Merk
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
Gjelder for: ✅ SQL analytics-endepunkt og Warehouse i Microsoft Fabric
Egendefinerte SQL-pooler gir administratorer mer kontroll over hvordan ressurser tildeles for å håndtere forespørsler. I denne hurtigstarten konfigurerer du tilpassede SQL-pooler og observerer klassifisatorverdiene ved hjelp av Fabric REST API.
Arbeidsområdeadministratorer kan bruke applikasjonsnavnet (eller programnavnet) fra tilkoblingsstrengen for å rute forespørsler til forskjellige beregningspooler. Workspace-administratorer kan også kontrollere prosentandelen ressurser hver compute SQL-pool kan få tilgang til, basert på den burstbare skaleringsgrensen for arbeidsområdets kapasitet.
Fabric REST API definerer et samlet endepunkt for operasjoner.
Forutsetninger
- Tilgang til en lagergjenstand i et arbeidsområde. Du bør være medlem av administratorrollen.
Få den nåværende konfigurasjonen
Bruk følgende API for å få den nåværende konfigurasjonen.
Eksempel på stoffnotatbok
Du kan kjøre følgende eksempel på Python-kode i en Fabric Spark-notatbok.
- Koden sender en
GETforespørsel til det tilpassede SQL-poolkonfigurasjons-API-et og returnerer den tilpassede SQL-poolkonfigurasjonen for arbeidsområdet. - Feltet
workspace_idbruker formssparkutils.runtime.contextå hente arbeidsområdets GUID som notatboken kjører i. For å konfigurere en tilpasset SQL-pool i et annet arbeidsområde, oppdater tilworkspace_idGUID-en til arbeidsområdet der du vil konfigurere de tilpassede SQL-poolene.
import requests
import json
from notebookutils import mssparkutils
# This will get the workspace_id where this notebook is running.
# Update to the workspace_id (guid) if running this notebook outside of the workspace where the warehouse exists.
workspaceId = mssparkutils.runtime.context.get('currentWorkspaceId')
url = f'https://api.fabric.microsoft.com/v1/workspaces/{workspaceId}/warehouses/sqlPoolsConfiguration?beta=true'
response = requests.request(method='get', url=url, headers={'Authorization': f'Bearer {mssparkutils.credentials.getToken("pbi")}'})
if response.status_code == 200:
print(json.dumps(response.json(), indent=4))
else:
print(response.text)
Konfigurer tilpassede SQL-pooler
Følgende Python-eksempel aktiverer og konfigurerer egendefinerte SQL-pooler. Du kan kjøre denne Python-koden i en Fabric Spark-notatbok.
- Den tilpassede SQL-poolkonfigurasjonen er kun aktiv når
customSQLPoolsEnabledattributtet er satt til true. Du kan definere en nyttelast i objektdefinisjonencustomSQLPools, men hvis du ikke setter customSQLPoolsEnabled til true, ignoreres nyttelasten og autonom arbeidsbelastningshåndtering brukes. - Koden konfigurerer to tilpassede SQL-pooler,
ContosoSQLPoologAdhocPool.- Den
ContosoSQLPooler satt til å motta 70% av tilgjengelige ressurser. Applikasjonsnavnklassifikatoren har verdien .MyContosoApp - Alle SQL-spørringer som kommer fra en tilkoblingsstreng som spesifiserer applikasjonsnavnet
MyContosoApp, klassifiseres i den tilpassede SQL-poolenContosoSQLPoolog har tilgang til 70% av de totale nodene med burstbar kapasitet. - Alle SQL-spørringer som ikke inneholder
MyContosoAppapplikasjonsnavnet til tilkoblingsstrengen, sendes til denAdhocegendefinerte SQL-poolen, som er definert som standardpoolen. Disse forespørslene får tilgang til 30% av de totale nodene med burstbar kapasitet.
- Den
- Alle tilpassede SQL-poolkonfigurasjoner må ha én standard SQL-pool identifisert ved å sette attributtet
isDefaulttil true. - Summen av alle
maxResourcePercentageverdier må være mindre enn eller lik 100%. - Feltet
workspace_idbruker formssparkutils.runtime.contextå hente arbeidsområdets GUID som notatboken kjører i. For å konfigurere en tilpasset SQL-pool i et annet arbeidsområde, oppdater tilworkspace_idGUID-en til arbeidsområdet der du vil konfigurere de tilpassede SQL-poolene.
import requests
import json
from notebookutils import mssparkutils
body = {
"customSQLPoolsEnabled": True,
"customSQLPools": [
{
"name": "ContosoSQLPool",
"isDefault": False,
"maxResourcePercentage": 70,
"optimizeForReads": False,
"classifier": {
"type": "Application Name",
"value": [
"MyContosoApp"
]
}
},
{
"name": "AdhocPool",
"isDefault": True,
"maxResourcePercentage": 30,
"optimizeForReads": True
}
]
}
# This will get the workspaceId where this notebook is running.
# Update to the workspace_id (guid) if running this notebook outside of the workspace where the warehouse exists.
workspace_id = mssparkutils.runtime.context.get('currentWorkspaceId')
url = f'https://api.fabric.microsoft.com/v1/workspaces/{workspace_id}/warehouses/sqlPoolsConfiguration?beta=true'
response = requests.request(method='patch', url=url, json=body, headers={'Authorization': f'Bearer {mssparkutils.credentials.getToken("pbi")}'})
if response.status_code == 200:
print("SQL Custom Pools configured successfully.")
else:
print(response.text)
Tips
Bruk disse nyttige Application Name (regex) klassifikatorverdiene for trafikk fra Fabric:
- For å klassifisere spørringer fra Fabric-pipelines, bruk
^Data Integration-to[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[1-5][0-9a-fA-F]{3}-[89abAB][0-9a-fA-F]{3}-[0-9a-fA-F]{12}$. - For å klassifisere spørringer fra Power BI, bruk
^(PowerBIPremium-DirectQuery|Mashup Engine(?: \(PowerBIPremium-Import\))?). - For å klassifisere spørringer fra Fabric-portalens SQL-spørringseditor, bruk
DMS_user.
Sett applikasjonsnavnet i SQL Server Management Studio (SSMS)
Klassifisereren for tilpassede SQL-pooler bruker applikasjonsnavnet eller programnavnparameteren til vanlige tilkoblingsstrenger.
I SQL Server Management Studio (SSMS), spesifiser servernavnet for lageret og gir autentisering. Microsoft Entra MFA anbefales.
Velg Avansert-knappen .
På siden Avanserte egenskaper , under Kontekst, endre verdien av applikasjonsnavn til
MyContosoApp.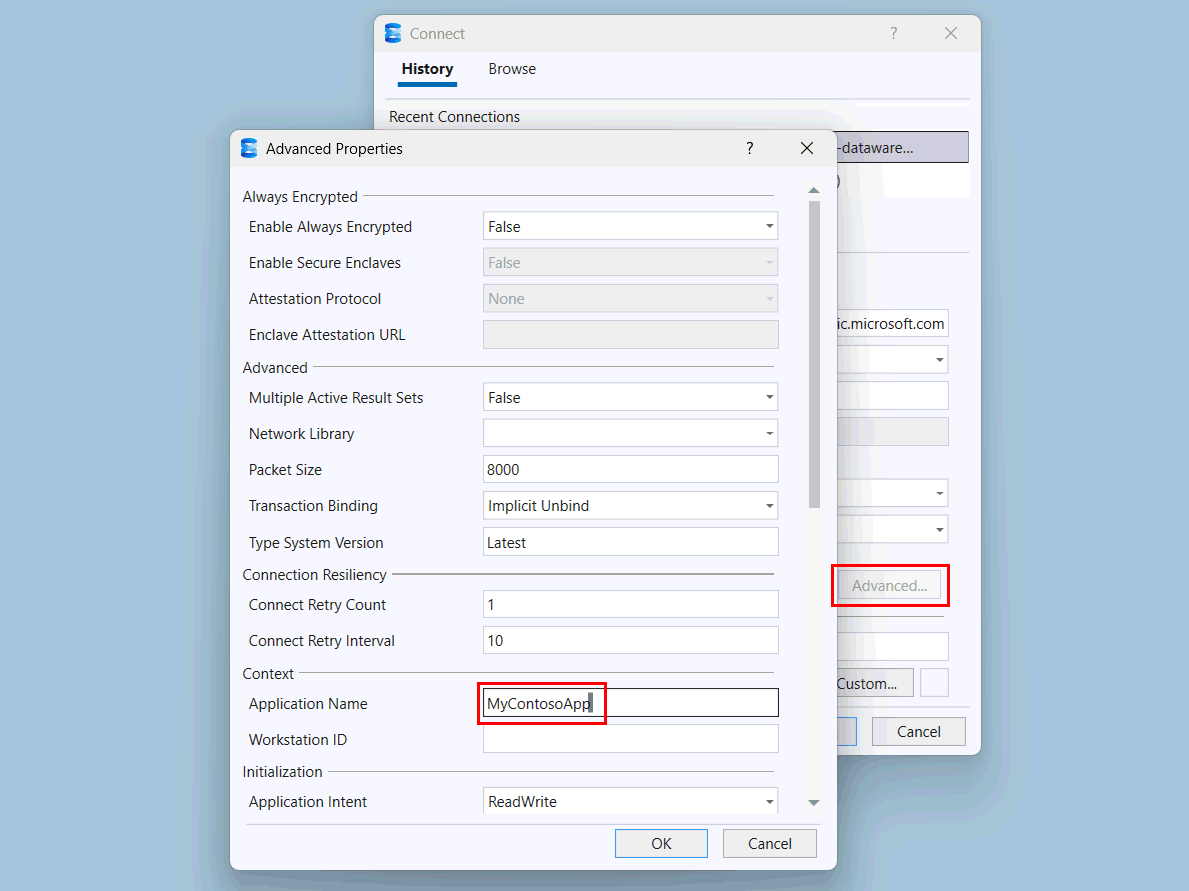
Velg OK.
Velg Koble til.
For å generere noe eksempelaktivitet, bruk denne tilkoblingen i SSMS til å kjøre en enkel spørring i lageret ditt, for eksempel:
SELECT * FROM dbo.DimDate;

Observer spørringsinnsikter for den tilpassede SQL-poolen
Gå gjennom den dynamiske administrasjonsvisningen
sys.dm_exec_sessionsfor å se at detMyContosoAppblir gjenkjent som applikasjonsnavnet som sendes fra SSMS til SQL-motoren.SELECT session_id, program_name FROM sys.dm_exec_sessions WHERE program_name = 'MyContosoApp';Eksempel:
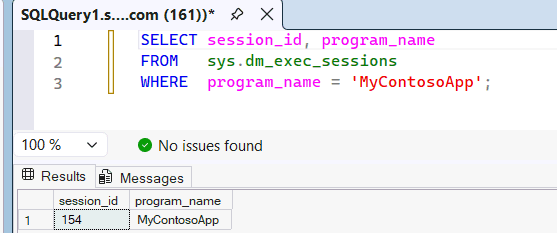
Fordi den
program_namematcher applikasjonsnavnet i den tilpassede SQL-poolenMyContosoApp, bruker denne spørringen ressursene i den poolen. For å bevise hvilken egendefinert SQL-pool spørringen brukte, kan du spørre i queryinsights.exec_requests_history systemvisning. Vent 10-15 minutter på at query insights skal fylles ut, og kjør deretter følgende forespørsel.SELECT distributed_statement_id, submit_time, program_name, sql_pool_name, start_time, end_time FROM queryinsights.exec_requests_history WHERE program_name = 'MyContosoApp';Du kan også identifisere poolen til en spørring ut fra dens Statement-ID. I Fabric-portalens SQL-spørringseditor, kjør en spørring mot lageret ditt eller SQL-analyse-endepunktet.
SELECT * FROM dbo.DimDate;Velg fanen Meldinger og registrer setnings-ID-en for utførelsen av spørringen. I SQL-spørringseditoren er
DMS_userdenprogram_name, som du konfigurerte til å bruke den tilpassede SQL-poolenMyContosoApptidligere.Vent 10-15 minutter på at søkeinnsikter skal fylles ut.
Hente og
sql_pool_nameannen informasjon for å verifisere at riktig tilpasset SQL-pool ble brukt.SELECT distributed_statement_id, submit_time, program_name, sql_pool_name, start_time, end_time FROM queryinsights.exec_requests_history WHERE distributed_statement_id = '<Statement ID>';
Tilbakestill konfigurasjonen av de tilpassede SQL-poolene
For å returnere arbeidsområdet til opprinnelig tilstand, endre egenskapen customSQLPoolsEnabled til False. Hvis du vil bevare den egendefinerte SQL-poolkonfigurasjonen, må du sende inn hvert poolnavn som i customSQLPools listen.
Dette eksempel-Python-koden deaktiverer egendefinerte SQL-pooler og går tilbake til den autonome workload management-konfigurasjonen for SELECT og ikke-poolerSELECT . En PATCH forespørsel kalles med egenskapen customSQLPoolsEnabled satt til False.
import requests
import json
from notebookutils import mssparkutils
body = {
"customSQLPoolsEnabled": False,
"customSQLPools": []
}
# This will get the workspaceId where this notebook is running.
# Update to the workspace_id (guid) if running this notebook outside of the workspace where the warehouse exists.
workspace_id = mssparkutils.runtime.context.get('currentWorkspaceId')
url = f'https://api.fabric.microsoft.com/v1/workspaces/{workspace_id}/warehouses/sqlPoolsConfiguration?beta=true'
response = requests.request(method='patch', url=url, json=body, headers={'Authorization': f'Bearer {mssparkutils.credentials.getToken("pbi")}'})
if response.status_code == 200:
print("SQL Custom Pools successfully disabled.")
else:
print(response.text)