Få strømming av data til lakehouse og tilgang med SQL Analytics-endepunkt
Denne hurtigstarten forklarer hvordan du oppretter en Spark Job Definition som inneholder Python-kode med Spark Structured Streaming for å lande data i et lakehouse og deretter betjene den gjennom et SQL Analytics-endepunkt. Når du har fullført denne hurtigstarten, har du en sparkjobbdefinisjon som kjører kontinuerlig, og SQL Analytics-endepunktet kan vise innkommende data.
Opprette et Python-skript
Bruk følgende Python-kode som bruker Spark-strukturert strømming til å hente data i et lakehouse-bord.
import sys from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession.builder.appName("MyApp").getOrCreate() tableName = "streamingtable" deltaTablePath = "Tables/" + tableName df = spark.readStream.format("rate").option("rowsPerSecond", 1).load() query = df.writeStream.outputMode("append").format("delta").option("path", deltaTablePath).option("checkpointLocation", deltaTablePath + "/checkpoint").start() query.awaitTermination()Lagre skriptet som Python-fil (PY) på den lokale datamaskinen.
Opprett et innsjøhus
Bruk følgende fremgangsmåte for å opprette et lakehouse:
Velg Synapse Dataingeniør ing-opplevelsen i Microsoft Fabric.
Gå til ønsket arbeidsområde, eller opprett et nytt om nødvendig.
Hvis du vil opprette et lakehouse, velger du Lakehouse-ikonet under Ny-delen i hovedruten.
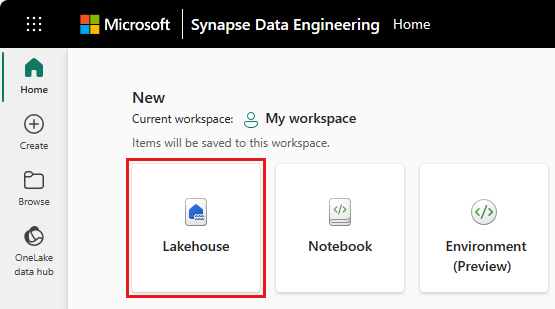
Skriv inn navnet på lakehouse, og velg Opprett.
Opprett en spark-jobbdefinisjon
Bruk følgende fremgangsmåte for å opprette en spark-jobbdefinisjon:
Velg Opprett-ikonet fra menyen til venstre fra samme arbeidsområde der du opprettet et lakehouse.
Velg Spark Job Definition under Dataingeniør ing.
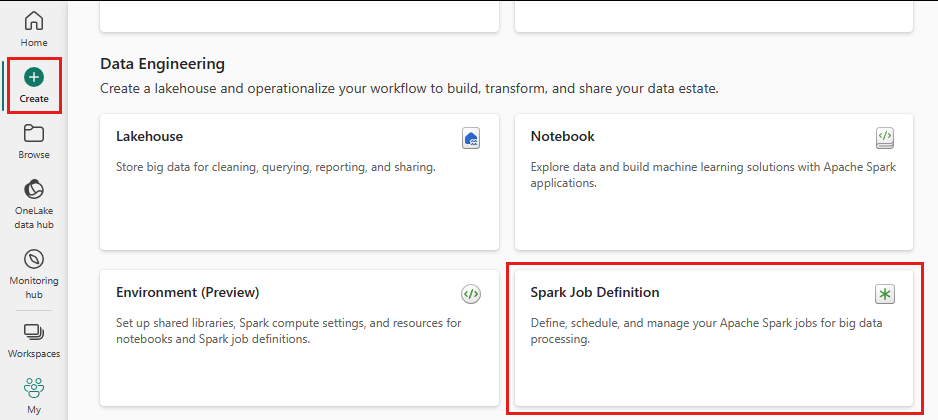
Skriv inn navnet på sparkjobbdefinisjonen, og velg Opprett.
Velg Last opp , og velg Python-filen du opprettet i forrige trinn.
Under Lakehouse Reference velger du lakehouse du opprettet.
Angi policy for nytt forsøk for spark-jobbdefinisjon
Bruk følgende fremgangsmåte for å angi policyen for ny forsøk for Spark-jobbdefinisjonen:
Velg Innstilling-ikonet fra den øverste menyen.

Åpne fanen Optimalisering, og angi Utløser for prøving av policy på nytt.
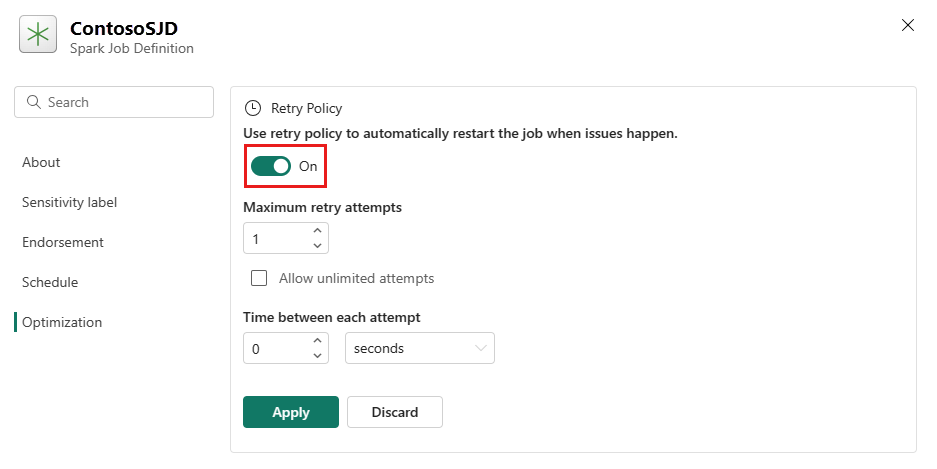
Definer maksimalt antall forsøk på nytt, eller kontroller Tillat ubegrensede forsøk.
Angi tid mellom hvert forsøk på nytt, og velg Bruk.
Merk
Det er en levetidsgrense på 90 dager for konfigurasjonen av policyen for nye forsøk. Når policyen for nye forsøk er aktivert, startes jobben på nytt i henhold til policyen innen 90 dager. Etter denne perioden opphører policyen for nye forsøk automatisk å fungere, og jobben avsluttes. Brukere må deretter starte jobben på nytt manuelt, noe som igjen aktiverer policyen for nytt forsøk.
Utfør og overvåk spark-jobbdefinisjonen
Velg Kjør-ikonet fra den øverste menyen.
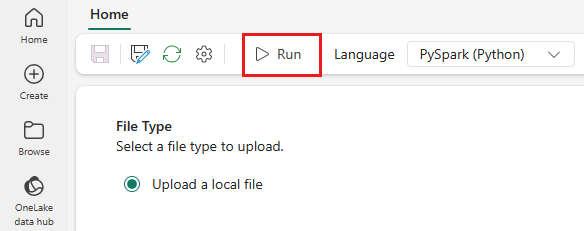
Kontroller om Spark Job-definisjonen ble sendt inn og kjørt.
Vise data ved hjelp av et SQL Analytics-endepunkt
Velg Lakehouse i arbeidsområdevisning.
Velg Lakehouse fra høyre hjørne, og velg SQL Analytics-endepunkt.
Velg tabellen som skriptet bruker til å lande data, i sql analytics-endepunktvisningen under Tabeller. Deretter kan du forhåndsvise dataene fra SQL Analytics-endepunktet.
Relatert innhold
Tilbakemeldinger
Kommer snart: Gjennom 2024 faser vi ut GitHub Issues som tilbakemeldingsmekanisme for innhold, og erstatter det med et nytt system for tilbakemeldinger. Hvis du vil ha mer informasjon, kan du se: https://aka.ms/ContentUserFeedback.
Send inn og vis tilbakemelding for