Merk
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
I denne artikkelen lærer du hvordan du utfører utforskende dataanalyse ved hjelp av Azure Open Datasets og Apache Spark. Denne artikkelen analyserer new york city taxi datasett. Dataene er tilgjengelige via Azure Open Datasets. Dette delsettet av datasettet inneholder informasjon om gule taxiturer: informasjon om hver tur, start- og sluttidspunkt og plasseringer, kostnader og andre interessante attributter.
I denne artikkelen:
- Laste ned og klargjøre data
- Analyser data
- Visualiser data
Forutsetning
Få et Microsoft Fabric-abonnement. Eller registrer deg for en gratis prøveversjon av Microsoft Fabric.
Logg på Microsoft Fabric.
Bruk opplevelsesbryteren nederst til venstre på hjemmesiden for å bytte til Fabric.

Laste ned og klargjøre dataene
For å starte, last ned New York City (NYC) Taxi datasett og klargjøre dataene.
Opprett en notatblokk ved hjelp av PySpark. Hvis du vil ha instruksjoner, kan du se Opprette en notatblokk.
Merk
På grunn av PySpark-kjernen trenger du ikke å opprette noen kontekster eksplisitt. Spark-konteksten opprettes automatisk for deg når du kjører den første kodecellen.
I denne artikkelen bruker du flere ulike biblioteker for å visualisere datasettet. Hvis du vil gjøre denne analysen, importerer du følgende biblioteker:
import matplotlib.pyplot as plt import seaborn as sns import pandas as pdSiden rådataene er i Parquet-format, kan du bruke Spark-konteksten til å hente filen inn i minnet som en DataFrame direkte. Bruk API-en åpne datasett til å hente dataene og opprette en Spark DataFrame. Hvis du vil utlede datatyper og skjema, bruker du Spark DataFrame-skjemaet på leseegenskaper .
from azureml.opendatasets import NycTlcYellow end_date = parser.parse('2018-06-06') start_date = parser.parse('2018-05-01') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) nyc_tlc_pd = nyc_tlc.to_pandas_dataframe() df = spark.createDataFrame(nyc_tlc_pd)Når dataene er lest, kan du utføre noen første filtrering for å rense datasettet. Du kan fjerne unødvendige kolonner og legge til kolonner som trekker ut viktig informasjon. I tillegg kan du filtrere ut avvik i datasettet.
# Filter the dataset from pyspark.sql.functions import * filtered_df = df.select('vendorID', 'passengerCount', 'tripDistance','paymentType', 'fareAmount', 'tipAmount'\ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , dayofweek('tpepPickupDateTime').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month'))\ .filter((df.passengerCount > 0)\ & (df.tipAmount >= 0)\ & (df.fareAmount >= 1) & (df.fareAmount <= 250)\ & (df.tripDistance > 0) & (df.tripDistance <= 200)) filtered_df.createOrReplaceTempView("taxi_dataset")
Analyser data
Som dataanalytiker har du et bredt spekter av tilgjengelige verktøy for å hjelpe deg med å trekke ut innsikt fra dataene. I denne delen av artikkelen kan du lære om noen nyttige verktøy som er tilgjengelige i Microsoft Fabric-notatblokker. I denne analysen vil du forstå faktorene som gir høyere taxitips for den valgte perioden.
Apache Spark SQL Magic
Først gjør du utforskende dataanalyse ved hjelp av Apache Spark SQL og magiske kommandoer med Microsoft Fabric-notatblokken. Når du har spørringen, visualiserer du resultatene ved hjelp av den innebygde chart options funksjonen.
Opprett en ny celle i notatblokken, og kopier følgende kode. Ved hjelp av denne spørringen kan du forstå hvordan de gjennomsnittlige tipsmengdene endres i løpet av perioden du velger. Denne spørringen hjelper deg også med å identifisere annen nyttig innsikt, inkludert minimums-/maksimumstipsbeløpet per dag og gjennomsnittlig prisbeløp.
%%sql SELECT day_of_month , MIN(tipAmount) AS minTipAmount , MAX(tipAmount) AS maxTipAmount , AVG(tipAmount) AS avgTipAmount , AVG(fareAmount) as fareAmount FROM taxi_dataset GROUP BY day_of_month ORDER BY day_of_month ASCNår spørringen er ferdig, kan du visualisere resultatene ved å bytte til diagramvisningen. Dette eksemplet oppretter et linjediagram ved å
day_of_monthangi feltet som nøkkel ogavgTipAmountverdi. Når du har gjort valgene, velger du Bruk for å oppdatere diagrammet.
Visualiser data
I tillegg til de innebygde diagramalternativene for notatblokker, kan du bruke populære biblioteker med åpen kildekode til å opprette dine egne visualiseringer. I eksemplene nedenfor bruker du Seaborn og Matplotlib, som ofte brukes Python-biblioteker for datavisualisering.
For å gjøre utviklingen enklere og rimeligere, kan du redusere datasettet. Bruk den innebygde samplingsfunksjonen for Apache Spark. I tillegg krever både Seaborn og Matplotlib en Pandas DataFrame- eller NumPy-matrise. Hvis du vil ha en Pandas DataFrame, bruker
toPandas()du kommandoen til å konvertere DataFrame.# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) # The charting package needs a Pandas DataFrame or NumPy array to do the conversion sampled_taxi_pd_df = sampled_taxi_df.toPandas()Du kan forstå distribusjonen av tips i datasettet. Bruk Matplotlib til å opprette et histogram som viser fordelingen av tipsbeløp og antall. Basert på fordelingen kan du se at tips er skjevt mot beløp som er mindre enn eller lik KR 10.
# Look at a histogram of tips by count by using Matplotlib ax1 = sampled_taxi_pd_df['tipAmount'].plot(kind='hist', bins=25, facecolor='lightblue') ax1.set_title('Tip amount distribution') ax1.set_xlabel('Tip Amount ($)') ax1.set_ylabel('Counts') plt.suptitle('') plt.show()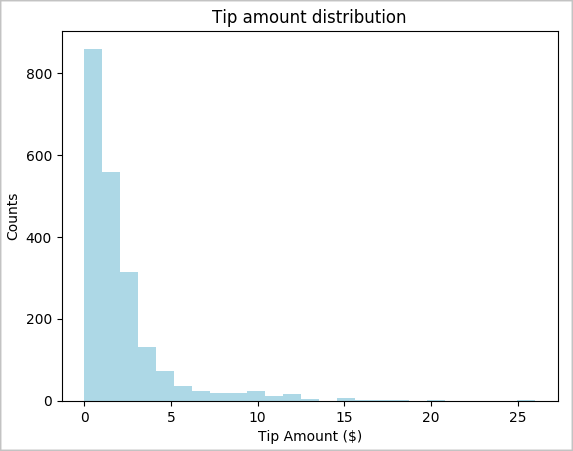
Prøv deretter å forstå forholdet mellom tipsene for en gitt reise og ukedagen. Bruk Seaborn til å opprette et boksplott som oppsummerer trendene for hver dag i uken.
# View the distribution of tips by day of week using Seaborn ax = sns.boxplot(x="day_of_week", y="tipAmount",data=sampled_taxi_pd_df, showfliers = False) ax.set_title('Tip amount distribution per day') ax.set_xlabel('Day of Week') ax.set_ylabel('Tip Amount ($)') plt.show()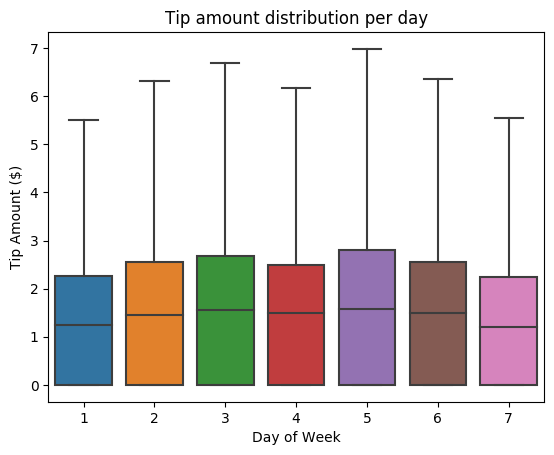
En annen hypotese kan være at det er en positiv sammenheng mellom antall passasjerer og det totale taxitipsbeløpet. Hvis du vil bekrefte denne relasjonen, kjører du følgende kode for å generere et boksplott som illustrerer fordelingen av tips for hver passasjerantall.
# How many passengers tipped by various amounts ax2 = sampled_taxi_pd_df.boxplot(column=['tipAmount'], by=['passengerCount']) ax2.set_title('Tip amount by Passenger count') ax2.set_xlabel('Passenger count') ax2.set_ylabel('Tip Amount ($)') ax2.set_ylim(0,30) plt.suptitle('') plt.show()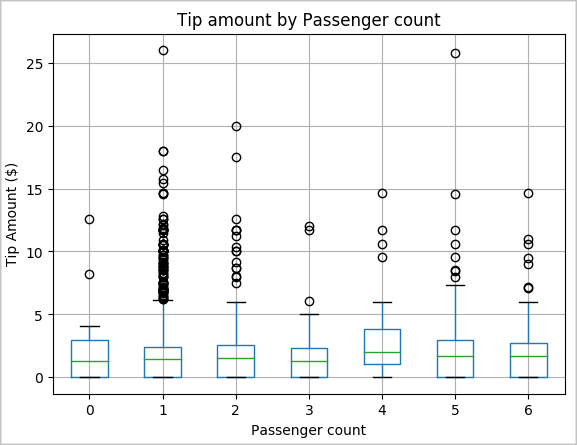
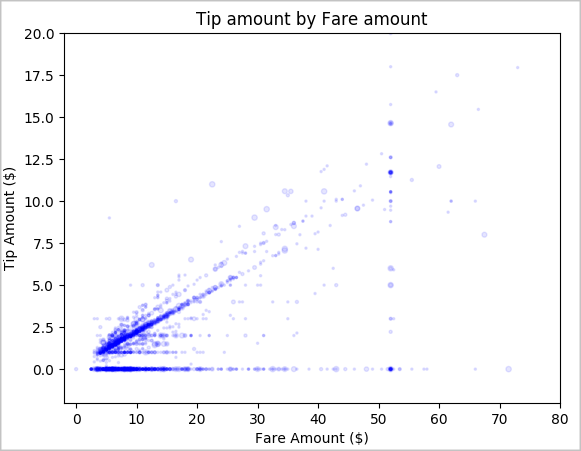
Til slutt kan du utforske forholdet mellom prisbeløpet og tipsbeløpet. Basert på resultatene kan du se at det finnes flere observasjoner der personer ikke tipser. Det er imidlertid en positiv sammenheng mellom den totale prisen og tipsbeløpene.
# Look at the relationship between fare and tip amounts ax = sampled_taxi_pd_df.plot(kind='scatter', x= 'fareAmount', y = 'tipAmount', c='blue', alpha = 0.10, s=2.5*(sampled_taxi_pd_df['passengerCount'])) ax.set_title('Tip amount by Fare amount') ax.set_xlabel('Fare Amount ($)') ax.set_ylabel('Tip Amount ($)') plt.axis([-2, 80, -2, 20]) plt.suptitle('') plt.show()