Merk
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
Med speiling i Fabric kan du enkelt unngå kompliserte ETL-prosesser (Extract, Transform, Load) og sømløst integrere eksisterende Google BigQuery-lagerdata med resten av dataene dine i Fabric. Du kan kontinuerlig replikere Google BigQuery-dataene dine direkte til Fabrics OneLake. Når du er i Fabric, kan du dra nytte av kraftige funksjoner for forretningsanalyse, kunstig intelligens, datateknikk, datavitenskap og datadeling.
For en veiledning om hvordan du konfigurerer din Google BigQuery-database for speiling i Fabric, se Tutorial: Konfigurer Microsoft Fabric speilede databaser fra Google BigQuery.
Viktig!
Speiling for Google BigQuery er nå i forhåndsversjon. Produksjonsarbeidsbelastninger støttes ikke i forhåndsversjon.
Hvorfor bruke speiling i Fabric?
Speiling i Microsoft Fabric fjerner kompleksiteten ved å sette sammen verktøy fra ulike leverandører. Du trenger ikke å overføre dataene dine. Koble til Google BigQuery-dataene dine i nær sanntid for å bruke Fabric-analyseverktøyene. Fabric fungerer også sømløst med Microsoft-produkter, Google BigQuery og et bredt spekter av teknologier som støtter Delta Lake-tabellformatet med åpen kildekode.
Hvilke analyseopplevelser er innebygd?
Speiling oppretter to elementer i Fabric-arbeidsområdet:
- Det speilvendte databaseelementet. Speiling administrerer replikeringen av data til OneLake og konvertering til Parquet, i et analyseklart format. Speiling muliggjør nedstrømsscenarioer som datateknikk, datavitenskap og mer. Speilede databaser skiller seg fra lager- og SQL Analytics-endepunktelementer.
- Et SQL-analyseendepunkt
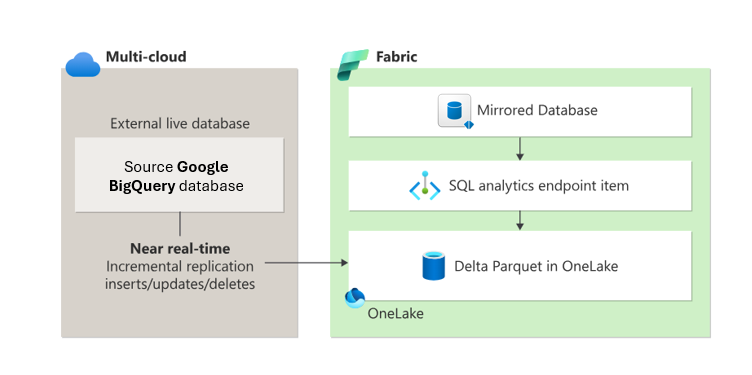
Fra hver speilede database leverer et SQL-analyseendepunkt en skrivebeskyttet analytisk opplevelse på toppen av Delta-tabellene som opprettes under speiling. Dette endepunktet støtter T-SQL-syntaks for å definere og spørre etter dataobjekter, men det tillater ikke direkte dataendringer siden dataene er skrivebeskyttet.
Med SQL-analyseendepunktet kan du:
- Bla gjennom tabeller som refererer til Delta Lake-dataene dine speilet fra BigQuery.
- Bygg kodefrie spørringer og visninger, og utforsk data visuelt – ingen SQL kreves.
- Opprett SQL-visninger, innebygde tabellverdifunksjoner (TVF-er) og lagrede prosedyrer for å legge inn forretningslogikk med T-SQL.
- Angi og administrer tillatelser for objekter.
- Spør etter data i andre lagre og innsjøhus i samme arbeidsområde.
I tillegg til SQL-spørringseditoren, finnes det et bredt økosystem av verktøy som kan spørre SQL-analyseendepunktet, inkludert SQL Server Management Studio (SSMS), MSSQL-utvidelsen for Visual Studio Code, og til og med GitHub Copilot.
Sikkerhetshensyn
Det er spesifikke krav til brukertillatelser for å aktivere Fabric Mirroring.
Fabric tilbyr også databeskyttelsesfunksjoner for å administrere tilgang i Microsoft Fabric. Hvis du vil ha mer informasjon, kan du se dokumentasjonen for databeskyttelsesfunksjoner.
Kostnadsvurderinger for speilet BigQuery
Fabric-databehandlingen som brukes til å replikere dataene dine til Fabric OneLake, er gratis. Lagringskostnaden for speiling er gratis opp til en grense basert på kapasitet. Beregningen for å spørre data med SQL, Power BI eller Spark belastes med vanlige satser.
Fabric tar ikke betalt for inngangsgebyrer for nettverksdata i OneLake for speiling.
Det er Google BigQuery-databehandlings- og skysøkekostnader når data speiles: BigQuery Change Data Capture (CDC) bruker BigQuery-databehandling for radendring, Storage Write API for datainntak og BigQuery-lagring for datalagring som alle medfører kostnader.
Hvis du vil ha mer informasjon om kostnadene ved speiling av Google BigQuery, kan du se de forklarte prisene.