Merk
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
Fabric Runtime tilbyr en sømløs integrasjon med Azure. Det gir et sofistikert miljø for både datateknikk og datavitenskapsprosjekter som bruker Apache Spark. Denne artikkelen gir en oversikt over de essensielle funksjonene og komponentene i Fabric Runtime 1.3.
Microsoft Fabric Runtime 1.3 er en GA-versjon som inkluderer følgende komponenter og oppgraderinger designet for å forbedre dine databehandlingsmuligheter:
- Apache Spark 3.5
- Operativsystem: Mariner 2.0 (Azure Linux 2.0)
- Java: 11
- Scala: 2.12.17
- Python: 3.11
- Deltasjøen: 3.2
- R: 4.4.1
Important
Tidlig tilgangskanalen for Runtime 1.3 inkluderer et oppgradert operativsystem fra Mariner 2.0 (Azure Linux 2.0) til Mariner 3.0 (Azure Linux 3.0). Bruk tidlig tilgangskanalen for å teste arbeidsbelastningene dine mot denne endringen før den blir standard. Denne valideringen er avgjørende, spesielt hvis arbeidsbelastningene dine har avhengigheter av OS-nivå-pakker.
Tips
Fabric Runtime 1.3 inkluderer støtte for den opprinnelige kjøringsmotoren, noe som kan forbedre ytelsen betydelig uten mer kostnader. Hvis du vil aktivere den opprinnelige kjøringsmotoren på tvers av alle jobber og notatblokker i miljøet, går du til miljøinnstillingene, velger Spark-databehandling, går til Akselerasjon-fanen og kontrollerer Aktiver opprinnelig kjøringsmotor. Når du har lagret og publisert, brukes denne innstillingen på tvers av miljøet, slik at alle nye jobber og notatblokker automatisk arver og drar nytte av de forbedrede ytelsesfunksjonene.
Integrer Kjøretid 1.3
Note
For informasjon om alle tilgjengelige Fabric-kjøretider og deres nåværende status, se Apache Spark Runtimes in Fabric.
Bruk følgende instruksjoner for å integrere kjøretid 1.3 i arbeidsområdet og bruke de nye funksjonene:
Gå til fanen Innstillinger for arbeidsområde i Fabric-arbeidsområdet.
Gå til fanen Dataingeniør ing/vitenskap, og velg Spark-innstillinger.
Velg Miljø-fanen.
Utvid rullegardinlisten under Kjøretidsversjoner.
Velg 1.3 (Spark 3.5, Delta 3.2) og lagre endringene. Denne handlingen angir 1,3 som standard kjøretid for arbeidsområdet.
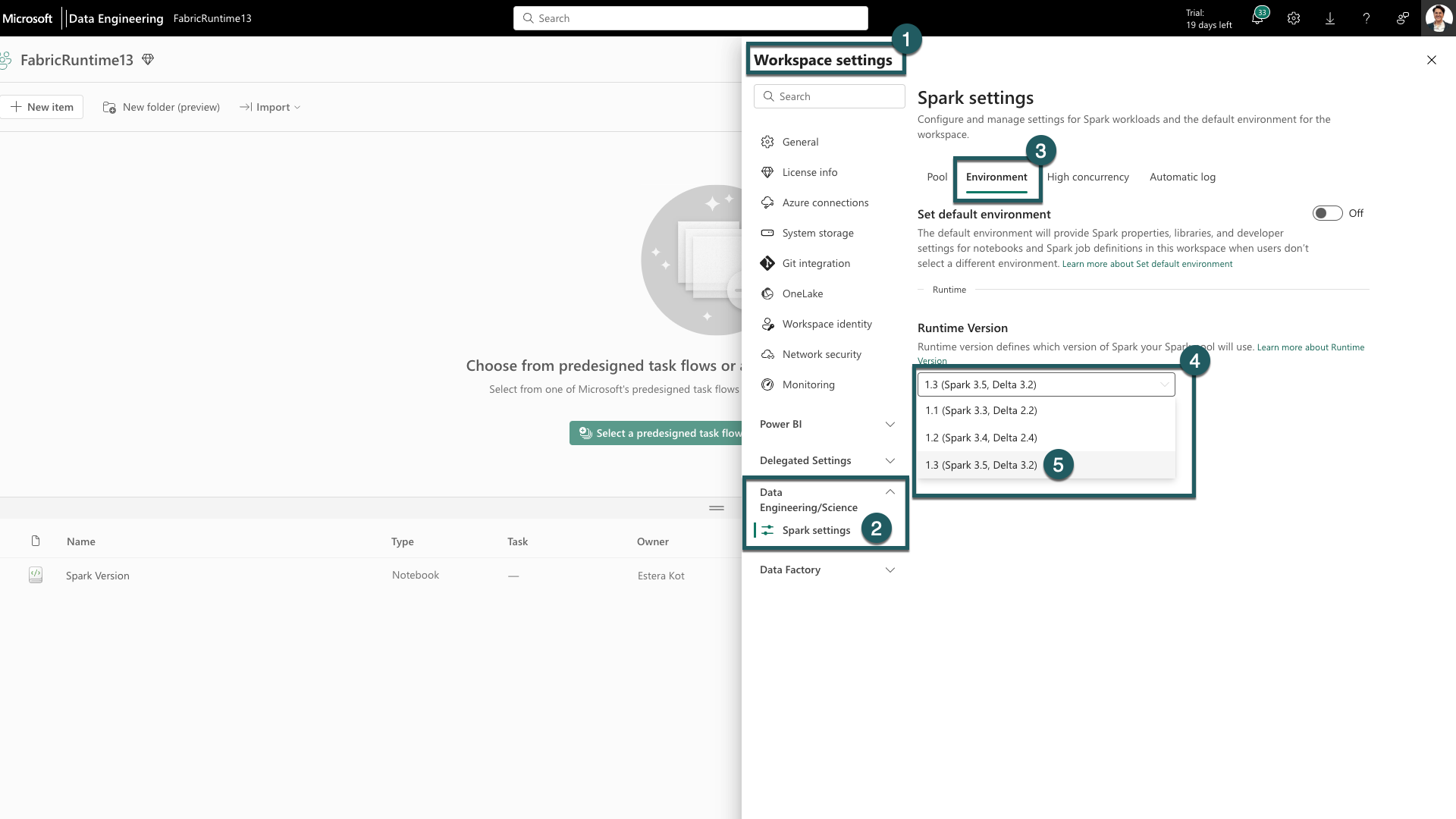

Nå kan du begynne å arbeide med de nyeste forbedringene og funksjonalitetene som introduseres i Fabric Runtime 1.3 (Spark 3.5 og Delta Lake 3.2).
Finn ut mer om Apache Spark 3.5
Apache Spark 3.5.0 er den sjette versjonen i 3.x-serien. Denne versjonen er et produkt av omfattende samarbeid i åpen kildekode-fellesskapet, som tar for seg mer enn 1300 problemer som registrert i Jira.
I denne versjonen er det en oppgradering i kompatibilitet for strukturert strømming. I tillegg utvider denne utgivelsen funksjonaliteten i PySpark og SQL. Den legger til funksjoner som SQL-identifikatorsetningen, navngitte argumenter i SQL-funksjonskall og inkludering av SQL-funksjoner for hyperlog tilnærmet aggregasjoner.
Andre nye funksjoner inkluderer også Python-brukerdefinerte tabellfunksjoner, forenkling av distribuert opplæring via DeepSpeed og nye strukturerte strømmingsfunksjoner som vannmerkeoverføring og dropDuplicatesWithinWatermark-operasjonen .
Du kan sjekke hele listen og detaljerte endringer her: Spark Release 3.5.0.
Finn ut mer om Delta Spark
Delta Lake 3.2 markerer en kollektiv forpliktelse til å gjøre Delta Lake interoperabel på tvers av formater, enklere å jobbe med, og mer performant. Delta Spark 3.2 er bygget på toppen av Apache Spark™ 3.5. Delta Spark maven-artefakten gis nytt navn fra deltakjerne til delta-spark.
Du kan kontrollere hele listen og detaljerte endringer her: https://docs.delta.io/index.html.
Komponenter og biblioteker
Hvis du vil ha oppdatert informasjon, en detaljert liste over endringer og spesifikke produktmerknader for Fabric Runtimes, kan du se og abonnere på Utgivelser og oppdateringer for Spark Runtimes.
Note
EventHubConnector er avskrevet i Fabric Runtime 1.3 (Spark 3.5) og vil bli fjernet fra fremtidige Fabric Runtime-versjoner. Kunder oppfordres til å bruke Kafka Spark Connector i stedet, siden Event Hubs allerede er Kafka-kompatibel. Du kan finne mer informasjon om bruk av Kafka Spark Connector med Event Hubs her: Event Hubs Kafka Spark Tutorial
Relatert innhold
- Les om Apache Spark Runtimes in Fabric – Oversikt, versjonskontroll, støtte for flere kjøretider og oppgradering av Delta Lake Protocol
- Spark Core-overføringsveiledning
- Overføringsveiledninger for SQL, Datasett og DataFrame
- Strukturert overføringsveiledning for strømming
- Overføringsveiledning for MLlib (Machine Learning)
- Overføringsveiledning for PySpark (Python på Spark)
- Overføringsveiledning for SparkR (R på Spark)