Brukerdefinerte aggregasjoner
Aggregasjoner i Power BI kan forbedre spørringsytelsen over store DirectQuery-semantiske modeller. Ved hjelp av aggregasjoner bufrer du data på aggregert nivå i minnet. Aggregasjoner i Power BI kan konfigureres manuelt i datamodellen, som beskrevet i denne artikkelen. For Premium-abonnementer, automatisk ved å aktivere funksjonen Automatiske aggregasjoner i modell Innstillinger.
Opprette aggregasjonstabeller
Avhengig av datakildetypen kan det opprettes en aggregasjonstabell i datakilden som en tabell eller visning, opprinnelig spørring. For størst ytelse kan du opprette en aggregasjonstabell som en importtabell som er opprettet i Power Query. Deretter bruker du dialogboksen Behandle aggregasjoner i Power BI Desktop til å definere aggregasjoner for aggregasjonskolonner med sammendrag, detaljtabell og detaljkolonneegenskaper.
Dimensjonale datakilder, for eksempel datalagre og datamarts, kan bruke relasjonsbaserte aggregasjoner. Hadoop-baserte store datakilder baserer ofte aggregasjoner på GroupBy-kolonner. Denne artikkelen beskriver vanlige forskjeller på datamodellering for Power BI for hver type datakilde.
Administrere aggregasjoner
Høyreklikk aggregasjonstabellen i dataruten i en Power BI Desktop-visning, og velg deretter Administrer aggregasjoner.

Dialogboksen Behandle aggregasjoner viser en rad for hver kolonne i tabellen, der du kan angi aggregasjonsvirkemåten. I eksemplet nedenfor omdirigeres spørringer til salgsdetaljtabellen internt til salgsaggregasjonstabellen.
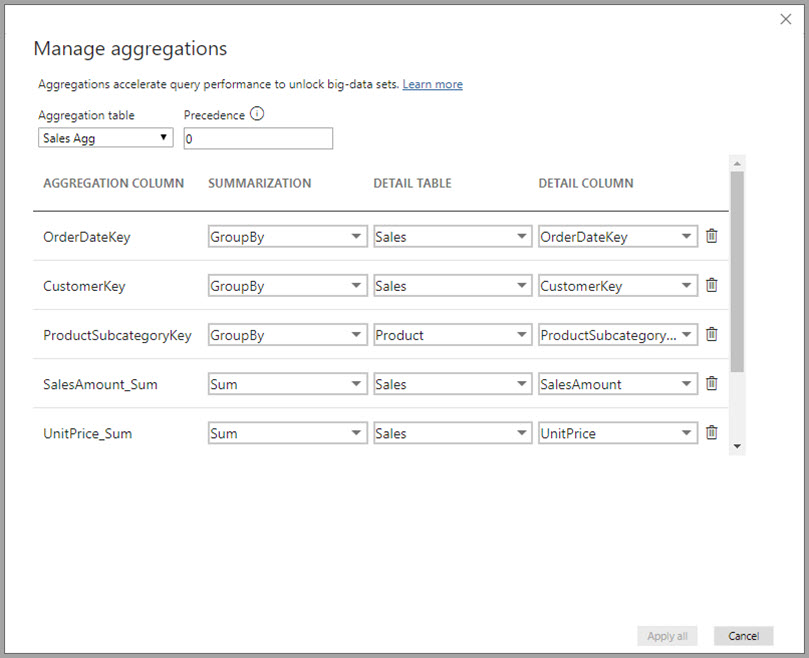
I dette relasjonsbaserte aggregasjonseksemplet er GroupBy-oppføringene valgfrie. Bortsett fra DISTINCTCOUNT, påvirker de ikke aggregasjonsvirkemåten og er først og fremst for lesbarhet. Uten GroupBy-oppføringene ville aggregasjonene fortsatt bli truffet, basert på relasjonene. Dette er forskjellig fra det store dataeksemplet senere i denne artikkelen, der GroupBy-oppføringene kreves.
Valideringer
Dialogboksen Administrer aggregasjoner håndhever valideringer:
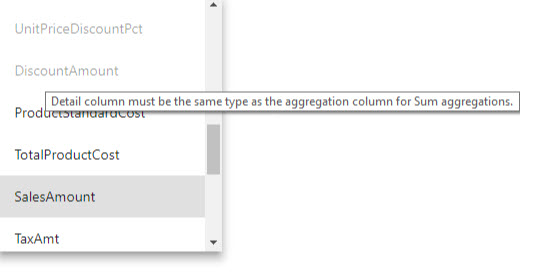
- Detaljkolonnen må ha samme datatype som Aggregasjonskolonnen, bortsett fra sammendragsfunksjonene antall og antall tabellrader. Antall og Tell tabellrader er bare tilgjengelige for aggregasjonskolonner for heltall, og krever ikke en samsvarende datatype.
- Kjedede aggregasjoner som dekker tre eller flere tabeller, er ikke tillatt. Aggregasjoner i tabell A kan for eksempel ikke referere til en tabell B som har aggregasjoner som refererer til en tabell C.
- Dupliserte aggregasjoner, der to oppføringer bruker samme sammendragsfunksjon og refererer til samme detaljtabell og detaljkolonne, er ikke tillatt.
- Detaljtabellen må bruke DirectQuery-lagringsmodus, ikke import.
- Gruppering etter en sekundærnøkkelkolonne som brukes av en inaktiv relasjon, og avhengig av USERELATIONSHIP-funksjonen for aggregasjonstreff, støttes ikke.
- Aggregasjoner basert på GroupBy-kolonner kan bruke relasjoner mellom aggregasjonstabeller, men redigering av relasjoner mellom aggregasjonstabeller støttes ikke i Power BI Desktop. Hvis det er nødvendig, kan du opprette relasjoner mellom aggregasjonstabeller ved hjelp av et tredjepartsverktøy eller en skriptløsning gjennom XML for Analysis -endepunkter (XMLA).
De fleste valideringer håndheves ved å deaktivere rullegardinverdier og vise forklarende tekst i verktøytipset.
Aggregasjonstabeller er skjult
Brukere med skrivebeskyttet tilgang til modellen kan ikke spørre etter aggregasjonstabeller. Skrivebeskyttet tilgang unngår sikkerhetsproblemer når de brukes med sikkerhet på radnivå (RLS). Forbrukere og spørringer refererer til detaljtabellen, ikke aggregasjonstabellen, og trenger ikke å vite om aggregasjonstabellen.
Av denne grunn er aggregasjonstabeller skjult for rapportvisning . Hvis tabellen ikke allerede er skjult, blir dialogboksen Behandle aggregasjoner skjult når du velger Bruk alle.
Lagringsmoduser
Aggregasjonsfunksjonen samhandler med lagringsmoduser på tabellnivå. Power BI-tabeller kan bruke DirectQuery-, Import- eller Dual Storage-moduser. DirectQuery spør backend direkte, mens Importer bufrer data i minnet og sender spørringer til de bufrede dataene. Alle Datakilder for Power BI-import og ikke-flerdimensjonale DirectQuery-datakilder kan fungere med aggregasjoner.
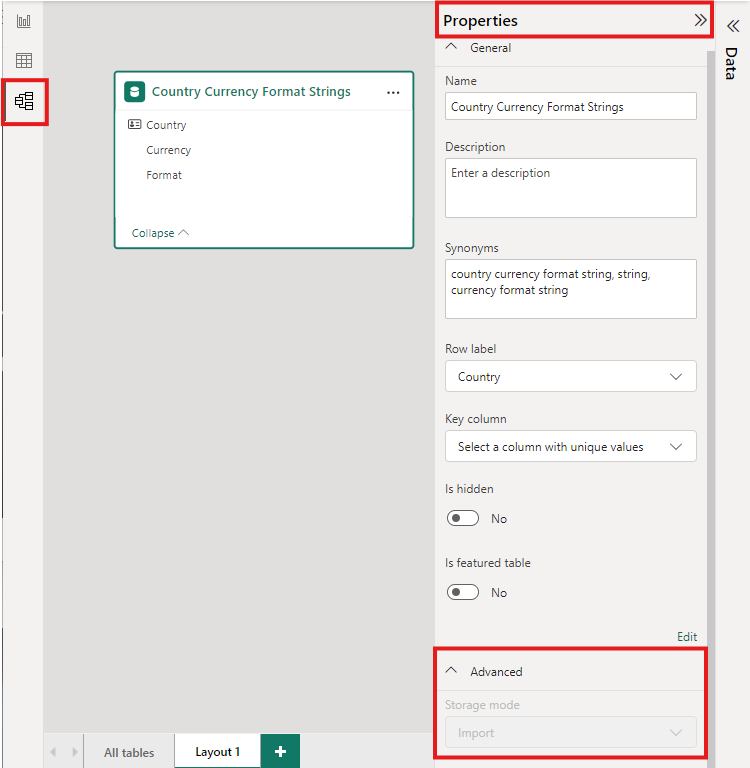
Hvis du vil angi lagringsmodus for en aggregert tabell til Importer for å øke hastigheten på spørringer, velger du den aggregerte tabellen i Power BI Desktop-modellvisning. Utvid Avansert i Egenskaper-ruten, slipp det merkede området under Lagringsmodus, og velg Importer. Endring av import er irreversibelt.
Hvis du vil lære mer om tabelllagringsmoduser, kan du se Behandle lagringsmodus i Power BI Desktop.
RLS for aggregasjoner
Hvis du vil fungere riktig for aggregasjoner, bør RLS-uttrykk filtrere aggregasjonstabellen og detaljtabellen.
I eksemplet nedenfor fungerer RLS-uttrykket i Geografi-tabellen for aggregasjoner, fordi Geografi er på filtreringssiden av relasjoner til Salg-tabellen og Salg-Agg-tabellen . Spørringer som treffer aggregasjonstabellen og spørringer som ikke har RLS aktivert.
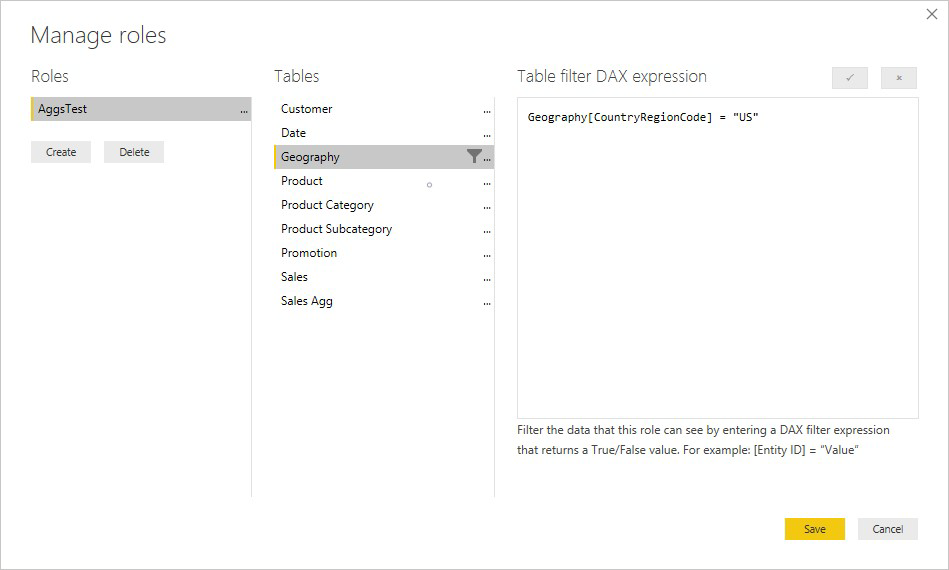
Et RLS-uttrykk i Produkt-tabellen filtrerer bare detaljtabellen Salg, ikke den aggregerte Sales Agg-tabellen. Siden aggregasjonstabellen er en annen representasjon av dataene i detaljtabellen, er det usikkert å svare på spørringer fra aggregasjonstabellen hvis RLS-filteret ikke kan brukes. Filtrering av bare detaljtabellen anbefales ikke, fordi brukerspørringer fra denne rollen ikke drar nytte av aggregasjonstreff.
Et RLS-uttrykk som bare filtrerer tabellen Salgsaggaggregasjon, og ikke salgsdetaljtabellen, er ikke tillatt.
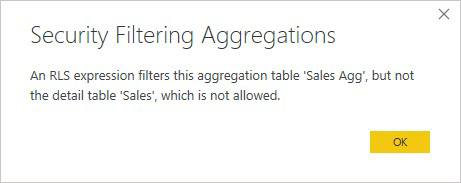
For aggregasjoner basert på GroupBy-kolonner kan et RLS-uttrykk som brukes i detaljtabellen, brukes til å filtrere aggregasjonstabellen, fordi alle GroupBy-kolonnene i aggregasjonstabellen dekkes av detaljtabellen. På den annen side kan ikke et RLS-filter i aggregasjonstabellen brukes i detaljtabellen, så det er ikke tillatt.
Aggregasjon basert på relasjoner
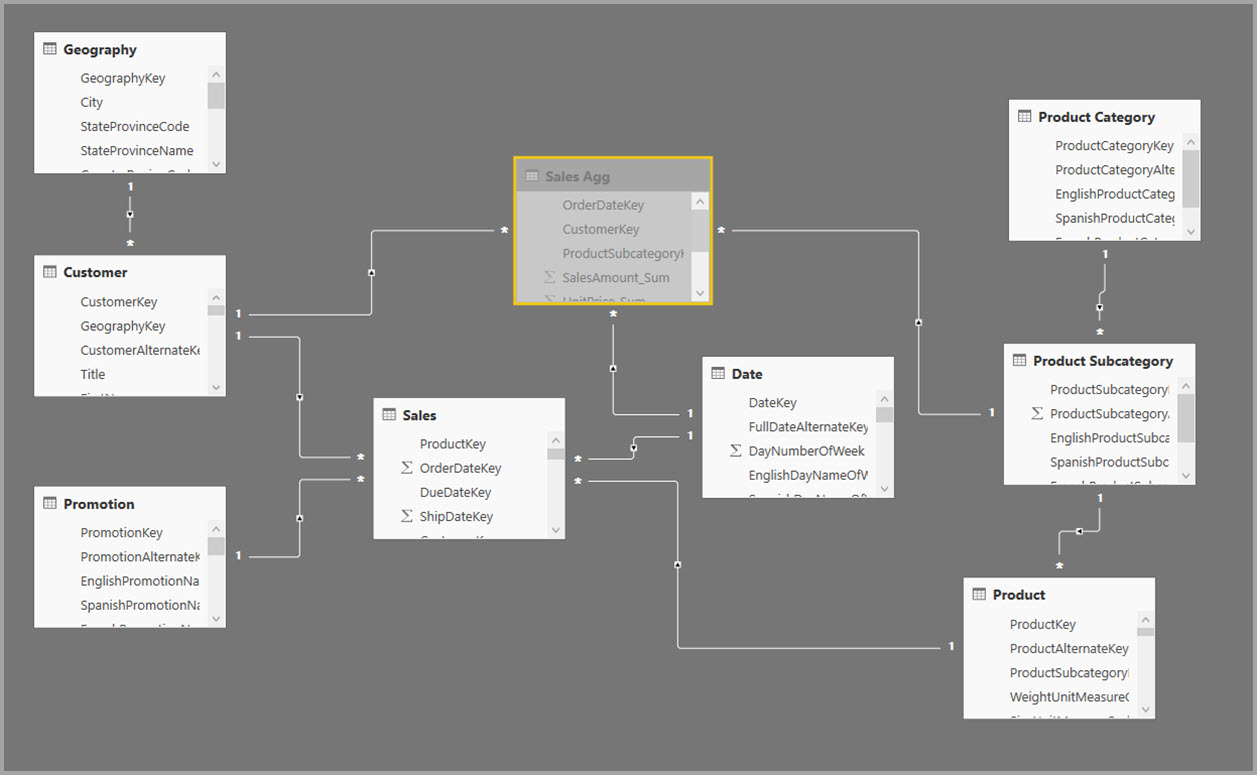
Dimensjonale modeller bruker vanligvis aggregasjoner basert på relasjoner. Power BI-modeller fra datalagre og datamarts ligner stjerne-/snøfnuggskjemaer, med relasjoner mellom dimensjonstabeller og faktatabeller.
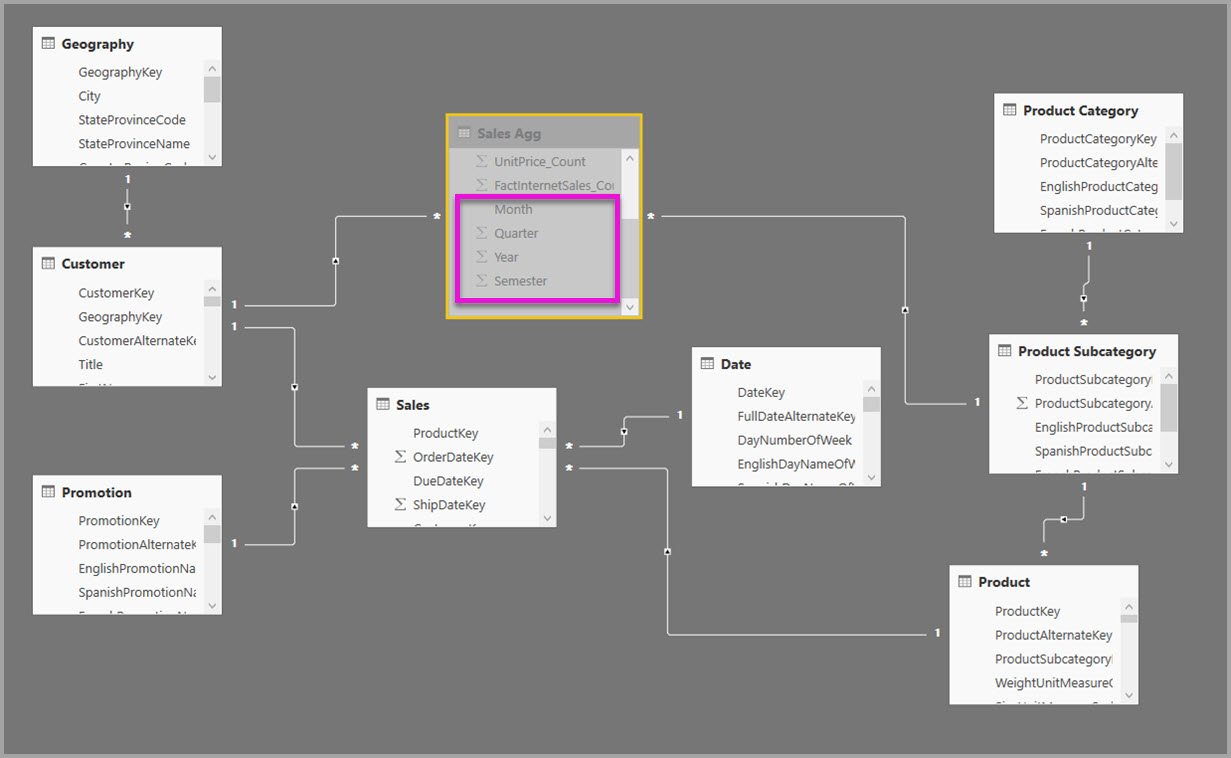
I eksemplet nedenfor henter modellen data fra én enkelt datakilde. Tabeller bruker DirectQuery-lagringsmodus. Faktatabellen Salg inneholder milliarder av rader. Hvis du angir lagringsmodusen for Salg til Import for hurtigbufring, brukes mye minne og ressurser.

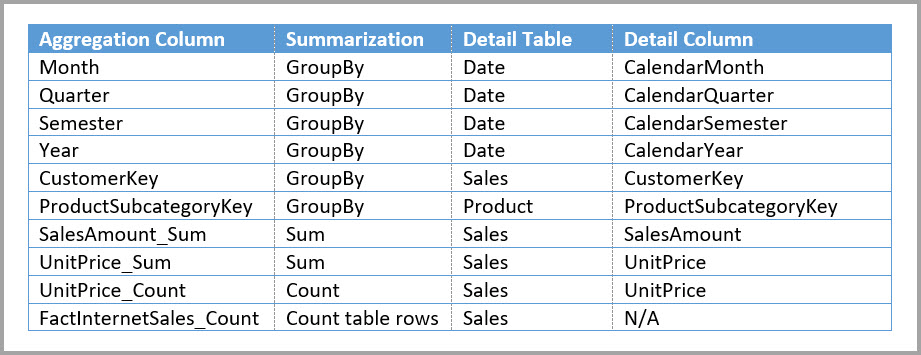
I stedet kan du opprette salgsaggregasjonstabellen. I Salg Agg-tabellen er antall rader lik summen av SalesAmount gruppert etter CustomerKey, DateKey og ProductSubcategoryKey. Salg-Agg-tabellen har en høyere detaljnivå enn Salg, så i stedet for milliarder kan den inneholde millioner av rader, som er enklere å administrere.
Hvis følgende dimensjonstabeller brukes oftest for spørringer med høy forretningsverdi, kan de filtrere Salgsagg ved hjelp av én-til-mange - eller mange-til-én-relasjoner .
- Geography
- Customer
- Dato
- Underkategori for produkt
- Produktkategori
Bildet nedenfor viser denne modellen.
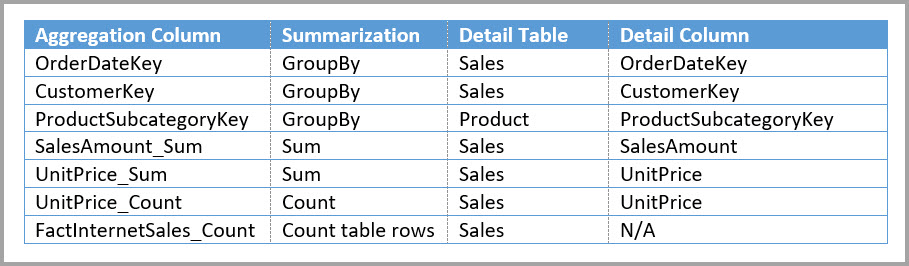
Tabellen nedenfor viser aggregasjonene for Sales Agg-tabellen .
Merk
Salg-Agg-tabellen, som alle tabeller, har fleksibiliteten til å lastes inn på en rekke måter. Aggregasjonen kan utføres i kildedatabasen ved hjelp av ETL/ELT-prosesser, eller av M-uttrykket for tabellen. Den aggregerte tabellen kan bruke importlagringsmodus, med eller uten trinnvis oppdatering for semantiske modeller, eller den kan bruke DirectQuery og optimaliseres for raske spørringer ved hjelp av kolonnelagerindekser. Denne fleksibiliteten muliggjør balanserte arkitekturer som kan spre spørringsbelastning for å unngå flaskehalser.
Hvis du endrer lagringsmodusen for den aggregerte Sales Agg-tabellen til Import, åpnes en dialogboks som sier at de relaterte dimensjonstabellene kan settes til dobbel lagringsmodus.
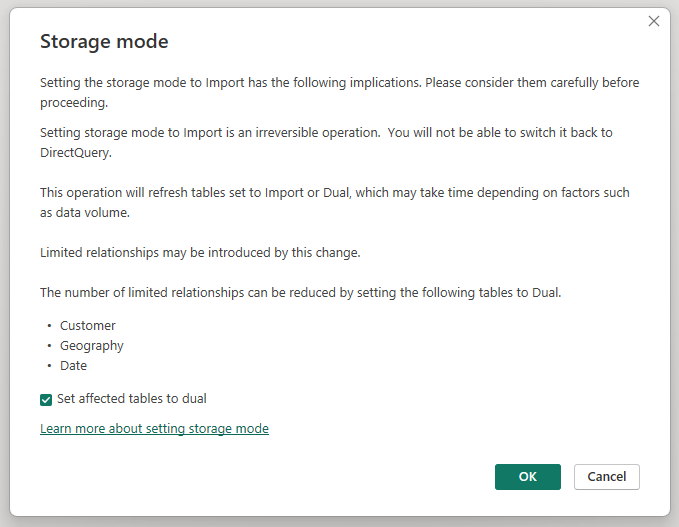
Hvis du angir de relaterte dimensjonstabellene til Dobbel, kan de fungere som enten Importer eller DirectQuery, avhengig av delspørringen. I eksemplet:
- Spørringer som aggregerer måledata fra tabellen Import-modus Salgsagg , og grupperer etter attributter fra de relaterte to tabellene, kan returneres fra minnehurtigbufferen.
- Spørringer som aggregerer måledata fra DirectQuery Sales-tabellen , og grupperer etter attributter fra de relaterte doble tabellene, kan returneres i DirectQuery-modus. Spørringslogikken, inkludert GroupBy-operasjonen, sendes ned til kildedatabasen.
Hvis du vil ha mer informasjon om dobbel lagringsmodus, kan du se Administrere lagringsmodus i Power BI Desktop.
Vanlige kontra begrensede relasjoner
Aggregasjonstreff basert på relasjoner krever regelmessige relasjoner.
Vanlige relasjoner inkluderer følgende kombinasjoner av lagringsmodus, der begge tabellene er fra én enkelt kilde:
| Tabell på mange sider | Tabell på 1-siden |
|---|---|
| Dual | Dual |
| Importer | Importer eller dobbel |
| DirectQuery | DirectQuery eller Dobbel |
Det eneste tilfellet der en krysskilderelasjon anses som vanlig, er hvis begge tabellene er satt til Importer. Mange-til-mange-relasjoner anses alltid som begrensede.
Hvis du vil se aggregasjonstreff på tvers av kilder som ikke er avhengige av relasjoner, kan du se Aggregasjoner basert på GroupBy-kolonner.
Eksempler på relasjonsbasert aggregasjonsspørring
Følgende spørring treffer aggregasjonen, fordi kolonnene i Dato-tabellen er på detaljnivået som kan treffe aggregasjonen. SalesAmount-kolonnen bruker Sum-aggregasjonen.

Følgende spørring treffer ikke aggregasjonen. Til tross for at du ber om summen av SalesAmount, utfører spørringen en GroupBy-operasjon på en kolonne i produkttabellen, som ikke er på detaljnivået som kan treffe aggregasjonen. Hvis du ser på relasjonene i modellen, kan en produktunderkategori ha flere produktrader . Spørringen kan ikke bestemme hvilket produkt som skal aggregeres til. I dette tilfellet går spørringen tilbake til DirectQuery og sender en SQL-spørring til datakilden.

Aggregasjoner er ikke bare for enkle beregninger som utfører en enkel sum. Komplekse beregninger kan også dra nytte av dette. En kompleks beregning deles opp i delspørringer for hver SUM, MIN, MAX og COUNT. Hver delspørring evalueres for å avgjøre om den kan treffe aggregasjonen. Denne logikken gjelder ikke i alle tilfeller på grunn av optimalisering av spørringsplan, men generelt bør den gjelde. Følgende eksempel treffer aggregasjonen:

COUNTROWS-funksjonen kan dra nytte av aggregasjoner. Følgende spørring treffer aggregasjonen fordi det er definert en aggregasjon for antall tabellrader for Salg-tabellen.

GJENNOMSNITT-funksjonen kan dra nytte av aggregasjoner. Følgende spørring treffer aggregasjonen fordi GJENNOMSNITT internt blir brettet til en SUM delt på en COUNT. Siden UnitPrice-kolonnen har aggregasjoner definert for både SUMMER og ANTALL, treffes aggregasjonen.

I noen tilfeller kan DISTINCTCOUNT-funksjonen dra nytte av aggregasjoner. Følgende spørring treffer aggregasjonen fordi det finnes en GroupBy-oppføring for CustomerKey, som opprettholder distinktheten til CustomerKey i aggregasjonstabellen. Denne teknikken kan fortsatt treffe ytelsesterskelen der mer enn to til fem millioner distinkte verdier kan påvirke spørringsytelsen. Det kan imidlertid være nyttig i scenarioer der det er milliarder av rader i detaljtabellen, men to til fem millioner distinkte verdier i kolonnen. I dette tilfellet kan DISTINCTCOUNT utføre raskere enn å skanne tabellen med milliarder av rader, selv om den ble bufret i minnet.

Data Analysis Expressions (DAX) tidsintelligensfunksjoner er aggregasjonsbevisste. Følgende spørring treffer aggregasjonen fordi DATESYTD-funksjonen genererer en tabell med CalendarDay-verdier , og aggregasjonstabellen har en detaljerthet som dekkes for grupper etter-kolonner i Dato-tabellen . Dette er et eksempel på et tabellverdifilter til CALCULATE-funksjonen, som kan fungere med aggregasjoner.

Aggregasjon basert på GroupBy-kolonner
Hadoop-baserte stordatamodeller har forskjellige egenskaper enn dimensjonale modeller. For å unngå sammenføyninger mellom store tabeller bruker store datamodeller ofte ikke relasjoner, men denormaliserer dimensjonsattributter til faktatabeller. Du kan låse opp slike store datamodeller for interaktiv analyse ved hjelp av aggregasjoner basert på GroupBy-kolonner.
Tabellen nedenfor inneholder den numeriske bevegelseskolonnen som skal aggregeres. Alle de andre kolonnene er attributter som grupperes etter. Tabellen inneholder IoT-data og et stort antall rader. Lagringsmodusen er DirectQuery. Spørringer på datakilden som aggregerer på tvers av hele modellen, er treg på grunn av det store volumet.
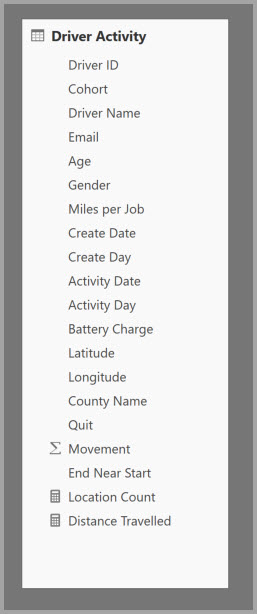
Hvis du vil aktivere interaktiv analyse på denne modellen, kan du legge til en aggregasjonstabell som grupperer etter de fleste attributtene, men utelater attributtene med høy kardinalitet som lengdegrad og breddegrad. Dette reduserer antall rader dramatisk, og er lite nok til å passe komfortabelt inn i en minnehurtigbuffer.
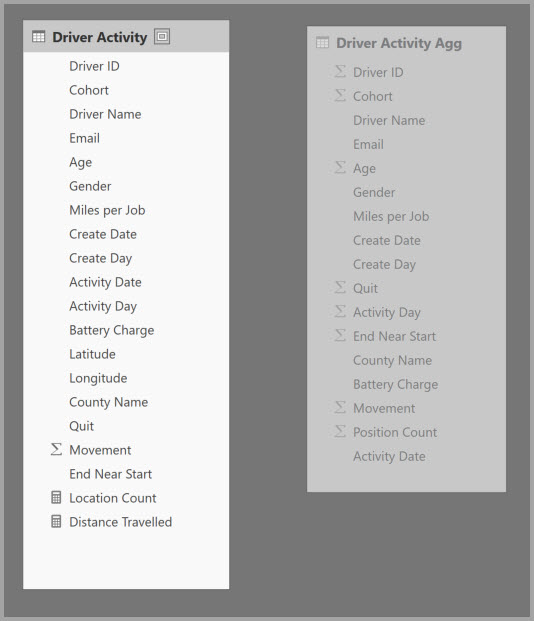
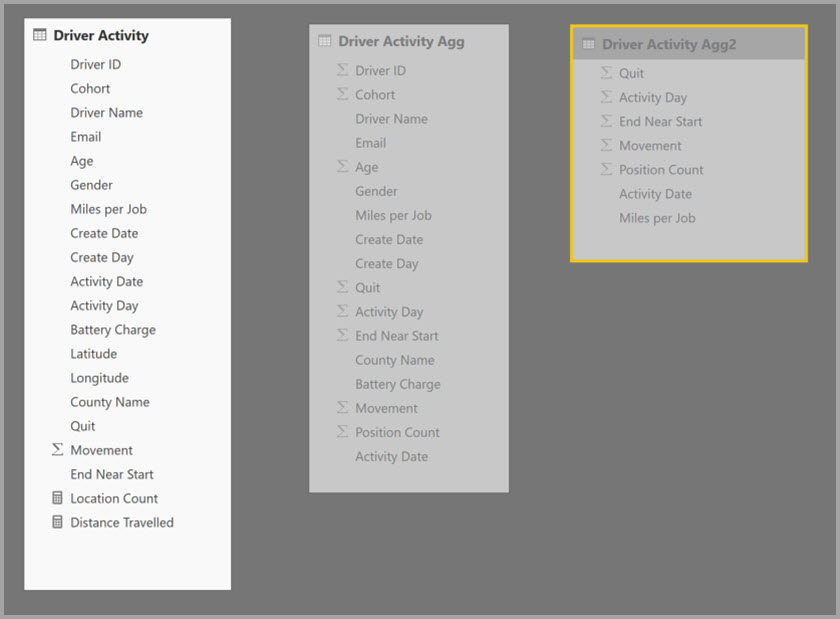
Du definerer aggregasjonstilordningene for Agg-tabellen driveraktivitet i dialogboksen Administrer aggregasjoner .
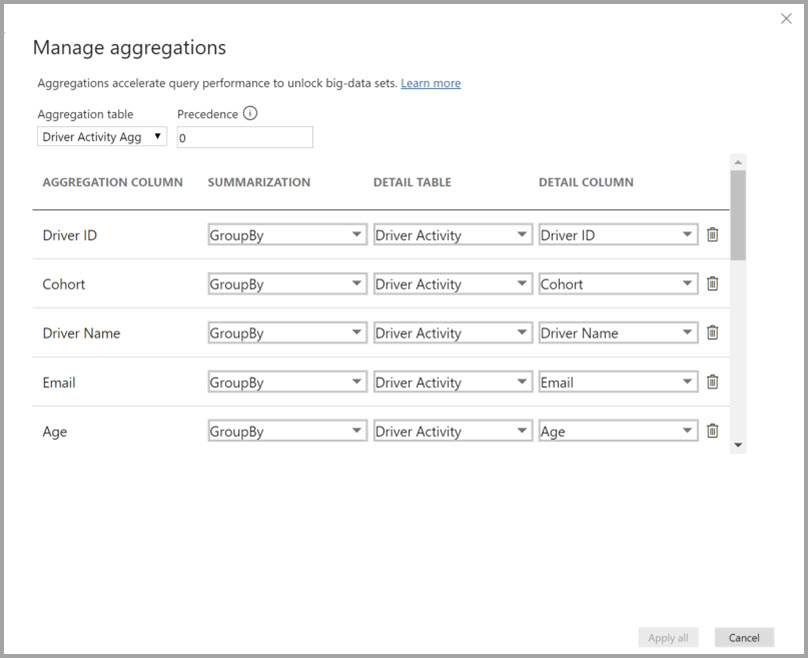
GroupBy-oppføringene er ikke valgfrie i aggregasjoner basert på GroupBy-kolonner. Uten dem blir ikke aggregasjonene truffet. Dette er forskjellig fra å bruke aggregasjoner basert på relasjoner, der GroupBy-oppføringene er valgfrie.
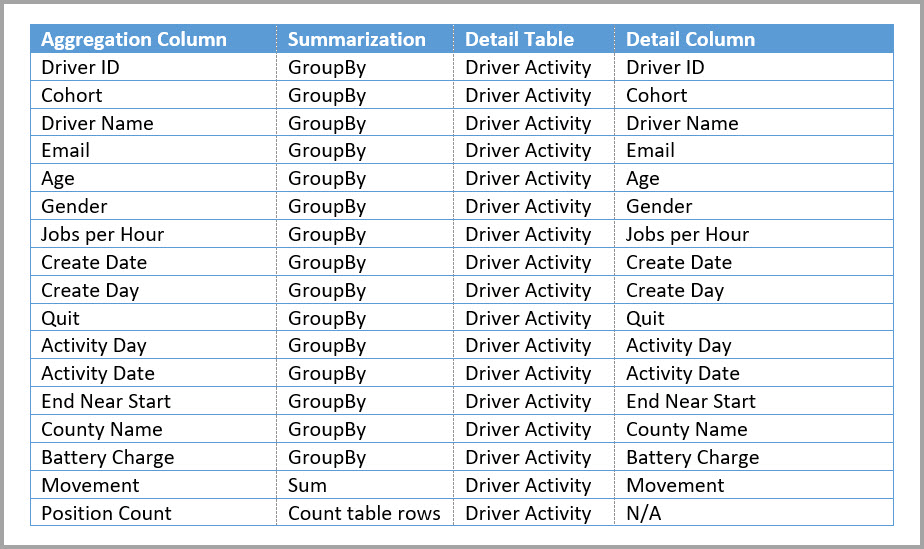
Tabellen nedenfor viser aggregasjonene for driveraktivitetsaggtabellen.
Du kan angi lagringsmodusen for den aggregerte driveraktivitets-Agg-tabellen til Importer.
Eksempel på GroupBy-aggregasjonsspørring
Følgende spørring treffer aggregasjonen fordi kolonnen Aktivitetsdato dekkes av aggregasjonstabellen. COUNTROWS-funksjonen bruker aggregasjonen Tellede tabellrader .

Spesielt for modeller som inneholder filterattributter i faktatabeller, er det lurt å bruke Aggregasjoner for antall tabellrader . Power BI kan sende spørringer til modellen ved hjelp av COUNTROWS i tilfeller der den ikke er eksplisitt forespurt av brukeren. Filterdialogboksen viser for eksempel antall rader for hver verdi.
Kombinerte aggregasjonsteknikker
Du kan kombinere relasjoner og GroupBy-kolonneteknikker for aggregasjoner. Aggregasjoner basert på relasjoner kan kreve at de denormaliserte dimensjonstabellene deles inn i flere tabeller. Hvis dette er kostbart eller upraktisk for bestemte dimensjonstabeller, kan du replikere de nødvendige attributtene i aggregasjonstabellen for disse dimensjonene, og bruke relasjoner for andre.
Modellen nedenfor replikerer for eksempel Måned, Kvartal, Semester og År i Salg Agg-tabellen . Det er ingen relasjon mellom Salgsagg og Dato-tabellen, men det finnes relasjoner til underkategorien Kunde og Produkt. Lagringsmodusen for Salgsagg er Importer.
Tabellen nedenfor viser oppføringene som er angitt i dialogboksen Administrer aggregasjoner for Salg-Agg-tabellen . GroupBy-oppføringene der Dato er detaljtabellen er obligatorisk, for å treffe aggregasjoner for spørringer som grupperer etter Dato-attributtene . Som i forrige eksempel påvirker ikke GroupBy-oppføringene for CustomerKey og ProductSubcategoryKey aggregasjonstreff, bortsett fra DISTINCTCOUNT, på grunn av tilstedeværelsen av relasjoner.
Eksempler på kombinert aggregasjonsspørring
Følgende spørring treffer aggregasjonen fordi aggregasjonstabellen dekker CalendarMonth, og CategoryName er tilgjengelig via én-til-mange-relasjoner. SalesAmount bruker SUM-aggregasjonen .

Følgende spørring treffer ikke aggregasjonen, fordi aggregasjonstabellen ikke dekker CalendarDay.

Følgende tidsintelligensspørring treffer ikke aggregasjonen fordi DATESYTD-funksjonen genererer en tabell med CalendarDay-verdier , og aggregasjonstabellen dekker ikke CalendarDay.

Aggregasjonsprioritet
Aggregasjonsprioritet gjør at flere aggregasjonstabeller kan vurderes av én enkelt delspørring.
Følgende eksempel er en sammensatt modell som inneholder flere kilder:
- Tabellen Driver Activity DirectQuery inneholder over en billion rader med IoT-data hentet fra et stort datasystem. Den serverer ekstraheringsspørringer for å vise individuelle IoT-avlesninger i kontrollerte filterkontekster.
- Driveraktivitet-Agg-tabellen er en mellomliggende aggregasjonstabell i DirectQuery-modus. Den inneholder over en milliard rader i Azure Synapse Analytics (tidligere SQL Data Warehouse) og er optimalisert ved kilden ved hjelp av kolonnelagerindekser.
- Importtabellen driveraktivitet Agg2 har høy detaljnivå, fordi group-by-attributtene er få og lav kardinalitet. Antall rader kan være så lavt som tusenvis, slik at det enkelt kan passe inn i en minnehurtigbuffer. Disse attributtene brukes tilfeldigvis av et høyt profilert instrumentbord, så spørringer som refererer til dem, bør være så raske som mulig.
Merk
DirectQuery-aggregasjonstabeller som bruker en annen datakilde fra detaljtabellen, støttes bare hvis aggregasjonstabellen er fra en SQL Server-, Azure SQL- eller Azure Synapse Analytics-kilde (tidligere SQL Data Warehouse).
Minneavtrykket til denne modellen er relativt liten, men den låser opp en stor modell. Den representerer en balansert arkitektur fordi den sprer spørringsbelastningen på tvers av komponenter i arkitekturen, og bruker dem basert på deres styrker.
Dialogboksen Administrerte aggregasjoner for Driveraktivitet Agg2 angir Prioritet-feltet til 10, som er høyere enn for Driver Activity Agg. Den høyere prioritetsinnstillingen betyr at spørringer som bruker aggregasjoner, vurderer Driver Activity Agg2 først. Delspørringer som ikke er på detaljnivå som kan besvares av Driver Activity Agg2 , kan vurdere Driver Activity Agg i stedet. Detaljspørringer som ikke kan besvares av noen av aggregasjonstabellene, kan sendes til Driveraktivitet.
Tabellen som er angitt i detaljtabellkolonnen , er Driveraktivitet, ikke DriverAktivitet-agg, fordi kjedede aggregasjoner ikke er tillatt.
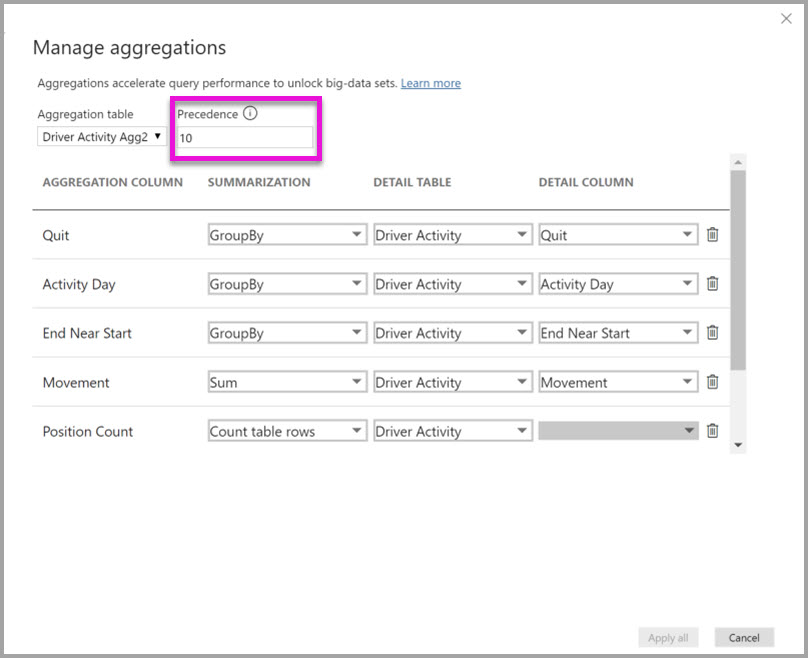
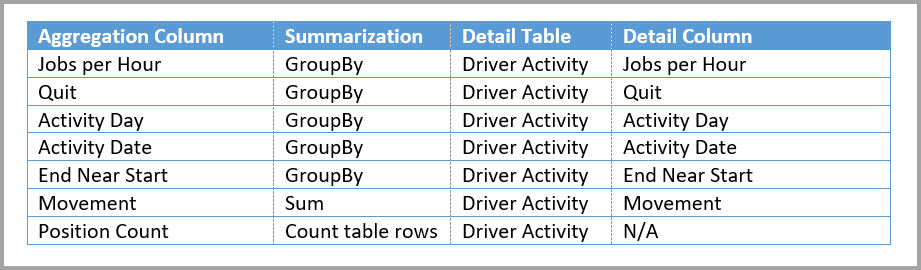
Tabellen nedenfor viser aggregasjonene for Driver Activity Agg2-tabellen .
Finn ut om spørringer treffer eller går glipp av aggregasjoner
SQL Profiler kan oppdage om spørringer returneres fra lagringsmotoren for hurtigbufferen i minnet, eller sendes til datakilden av DirectQuery. Du kan bruke samme prosess til å finne ut om aggregasjoner blir truffet. Hvis du vil ha mer informasjon, kan du se Spørringer som treffer eller går glipp av hurtigbufferen.
SQL Profiler gir også den Query Processing\Aggregate Table Rewrite Query utvidede hendelsen.
Følgende JSON-kodesnutt viser et eksempel på utdataene for hendelsen når en aggregasjon brukes.
- matchingResult viser at delspørringen brukte en aggregasjon.
- dataRequest viser GroupBy-kolonnen(e) og aggregerte kolonner som delspørringen som brukes.
- tilordningen viser kolonnene i aggregasjonstabellen som ble tilordnet til.

Holde hurtigbuffere synkronisert
Aggregasjoner som kombinerer DirectQuery-, Import- og/eller Dual-lagringsmoduser, kan returnere forskjellige data med mindre minnehurtigbufferen holdes synkronisert med kildedataene. Spørringskjøring forsøker for eksempel ikke å maskere dataproblemer ved å filtrere DirectQuery-resultater for å samsvare med bufrede verdier. Det finnes etablerte teknikker for å håndtere slike problemer ved kilden, om nødvendig. Ytelsesoptimaliseringer bør bare brukes på måter som ikke gir deg mulighet til å oppfylle forretningskrav. Det er ditt ansvar å kjenne dataflytene og utformingen tilsvarende.
Hensyn og begrensninger
Aggregasjoner støtter ikke dynamiske M-spørringsparametere.
Fra og med august 2022 ignorerer Power BI importmodusaggregasjonstabeller med enkel pålogging (SSO) aktiverte datakilder på grunn av potensielle sikkerhetsrisikoer. For å sikre optimal spørringsytelse med aggregasjoner anbefales det at du deaktiverer SSO for disse datakildene.
Fellesskap
Power BI har et levende fellesskap der MVPer, BI-eksperter og kolleger deler ekspertise i diskusjonsgrupper, videoer, blogger og mer. Når du lærer om aggregasjoner, må du sjekke ut disse ekstra ressursene: