Merk
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
I denne artikkelen diskuterer vi teknikker for å hjelpe deg med å optimalisere kopieringsaktivitet med en SQL-databasekilde, ved hjelp av en Azure SQL Database som referanse. Vi dekker ulike aspekter ved optimalisering, inkludert dataoverføringshastigheter, kostnader, overvåking, enkel utvikling og balansering av disse ulike vurderingene for det beste resultatet.
Kopier aktivitetsalternativer
Merk
Måledataene som er inkludert i denne artikkelen, er resultatene av testtilfeller som sammenligner og kontrasterer atferd på tvers av ulike funksjoner, og er ikke formelle tekniske benchmarks. Alle testtilfeller flytter data fra Øst-USA 2 til USA 2-regioner vest.
Når du starter med en pipelinekopieringsaktivitet, er det viktig å forstå kilde- og målsystemene før du starter utviklingen. Du bør angi hva du optimaliserer for, og forstå hvordan du overvåker kilden, målet og pipelinen for å oppnå best mulig ressursutnyttelse, ytelse og forbruk.
Når du henter fra en Azure SQL Database, er det viktig å forstå:
- Inndata-/utdataoperasjoner per sekund (IOPS)
- Datavolum
- DDL for én eller flere tabeller
- Partisjonering av skjemaer
- Primærnøkkel eller annen kolonne med en god fordeling av data (skjev)
- Beregne tildelte og tilknyttede begrensninger, for eksempel antall samtidige tilkoblinger
Det samme gjelder for målet. Med en forståelse av begge deler kan du utforme et datasamlebånd for å operere innenfor grensene og grensene for både kilden og målet samtidig som du optimaliserer for dine prioriteringer.
Merk
Nettverksbåndbredde mellom kilden og målet, sammen med inndata/utdata per sekund (IOPer) av hver, kan begge være en flaskehals til gjennomstrømming, og det anbefales å forstå disse grensene. Nettverk er imidlertid ikke innenfor omfanget av denne artikkelen.
Når du forstår både kilden og målet, kan du bruke ulike alternativer i Kopier-aktiviteten for å forbedre ytelsen for prioriteringene. Disse alternativene kan omfatte:
- Alternativer for kildepartisjonering – Ingen, Fysisk partisjon, Dynamisk område
- Kildeisolasjonsnivå - Ingen, Lese uforpliktende, Lese forpliktet, Øyeblikksbilde
- Innstilling for intelligent gjennomstrømmingsoptimalisering – Auto, Standard, Balansert, Maksimum
- Grad av parallellitetsinnstilling for kopiering – automatisk, angitt verdi
- Logisk partisjonering – utforming av datasamlebånd for å generere flere samtidige kopieringsaktiviteter
Kildedetaljer: Azure SQL Database
For å gi konkrete eksempler testet vi flere scenarier, og flyttet data fra en Azure SQL Database til både Fabric Lakehouse (tabeller) og Fabric Warehouse-tabeller. I disse eksemplene testet vi fire kildetabeller. Alle har samme skjema- og postantall. En bruker en haug, et sekund bruker en gruppert indeks, mens den tredje og fjerde bruker henholdsvis 8 og 85 partisjoner. Dette eksemplet brukte en prøvekapasitet (F64) i Microsoft Fabric (Vest-USA 2).
- Tjenestenivå: Generelt formål
- Databehandlingsnivå: Serverløs
- Maskinvarekonfigurasjon: Standardserie (Gen5)
- Maks vCores: 80
- Min vKjerner 20
- Postantall: 1 500 000 000
- Område: USA øst 2
Standardevaluering
Før du angir alternativet for kildepartisjon, er det viktig å forstå standardvirkemåten for Kopier-aktiviteten.
Standardinnstillingene er:
Kilde
- Partisjonsalternativ - Ingen
- Isolasjonsnivå - Ingen
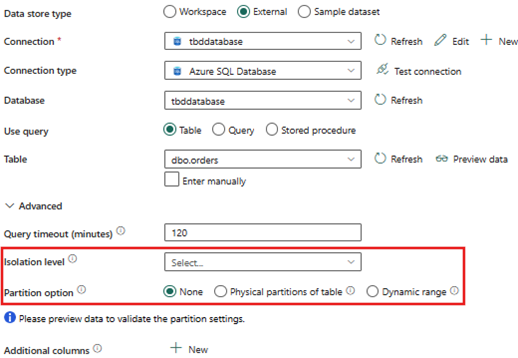
Avanserte innstillinger
- Intelligent gjennomstrømmingsoptimalisering - auto
- Graden av kopieringsparallalisme - Auto
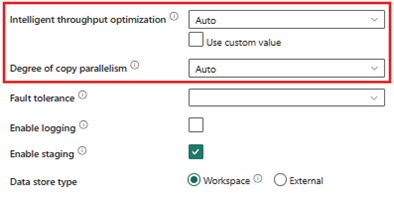


Med det formål å angi en opprinnelig referanseverdi for fremtidig sammenligning, brukte vi standardinnstillingene for en kopieringsaktivitet som lastet inn 1,5 milliarder poster i hvert mål og tok litt over 2 timer per kopiaktivitet.
| Mål | Partisjonsalternativ | Grad av kopi parallellisme | Brukte parallelle kopier | Total varighet |
|---|---|---|---|---|
| Stoff lager | Ingen | automatisk | 1 | 02:23:21 |
| Stoff Lakehouse | Ingen | automatisk | 1 | 02:10:37 |
I denne artikkelen fokuserer vi på total varighet. Total varighet omfatter andre faser, for eksempel kø, forhåndskopiskript og overføringsvarighet. Hvis du vil ha mer informasjon om disse fasene, kan du se Kopier aktivitetskjøringsdetaljer. Hvis du vil ha en omfattende oversikt over egenskapene for Kopier aktivitet for Azure SQL Database som kilde, kan du se kildeegenskapene for Azure SQL Database for Kopier-aktiviteten.
Innstillinger
Intelligent gjennomstrømmingsoptimalisering (ITO)
ITO bestemmer den maksimale mengden CPU, minne og nettverksressurstildeling som aktiviteten kan bruke. Hvis du setter ITO til Maksimum (eller 256), velger tjenesten den høyeste verdien som gir den mest optimaliserte gjennomstrømmingen. I denne artikkelen har alle testtilfeller ITO satt til Maksimum, selv om tjenesten bare bruker det den krever, og den faktiske verdien er lavere enn 256.
Hvis du vil ha en dypere forståelse av ITO, kan du se Intelligent gjennomstrømmingsoptimalisering.
Merk
Oppsamling kreves når kopieringsaktivitetsvasken er Fabric Warehouse. Alternativer som grad av kopieringsparellitet og intelligent gjennomstrømmingsoptimalisering gjelder bare i dette tilfellet fra Kilde til Oppsamling. Testtilfeller til Lakehouse hadde ikke oppsamling aktivert.
Partisjonsalternativer
Når kilden er en relasjonsdatabase som Azure SQL-database, kan du angi et partisjonsalternativ under Avansert. Som standard er denne innstillingen satt til Ingen, med to andre alternativer for fysiske partisjoner av tabellen og dynamisk område.
Dynamisk område
Heap-tabell
Dynamisk område gjør det mulig for tjenesten å generere spørringer intelligent mot kilden. Antallet spørringer som genereres, er lik antallet brukte parallelle kopier av tjenesten som er valgt under kjøring. Graden av kopi parallellisme og brukte parallelle kopier er viktig å vurdere når du optimaliserer bruken av alternativet Dynamisk områdepartisjon .
Partisjonsgrenser
Partisjonens øvre og nedre grense er valgfrie felt som lar deg angi partisjonssteget. I disse testtilfellene forhåndsdefinerte vi både øvre og nedre grense. Hvis disse feltene ikke er angitt, pådrar systemet seg ekstra kostnader ved spørring av kilden for å bestemme områdene. For optimal ytelse, få grensene på forhånd, spesielt for engangs historiske belastninger.
Hvis du vil ha mer informasjon, kan du referere til tabellen i delen Parallell kopi fra SQL-database i azure SQL Database-koblingsartikkelen.
Følgende SQL-spørring bestemmer området vårt min og maks:

Deretter oppgir vi disse detaljene i konfigurasjonen for dynamisk område .

Her er en eksempelspørring generert av Kopier-aktiviteten ved hjelp av dynamisk område:
SELECT * FROM [dbo].[orders] WHERE [o_orderkey] > '4617187501' AND [o_orderkey] <= '4640625001'
Grad av kopi parallellisme
Som standard tilordnes Auto for graden av kopi-parallellitet. Auto kan imidlertid ikke oppnå det optimale antallet parallelle kopier. Parallelle kopier korrelerer med antall økter som er opprettet i kildedatabasen. Hvis det genereres for mange parallelle kopier, står CPU-en for kildedatabasen i fare for å bli overskattet, noe som fører til at spørringer er i en avbrutt tilstand.
I det opprinnelige testtilfellet for dynamisk område ved hjelp av Auto genererte tjenesten faktisk 251 parallelle kopier ved kjøring. Ved å angi en verdi i graden av kopi parallellisme, angir du maksimalt antall parallelle kopier. Med denne innstillingen kan du begrense antall samtidige økter som er gjort til kilden, slik at du kan kontrollere ressursbehandlingen bedre. I disse testtilfellene, ved å angi 50 som verdi, forbedret både total varighet og kilderessursutnyttelse.
| Mål | Partisjonsalternativ | Grad av kopi parallellisme | Brukte parallelle kopier | Total varighet |
|---|---|---|---|---|
| Stoff lager | Ingen | automatisk | 1 | 02:23:21 |
| Stoff lager | Dynamisk område | 50 | 50 | 00:13:05 |
Dynamisk område med en grad av parallelle kopier kan forbedre ytelsen betydelig. Hvis du bruker innstillingen, må du imidlertid forhåndsdefinere grensene eller la tjenesten bestemme verdiene ved kjøretid. Å tillate tjenesten å bestemme verdiene ved kjøretid kan påvirke total varighet, avhengig av DDL og datavolumet i kildetabellen. I tillegg bør det å la tjenesten bestemme verdiene ved kjøretid også være sammenkoblet med en forståelse av hvor mange parallelle kopier kilden kan håndtere. Hvis verdien er for høy, kan kildesystemet og kopieringsaktivitetsytelsen reduseres.
Hvis du vil ha mer informasjon om parallelle kopier, kan du se Kopier aktivitetsytelsesfunksjoner: Parallell kopi.
Fabric Warehouse med dynamisk område
Isoleringsnivå er som standard ikke angitt, og parallellitetsgraden er satt til Auto.
| Mål | Partisjonsalternativ | Grad av kopi parallellisme | Brukte parallelle kopier | Total varighet |
|---|---|---|---|---|
| Stoff lager | Ingen | automatisk | 1 | 02:23:21 |
| Stoff lager | Dynamisk område | automatisk | 251 | 00:39:03 |
Fabric Lakehouse (Tabeller) med dynamisk område
| Mål | Partisjonsalternativ | Grad av kopi parallellisme | Brukte parallelle kopier | Total varighet |
|---|---|---|---|---|
| Stoff Lakehouse | Ingen | automatisk | 1 | 02:23:21 |
| Stoff Lakehouse | Dynamisk område | automatisk | 251 | 00:36:40 |
| Stoff Lakehouse | Dynamisk område | 50 | 50 | 00:12:01 |
Gruppert indeks
Sammenlignet med en heap-tabell, forbedret en tabell med en gruppert nøkkelindeks i kolonnen som er valgt for partisjonskolonnen for dynamisk område drastisk ytelse og ressursutnyttelse. Dette var sant selv når graden av kopi parallellisme ble satt til auto.
Fabric Warehouse med gruppert indeks
| Mål | Partisjonsalternativ | Grad av kopi parallellisme | Brukte parallelle kopier | Total varighet |
|---|---|---|---|---|
| Stoff lager | Ingen | automatisk | 1 | 02:23:21 |
| Stoff lager | Dynamisk område | automatisk | 251 | 00:09:02 |
| Stoff lager | Dynamisk område | 50 | 50 | 00:08:38 |
Fabric Lakehouse (tabeller) med gruppert indeks
| Mål | Partisjonsalternativ | Grad av kopi parallellisme | Brukte parallelle kopier | Total varighet |
|---|---|---|---|---|
| Stoff Lakehouse | Ingen | automatisk | 1 | 02:23:21 |
| Stoff Lakehouse | Dynamisk område | automatisk | 251 | 00:06:44 |
| Stoff Lakehouse | Dynamisk område | 50 | 50 | 00:06:34 |
Logisk partisjonsutforming
Det logiske partisjonsutformingsmønsteret er mer avansert og krever mer utviklerinnsats. Denne utformingen brukes imidlertid i scenarioer med strenge krav til innlasting av data. Denne utformingen ble opprinnelig utviklet for å dekke behovene til en lokal Oracle-database for å laste inn 180 GB data på under 1,5 timer. Den opprinnelige utformingen, ved hjelp av standarder for kopiaktiviteten, tok over 65 timer. Ved hjelp av en logisk partisjoneringsutforming ser vi de samme dataene som er overført på under 1,5 timer.
Denne utformingen ble også brukt i denne bloggserien: Forbedringer av pipelineytelse Del 1: Slik konverterer du et tidsintervall til sekunder). Denne utformingen er god til å etterligne i miljøet når du laster inn store kildetabeller og trenger optimal innlastingsytelse ved hjelp av teknikker som å angi et dataområde for å partisjonere kildedataene. Denne utformingen genererer mange sekundære datoområder. Deretter aktiveres mange kopieringsaktiviteter til kildedata mellom det angitte området ved å bruke en for-hver aktivitet til å gjentakelse over områdene. I for-hver-aktiviteten kjører alle kopieringsaktivitetene parallelt (opptil antall partiantall maksimalt 50) og har graden av kopieringsparellitet satt til Auto.
For eksemplene nedenfor ble de partisjonerte datoverdiene satt til disse verdiene:
- Startverdi: 1992-01-01
- Sluttverdi: 1998-08-02
- Samlingsintervalldager: 50
Parallelle kopier og total varighet er en maksimal verdi som er observert på tvers av alle de 50 kopiaktivitetene som ble opprettet. Siden alle 50 kjørte parallelt, er den maksimale verdien for total varighet hvor lang tid alle kopieringsaktiviteter tok å fullføre parallelt.
Fabric Warehouse med logisk partisjonsutforming
| Mål | Partisjonsalternativ | Grad av kopi parallellisme | Brukte parallelle kopier | Total varighet |
|---|---|---|---|---|
| Stoff lager | Ingen | automatisk | 1 | 02:23:21 |
| Stoff lager | Logisk utforming | automatisk | 1 | 00:12:11 |
Fabric Lakehouse (tabeller) med logisk partisjonsutforming
| Mål | Partisjonsalternativ | Grad av kopi parallellisme | Brukte parallelle kopier | Total varighet |
|---|---|---|---|---|
| Stoff Lakehouse | Ingen | automatisk | 1 | 02:10:37 |
| Stoff Lakehouse | Logisk utforming | automatisk | 1 | 00:09:14 |
Fysiske partisjoner av tabellen
Merk
Når du bruker fysiske partisjoner, bestemmes partisjonskolonnen og mekanismen automatisk basert på den fysiske tabelldefinisjonen.
Hvis du vil bruke fysiske partisjoner i en tabell, må kildetabellen partisjoneres. For å forstå hvordan antall partisjoner påvirker ytelsen, opprettet vi to partisjonerte tabeller, én med 8 partisjoner og den andre med 85 partisjoner.
Antall fysiske partisjoner begrenser graden av kopi parallellisme. Du kan fortsatt begrense antallet ved å angi en verdi som er mindre enn antall partisjoner.
Fabric Warehouse med fysiske partisjoner
| Mål | Partisjonsalternativ | Grad av kopi parallellisme | Brukte parallelle kopier | Total varighet |
|---|---|---|---|---|
| Stoff lager | Ingen | automatisk | 1 | 02:23:21 |
| Stoff lager | Fysisk | automatisk | 8 | 00:26:29 |
| Stoff lager | Fysisk | automatisk | 85 | 00:08:31 |
Fabric Lakehouse (tabeller) med fysiske partisjoner
| Mål | Partisjonsalternativ | Grad av kopi parallellisme | Brukte parallelle kopier | Total varighet |
|---|---|---|---|---|
| Stoff Lakehouse | Ingen | automatisk | 1 | 02:10:37 |
| Stoff Lakehouse | Fysisk | automatisk | 8 | 00:36:36 |
| Stoff Lakehouse | Fysisk | automatisk | 85 | 00:12:21 |
Isolasjonsnivåer
La oss sammenligne hvordan angivelse av ulike innstillinger for isolasjonsnivå påvirker ytelsen. Når du velger Isoleringsnivå med en grad av kopi parallellisme satt til Auto, står Kopier-aktiviteten i fare for å overskatte kildesystemet og mislykkes. Det anbefales å forlate isoleringsnivå som Ingen hvis du vil la graden av kopi parallellisme være satt til Auto.
Merk
Azure SQL Database er som standard *Isoleringsnivå Read_Committed_Snapshot.
La oss utvide testtilfellet for dynamisk område med grad av kopi parallellisme satt til 50 og se hvordan isolasjonsnivå påvirker ytelsen.
| Isolasjonsnivå | Total varighet | Kapasitetsenheter | DB Maks CPU-% | Maksimal DB-økt |
|---|---|---|---|---|
| Ingen (standard) | 00:14:23 | 93,960 | 70 | 76 |
| Les uforpliktende | 00:13:46 | 89,280 | 81 | 76 |
| Les forpliktet | 00:25:34 | 97,560 | 81 | 76 |
Isolasjonsnivået du velger for databasekildespørringene, vil være mer et krav i stedet for optimaliseringsbane, men det er viktig å forstå forskjellene i ytelse og kapasitetsenheters forbruk mellom hvert alternativ.
Hvis du vil ha mer informasjon om isolasjonsnivå,** kan du se IsolationLevel Enum.
ITO og kapasitetsforbruk
I likhet med graden av parallelle kopier, er Intelligent gjennomstrømmingsoptimalisering (ITO) en annen maksimumsverdi som kan angis. Hvis du optimaliserer for kostnader, er ITO en flott innstilling for å vurdere å justere for å møte ønsket resultat.
ITO-områder:
| ITO | Maks. verdi |
|---|---|
| automatisk | Ikke angitt |
| Standard | 64 |
| Balansert | 128 |
| Maksimalt | 256 |
Selv om rullegardinlisten tillater innstillingene ovenfor, tillater vi også bruk av egendefinerte verdier mellom 4 og 256.
Merk
Det faktiske antallet ITO som brukes, finnes i feltet Kopier aktivitetsutdata bruktDataIntegrationUnits .
For testtilfellet dynamisk område heap der graden av parallelle kopier ble satt til Auto, valgte tjenesten Balansert med en faktisk verdi på 100. La oss se hva som skjer når ITO-en halveres ved å angi en egendefinert verdi på 50:
| ITO angitt | Total varighet | Kapasitetsenheter | DB Maks CPU-% | Maksimal DB-økt | Bruk optimalisert gjennomstrømming |
|---|---|---|---|---|---|
| Maksimum (256) | 00:13:46 | 89,280 | 81 | 76 | Balansert (100) |
| 50 | 00:18:28 | 48,600 | 76 | 61 | Standard (48) |
Ved å kutte ITO-en med 50 %, økte den totale varigheten med 34 %, men tjenesten brukte 45,5 % færre kapasitetsenheter. Hvis du ikke optimaliserer for forbedret total varighet og vil redusere kapasitetsenhetene som brukes, vil det være nyttig å sette ITO-en til en lavere verdi.
Sammendrag
De følgende diagrammene oppsummerer hvordan du laster inn i tabellene Fabric Warehouse og Fabric Lakehouse. Hvis tabellen har en fysisk partisjon, vil bruk av partisjonsalternativet: Fysiske partisjoner av tabellen være den mest balanserte tilnærmingen for overføringsvarighet, kapasitetsenheter og beregningskostnader på kilden. Denne innstillingen er spesielt ideell hvis du har flere økter som kjører mot databasen i løpet av dataflyttingen.
Hvis tabellen ikke har fysiske partisjoner, kan du fortsatt bruke partisjonsalternativet: Dynamisk område. Dette alternativet krever et tidligere trinn for å fastslå øvre og nedre grense, men det gir fortsatt betydelige forbedringer i overføringsvarigheten sammenlignet med standardalternativene på bekostning av litt høyere kapasitetsforbruk, bruk av kildedatabehandling og behovet for å teste for optimal grad av parallellisme.
En annen viktig faktor for å maksimere ytelsen til kopieringsjobbene er å holde databevegelsen inne i et enkelt skyområde. Dataflytting fra et kilde- og måldatalager i USA vest, med en datafabrikk i USA vest overgår for eksempel en kopijobb som flytter data fra USA øst til USA vest.
Til slutt, hvis hastighet er det viktigste aspektet ved optimalisering, er det viktig å ha en optimalisert DDL i kildetabellen ved hjelp av fysiske partisjonsalternativer. Prøv dynamisk område for en ikke-partisjonert tabell, og denne innstillingen er ikke rask nok, og vurder logisk partisjonering eller en hybrid tilnærming til logisk partisjonering pluss dynamisk område innenfor underboundaries.
Retningslinjer
Kostnadsjuster intelligent gjennomstrømmingsoptimalisering og grad av parallelle kopier. Hastighet For partisjonerte tabeller, hvis det finnes et godt antall partisjoner, bruker du partisjonsalternativet: Fysiske partisjoner av tabeller. Hvis ikke, hvis dataene er skjevt eller det er et begrenset antall partisjoner, bør du vurdere å bruke dynamisk område. For heap og tabeller med indekser bruker du dynamisk område med grad av parallelle kopier som vil begrense antall suspenderte spørringer på kilden. Hvis du kan forhåndsdefinere partisjonens øvre/nedre grense, kan du realisere ytterligere ytelsesforbedringer.
Vurder vedlikehold og utviklerinnsats. Når du forlater standardalternativene, tar det lengst tid å flytte data, men det kan hende at kjøring med standardinnstillingene er det beste alternativet, spesielt hvis kildetabellens DDL er ukjent. Dette gir også rimelig forbruk av kapasitetsenheter.
Testtilfeller
Testtilfeller for Fabric Warehouse
| Partisjonsalternativ | Grad av kopi parallellisme | Brukte parallelle kopier | Total varighet | Kapasitetsenheter | Maks. CPU % | Maksimalt antall økter |
|---|---|---|---|---|---|---|
| Ingen | automatisk | 1 | 02:23:21 | 51,839 | < 1 | 2 |
| Fysisk (8) | automatisk | 8 | 00:26:29 | 49,320 | 3 | 10 |
| Fysisk (85) | automatisk | 85 | 00:08:31 | 108,000 | sept. | 83 |
| Dynamisk område (heap) | automatisk | 242 | 00:39:03 | 282,600 | 100 | 272 |
| Dynamisk område (heap) | 50 | 50 | 00:13:05 | 92,159 | 81 | 76 |
| Dynamisk område (gruppert indeks) | automatisk | 251 | 00:09:02 | 64,080 | 9 | 277 |
| Dynamisk område (gruppert indeks) | 50 | 50 | 00:08:38 | 55,440 | 10 | 77 |
| Logisk utforming | automatisk | 1 | 00:12:11 | 226,108 | 91 | 50 |
Testtilfeller for Fabric Lakehouse (Tabeller)
| Partisjonsalternativ | Grad av kopi parallellisme | Brukte parallelle kopier | Total varighet | Kapasitetsenheter | Maks. CPU % | Maksimalt antall økter |
|---|---|---|---|---|---|---|
| Ingen | automatisk | 1 | 02:10:37 | 47,520 | <1% | 2 |
| Fysisk (8) | automatisk | 8 | 00:36:36 | 64,079 | 2 | 10 |
| Fysisk (85) | automatisk | 85 | 00:12:21 | 275,759 | ||
| Dynamisk område (heap) | automatisk | 251 | 00:36:12 | 280,080 | 100 | 276 |
| Dynamisk område (heap) | 50 | 50 | 00:12:01 | 101,159 | 68 | 76 |
| Dynamisk område (gruppert indeks) | automatisk | 251 | 00:06:44 | 59,760 | 11 | 276 |
| Dynamisk område (gruppert indeks) | 50 | 50 | 00:06:34 | 54,760 | 10 | 76 |
| Logisk utforming | automatisk | 1 | 00:09:14 | 164,908 | 82 | 50 |
Relatert innhold
- Slik kopierer du data ved hjelp av kopieringsaktivitet
- Kopier aktivitetsytelse og skalerbarhetsveiledning
- Kopiere og transformere data i Azure SQL Database
- Konfigurer Azure SQL Database i en kopiaktivitet
- Opprette partisjonerte tabeller og indekser i Azure SQL Database
- Microsoft Fabric-bloggen: Forbedring av pipelineytelse del 3 – Få mer enn 50% forbedring for historiske belastninger