Obs!
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
Dette scenarioet viser hvordan du kobler til OneLake via Azure Databricks. Når du har fullført denne opplæringen, kan du lese og skrive til et Microsoft Fabric lakehouse fra Azure Databricks-arbeidsområdet.
Forutsetning
Før du kobler til, må du ha:
- Et stoffarbeidsområde og lakehouse.
- Et premium Azure Databricks-arbeidsområde. Bare premium Azure Databricks-arbeidsområder støtter Microsoft Entra-legitimasjonsforsendelse, som du trenger for dette scenarioet.
Konfigurere Databricks-arbeidsområdet
Åpne Azure Databricks-arbeidsområdet, og velg Opprett>klynge.
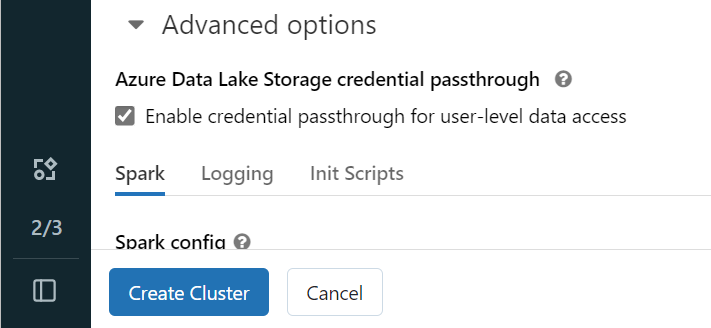
Hvis du vil godkjenne OneLake med Microsoft Entra-identiteten din, må du aktivere legitimasjonsoversigelse for Azure Data Lake Storage (ADLS) på klyngen i avanserte alternativer.
Merk
Du kan også koble Databricks til OneLake ved hjelp av en tjenestekontohaver. Hvis du vil ha mer informasjon om godkjenning av Azure Databricks ved hjelp av en tjenestekontohaver, kan du se Administrere tjenestekontohavere.
Opprett klyngen med de foretrukne parameterne. Hvis du vil ha mer informasjon om hvordan du oppretter en Databricks-klynge, kan du se Konfigurere klynger – Azure Databricks.
Åpne en notatblokk og koble den til den nyopprettede klyngen.
Redigere notatblokken
Gå til Fabric Lakehouse og kopier Azure Blob Filesystem (ABFS)-banen til lakehouse. Du finner den i Egenskaper-ruten.
Merk
Azure Databricks støtter bare Azure Blob Filesystem (ABFS)-driveren når du leser og skriver til ADLS Gen2 og OneLake:
abfss://myWorkspace@onelake.dfs.fabric.microsoft.com/.Lagre banen til lakehouse i Databricks-notatblokken. Dette lakehouse er der du skriver dine behandlede data senere:
oneLakePath = 'abfss://myWorkspace@onelake.dfs.fabric.microsoft.com/myLakehouse.lakehouse/Files/'Last inn data fra et datasett for databricks i en dataramme. Du kan også lese en fil fra andre steder i Fabric eller velge en fil fra en annen ADLS Gen2-konto du allerede eier.
yellowTaxiDF = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/databricks-datasets/nyctaxi/tripdata/yellow/yellow_tripdata_2019-12.csv.gz")Filtrere, transformere eller klargjøre dataene. I dette scenarioet kan du trimme ned datasettet for raskere innlasting, bli med i andre datasett eller filtrere ned til bestemte resultater.
filteredTaxiDF = yellowTaxiDF.where(yellowTaxiDF.fare_amount<4).where(yellowTaxiDF.passenger_count==4) display(filteredTaxiDF)Skriv den filtrerte datarammen til Fabric Lakehouse ved hjelp av OneLake-banen.
filteredTaxiDF.write.format("csv").option("header", "true").mode("overwrite").csv(oneLakePath)Test at dataene ble skrevet ved å lese den nylig innlastede filen.
lakehouseRead = spark.read.format('csv').option("header", "true").load(oneLakePath) display(lakehouseRead.limit(10))
Gratulerer. Nå kan du lese og skrive data i Fabric ved hjelp av Azure Databricks.