må du ha en hoveddefinisjonsfil og standard lakehouse-kontekst. Hvis du ikke har et lakehouse, kan du opprette en ved å følge trinnene i Create a lakehouse.
Opprett en Spark-jobbdefinisjon
Opprettingsprosessen for Spark-jobbdefinisjon er rask og enkel. det finnes flere måter å komme i gang på.
Alternativer for å opprette en Spark-jobbdefinisjon
Det finnes noen måter du kan komme i gang med opprettingsprosessen på:
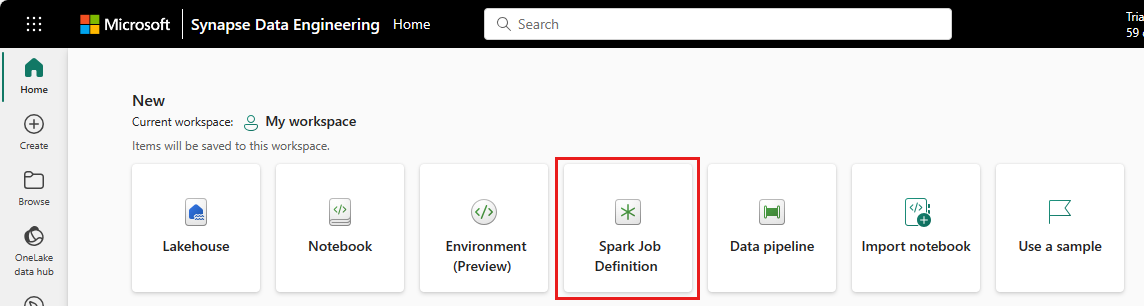
Hjemmeside for datateknikk: Du kan enkelt opprette en Spark-jobbdefinisjon via Spark Job Definition-kortet under Ny-delen på hjemmesiden.
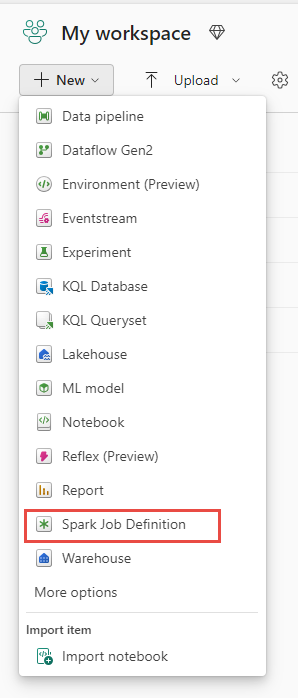
Arbeidsområdevisning: Du kan også opprette en Spark-jobbdefinisjon via arbeidsområdet i Dataingeniør ved hjelp av ny rullegardinmeny.
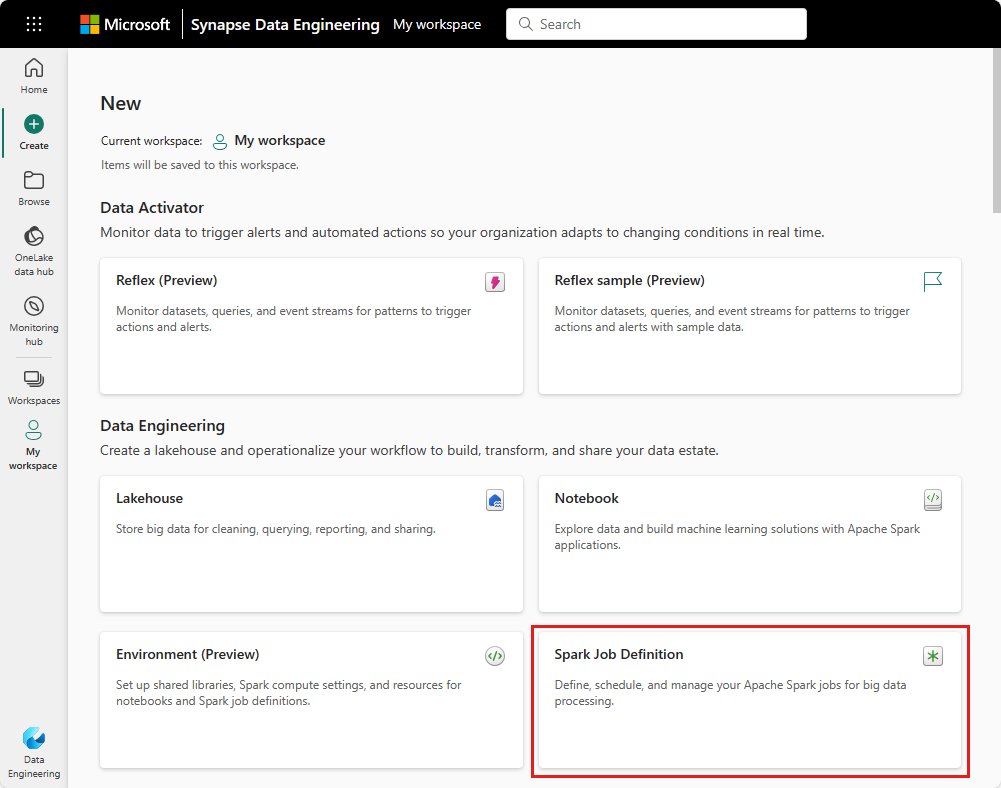
Opprett visning: Et annet inngangspunkt for å opprette en Spark-jobbdefinisjon er Opprett-siden under Dataingeniør ing.
Du må gi Spark-jobbdefinisjonen et navn når du oppretter den. Navnet må være unikt i gjeldende arbeidsområde. Den nye Spark-jobbdefinisjonen opprettes i gjeldende arbeidsområde.
Opprett en Spark-jobbdefinisjon for PySpark (Python)
Slik oppretter du en Spark-jobbdefinisjon for PySpark:
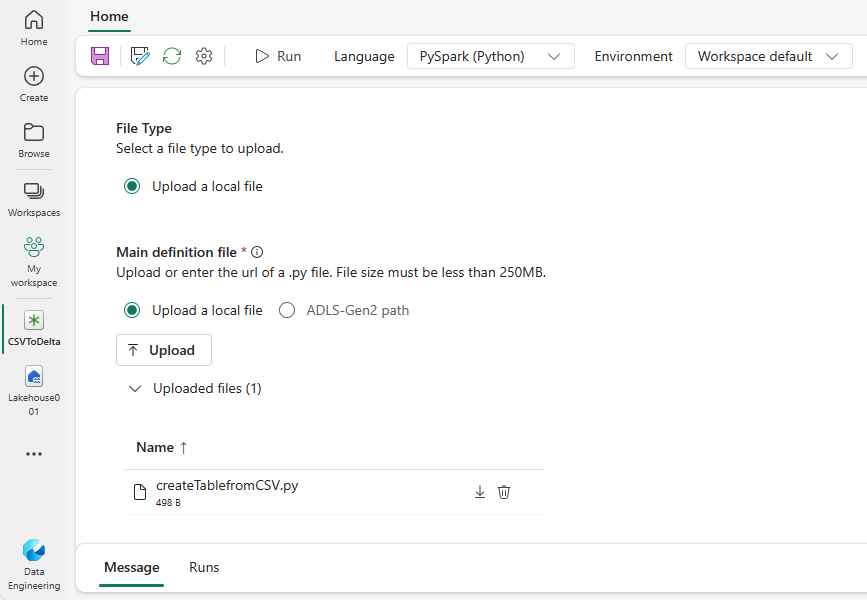
Last ned eksempelparquetfilen yellow_tripdata_2022-01.parquet , og last den opp til fildelen av lakehouse.
Opprett en ny Spark-jobbdefinisjon.
Velg PySpark (Python) fra rullegardinlisten Språk .
Last ned createTablefromParquet.py eksempelet, og last det opp som hoveddefinisjonsfil. Hoveddefinisjonsfilen (jobb. Main) er filen som inneholder programlogikken og er obligatorisk for å kjøre en Spark-jobb. For hver Spark-jobbdefinisjon kan du bare laste opp én hoveddefinisjonsfil.
Du kan laste opp hoveddefinisjonsfilen fra det lokale skrivebordet, eller du kan laste opp fra en eksisterende Azure Data Lake Storage (ADLS) Gen2 ved å oppgi hele ABFSS-banen til filen. Eksempel:
abfss://your-storage-account-name.dfs.core.windows.net/your-file-path.Last opp referansefiler som .py filer. Referansefilene er python-modulene som importeres av hoveddefinisjonsfilen. Akkurat som hoveddefinisjonsfilen, kan du laste opp fra skrivebordet eller en eksisterende ADLS Gen2. Flere referansefiler støttes.
Tips
Hvis du bruker en ADLS Gen2-bane, må du gi brukerkontoen som kjører jobben riktig tillatelse til lagringskontoen, for å sikre at filen er tilgjengelig. Vi foreslår to forskjellige måter å gjøre dette på:
- Tilordne brukerkontoen en bidragsyterrolle for lagringskontoen.
- Gi lese- og kjøringstillatelse til brukerkontoen for filen via ADLS Gen2 Access Control List (ACL).
For en manuell kjøring brukes kontoen til gjeldende påloggingsbruker til å kjøre jobben.
Angi kommandolinjeargumenter for jobben om nødvendig. Bruk et mellomrom som deling for å skille argumentene.
Legg til lakehouse-referansen i jobben. Du må ha minst én lakehouse referanse lagt til jobben. Dette lakehouse er standard lakehouse kontekst for jobben.
Flere lakehouse-referanser støttes. Finn navnet på lakehouse som ikke er standard, og fullstendig NETTADRESSE for OneLake på Siden Spark-innstillinger .
Opprett en Spark-jobbdefinisjon for Scala/Java
Slik oppretter du en Spark-jobbdefinisjon for Scala/Java:
Opprett en ny Spark-jobbdefinisjon.
Velg Spark(Scala/Java) fra rullegardinlisten Språk .
Last opp hoveddefinisjonsfilen som en .jar fil. Hoveddefinisjonsfilen er filen som inneholder programlogikken i denne jobben, og er obligatorisk for å kjøre en Spark-jobb. For hver Spark-jobbdefinisjon kan du bare laste opp én hoveddefinisjonsfil. Angi hovedklassenavnet.
Last opp referansefiler som .jar filer. Referansefilene er filene som refereres til/importeres av hoveddefinisjonsfilen.
Angi kommandolinjeargumenter for jobben om nødvendig.
Legg til lakehouse-referansen i jobben. Du må ha minst én lakehouse referanse lagt til jobben. Dette lakehouse er standard lakehouse kontekst for jobben.
Opprett en Spark-jobbdefinisjon for R
Slik oppretter du en Spark-jobbdefinisjon for SparkR(R):
Opprett en ny Spark-jobbdefinisjon.
Velg SparkR(R) fra rullegardinlisten Språk .
Last opp hoveddefinisjonsfilen som en . R-fil . Hoveddefinisjonsfilen er filen som inneholder programlogikken i denne jobben, og er obligatorisk for å kjøre en Spark-jobb. For hver Spark-jobbdefinisjon kan du bare laste opp én hoveddefinisjonsfil.
Last opp referansefiler som . R-filer . Referansefilene er filene som refereres til/importeres av hoveddefinisjonsfilen.
Angi kommandolinjeargumenter for jobben om nødvendig.
Legg til lakehouse-referansen i jobben. Du må ha minst én lakehouse referanse lagt til jobben. Dette lakehouse er standard lakehouse kontekst for jobben.
Merk
Spark-jobbdefinisjonen opprettes i gjeldende arbeidsområde.
Alternativer for å tilpasse Spark-jobbdefinisjoner
Det finnes noen alternativer for å tilpasse kjøringen av Spark-jobbdefinisjoner ytterligere.
- Spark Compute: I Spark Compute-fanen kan du se Runtime-versjonen som er versjonen av Spark som skal brukes til å kjøre jobben. Du kan også se konfigurasjonsinnstillingene for Spark som skal brukes til å kjøre jobben. Du kan tilpasse konfigurasjonsinnstillingene for Spark ved å klikke legg til-knappen .
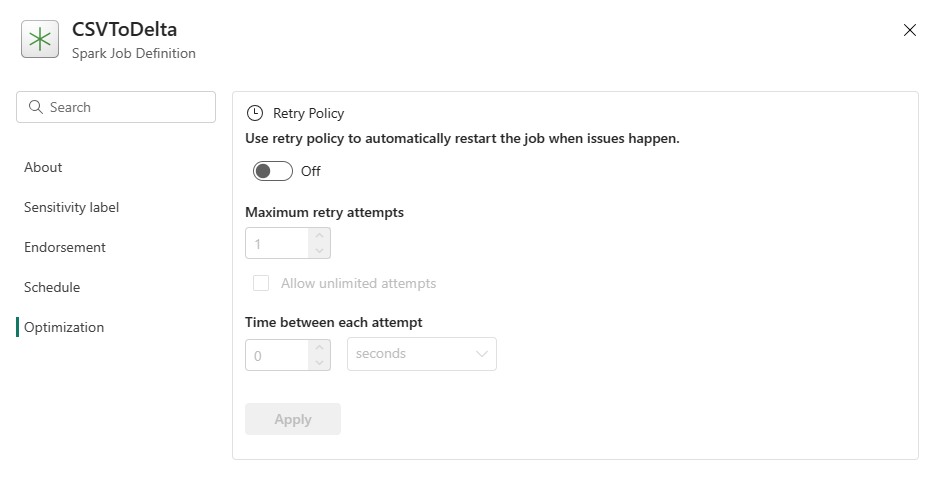
Optimalisering: På fanen Optimalisering kan du aktivere og konfigurere policyen for nye forsøk for jobben. Når den er aktivert, prøves jobben på nytt hvis den mislykkes. Du kan også angi maksimalt antall nye forsøk og intervallet mellom nye forsøk. Jobben startes på nytt for hvert forsøk på nytt. Kontroller at jobben er idempotent.