Hendelser
14. feb., 16 - 31. mars, 16
Med fire sjanser til å delta, kan du vinne en konferansepakke og komme deg til LIVE Grand Finale i Las Vegas
Finn ut merDenne nettleseren støttes ikke lenger.
Oppgrader til Microsoft Edge for å dra nytte av de nyeste funksjonene, sikkerhetsoppdateringene og den nyeste tekniske støtten.
I Power BI Desktop eller Power Bi-tjeneste kan du koble til mange forskjellige datakilder på forskjellige måter. Du kan importere data til Power BI, som er den vanligste måten å hente data på. Du kan også koble direkte til noen data i det opprinnelige kilderepositoriet, som kalles DirectQuery. Denne artikkelen tar hovedsakelig for seg DirectQuery-funksjoner.
Denne artikkelen beskriver:
Artikkelen fokuserer på DirectQuery-arbeidsflyten når du oppretter en rapport i Power BI Desktop, men dekker også tilkobling via DirectQuery i Power Bi-tjeneste.
Obs!
DirectQuery er også en funksjon i SQL Server Analysis Services. Denne funksjonen deler mange detaljer med DirectQuery i Power BI, men det er også viktige forskjeller. Denne artikkelen dekker hovedsakelig DirectQuery med Power BI, ikke SQL Server Analysis Services.
Hvis du vil ha mer informasjon om hvordan du bruker DirectQuery med SQL Server Analysis Services, kan du se Bruke sammensatte modeller i Power BI Desktop). Du kan også laste ned PDF DirectQuery i SQL Server 2016 Analysis Services.
Power BI kobler til et stort antall varierte datakilder, for eksempel:
Du kan importere data fra disse kildene til Power BI. For enkelte kilder kan du også koble til ved hjelp av DirectQuery. Hvis du vil ha et sammendrag av kildene som støtter DirectQuery, kan du se Power BI-datakilder. DirectQuery-aktiverte kilder er hovedsakelig kilder som kan levere god interaktiv spørringsytelse.
Du bør importere data til Power BI der det er mulig. Import drar nytte av Power BIs spørringsmotor med høy ytelse og gir en svært interaktiv, fullstendig utvalgt opplevelse.
Hvis du ikke kan nå målene dine ved å importere data, for eksempel hvis dataene endres ofte og rapporter må gjenspeile de nyeste dataene, bør du vurdere å bruke DirectQuery. DirectQuery er bare mulig når den underliggende datakilden kan gi interaktive spørringsresultater på mindre enn fem sekunder for en vanlig aggregeringsspørring, og kan håndtere den genererte spørringsbelastningen. Vurder nøye begrensningene og implikasjonene ved å bruke DirectQuery.
Power BI-import- og DirectQuery-funksjoner utvikler seg over tid. Endringer som gir mer fleksibilitet når du bruker importerte data, lar deg importere oftere, og eliminere noen av ulempene ved å bruke DirectQuery. Uavhengig av forbedringer er ytelsen til den underliggende datakilden en viktig vurdering når du bruker DirectQuery. Hvis en underliggende datakilde er treg, er bruk av DirectQuery for denne kilden utilgjengelig.
De følgende avsnittene dekker disse tre alternativene for å koble til data: import, DirectQuery og live-tilkobling. Resten av artikkelen fokuserer på DirectQuery.
Når du kobler til en datakilde som SQL Server og importerer data i Power BI Desktop, finnes følgende tilkoblingsbetingelser:
Når du først bruker Hent data, definerer hvert sett med tabeller du velger, en spørring som returnerer et sett med data. Du kan redigere disse spørringene før du laster inn dataene, for eksempel for å bruke filtre, aggregere dataene eller bli med i forskjellige tabeller.
Ved innlasting importeres alle dataene som er definert av spørringene, til Power BI-hurtigbufferen.
Hvis du bygger et visualobjekt i Power BI Desktop, spørres de bufrede dataene. Power BI-lageret sikrer at spørringen er rask, og at alle endringer i visualobjektet reflekteres umiddelbart.
Visualobjekter gjenspeiler ikke endringer i de underliggende dataene i datalageret. Du må importere på nytt for å oppdatere dataene.
Publisering av rapporten til Power Bi-tjeneste som en PBIX-fil oppretter og laster opp en semantisk modell som inneholder de importerte dataene. Deretter kan du planlegge dataoppdatering for å importere dataene daglig på nytt, for eksempel. Avhengig av plasseringen til den opprinnelige datakilden, kan det være nødvendig å konfigurere en lokal datagateway for oppdateringen.
Når du åpner en eksisterende rapport eller redigerer en ny rapport i Power Bi-tjeneste spør de importerte dataene på nytt, noe som sikrer interaktivitet.
Du kan feste visualobjekter eller hele rapportsider som instrumentbordfliser i Power Bi-tjeneste. Flisene oppdateres automatisk når den underliggende semantiske modellen oppdateres.
Når du bruker DirectQuery til å koble til en datakilde i Power BI Desktop, finnes følgende datatilkoblingsbetingelser:
Du bruker Hent data til å velge kilden. For relasjonskilder kan du fortsatt velge et sett med tabeller som definerer en spørring som logisk returnerer et sett med data. For flerdimensjonale kilder som SAP Business Warehouse (SAP BW) velger du bare kilden.
Ved innlasting importeres ingen data til Power BI-lageret. Når du bygger et visualobjekt, sender Power BI Desktop i stedet spørringer til den underliggende datakilden for å hente de nødvendige dataene. Tiden det tar for å oppdatere visualobjektet avhenger av ytelsen til den underliggende datakilden.
Eventuelle endringer i de underliggende dataene gjenspeiles ikke umiddelbart i eksisterende visualobjekter. Det er fortsatt nødvendig å oppdatere. Power BI Desktop sender de nødvendige spørringene på nytt for hvert visualobjekt, og oppdaterer visualobjektet etter behov.
Publisering av rapporten til Power Bi-tjeneste oppretter og laster opp en semantisk modell, det samme som for import. Den semantiske modellen inneholder imidlertid ingen data.
Når du åpner en eksisterende rapport eller redigerer en ny rapport i Power Bi-tjeneste spør den underliggende datakilden om å hente de nødvendige dataene. Avhengig av plasseringen til den opprinnelige datakilden, kan det være nødvendig å konfigurere en lokal datagateway for å hente dataene.
Du kan feste visualobjekter eller hele rapportsider som instrumentbordfliser. For å sikre at det er raskt å åpne et instrumentbord, oppdateres flisene automatisk etter en tidsplan, for eksempel hver time. Du kan kontrollere oppdateringsfrekvensen avhengig av hvor ofte dataene endres og viktigheten av å se de nyeste dataene.
Når du åpner et instrumentbord, gjenspeiler flisene dataene på tidspunktet for siste oppdatering, ikke nødvendigvis de siste endringene som er gjort i den underliggende kilden. Du kan oppdatere et åpent instrumentbord for å sikre at det er oppdatert.
Når du kobler til SQL Server Analysis Services, kan du velge å importere dataene eller bruke en live-tilkobling til den valgte datamodellen. Bruk av en live-tilkobling ligner på DirectQuery. Ingen data importeres, og den underliggende datakilden blir spurt om å oppdatere visualobjekter.
Når du for eksempel bruker import til å koble til SQL Server Analysis Services, definerer du en spørring mot den eksterne SQL Server Analysis Services-kilden og importerer dataene. Hvis du kobler til direkte, definerer du ikke en spørring, og hele den eksterne modellen vises i feltlisten.
Denne situasjonen gjelder også når du kobler til følgende kilder, bortsett fra at det ikke finnes noe alternativ for å importere dataene:
Semantiske Power BI-modeller, for eksempel å koble til en semantisk Power BI-modell som allerede er publisert til tjenesten, for å redigere en ny rapport over den.
Microsoft Dataverse.
Når du publiserer SQL Server Analysis Services-rapporter som bruker live-tilkoblinger, er virkemåten i Power Bi-tjeneste lik DirectQuery-rapporter på følgende måter:
Når du åpner en eksisterende rapport eller redigerer en ny rapport i Power Bi-tjeneste spør den underliggende SQL Server Analysis Services-kilden, som muligens krever en lokal datagateway.
Instrumentbordfliser oppdateres automatisk etter en tidsplan, for eksempel hver time.
En live-tilkobling skiller seg også fra DirectQuery på flere måter. Live-tilkoblinger sender for eksempel alltid identiteten til brukeren som åpner rapporten, til den underliggende SQL Server Analysis Services-kilden.
Tilkobling med DirectQuery kan være nyttig i følgende scenarioer. I flere av disse tilfellene er det nødvendig å la dataene være i den opprinnelige kildeplasseringen.
DirectQuery i Power BI gir de største fordelene i følgende scenarioer:
Du kan oppdatere modeller med importerte data maksimalt én gang per time, eller oftere med Power BI Pro- eller Power BI Premium-abonnementer. Hvis dataene kontinuerlig endres, og det er nødvendig for rapporter å vise de nyeste dataene, kan det hende at import med planlagt oppdatering ikke oppfyller dine behov. Du kan strømme data direkte til Power BI, selv om det er begrensninger på datavolumene som støttes for dette tilfellet.
Bruk av DirectQuery betyr at åpning eller oppdatering av en rapport eller et instrumentbord alltid viser de nyeste dataene i kilden. Instrumentbordflisene kan også oppdateres oftere, så ofte som hvert 15. minutt.
Hvis dataene er svært store, er det ikke mulig å importere alt. DirectQuery krever ingen stor overføring av data, fordi den spør etter data på plass. Store data kan imidlertid også gjøre ytelsen til spørringer mot den underliggende kilden for treg.
Du trenger ikke alltid å importere fullstendige, detaljerte data. Den Power Query-redigering gjør det enkelt å forhåndssamlede data under import. Teknisk sett er det mulig å importere nøyaktig de aggregerte dataene du trenger for hvert visualobjekt. Selv om DirectQuery er den enkleste tilnærmingen til store data, kan import av aggregerte data tilby en løsning hvis den underliggende datakilden er for treg for DirectQuery.
Disse detaljene er knyttet til bruk av Power BI alene. Hvis du vil ha mer informasjon om hvordan du bruker store modeller i Power BI, kan du se store semantiske modeller i Power BI Premium. Det er ingen begrensninger på hvor ofte dataene kan oppdateres.
Når du importerer data, kobler Power BI til datakilden ved hjelp av gjeldende brukers Power BI Desktop-legitimasjon, eller legitimasjonen som er konfigurert for planlagt oppdatering fra Power Bi-tjeneste. Når du publiserer og deler rapporter som har importerte data, må du være forsiktig med å dele bare med brukere som har tillatelse til å se dataene, eller du må definere sikkerhet på radnivå som en del av den semantiske modellen.
DirectQuery lar legitimasjonen til en rapportvisning gå gjennom til den underliggende kilden, som bruker sikkerhetsregler. DirectQuery støtter enkel pålogging (SSO) til Azure SQL-datakilder, og gjennom en datagateway til lokale SQL-servere. Hvis du vil ha mer informasjon, kan du se Oversikt over enkel pålogging (SSO) for lokale datagatewayer i Power BI.
Noen organisasjoner har policyer rundt datasuverenitet, noe som betyr at data ikke kan forlate organisasjonens lokaler. Disse dataene presenterer problemer for løsninger basert på dataimport. Med DirectQuery forblir dataene på den underliggende kildeplasseringen. Selv med DirectQuery beholder Power Bi-tjeneste imidlertid noen buffere med data på visuelt nivå, på grunn av planlagt oppdatering av fliser.
En underliggende datakilde, for eksempel SAP HANA eller SAP BW, inneholder mål. Mål betyr at importerte data allerede er på et bestemt nivå av aggregasjon, som definert av spørringen. Et visualobjekt som ber om data på et samlet nivå på høyere nivå, for eksempel TotalSalg etter år, aggregerer den aggregerte verdien ytterligere. Denne aggregasjonen er bra for additive mål, for eksempel Sum og Min, men kan være et problem for ikke-additive mål, for eksempel Gjennomsnitt og DistinctCount.
Enkelt å få de riktige aggregerte dataene som kreves for et visualobjekt direkte fra kilden, krever sending av spørringer per visualobjekt, som i DirectQuery. Når du kobler til SAP BW, tillater valg av DirectQuery denne behandlingen av mål. Hvis du vil ha mer informasjon, kan du se DirectQuery og SAP BW.
DirectQuery over SAP HANA behandler data på samme måte som en relasjonskilde, og produserer virkemåte som ligner på import. Hvis du vil ha mer informasjon, kan du se DirectQuery og SAP HANA.
Bruk av DirectQuery har noen potensielt negative implikasjoner. Noen av disse begrensningene varierer litt avhengig av den nøyaktige kilden du bruker. Avsnittene nedenfor viser generelle implikasjoner ved bruk av DirectQuery, og begrensninger knyttet til ytelse, sikkerhet, transformasjoner, modellering og rapportering.
Noen generelle implikasjoner og begrensninger ved bruk av DirectQuery følger:
Hvis dataene endres, må du oppdatere for å vise de nyeste dataene. Gitt bruken av hurtigbuffere, er det ingen garanti for at visualobjekter alltid viser de nyeste dataene. Et visualobjekt kan for eksempel vise transaksjoner den siste dagen. En slicerendring kan oppdatere visualobjektet for å vise transaksjoner de siste to dagene, inkludert nylige, nylig ankomne transaksjoner. Men å returnere sliceren til den opprinnelige verdien kan føre til at den igjen viser den hurtigbufrede forrige verdien. Velg Oppdater for å fjerne eventuelle hurtigbuffere og oppdatere alle visualobjektene på siden for å vise de nyeste dataene.
Hvis dataene endres, er det ingen garanti for konsekvens mellom visualobjekter. Ulike visualobjekter, enten på samme side eller på forskjellige sider, kan oppdateres på forskjellige tidspunkter. Hvis dataene i den underliggende kilden endres, er det ingen garanti for at hvert visualobjekt viser dataene samtidig.
Gitt at mer enn én spørring kan være nødvendig for et enkelt visualobjekt, for eksempel for å få detaljene og totalsummene, er ikke selv konsekvens i ett enkelt visualobjekt garantert. For å garantere denne konsistensen må du oppdatere alle visualobjekter når et visualobjekt oppdateres, sammen med å bruke kostbare funksjoner som øyeblikksbildeisolering i den underliggende datakilden.
Du kan redusere dette problemet i stor grad ved å velge Oppdater for å oppdatere alle visualobjektene på siden. Selv for importmodus er det et lignende problem med å opprettholde konsekvens når du importerer data fra mer enn én tabell.
Du må oppdatere i Power BI Desktop for å gjenspeile skjemaendringer. Når en rapport er publisert, oppdaterer Oppdater i Power Bi-tjeneste visualobjektene i rapporten. Men hvis det underliggende kildeskjemaet endres, oppdaterer ikke Power Bi-tjeneste listen over tilgjengelige felt automatisk. Hvis tabeller eller kolonner fjernes fra den underliggende kilden, kan det føre til at spørringen mislykkes ved oppdatering. Hvis du vil oppdatere feltene i modellen for å gjenspeile endringene, må du åpne rapporten i Power BI Desktop og velge Oppdater.
En grense på 1 million rader kan returneres på en spørring. Det er en fast grense på 1 million rader som kan returneres i én enkelt spørring til den underliggende kilden. Denne grensen har vanligvis ingen praktiske implikasjoner, og visualobjekter viser ikke så mange punkter. Grensen kan imidlertid oppstå i tilfeller der Power BI ikke optimaliserer spørringene som sendes fullstendig, og ber om et mellomliggende resultat som overskrider grensen.
Grensen kan også forekomme når du bygger et visualobjekt, på veien til en mer fornuftig endelig tilstand. For eksempel kan inkludert Kunde og TotalSalgQuantity treffe denne grensen hvis det er mer enn 1 million kunder, til du bruker et filter. Feilen som returnerer er: Resultatsettet for en spørring til ekstern datakilde har overskredet den maksimale tillatte størrelsen på '1000000'-rader.
Obs!
Premium-kapasiteter lar deg overskride grensen på én million rader. Hvis du vil ha mer informasjon, kan du se Maksimalt antall mellomliggende radsett.
Du kan ikke endre en modell fra import til DirectQuery-modus. Du kan bytte en modell fra DirectQuery-modus til importmodus hvis du importerer alle nødvendige data. Det er ikke mulig å bytte tilbake til DirectQuery-modus, hovedsakelig på grunn av funksjonssettet som DirectQuery-modus ikke støtter. For flerdimensjonale kilder som SAP BW kan du heller ikke bytte fra DirectQuery til importmodus på grunn av den ulike behandlingen av eksterne mål.
Når du bruker DirectQuery, avhenger den generelle opplevelsen av ytelsen til den underliggende datakilden. Hvis oppdatering av hvert visualobjekt, for eksempel etter å ha endret en slicerverdi, tar mindre enn fem sekunder, er opplevelsen rimelig, selv om det kan føles tregt sammenlignet med umiddelbar respons med importerte data. Hvis kildens treghet fører til at individuelle visualobjekter tar lengre tid enn titalls sekunder å oppdatere, blir opplevelsen urimelig dårlig. Spørringer kan til og med bli tidsavbrutt.
Sammen med ytelsen til den underliggende kilden påvirker belastningen på kilden også ytelsen. Hver bruker som åpner en delt rapport, og hver instrumentbordflis som oppdateres, sender minst én spørring per visualobjekt til den underliggende kilden. Kilden må kunne håndtere en slik spørringsbelastning samtidig som den opprettholder rimelig ytelse.
Med mindre den underliggende datakilden bruker SSO, bruker en DirectQuery-rapport alltid den samme faste legitimasjonen til å koble til kilden når den er publisert til Power Bi-tjeneste. Umiddelbart etter at du har publisert en DirectQuery-rapport, må du konfigurere legitimasjonen til brukeren som skal brukes. Inntil du konfigurerer legitimasjonen, vil det å prøve å åpne rapporten i Power Bi-tjeneste resultere i en feil.
Når du har angitt brukerlegitimasjonen, bruker Power BI denne legitimasjonen for den som åpner rapporten, det samme som for importerte data. Hver bruker ser de samme dataene, med mindre sikkerhet på radnivå er definert som en del av rapporten. Du må være oppmerksom på å dele rapporten som for importerte data, selv om det er sikkerhetsregler definert i den underliggende kilden.
Tilkobling til Semantiske Modeller for Power BI og Analysis Services i DirectQuery-modus bruker alltid SSO, slik at sikkerheten ligner på live-tilkoblinger til Analysis Services.
Alternativ legitimasjon støttes ikke når du oppretter DirectQuery-tilkoblinger til SQL Server fra Power BI Desktop. Du kan bruke gjeldende Windows-legitimasjon eller databaselegitimasjon.
Du kan bruke flere datakilder i en DirectQuery-modell ved hjelp av sammensatte modeller. Når du bruker flere datakilder, er det viktig å forstå sikkerhetsimplikasjonene av hvordan data flyttes frem og tilbake mellom de underliggende datakildene.
DirectQuery begrenser datatransformasjonene du kan bruke i Power Query-redigering. Med importerte data kan du enkelt bruke et avansert sett med transformasjoner for å rense og omforme dataene før du bruker dem til å opprette visualobjekter. Du kan for eksempel analysere JSON-dokumenter eller pivotere data fra en kolonne til et radskjema. Disse transformasjonene er mer begrenset i DirectQuery.
Når du kobler til en OLAP-kilde (Online Analytical Processing), for eksempel SAP BW, kan du ikke definere transformasjoner, og hele den eksterne modellen hentes fra kilden. For relasjonskilder som SQL Server kan du fortsatt definere et sett med transformasjoner per spørring, men disse transformasjonene er begrenset av ytelsesårsaker.
Alle transformasjoner må brukes på hver spørring til den underliggende kilden, i stedet for én gang på dataoppdatering. Transformasjoner må kunne oversettes til én enkelt opprinnelig spørring. Hvis du bruker en transformasjon som er for kompleks, får du en feilmelding om at den enten må slettes, eller at tilkoblingsmodellen må byttes til import.
Dialogboksen Hent data eller Power Query-redigering bruke undervalg i spørringene de genererer og sender for å hente data for et visualobjekt. Spørringer definert i Power Query-redigering må være gyldige i denne konteksten. Spesielt er det ikke mulig å bruke en spørring med vanlige tabelluttrykk, og heller ikke en som aktiverer lagrede prosedyrer.
Termmodellering i denne konteksten betyr at rådataene blir mer presisert og beriket som en del av redigeringen av en rapport ved hjelp av dataene. Eksempler på modellering inkluderer:
Du kan fortsatt gjøre mange av disse modellberikelsene når du bruker DirectQuery, og bruke prinsippet om å berike rådataene for å forbedre senere forbruk. Noen modelleringsfunksjoner er imidlertid ikke tilgjengelige eller er begrenset med DirectQuery. Begrensningene brukes for å unngå ytelsesproblemer.
Følgende begrensninger er felles for alle DirectQuery-kilder. Flere begrensninger kan gjelde for individuelle kilder.
Ingen innebygd datohierarki: Med importerte data har hver dato/datetime-kolonne også et innebygd datohierarki tilgjengelig som standard. Hvis du for eksempel importerer en tabell med salgsordrer som inneholder en kolonne Ordredato, og du bruker Ordredato i et visualobjekt, kan du velge riktig datonivå som skal brukes, for eksempel år, måned eller dag. Dette innebygde datohierarkiet er ikke tilgjengelig med DirectQuery. Hvis det finnes en datotabell i den underliggende kilden, som er vanlig i mange datalagre, kan du bruke tidsintelligensfunksjonene for dataanalyseuttrykk (DAX) som vanlig.
Støtte for dato/klokkeslett bare til sekundersnivå: For semantiske modeller som bruker tidskolonner, utsteder Power BI spørringer til den underliggende DirectQuery-kilden bare opptil sekunders detaljnivå, ikke millisekunder. Fjern millisekunders data fra kildekolonnene.
Begrensninger i beregnede kolonner: Beregnede kolonner kan bare være intrarad, det vil være at de bare kan referere til verdier i andre kolonner i samme tabell, uten å bruke mengdefunksjoner. Også de tillatte DAX-skalarfunksjonene, for eksempel LEFT(), er begrenset til de funksjonene som kan overføres til den underliggende kilden. Funksjonene varierer avhengig av de nøyaktige egenskapene til kilden. Funksjoner som ikke støttes, er ikke oppført i autofullfør når du redigerer DAX-spørringen for en beregnet kolonne, og resulterer i en feil hvis den brukes.
Ingen støtte for OVERORDNEDE-underordnede DAX-funksjoner: Når du er i DirectQuery-modus, er det ikke mulig å bruke familien av DAX PATH() funksjoner som vanligvis håndterer overordnede-underordnede strukturer, for eksempel diagrammer over kontoer eller ansatthierarkier.
Ingen klynger: Når du bruker DirectQuery, kan du ikke bruke klyngefunksjonen til automatisk å finne grupper.
Nesten alle rapporteringsfunksjoner støttes for DirectQuery-modeller. Så lenge den underliggende kilden tilbyr et passende ytelsesnivå, kan du bruke samme sett med visualiseringer som for importerte data.
En generell begrensning er at den maksimale lengden på data i en tekstkolonne for Semantiske DirectQuery-modeller er 32 764 tegn. Rapportering av lengre tekster resulterer i en feil.
Følgende funksjoner for Power BI-rapportering kan forårsake ytelsesproblemer i DirectQuery-baserte rapporter:
Målfiltre: Visualobjekter som bruker mål eller aggregater av kolonner, kan inneholde filtre i disse målene. Grafikken nedenfor viser for eksempel SalesAmount etter kategori, men bare for kategorier med mer enn 20 millioner salg.
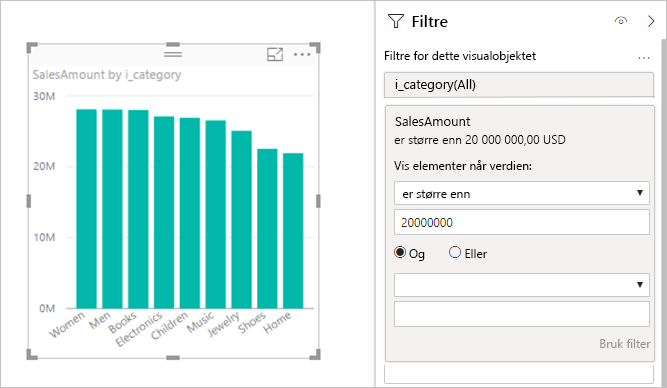
Denne tilnærmingen fører til at to spørringer sendes til den underliggende kilden:
WHERE betingelsen.Denne fremgangsmåten fungerer vanligvis bra hvis det finnes hundrevis eller tusenvis av kategorier, som i dette eksemplet. Ytelsen kan reduseres hvis antall kategorier er mye større. Spørringen mislykkes hvis det finnes mer enn en million kategorier.
TopN-filtre: Du kan definere avanserte filtre for å filtrere etter bare de øverste eller nederste N verdiene rangert etter noen mål. Filtre kan for eksempel inkludere de 10 beste kategoriene. Denne fremgangsmåten sender igjen to spørringer til den underliggende kilden. Den første spørringen returnerer imidlertid alle kategorier fra den underliggende kilden, og deretter bestemmes den TopN basert på de returnerte resultatene. Avhengig av kardinaliteten til kolonnen som er involvert, kan denne tilnærmingen føre til ytelsesproblemer eller spørringsfeil på grunn av grensen på én million rader for spørringsresultater.
Median: Alle aggregasjoner, for eksempel Sum eller Count Distinct, sendes til den underliggende kilden. Aggregatet støttes imidlertid median vanligvis ikke av den underliggende kilden. For medianhentes detaljdataene fra den underliggende kilden, og medianen beregnes fra de returnerte resultatene. Denne tilnærmingen er rimelig for å beregne medianen over et relativt lite antall resultater.
Ytelsesproblemer eller spørringsfeil kan oppstå hvis kardinaliteten er stor på grunn av grensen på én million rader. Spørring for medianland/områdepopulasjon kan for eksempel være rimelig, men median salgspris er kanskje ikke rimelig.
Avanserte tekstfiltre som "inneholder": Avansert filtrering på en tekstkolonne tillater filtre som contains og begins with. Disse filtrene kan føre til redusert ytelse for enkelte datakilder. Ikke bruk standardfilteret contains hvis du trenger et nøyaktig treff. Selv om resultatene kan være de samme avhengig av de faktiske dataene, kan ytelsen være drastisk forskjellig på grunn av indekser.
Flervalgsslicere: Som standard tillater slicere bare å gjøre ett enkelt valg. Hvis du tillater flervalg i filtre, kan det føre til ytelsesproblemer. Hvis brukeren for eksempel velger 10 produkter av interesse, resulterer hvert nytt utvalg i spørringer som sendes til kilden. Selv om brukeren kan velge det neste elementet før spørringen fullføres, resulterer denne tilnærmingen i ekstra belastning på den underliggende kilden.
Totaler for tabellvisualobjekter: Tabeller og matriser viser totalsummer og delsummer som standard. I mange tilfeller må det å få verdiene for slike totaler sende separate spørringer til den underliggende kilden. Dette kravet gjelder når du bruker DistinctCount aggregasjon, eller i alle tilfeller som bruker DirectQuery over SAP BW eller SAP HANA. Du kan slå av slike totalsummer ved hjelp av Format-ruten .
Denne delen gir veiledning på høyt nivå om hvordan du kan bruke DirectQuery, gitt dens implikasjoner.
Valider at enkle visualobjekter oppdateres innen fem sekunder, noe som gir en rimelig interaktiv opplevelse. Hvis visualobjekter tar mer enn 30 sekunder å oppdatere, er det sannsynlig at ytterligere problemer etter rapportpublikasjonen vil gjøre løsningen ubrukelig.
Hvis spørringene er trege, kan du undersøke spørringene som sendes til den underliggende kilden, og årsaken til treg ytelse. Hvis du vil ha mer informasjon, kan du se Ytelsesdiagnose.
Denne artikkelen dekker ikke det brede utvalget av anbefalinger for databaseoptimalisering på tvers av det fullstendige settet med potensielle underliggende kilder. Følgende standard databasepraksis gjelder for de fleste situasjoner:
For bedre ytelse baserer du relasjoner på heltallskolonner i stedet for å bli med i kolonner med andre datatyper.
Opprett de aktuelle indeksene. Indeksoppretting betyr vanligvis å bruke kolonnelagerindekser i kilder som støtter dem, for eksempel SQL Server.
Oppdater eventuell nødvendig statistikk i kilden.
Når du definerer modellen, følger du denne veiledningen:
Unngå komplekse spørringer i Power Query-redigering. Power Query-redigering oversetter en kompleks spørring til én sql-spørring. Den ene spørringen vises i undervalget for hver spørring som sendes til tabellen. Hvis denne spørringen er kompleks, kan det føre til ytelsesproblemer for hver spørring som sendes. Du kan få den faktiske SQL-spørringen for et sett med trinn ved å høyreklikke det siste trinnet under Brukte trinn i Power Query-redigering og velge Vis opprinnelig spørring.
Hold mål enkle. I det minste i utgangspunktet begrenser du mål til enkle aggregater. Hvis målene fungerer på en tilfredsstillende måte, kan du definere mer komplekse mål, men vær oppmerksom på ytelsen.
Unngå relasjoner på beregnede kolonner. Power BI tillater ikke basering av relasjoner på flere kolonner som primærnøkkel eller sekundærnøkkel, i databaser der du må utføre sammenføyninger med flere kolonner. Den vanlige midlertidige løsningen er å kjede sammen kolonnene ved hjelp av en beregnet kolonne, og basere sammenføyningen på denne kolonnen.
Denne midlertidige løsningen er rimelig for importerte data, men for DirectQuery resulterer den i en sammenføyning i et uttrykk. Dette resultatet hindrer vanligvis bruk av indekser, og fører til dårlig ytelse. Den eneste midlertidige løsningen er å materialisere flere kolonner til én enkelt kolonne i den underliggende datakilden.
Unngå relasjoner på «uniqueidentifier»-kolonner. Power BI støtter ikke en uniqueidentifier datatype opprinnelig. Definering av en relasjon mellom uniqueidentifier kolonner resulterer i en spørring med en sammenføyning som involverer en avstøpning. Igjen fører denne tilnærmingen vanligvis til dårlig ytelse. Den eneste midlertidige løsningen er å materialisere kolonner av en alternativ type i den underliggende datakilden.
Skjul «til»-kolonnen i relasjoner. Kolonnen to i relasjoner er vanligvis primærnøkkelen i to tabellen. Denne kolonnen skal være skjult, men hvis den er skjult, vises den ikke i feltlisten og kan ikke brukes i visualobjekter. Ofte er kolonnene som relasjoner er basert på, faktisk systemkolonner, for eksempel surrogatnøkler i et datalager. Det er fortsatt best å skjule slike kolonner.
Hvis kolonnen har mening, introduserer du en beregnet kolonne som er synlig, og som har et enkelt uttrykk for å være lik primærnøkkelen, for eksempel:
ProductKey_PK (Destination of a relationship, hidden)
ProductKey (= [ProductKey_PK], visible)
ProductName
...
Undersøk alle beregnede kolonner og datatypeendringer. Du kan bruke beregnede tabeller når du bruker DirectQuery med sammensatte modeller. Disse funksjonene er ikke nødvendigvis skadelige, men de resulterer i spørringer som inneholder uttrykk i stedet for enkle referanser til kolonner. Disse spørringene kan føre til at indekser ikke brukes.
Unngå toveis kryssfiltrering på relasjoner. Bruk av toveis kryssfiltrering kan føre til spørringssetninger som ikke fungerer bra. Hvis du vil ha mer informasjon om toveis kryssfiltrering, kan du se Aktivere toveis kryssfiltrering for DirectQuery i Power BI Desktop, eller laste ned det toveis kryssfiltrerende hvitboken. Eksemplene i artikkelen er for SQL Server Analysis Services, men de grunnleggende punktene gjelder også for Power BI.
Eksperimenter med innstillingen Anta referanseintegritet. Innstillingen Anta referanseintegritet for relasjoner gjør det mulig for spørringer å bruke INNER JOIN i stedet OUTER JOIN for setninger. Denne veiledningen forbedrer vanligvis spørringsytelsen, selv om den avhenger av detaljene i datakilden.
Ikke bruk den relative datofiltreringen i Power Query-redigering. Det er mulig å definere relativ datofiltrering i Power Query-redigering. Du kan for eksempel filtrere til radene der datoen er de siste 14 dagene.
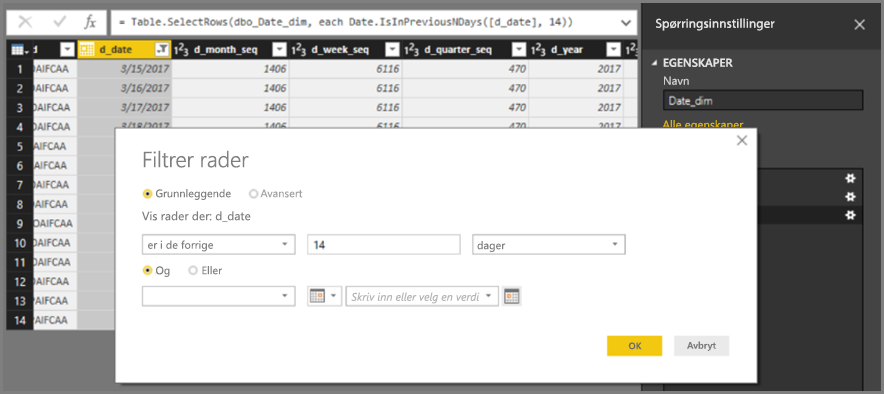
Dette filteret oversettes imidlertid til et filter basert på en fast dato, for eksempel tidspunktet da spørringen ble forfattet, som du kan se i den opprinnelige spørringen.

Disse dataene er sannsynligvis ikke det du ønsker. Hvis du vil sikre at filteret brukes basert på datoen da rapporten kjøres, bruker du datofilteret i rapporten. Du kan opprette en beregnet kolonne som beregner antall dager siden ved hjelp av funksjonen, og bruke den DAX DATE() beregnede kolonnen i filteret.
Når du oppretter en rapport som bruker en DirectQuery-tilkobling, følger du denne veiledningen:
Vurder å bruke alternativer for spørringsreduksjon: Power BI tilbyr rapportalternativer for å sende færre spørringer, og for å deaktivere bestemte interaksjoner som forårsaker en dårlig opplevelse hvis de resulterende spørringene tar lang tid å kjøre. Disse alternativene gjelder når du samhandler med rapporten i Power BI Desktop, og gjelder også når brukere bruker rapporten i Power Bi-tjeneste.
Hvis du vil ha tilgang til disse alternativene i Power BI Desktop, kan du gå til Alternativer for filalternativer>og velge Spørringsreduksjon.
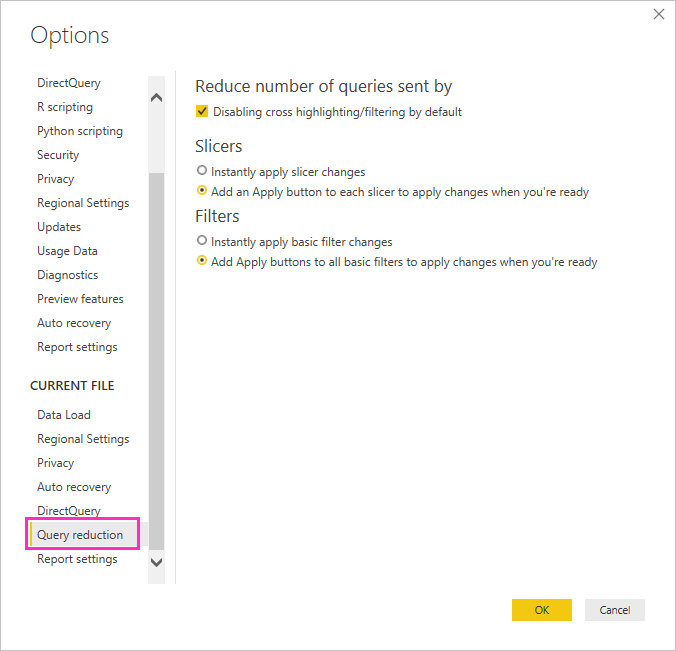
Valg på skjermbildet spørringsreduksjon lar deg vise en Bruk-knapp for slicere eller filtreringsvalg. Ingen spørringer sendes før du velger Bruk-knappen på filteret eller sliceren. Spørringene bruker deretter valgene dine til å filtrere dataene. Med denne knappen kan du foreta flere slicer- og filtreringsvalg før du bruker dem.
Bruk filtre først: Bruk alltid eventuelle gjeldende filtre i begynnelsen av byggingen av et visualobjekt. I stedet for å dra i TotalSalesAmount og ProductName, og deretter filtrere til et bestemt år, bruker du filteret på År i begynnelsen.
Hvert trinn i å bygge et visualobjekt sender en spørring. Selv om det er mulig å gjøre en ny endring før den første spørringen fullføres, etterlater denne tilnærmingen fortsatt unødvendig belastning på den underliggende kilden. Bruk av filtre tidlig gjør vanligvis disse mellomliggende spørringene mindre kostbare. Hvis du ikke bruker filtre tidlig, kan det føre til at grensen på én million rader blir nådd.
Begrens antall visualobjekter på en side: Når du åpner en side eller endrer en slicer eller et filter på sidenivå, oppdateres alle visualobjektene på siden. Det er en grense for antall parallelle spørringer. Etter hvert som antallet visualobjekter øker, oppdateres noen visualobjekter serielt, noe som øker tiden det tar å oppdatere siden. Derfor er det best å begrense antall visualobjekter på én enkelt side, og i stedet ha flere, enklere sider.
Vurder å slå av samhandling mellom visualobjekter: Visualiseringer på en rapportside kan som standard brukes til å kryssfiltrere og kryssutheve de andre visualiseringene på siden. Hvis du for eksempel velger 1999 i sektordiagrammet, er stolpediagrammet kryssuthevet for å vise salg etter kategori for 1999.
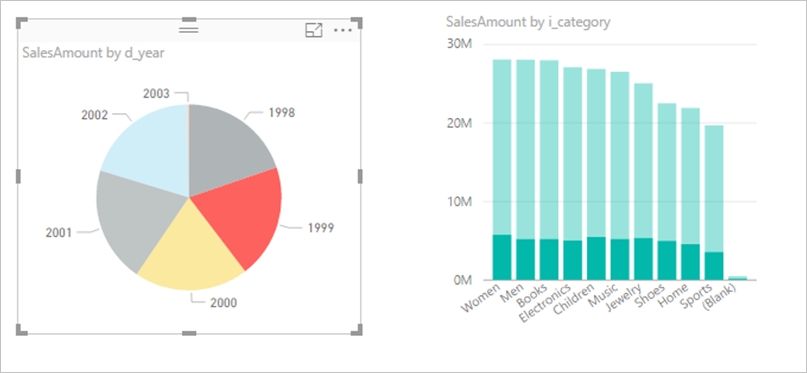
Kryssfiltrering og kryssutheving i DirectQuery krever at spørringer sendes til den underliggende kilden. Du bør slå av denne samhandlingen hvis tiden det tar å svare på brukernes valg, er urimelig lang.
Du kan bruke innstillingene for spørringsreduksjon til å deaktivere kryssutheving i hele rapporten, eller fra sak til sak. Hvis du vil ha mer informasjon, kan du se Hvordan visualobjekter kryssfiltrerer hverandre i en Power BI-rapport.
Du kan angi maksimalt antall tilkoblinger DirectQuery åpner for hver underliggende datakilde, som styrer antall spørringer som sendes samtidig til hver datakilde.
DirectQuery åpner et standard maksimumsantall på 10 samtidige tilkoblinger. Hvis du vil endre maksimalt antall for gjeldende fil i Power BI Desktop, går du til Alternativer for filog Innstillinger>, og velger > i Gjeldende fil-delen i den venstre ruten.
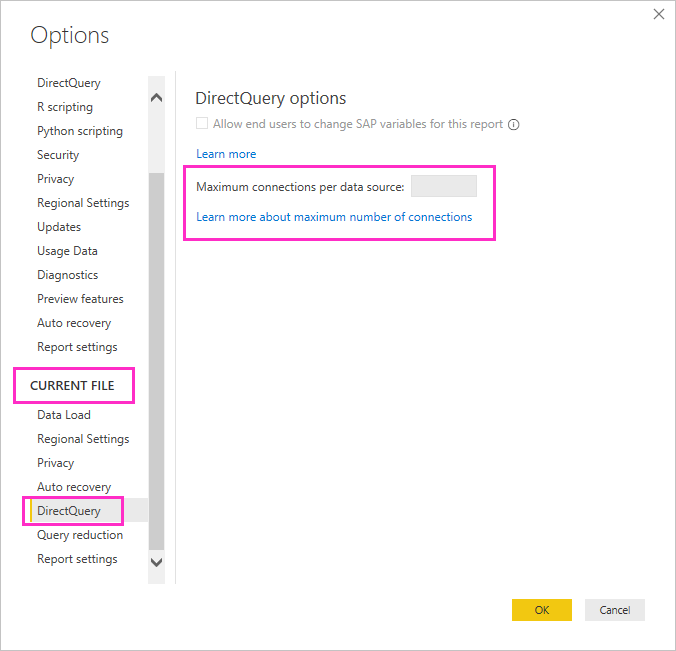
Innstillingen aktiveres bare når det er minst én DirectQuery-kilde i den gjeldende rapporten. Verdien gjelder for alle DirectQuery-kilder, og for eventuelle nye DirectQuery-kilder som er lagt til i denne rapporten.
Hvis du øker maksimalt antall tilkoblinger per datakilde , kan du sende flere spørringer, opptil det maksimale antallet som er angitt, til den underliggende datakilden. Denne fremgangsmåten er nyttig når mange visualobjekter er på én enkelt side, eller mange brukere får tilgang til en rapport samtidig. Når maksimalt antall tilkoblinger er nådd, legges ytterligere spørringer i kø til en tilkobling blir tilgjengelig. En høyere grense resulterer i mer belastning på den underliggende kilden, slik at innstillingen ikke garanteres for å forbedre den generelle ytelsen.
Når du publiserer en rapport til Power Bi-tjeneste, avhenger maksimalt antall samtidige spørringer også av faste grenser som er angitt for målmiljøet der rapporten publiseres. Power BI, Power BI Premium og rapportserver for Power BI innføre ulike grenser. Tabellen nedenfor viser de øvre grensene for de aktive tilkoblingene per datakilde for hvert Power BI-miljø. Disse grensene gjelder for datakilder i skyen og lokale datakilder, for eksempel SQL Server, Oracle og Teradata.
| Miljø | Øvre grense per datakilde |
|---|---|
| Power BI Pro | 10 aktive tilkoblinger |
| Power BI Premium | Avhenger av SKU-begrensning for semantisk modell |
| Power BI Report Server | 10 aktive tilkoblinger |
Obs!
Maksimalt antall DirectQuery-tilkoblingsinnstillinger gjelder for alle DirectQuery-kilder når du aktiverer forbedrede metadata, som er standardinnstillingen for alle modeller som er opprettet i Power BI Desktop.
Alle DirectQuery-datakilder støttes fra Power BI Desktop, og noen kilder er også tilgjengelige direkte fra Power Bi-tjeneste. En bedriftsbruker kan bruke Power BI til å koble til dataene sine i Salesforce, for eksempel, og umiddelbart få et instrumentbord, uten å bruke Power BI Desktop.
Bare følgende to DirectQuery-aktiverte kilder er tilgjengelige direkte i Power Bi-tjeneste:
Selv for disse to kildene er det fortsatt best å starte DirectQuery-bruk i Power BI Desktop. Selv om det er enkelt å starte tilkoblingen i Power Bi-tjeneste, er det begrensninger for ytterligere forbedring av den resulterende rapporten. I tjenesten er det for eksempel ikke mulig å opprette noen beregninger, eller bruke mange analytiske funksjoner, eller oppdatere metadataene for å gjenspeile endringer i det underliggende skjemaet.
Ytelsen til en DirectQuery-rapport i Power Bi-tjeneste avhenger av graden av belastning plassert på den underliggende datakilden. Belastningen avhenger av:
Når du åpner en rapport i Power Bi-tjeneste, oppdateres alle visualobjektene på den synlige sideoppdateringen. Hvert visualobjekt krever minst én spørring til den underliggende datakilden. Noen visualobjekter kan kreve mer enn én spørring. Et visualobjekt kan for eksempel vise aggregerte verdier fra to forskjellige faktatabeller, eller inneholde et mer komplekst mål, eller inneholde totaler av et ikke-additivt mål som Count Distinct. Hvis du flytter til en ny side, oppdateres disse visualobjektene. Oppdatering sender et nytt sett med spørringer til den underliggende kilden.
Hver brukers samhandling i rapporten kan føre til at visualobjekter oppdateres. Hvis du for eksempel velger en annen verdi på en slicer, må du sende et nytt sett med spørringer for å oppdatere alle de berørte visualobjektene. Det samme gjelder for å velge et visualobjekt for å kryssheve andre visualobjekter eller endre et filter. På samme måte krever oppretting eller redigering av en rapport at spørringer sendes for hvert trinn på banen for å produsere det endelige visualobjektet.
Det er noen hurtigbufring av resultater. Oppdateringen av et visualobjekt er øyeblikkelig hvis nøyaktig de samme resultatene nylig ble innhentet. Hvis sikkerhet på radnivå er definert, deles ikke disse hurtigbufferne på tvers av brukere.
Bruk av DirectQuery pålegger noen viktige begrensninger i noen av funksjonene Power Bi-tjeneste tilbyr for publiserte rapporter:
Hurtiginnsikter støttes ikke: Hurtiginnsikter i Power BI søker i ulike delsett av den semantiske modellen mens du bruker et sett med avanserte algoritmer for å oppdage potensielt interessant innsikt. Fordi rask innsikt krever spørringer med høy ytelse, er ikke denne funksjonen tilgjengelig på semantiske modeller som bruker DirectQuery.
Bruk av Utforsk i Excel gir dårlig ytelse: Du kan utforske en semantisk modell ved hjelp av funksjonen Utforsk i Excel , som lar deg opprette pivottabeller og pivotdiagrammer i Excel. Denne funksjonen støttes for semantiske modeller som bruker DirectQuery, men ytelsen er tregere enn å opprette visualobjekter i Power BI. Hvis du bruker Excel er viktig for scenarioene, må du ta hensyn til dette problemet når du skal avgjøre om du vil bruke DirectQuery.
Excel viser ikke hierarkier: Når du for eksempel bruker Analyser i Excel, viser ikke Excel noen hierarkier som er definert i Azure Analysis Services-modeller eller Power BI-semantiske modeller som bruker DirectQuery.
I Power Bi-tjeneste kan du feste individuelle visualobjekter eller hele sider til instrumentbord som fliser. Fliser som er basert på semantiske DirectQuery-modeller, oppdateres automatisk ved å sende spørringer til de underliggende datakildene etter en tidsplan. Semantiske modeller oppdateres som standard hver time, men du kan konfigurere intervallene for oppdateringsplan mellom ukentlig og hvert 15. minutt som en del av innstillingene for semantisk modell.
Hvis ingen sikkerhet på radnivå er definert i modellen, oppdateres hver flis én gang, og resultatene deles på tvers av alle brukere. Hvis du bruker sikkerhet på radnivå, krever hver flis at separate spørringer per bruker sendes til den underliggende kilden.
Det kan være en stor multiplikatoreffekt. Et instrumentbord med 10 fliser, delt med 100 brukere, opprettet på en semantisk modell ved hjelp av DirectQuery med sikkerhet på radnivå, resulterer i at minst 1000 spørringer sendes til den underliggende datakilden for hver oppdatering. Ta nøye hensyn til bruken av sikkerhet på radnivå og konfigurasjonen av oppdateringsplanen.
Et tidsavbrudd på fire minutter gjelder for individuelle spørringer i Power Bi-tjeneste. Spørringer som tar lengre tid enn fire minutter, mislykkes. Denne grensen er ment å forhindre problemer forårsaket av altfor lange kjøringstider. Du bør bare bruke DirectQuery for kilder som kan gi interaktiv spørringsytelse.
Når tidsavbruddsgrensen er nådd, lastes ikke visualobjekter inn med følgende feil: The query has exceeded the available resources. Try filtering to decrease the amount of data requested. The XML for Analysis request timed out before it was completed. Timeout value: 225 sec.
Denne delen beskriver hvordan du diagnostiserer ytelsesproblemer eller hvordan du får mer detaljert informasjon for å optimalisere rapportene.
Begynn å diagnostisere ytelsesproblemer i Power BI Desktop i stedet for i Power Bi-tjeneste. Ytelsesproblemer er ofte basert på ytelsen til den underliggende kilden. Du kan lettere identifisere og diagnostisere problemer i det mer isolerte Power BI Desktop-miljøet.
Denne fremgangsmåten eliminerer i utgangspunktet bestemte komponenter, for eksempel Power BI-gatewayen. Hvis ytelsesproblemene ikke oppstår i Power BI Desktop, kan du undersøke detaljene i rapporten i Power Bi-tjeneste.
Ytelsesanalyse i Power BI Desktop er et nyttig verktøy for å identifisere problemer. Prøv å isolere eventuelle problemer med ett visualobjekt, i stedet for mange visualobjekter på en side. Hvis et enkelt visualobjekt på en Power BI Desktop-side er treg, kan du bruke ytelsesanalysen til å analysere spørringene som Power BI Desktop sender til den underliggende kilden.
Du kan også vise sporinger og diagnosedata som enkelte underliggende datakilder avgir. Selv om det ikke finnes spor fra kilden, kan sporingsfilen inneholde nyttige detaljer om hvordan en spørring kjører og hvordan du kan forbedre den. Du kan bruke følgende prosess til å vise spørringene Power BI sender og kjøringstidene deres.
Som standard logger Power BI Desktop hendelser under en gitt økt til en sporingsfil kalt FlightRecorderCurrent.trc. Sporingsfilen er i Power BI Desktop-mappen for gjeldende bruker, i en mappe kalt AnalysisServicesWorkspaces.
For enkelte DirectQuery-kilder inneholder denne sporingsfilen alle spørringer som sendes til den underliggende datakilden. Følgende datakilder sender spørringer til loggen:
Du kan lese sporingsfilene ved hjelp av SQL Server Profiler, som er en del av den gratis nedlastingen av SQL Server Management Studio.
Slik åpner du sporingsfilen for gjeldende økt:
Velg Alternativer for filalternativer>og innstillinger under> en Power BI Desktop-økt, og velg deretter Diagnostikk.
Velg Åpne mappen krasjdump/sporing under Krasjdumpsamling.

Power BI Desktop\Traces-mappen åpnes.
Gå til den overordnede mappen og deretter til AnalysisServicesWorkspaces-mappen , som inneholder én arbeidsområdemappe for hver åpne forekomst av Power BI Desktop. Disse mappene er navngitt med et heltallssuffiks, for eksempel AnalysisServicesWorkspace2058279583. Arbeidsområdemappen slettes når den tilknyttede Power BI Desktop-økten avsluttes.
I arbeidsområdemappen for gjeldende Power BI-økt inneholder mappen \Data flightRecorderCurrent.trc sporingsfil. Noter lokasjonen.
Åpne SQL Server Profiler, og velg Åpne filsporingsfil>.
Gå til eller skriv inn banen til sporingsfilen for gjeldende Power BI-økt, og åpne FlightRecorderCurrent.trc.
SQL Server Profiler viser alle hendelser fra gjeldende økt. Skjermbildet nedenfor uthever en gruppe hendelser for en spørring. Hver spørringsgruppe har følgende hendelser:
A Query Begin og Query End hendelse, som representerer starten og slutten på en DAX-spørring som genereres ved å endre et visualobjekt eller et filter i Power BI-brukergrensesnittet, eller fra å filtrere eller transformere data i Power Query-redigering.
Ett eller flere par DirectQuery Begin og DirectQuery End hendelser, som representerer spørringer som sendes til den underliggende datakilden som en del av evalueringen av DAX-spørringen.

Flere DAX-spørringer kan kjøre parallelt, slik at hendelser fra ulike grupper kan deles inn. Du kan bruke ActivityID verdien til å bestemme hvilke hendelser som tilhører samme gruppe.
Følgende kolonner er også av interesse:
Query Begin og Query End hendelser er detaljen DAX-spørringen. For DirectQuery Begin og DirectQuery End hendelser er detaljene SQL-spørringen som sendes til den underliggende kilden.
TextData for den valgte hendelsen vises også i ruten nederst på skjermen.Slik registrerer du en sporing for å diagnostisere et potensielt ytelsesproblem:
Åpne én enkelt Power BI Desktop-økt for å unngå forvirringen i flere arbeidsområdemapper.
Gjør settet med handlinger av interesse i Power BI Desktop. Inkluder noen flere handlinger, for å sikre at hendelsene av interesse tømmes inn i sporingsfilen.
Åpne SQL Server Profiler, og undersøk sporingen. Husk at når du lukker Power BI Desktop, slettes sporingsfilen. Flere handlinger i Power BI Desktop vises heller ikke umiddelbart. Du må lukke og åpne sporingsfilen på nytt for å se nye hendelser.
Hold individuelle økter rimelig små, kanskje 10 sekunder med handlinger, ikke hundrevis. Denne fremgangsmåten gjør det enklere å tolke sporingsfilen. Det er også en grense for størrelsen på sporingsfilen. For lange økter er det en sjanse for at tidlige hendelser blir droppet.
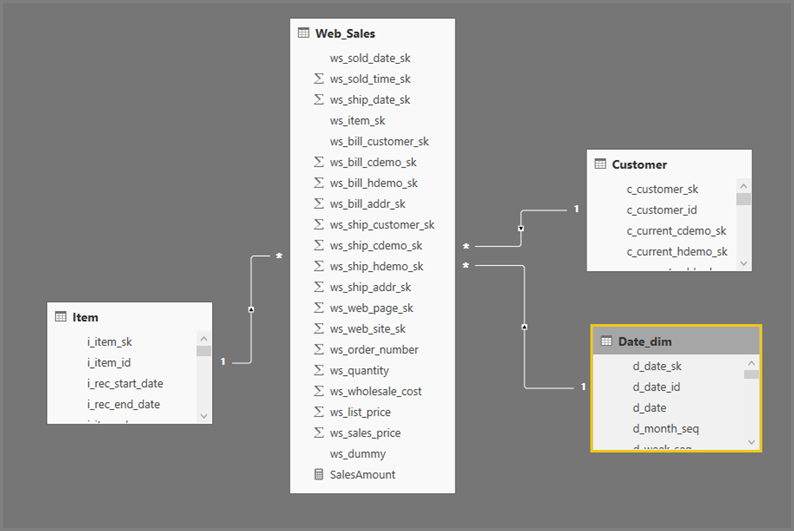
Det generelle formatet for Power BI Desktop-spørringer bruker undervalg for hver tabell de refererer til. Spørringen Power Query-redigering definerer undervalgsspørringene. Anta for eksempel at du har følgende TPC-DS-tabeller i SQL Server:
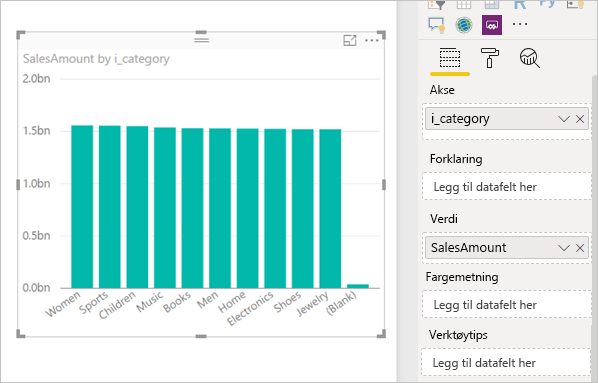
Kjører følgende spørring:
SalesAmount (SUMX(Web_Sales, [ws_sales_price]*[ws_quantity]))
by Item[i_category]
for Date_dim[d_year] = 2000
Resulterer i følgende visualobjekt i Power BI:
Oppdatering av visualobjektet produserer SQL-spørringen i illustrasjonen nedenfor. Det finnes tre undervalgsspørringer for Web_Sales, Itemog Date_dim, som hver returnerer alle kolonnene i den respektive tabellen, selv om visualobjektet bare refererer til fire kolonner.

Power Query-redigering definerer nøyaktig undervalgsspørringer. Denne bruken av undervalgsspørringer har ikke vist seg å påvirke ytelsen for datakildene DirectQuery støtter. Datakilder som SQL Server optimaliserer referansene til de andre kolonnene.
Power BI bruker dette mønsteret fordi analytikeren leverer SQL-spørringen direkte. Power BI bruker spørringen som angitt, uten forsøk på å skrive den på nytt.
Hvis du vil ha mer informasjon om DirectQuery i Power BI, kan du se:
Denne artikkelen beskrev aspekter av DirectQuery som er vanlige på tvers av alle datakilder. Se følgende artikler for mer informasjon om bestemte kilder:
Hendelser
14. feb., 16 - 31. mars, 16
Med fire sjanser til å delta, kan du vinne en konferansepakke og komme deg til LIVE Grand Finale i Las Vegas
Finn ut merOpplæring
Læringsbane
Use advance techniques in canvas apps to perform custom updates and optimization - Training
Use advance techniques in canvas apps to perform custom updates and optimization
Sertifisering
Microsoft Certified: Power BI Data Analyst Associate - Certifications
Demonstrere metoder og anbefalte fremgangsmåter som samsvarer med forretningsmessige og tekniske krav for modellering, visualisering og analyse av data med Microsoft Power BI.