Koble til til SAP HANA-datakilder ved hjelp av DirectQuery i Power BI
Du kan koble til SAP HANA-datakilder direkte ved hjelp av DirectQuery. Det finnes to alternativer når du kobler til SAP HANA:
Behandle SAP HANA som en flerdimensjonal kilde (standard): I dette tilfellet er virkemåten lik når Power BI kobler til andre flerdimensjonale kilder som SAP Business Warehouse eller Analysis Services. Når du kobler til SAP HANA ved hjelp av denne innstillingen, velges en enkelt analytisk visning eller beregningsvisning, og alle mål, hierarkier og attributter for denne visningen er tilgjengelige i feltlisten. Etter hvert som visualobjekter opprettes, hentes alltid de samlede dataene fra SAP HANA. Denne teknikken er den anbefalte fremgangsmåten, og er standard for nye DirectQuery-rapporter over SAP HANA.
Behandle SAP HANA som en relasjonskilde: I dette tilfellet behandler Power BI SAP HANA som en relasjonskilde. Denne tilnærmingen gir større fleksibilitet. Det må tas hensyn til denne tilnærmingen for å sikre at mål aggregeres som forventet, og for å unngå ytelsesproblemer.
Tilkoblingstilnærmingen bestemmes av et globalt verktøyalternativ, som angis ved å velge Filalternativer>og innstillinger og deretter Alternativer>for DirectQuery, og deretter velge alternativet Behandle SAP HANA som en relasjonskilde, som vist i illustrasjonen nedenfor.
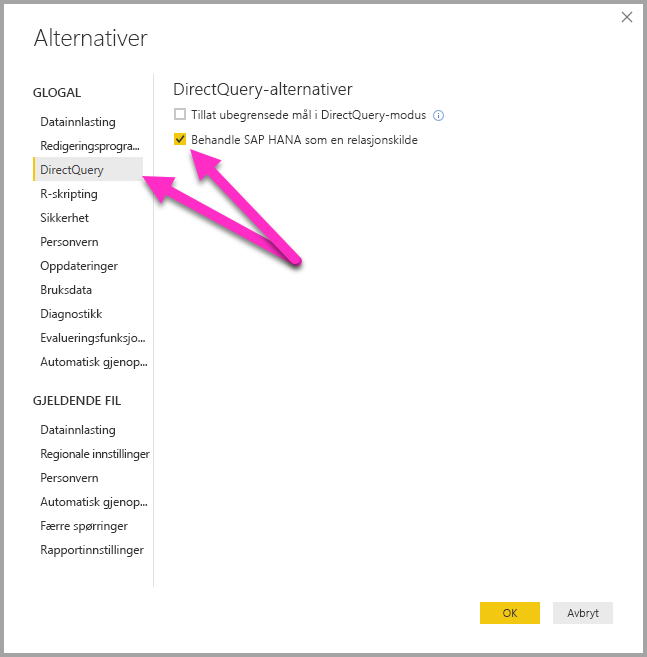
Alternativet for å behandle SAP HANA som en relasjonskilde styrer tilnærmingen som brukes for en ny rapport ved hjelp av DirectQuery over SAP HANA. Det har ingen innvirkning på eksisterende SAP HANA-tilkoblinger i den gjeldende rapporten, og heller ikke på tilkoblinger i andre rapporter som åpnes. Så hvis alternativet for øyeblikket ikke er avmerket, blir denne tilkoblingen behandlet SAP HANA som en flerdimensjonal kilde når du legger til en ny tilkobling til SAP HANA ved hjelp av Hent data. Men hvis en annen rapport åpnes som også kobler til SAP HANA, fortsetter denne rapporten å fungere i henhold til alternativet som ble angitt da den ble opprettet. Dette faktum betyr at alle rapporter som kobler til SAP HANA som ble opprettet før februar 2018, fortsetter å behandle SAP HANA som en relasjonskilde.
De to tilnærmingene utgjør forskjellig virkemåte, og det er ikke mulig å bytte en eksisterende rapport fra én tilnærming til den andre.
Behandle SAP HANA som en flerdimensjonal kilde (standard)
Alle nye tilkoblinger til SAP HANA bruker denne tilkoblingsmetoden som standard, og behandler SAP HANA som en flerdimensjonal kilde. Hvis du vil behandle en tilkobling til SAP HANA som en relasjonskilde, må du velge Alternativer for filalternativer>og innstillinger>, og deretter merke av i boksen under Behandle SAP HANA for direkte spørring>som relasjonskilde.
Når du kobler til SAP HANA som en flerdimensjonal kilde, gjelder følgende vurderinger:
I Hent datanavigator kan du velge én enkelt SAP HANA-visning. Det er ikke mulig å velge individuelle mål eller attributter. Det er ingen spørring definert på tidspunktet for tilkobling, som er forskjellig fra å importere data eller når du bruker DirectQuery mens du behandler SAP HANA som en relasjonskilde. Denne vurderingen betyr også at det ikke er mulig å bruke en SAP HANA SQL-spørring direkte når du velger denne tilkoblingsmetoden.
Alle mål, hierarkier og attributter i den valgte visningen vises i feltlisten.
Når et mål brukes i et visualobjekt, blir SAP HANA spurt om å hente målverdien på aggregasjonsnivået som er nødvendig for visualobjektet. Når du arbeider med ikke-additive mål, for eksempel tellere og forhold, utføres alle aggregasjoner av SAP HANA, og ingen ytterligere aggregasjon utføres av Power BI.
For å sikre at de riktige mengdeverdiene alltid kan hentes fra SAP HANA, må visse begrensninger pålegges. Det er for eksempel ikke mulig å legge til beregnede kolonner eller kombinere data fra flere SAP HANA-visninger i samme rapport.
Behandling av SAP HANA som en flerdimensjonal kilde gir ikke større fleksibilitet fra den alternative relasjonelle tilnærmingen, men det er enklere. Tilnærmingen sikrer også riktige aggregerte verdier når du arbeider med mer komplekse SAP HANA-mål, og resulterer vanligvis i høyere ytelse.
Feltlisten inneholder alle mål, attributter og hierarkier fra SAP HANA-visningen. Vær oppmerksom på følgende virkemåter som gjelder når du bruker denne tilkoblingsmetoden:
Alle attributter som er inkludert i minst ett hierarki, er skjult som standard. De kan imidlertid ses om nødvendig ved å velge Vis skjult fra hurtigmenyen i feltlisten. Fra samme hurtigmeny kan de gjøres synlige om nødvendig.
I SAP HANA kan et attributt defineres til å bruke et annet attributt som etikett. Produkt, med verdier
1, ,2og3så videre, kan for eksempel bruke ProductName, med verdierBike,Shirt,Glovesog så videre, som etikett. I dette tilfellet vises et enkelt felt produkt i feltlisten, der verdiene er etiketteneBike,Shirt,Glovesog så videre, men som er sortert etter, og med unikhet bestemt av, nøkkelverdiene1, ,23. En skjult kolonne Product.Key opprettes også, noe som gir tilgang til de underliggende nøkkelverdiene om nødvendig.
Alle variabler som er definert i den underliggende SAP HANA-visningen, vises på tidspunktet for tilkoblingen, og de nødvendige verdiene kan angis. Disse verdiene kan senere endres ved å velge Transformer data fra båndet, og deretter redigere parametere fra rullegardinmenyen som vises.
De tillatte modelleringsoperasjonene er mer restriktive enn i det generelle tilfellet når du bruker DirectQuery, gitt behovet for å sikre at riktige aggregerte data alltid kan hentes fra SAP HANA. Det er imidlertid fortsatt mulig å gjøre mange tillegg og endringer, inkludert å definere mål, gi nytt navn til og skjule felt og definere visningsformater. Alle slike endringer bevares ved oppdatering, og eventuelle ikke-motstridende endringer i SAP HANA-visningen brukes.
Flere modelleringsbegrensninger
De andre primære modelleringsbegrensningene når du kobler til SAP HANA ved hjelp av DirectQuery (behandle som flerdimensjonal kilde) er følgende begrensninger:
- Ingen støtte for beregnede kolonner: Muligheten til å opprette beregnede kolonner er deaktivert. Dette faktum betyr også at gruppering og klynger, som oppretter beregnede kolonner, ikke er tilgjengelige.
- Ytterligere begrensninger for mål: Det er andre begrensninger på DAX-uttrykkene som kan brukes i mål, for å gjenspeile støttenivået som tilbys av SAP HANA.
- Ingen støtte for å definere relasjoner: Bare én enkelt visning kan spørres i en rapport, og derfor er det ingen støtte for å definere relasjoner.
- Ingen datavisning: Datavisningen viser vanligvis data på detaljnivå i tabellene. Gitt olap-kilders natur, for eksempel SAP HANA, er ikke denne visningen tilgjengelig via SAP HANA.
- Kolonne- og måldetaljer er løst: Listen over kolonner og mål som vises i feltlisten, er løst av den underliggende kilden, og kan ikke endres. Det er for eksempel ikke mulig å slette en kolonne eller endre datatypen. Det kan imidlertid gis nytt navn.
- Flere begrensninger i DAX: Det finnes andre begrensninger på DAX som kan brukes i måldefinisjoner, for å gjenspeile begrensninger i kilden. Det er for eksempel ikke mulig å bruke en mengdefunksjon over en tabell.
Flere visualiseringsbegrensninger
Det finnes begrensninger i visualobjekter når du kobler til SAP HANA ved hjelp av DirectQuery (behandle som flerdimensjonal kilde):
- Ingen aggregasjon av kolonner: Det er ikke mulig å endre aggregasjonen for en kolonne på et visualobjekt, og det er alltid Ikke oppsummer.
Behandle SAP HANA som en relasjonskilde
Når du velger å koble til SAP HANA som en relasjonskilde, blir noe ekstra fleksibilitet tilgjengelig. Du kan for eksempel opprette beregnede kolonner, inkludere data fra flere SAP HANA-visninger og opprette relasjoner mellom de resulterende tabellene. Det er imidlertid forskjeller fra virkemåten når du behandler SAP HANA som en flerdimensjonal kilde, spesielt når SAP HANA-visningen inneholder ikke-additive mål, for eksempel distinkte antall eller gjennomsnitt, i stedet for enkle summer, og relatert til effektiviteten av spørringene som kjøres mot SAP HANA.
Det er nyttig å starte med å klargjøre virkemåten til en relasjonskilde, for eksempel SQL Server, når spørringen som er definert i Hent data eller Power Query-redigering utfører en aggregasjon. I eksemplet som følger, returnerer en spørring definert i Power Query-redigering gjennomsnittsprisen etter ProductID.
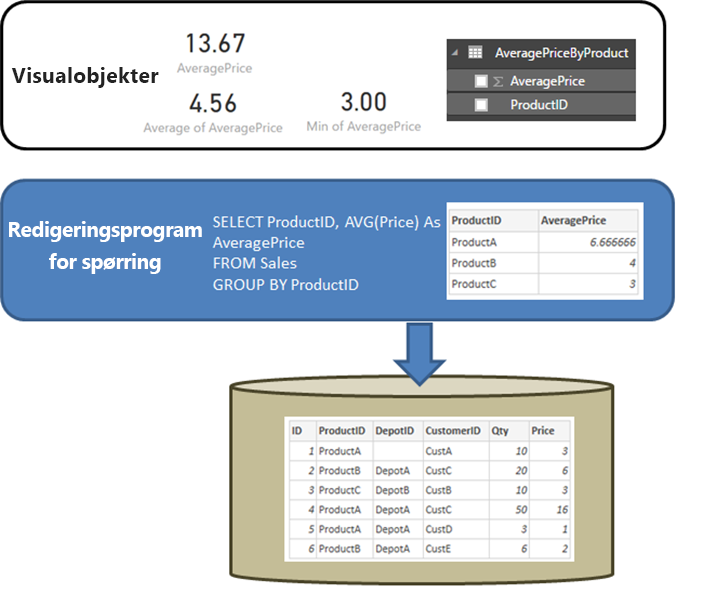
Hvis dataene importeres til Power BI kontra bruk av DirectQuery, vil følgende situasjon resultere:
- Dataene importeres på aggregasjonsnivået som er definert av spørringen som er opprettet i Power Query-redigering. For eksempel gjennomsnittspris etter produkt. Dette faktumet resulterer i en tabell med de to kolonnene ProductID og AveragePrice som kan brukes i visualobjekter.
- I et visualobjekt utføres eventuelle etterfølgende aggregasjoner, for eksempel Sum, Gjennomsnitt, Min og andre, over de importerte dataene. Inkludert Gjennomsnittspris på et visualobjekt bruker for eksempel summengden som standard, og returnerer summen over Gjennomsnittspris for hver Produkt-ID, i dette eksemplet 13,67. Det samme gjelder for alle alternative mengdefunksjoner, for eksempel Min eller Gjennomsnitt, som brukes på visualobjektet. Gjennomsnitt av Gjennomsnittspris returnerer for eksempel gjennomsnittet på 6,66, 4 og 3, som tilsvarer 4,56, og ikke gjennomsnittet av pris på de seks postene i den underliggende tabellen, som er 5,17.
Hvis DirectQuery over den samme relasjonskilden brukes i stedet for import, gjelder de samme semantikkene, og resultatene vil være nøyaktig de samme:
Gitt den samme spørringen presenteres logisk nøyaktig de samme dataene for rapporteringslaget – selv om dataene ikke faktisk er importert.
I et visualobjekt utføres alle etterfølgende aggregasjoner, for eksempel Sum, Gjennomsnitt og Min, på nytt over den logiske tabellen fra spørringen. Og igjen returnerer et visualobjekt som inneholder gjennomsnitt av Gjennomsnittspris de samme 4,56.
Vurder SAP HANA når tilkoblingen behandles som en relasjonskilde. Power BI kan arbeide med både analytiske visninger og beregningsvisninger i SAP HANA, som begge kan inneholde mål. Men i dag følger fremgangsmåten for SAP HANA de samme prinsippene som beskrevet tidligere i denne delen: spørringen som er definert i Hent data eller Power Query-redigering bestemmer dataene som er tilgjengelige, og deretter er eventuelle etterfølgende aggregasjoner i et visualobjekt over disse dataene, og det samme gjelder for både Import og DirectQuery. Men med tanke på SAP HANAs natur, er spørringen som er definert i den første dialogboksen Hent data eller Power Query-redigering alltid en aggregert spørring, og inkluderer vanligvis mål der den faktiske aggregasjonen som brukes, er definert av SAP HANA-visningen.
Tilsvarende for det forrige SQL Server-eksemplet er at det finnes en SAP HANA-visning som inneholder ID, ProductID, DepotID og mål, inkludert AveragePrice, definert i visningen som Gjennomsnitt av pris.
Hvis du er i Hent data-opplevelsen , var valgene som ble gjort for ProductID og AveragePrice-målet , så definerer det en spørring over visningen, og ber om at aggregerte data. I det tidligere eksemplet brukes pseudo-SQL for enkelhet som ikke samsvarer med den nøyaktige syntaksen for SAP HANA SQL. Deretter aggregerer eventuelle ytterligere aggregasjoner som er definert i et visualobjekt, ytterligere resultatene av en slik spørring. På nytt, som beskrevet tidligere for SQL Server, gjelder dette resultatet både for import- og DirectQuery-saken. I DirectQuery-tilfellet brukes spørringen fra Hent data eller Power Query-redigering i et undervalg i én enkelt spørring som sendes til SAP HANA, og dermed er det ikke tilfelle at alle dataene vil bli lest i, før du aggregerer videre.
Alle disse hensynene og virkemåtene krever følgende viktige hensyn når du bruker DirectQuery over SAP HANA:
Det må legges vekt på ytterligere aggregasjon som utføres i visualobjekter, når målet i SAP HANA ikke er additivt, for eksempel ikke en enkel Sum, Min eller Max.
I Hent data eller Power Query-redigering skal bare de nødvendige kolonnene inkluderes for å hente de nødvendige dataene, noe som gjenspeiler at resultatet er en spørring som må være en rimelig spørring som kan sendes til SAP HANA. Hvis for eksempel dusinvis av kolonner ble valgt, med tanke på at de kan være nødvendige på etterfølgende visualobjekter, betyr selv for DirectQuery at aggregeringsspørringen som brukes i undervalget, inneholder de dusinvis av kolonnene, som vanligvis yter dårlig.
I eksemplet nedenfor, velger du fem kolonner (CalendarQuarter, Color, LastName, ProductLine, SalesOrderNumber) i dialogboksen Hent data, sammen med målet OrderQuantity, betyr at senere oppretting av et enkelt visualobjekt som inneholder Min OrderQuantity resulterer i følgende SQL-spørring til SAP HANA. Den skyggelagte er undervalget, som inneholder spørringen fra Hent data /Power Query-redigering. Hvis dette undervalget gir et resultat med høy kardinalitet, vil den resulterende SAP HANA-ytelsen sannsynligvis være dårlig.

På grunn av denne virkemåten anbefaler vi at elementene som er valgt i Hent data eller Power Query-redigering være begrenset til de nødvendige elementene, samtidig som de resulterer i en rimelig spørring for SAP HANA.
Beste fremgangsmåter
For begge tilnærmingene til tilkobling til SAP HANA gjelder anbefalinger for bruk av DirectQuery også for SAP HANA, spesielt anbefalinger knyttet til å sikre god ytelse. Hvis du vil ha mer informasjon, kan du se bruke DirectQuery i Power BI.
Hensyn og begrensninger
Listen nedenfor beskriver alle SAP HANA-funksjoner som ikke støttes fullstendig, eller funksjoner som fungerer annerledes når du bruker Power BI.
- Overordnede underordnede hierarkier: Overordnede underordnede hierarkier er ikke synlige i Power BI. Dette faktum er at Power BI får tilgang til SAP HANA ved hjelp av SQL-grensesnittet, og overordnede underordnede hierarkier kan ikke nås fullt ut ved hjelp av SQL.
- Andre hierarkimetadata: Den grunnleggende strukturen i hierarkier vises i Power BI, men enkelte hierarkimetadata, for eksempel kontroll av virkemåten til fillete hierarkier, har ingen effekt. Dette faktumet skyldes igjen begrensningene i SQL-grensesnittet.
- Koble til ion ved hjelp av SSL: Du kan koble til ved hjelp av Import og flerdimensjonal med TLS, men kan ikke koble til SAP HANA-forekomster som er konfigurert til å bruke TLS for relasjonskoblingen.
- Støtte for attributtvisninger: Power BI kan koble til analyse- og beregningsvisninger, men kan ikke koble direkte til attributtvisninger.
- Støtte for katalogobjekter: Power BI kan ikke koble til katalogobjekter.
- Endre til variabler etter publisering: Du kan ikke endre verdiene for noen SAP HANA-variabler direkte i Power Bi-tjeneste, etter at rapporten er publisert.
Kjente problemer
Listen nedenfor beskriver alle kjente problemer når du kobler til SAP HANA (DirectQuery) ved hjelp av Power BI.
SAP HANA-problem når spørring etter tellere og andre mål: Feil data returneres fra SAP HANA hvis du kobler til en analytisk visning, og et tellermål og et annet forholdsmål, inkluderes i samme visualobjekt. Dette problemet dekkes av SAP Note 2128928 (uventede resultater når du spør etter en beregnet kolonne og en teller). Forholdet er feil i dette tilfellet.
Flere Power BI-kolonner fra én SAP HANA-kolonne: For enkelte beregningsvisninger, der en SAP HANA-kolonne brukes i mer enn ett hierarki, viser SAP HANA kolonnen som to separate attributter. Denne fremgangsmåten resulterer i at to kolonner opprettes i Power BI. Disse kolonnene er imidlertid skjult som standard, og alle spørringer som involverer hierarkiene, eller kolonnene direkte, fungerer som de skal.
Relatert innhold
Hvis du vil ha mer informasjon om DirectQuery, kan du se følgende ressurser: