Automatiske aggregasjoner
Automatiske aggregasjoner bruker toppmoderne maskinlæring (ML) til å kontinuerlig optimalisere Semantiske modeller for DirectQuery for maksimal rapportspørringsytelse. Automatiske aggregasjoner bygges oppå eksisterende brukerdefinert aggregasjonsinfrastruktur som først ble introdusert med sammensatte modeller for Power BI. I motsetning til brukerdefinerte aggregasjoner krever ikke automatiske aggregasjoner omfattende datamodellerings- og spørringsoptimaliseringsferdigheter for å konfigurere og vedlikeholde. Automatiske aggregasjoner er både selvtrening og selvoptimalisering. De gjør det mulig for modelleiere på alle ferdighetsnivåer å forbedre spørringsytelsen, noe som gir raskere rapportvisualiseringer for store modeller.
Med automatiske aggregasjoner:
- Rapportvisualiseringer er raskere – En optimal prosentandel av rapportspørringer returneres av en automatisk vedlikeholdt minneaggregasjonsbuffer i stedet for serverdeldatakildesystemer. Ytre spørringer som ikke returneres av hurtigbufferen i minnet, sendes direkte til datakilden ved hjelp av DirectQuery.
- Balansert arkitektur – sammenlignet med ren DirectQuery-modus returneres de fleste spørringsresultatene av Power BI-spørringsmotoren og minneaggregasjonsbufferen. Belastning for spørringsbehandling på datakildesystemer på høyeste rapporteringstidspunkt kan reduseres betydelig, noe som betyr økt skalerbarhet i datakilden.
- Enkelt oppsett – Modelleiere kan aktivere automatisk aggregasjonsopplæring og planlegge én eller flere oppdateringer for modellen. Med den første opplæringen og oppdateringen begynner automatiske aggregasjoner å opprette et aggregasjonsrammeverk og optimale aggregasjoner. Systemet justerer seg automatisk over tid.
- Finjustering – Med et enkelt og intuitivt brukergrensesnitt i modellinnstillingene kan du beregne ytelsesgevinsten for en annen prosentandel av spørringer som returneres fra minneaggregasjonsbufferen og foreta justeringer for enda større gevinster. Med én enkelt lysbildelinjekontroll kan du enkelt finjustere miljøet.
Forutsetninger
Støttede planer
Automatiske aggregasjoner støttes for Power BI Premium per kapasitet, Premium per bruker og Power BI Embedded-modeller.
Støttede datakilder
Automatiske aggregasjoner støttes for følgende datakilder:
- Azure SQL Database
- Azure Synapse Dedicated SQL Pool
- SQL Server 2019 eller nyere
- Google BigQuery
- Snowflake
- Databricks
- Amazon Redshift
Støttede moduser
Automatiske aggregasjoner støttes for DirectQuery-modusmodeller. Sammensatte modellmodeller med både importtabeller og DirectQuery-tilkoblinger støttes. Automatiske aggregasjoner støttes bare for DirectQuery-tilkoblingen.
Tillatelser
Hvis du vil aktivere og konfigurere automatiske aggregasjoner, må du være modelleier. Administratorer for arbeidsområder kan overta som eier for å konfigurere innstillingene for automatiske aggregasjoner.
Konfigurere automatiske aggregasjoner
Automatiske aggregasjoner konfigureres i modell Innstillinger. Konfigurering er enkelt – aktiver automatisk aggregasjonsopplæring og planlegg én eller flere oppdateringer. Før du konfigurerer automatiske aggregasjoner for modellen, må du lese gjennom denne artikkelen fullstendig. Det gir en god forståelse av hvordan automatiske aggregasjoner fungerer og kan hjelpe deg med å avgjøre om automatiske aggregasjoner passer for miljøet ditt. Når du er klar for trinnvise instruksjoner om hvordan du aktiverer automatisk aggregasjonsopplæring, konfigurerer en oppdateringsplan og finjusterer for miljøet, kan du se Konfigurere automatiske aggregasjoner.
Fordeler
Med DirectQuery, hver gang en modellbruker åpner en rapport eller samhandler med en rapportvisualisering, sendes DAX-spørringer (Data Analysis Expressions) til spørringsmotoren og deretter til serverdeldatakilden som SQL-spørringer. Datakilden må beregne og returnere resultater for hver spørring. Sammenlignet med importmodusmodeller som er lagret i minnet, kan DirectQuery-datakilde-rundturer være både tids- og prosessintensive, noe som ofte forårsaker trege responstider for spørringer i rapportvisualiseringer.
Når det er aktivert for en DirectQuery-modell, kan automatiske aggregasjoner øke rapportspørringsytelsen ved å unngå avrunding av datakildespørringer. Forhåndssamlede spørringsresultater returneres automatisk av en minneaggregasjonsbuffer i stedet for å bli sendt til og returnert av datakilden. Mengden forhåndsaggregerte data i minneaggregasjonsbufferen er en liten brøkdel av mengden data som beholdes i fakta- og detaljtabeller hos datakilden. Resultatet er ikke bare bedre rapportspørringsytelse, men også redusert belastning på serverdeldatakildesystemer. Med automatiske aggregasjoner sendes bare en liten del av rapport- og ad hoc-spørringer som krever aggregasjoner som ikke er inkludert i minnehurtigbufferen, til serverdeldatakilden, akkurat som med ren DirectQuery-modus.
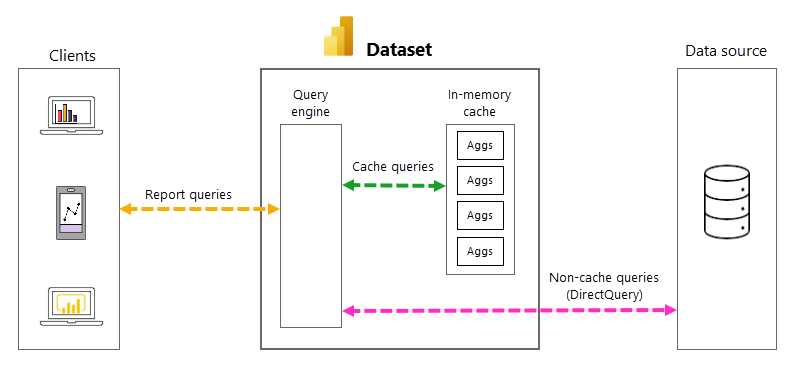
Automatisk behandling av spørringer og aggregasjoner
Selv om automatiske aggregasjoner eliminerer behovet for å opprette brukerdefinerte aggregasjonstabeller og dramatisk forenkle implementeringen av en forhåndsaggregert dataløsning, er en dypere kjennskap til de underliggende prosessene og avhengighetene nyttig for å forstå hvordan automatiske aggregasjoner fungerer. Power BI er avhengig av følgende for å opprette og administrere automatiske aggregasjoner.
Spørringslogg
Power BI sporer modell- og brukerrapportspørringer i en spørringslogg. For hver modell opprettholder Power BI sju dager med spørringsloggdata. Spørringsloggdata rulles frem hver dag. Spørringsloggen er sikker og ikke synlig for brukere eller via XMLA-endepunktet.
Opplæringsoperasjoner
Som en del av den første planlagte modelloppdateringsoperasjonen for den valgte frekvensen (dag eller uke), starter Power BI først en opplæringsoperasjon som evaluerer spørringsloggen for å sikre at aggregasjoner i minneaggregasjonene hurtigbufferen tilpasser seg endrede spørringsmønstre. Minneaggregasjonstabeller opprettes, oppdateres eller slippes, og spesielle spørringer sendes til datakilden for å fastslå aggregasjoner som skal inkluderes i hurtigbufferen. Beregnede aggregasjoner-data lastes imidlertid ikke inn i minnehurtigbufferen under opplæring – den lastes inn under den påfølgende oppdateringsoperasjonen.
Hvis du for eksempel velger en dagfrekvens og tidsplanen oppdateres klokken 04:00, 09:00, 14:00 og 19:00, vil bare 4:00-oppdateringen hver dag inkludere både en opplæringsoperasjon og en oppdateringsoperasjon. De etterfølgende planlagte oppdateringene 09:00, 14:00 og 19:00 er bare oppdateringsoperasjoner som oppdaterer eksisterende aggregasjoner i hurtigbufferen.
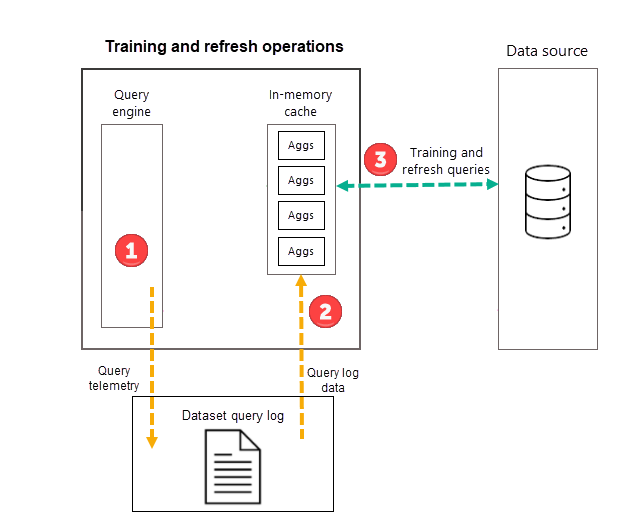
Mens opplæringsoperasjoner evaluerer tidligere spørringer fra spørringsloggen, er resultatene tilstrekkelig nøyaktige for å sikre at fremtidige spørringer dekkes. Det er imidlertid ingen garanti for at fremtidige spørringer returneres av minneaggregasjonsbufferen fordi de nye spørringene kan være annerledes enn de som er avledet fra spørringsloggen. Disse spørringene som ikke returneres av minneaggregasjonsbufferen, sendes til datakilden ved hjelp av DirectQuery. Avhengig av hyppigheten og rangeringen av de nye spørringene, kan aggregasjoner for dem inkluderes i minneaggregasjonsbufferen med neste opplæringsoperasjon.
Opplæringsoperasjonen har en tidsgrense på 60 minutter. Hvis opplæring ikke kan behandle hele spørringsloggen innenfor tidsgrensen, logges et varsel i modelloppdateringsloggen, og opplæringen gjenopptas neste gang den startes. Opplæringssyklusen fullføres og erstatter eksisterende automatiske aggregasjoner når hele spørringsloggen behandles.
Oppdater operasjoner
Som beskrevet tidligere, etter at opplæringsoperasjonen er fullført som en del av den første planlagte oppdateringen for den valgte frekvensen, utfører Power BI en oppdateringsoperasjon som spør og laster inn nye og oppdaterte aggregasjonsdata i minneaggregasjonsbufferen og fjerner eventuelle aggregasjoner som ikke lenger rangeres høyt nok (som bestemmes av opplæringsalgoritmen). Alle etterfølgende oppdateringer for den valgte dag- eller ukefrekvensen er bare oppdateringsoperasjoner som spør datakilden for å oppdatere eksisterende aggregasjonsdata i hurtigbufferen. Ved å bruke vårt forrige eksempel, er 09:00, 14:00 og 19:00 planlagte oppdateringer for den dagen bare oppdateringsoperasjoner.
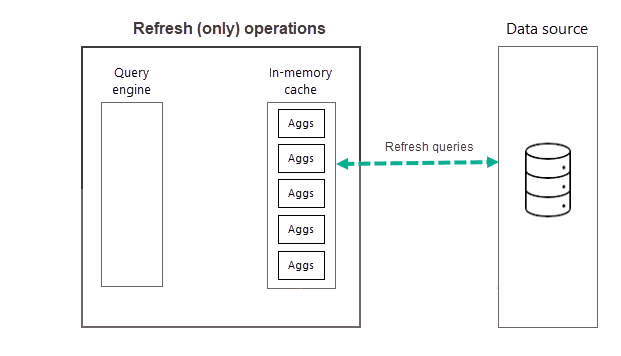
Regelmessige planlagte oppdateringer i løpet av dagen (eller uken) sikrer at aggregasjonsdata i hurtigbufferen er mer oppdatert med data på serverdeldatakilden. Gjennom modell Innstillinger kan du planlegge opptil 48 oppdateringer per dag for å sikre at rapportspørringer som returneres av aggregasjonsbufferen, får resultater basert på de nyeste oppdaterte dataene fra serverdeldatakilden.
Forsiktig!
Opplærings- og oppdateringsoperasjoner er prosess- og ressursintensive for både Power Bi-tjeneste og datakildesystemene. Å øke prosentandelen av spørringer som bruker aggregasjoner betyr at flere aggregasjoner må spørres og beregnes fra datakilder under opplærings- og oppdateringsoperasjoner, noe som øker sannsynligheten for overdreven bruk av systemressurser og potensielt forårsaker tidsavbrudd. Hvis du vil ha mer informasjon, kan du se Finjustering.
Opplæring ved behov
Som nevnt tidligere, kan det hende at en opplæringssyklus ikke fullføres innenfor tidsbegrensningene for én enkelt dataoppdateringssyklus. Hvis du ikke vil vente til neste planlagte oppdateringssyklus som inkluderer opplæring, kan du også utløse automatisk aggregasjonsopplæring ved behov ved å velge Tog og Oppdater nå i modell Innstillinger. Ved hjelp av Train og Refresh Now utløses både en opplæringsoperasjon og en oppdateringsoperasjon. Kontroller modelloppdateringsloggen for å se om den gjeldende operasjonen er fullført før du kjører en annen behovsbetinget opplærings- og oppdateringsoperasjon, om nødvendig.
Oppdater historikk
Hver oppdateringsoperasjon registreres i modelloppdateringsloggen. Viktig informasjon om hver oppdatering vises, inkludert antall minneaggregasjoner i hurtigbufferen som brukes for den konfigurerte spørringsprosenten. Hvis du vil vise oppdateringsloggen, velger du Oppdateringslogg på siden Innstillinger modell. Hvis du vil drille ned litt lenger, velger du Vis detaljer.
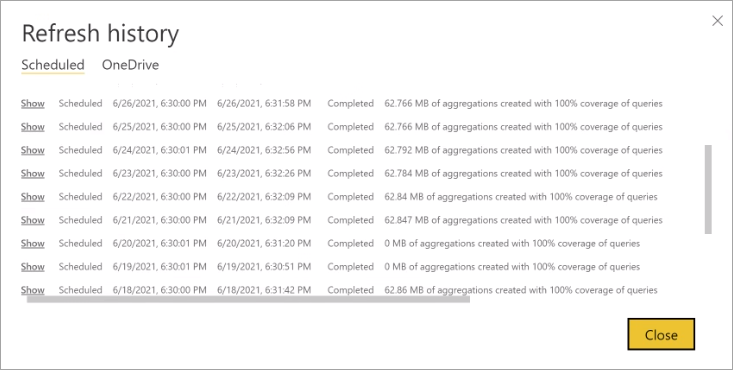
Ved regelmessig å kontrollere oppdateringsloggen kan du sikre at de planlagte oppdateringsoperasjonene fullføres innen en akseptabel periode. Kontroller at oppdateringsoperasjonene fullføres før neste planlagte oppdatering starter.
Opplærings- og oppdateringsfeil
Mens Power BI utfører opplærings- og oppdateringsoperasjoner som en del av den første planlagte oppdateringen for dagen eller uken du velger, implementeres disse operasjonene som separate transaksjoner. Hvis en opplæringsoperasjon ikke kan behandle spørringsloggen fullstendig innenfor tidsbegrensningene, vil Power BI fortsette å oppdatere eksisterende aggregasjoner (og vanlige tabeller i en sammensatt modell) ved hjelp av den forrige opplæringstilstanden. I dette tilfellet vil oppdateringsloggen indikere at oppdateringen var vellykket, og opplæringen kommer til å gjenoppta behandlingen av spørringsloggen neste gang opplæringen startes. Spørringsytelsen kan være mindre optimalisert hvis spørringsmønstrene for klientrapporten ble endret og aggregasjonene ikke ble justert ennå, men det oppnådde ytelsesnivået bør fortsatt være langt bedre enn en ren DirectQuery-modell uten aggregasjoner.
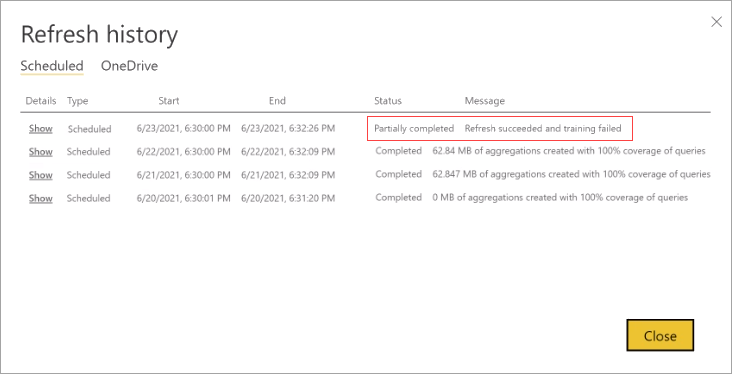
Hvis en opplæringsoperasjon krever for mange sykluser for å fullføre behandlingen av spørringsloggen, bør du vurdere å redusere prosentandelen av spørringer som bruker minneaggregasjonsbufferen i modell Innstillinger. Dette reduserer antall aggregasjoner som er opprettet i hurtigbufferen, men gir mer tid til at opplærings- og oppdateringsoperasjoner fullføres. Hvis du vil ha mer informasjon, kan du se Finjustering.
Hvis opplæringen lykkes, men oppdatering mislykkes, merkes hele oppdateringen som Mislykket fordi resultatet er en utilgjengelig minneaggregasjonsbuffer.
Når du planlegger oppdatering, kan du angi e-postvarsler hvis det oppstår oppdateringsfeil.
Brukerdefinerte og automatiske aggregasjoner
Brukerdefinerte aggregasjoner i Power BI kan konfigureres manuelt basert på skjulte aggregerte tabeller i modellen. Konfigurering av brukerdefinerte aggregasjoner er ofte komplisert, noe som krever et større nivå av datamodellerings- og spørringsoptimaliseringsferdigheter. Automatiske aggregasjoner eliminerer derimot denne kompleksiteten som en del av et AI-drevet system. I motsetning til brukerdefinerte aggregasjoner som forblir statiske, opprettholder Power BI kontinuerlig spørringslogger, og fra disse loggene bestemmer spørringsmønstre basert på maskinlæring (ML) prediktive modelleringsalgoritmer. Forhåndssamlede data beregnes og lagres i minnet basert på analyse av spørringsmønster. Med automatiske aggregasjoner er modeller både selvtrening og selvoptimalisering. Etter hvert som spørringsmønstrene for klientrapporten endres, justeres automatiske aggregasjoner, prioriterer og bufrer disse aggregasjonene som oftest brukes.
Siden automatiske aggregasjoner bygges oppå den eksisterende brukerdefinerte aggregasjonsinfrastrukturen, er det mulig å bruke både brukerdefinerte og automatiske aggregasjoner sammen i samme modell. Dyktige datamodellerere kan definere aggregasjoner for tabeller ved hjelp av DirectQuery, Import (med eller uten trinnvis oppdatering) eller dobbel lagringsmodus, samtidig som de har fordelene med mer automatiske aggregasjoner for spørringer over DirectQuery-tilkoblinger som ikke treffer de brukerdefinerte aggregasjonstabellene. Denne fleksibiliteten muliggjør balanserte arkitekturer som kan redusere spørringsbelastninger og unngå flaskehalser.
Aggregasjoner som opprettes i minnehurtigbufferen av opplæringsalgoritmen for automatiske aggregasjoner, identifiseres som System aggregasjoner. Opplæringsalgoritmen oppretter og sletter bare disse System aggregasjonene etter hvert som rapporteringsspørringer analyseres, og justeringer gjøres for å opprettholde de optimale aggregasjonene for modellen. Både brukerdefinerte og automatiske aggregasjoner oppdateres med oppdatering. Bare de aggregasjonene som er opprettet av automatiske aggregasjoner og merket som systemgenererte aggregasjoner, inkluderes i automatisk aggregasjonsbehandling.
Hurtigbufring av spørring og automatiske aggregasjoner
Power BI Premium støtter også hurtigbufring av spørring i Power BI Premium/Embedded for å opprettholde spørringsresultater. Hurtigbufring av spørring er en annen funksjon enn automatiske aggregasjoner. Med hurtigbufring av spørring bruker Power BI Premium sin lokale hurtigbufringstjeneste til å implementere hurtigbufring, mens automatiske aggregasjoner implementeres på modellnivå. Med hurtigbufring av spørring bufrer tjenesten bare spørringer for den første rapportsideinnlastingen, og derfor forbedres ikke spørringsytelsen når brukere samhandler med en rapport. Derimot optimaliserer automatiske aggregasjoner de fleste rapportspørringer ved å forhåndsbufre aggregerte spørringsresultater, inkludert spørringene som genereres når brukere samhandler med rapporter. Hurtigbufring av spørringer og automatiske aggregasjoner kan begge aktiveres for en modell, men det er sannsynligvis ikke nødvendig.
Overvåk med Azure Log Analytics
Azure Log Analytics (LA) er en tjeneste i Azure Monitor som Power BI kan bruke til å lagre aktivitetslogger. Med Azure Monitor-programserien kan du samle inn, analysere og handle på telemetridata fra Azure og lokale miljøer. Den tilbyr langsiktig lagring, et ad hoc-spørringsgrensesnitt og API-tilgang for å tillate dataeksport og integrering med andre systemer. Hvis du vil ha mer informasjon, kan du se Bruke Azure Log Analytics i Power BI.
Hvis Power BI er konfigurert med en Azure LA-konto, som beskrevet i konfigurering av Azure Log Analytics for Power BI, kan du analysere suksessraten for automatiske aggregasjoner. Du kan blant annet avgjøre om rapportspørringer besvares fra minnehurtigbufferen.
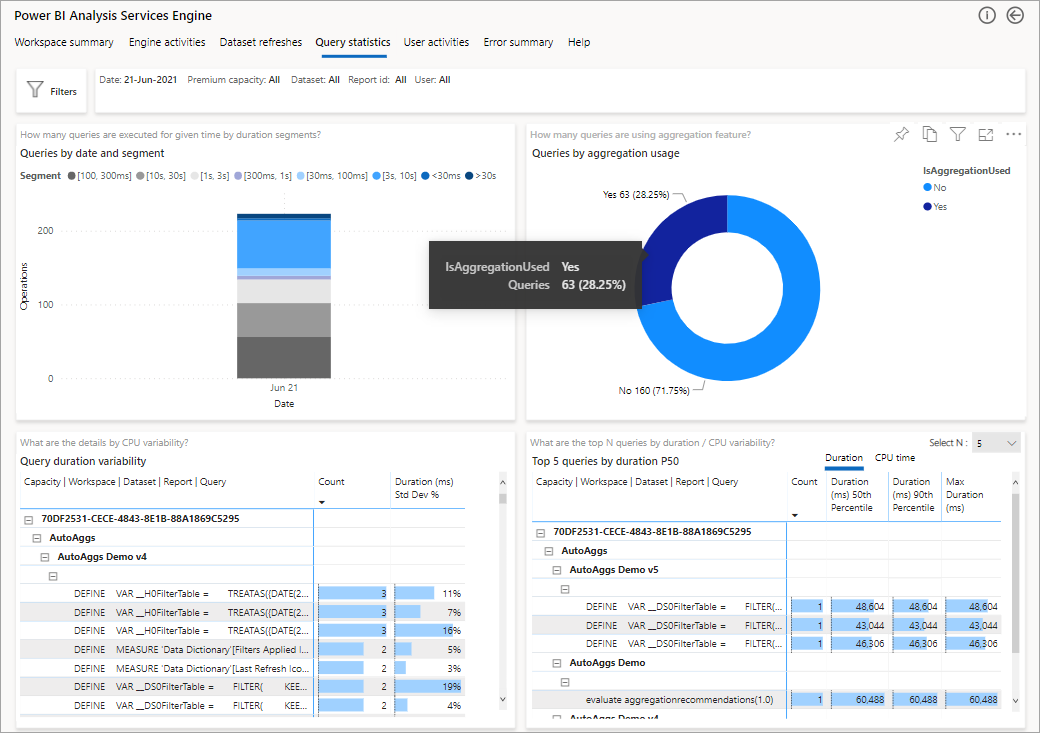
Hvis du vil bruke denne muligheten, kan du laste ned PBIT-malen og koble den til logganalysekontoen, som beskrevet i dette blogginnlegget i Power BI. I rapporten kan du vise data på tre forskjellige nivåer: Sammendragsvisning, visning av DAX-spørringsnivå og visning av SQL-spørringsnivå.
Bildet nedenfor viser sammendragssiden for alle spørringene. Som du kan se, viser det merkede diagrammet prosentandelen av totalt antall spørringer som ble oppfylt av aggregasjoner kontra de som måtte bruke datakilden.
Det neste trinnet for å dykke dypere er å se på bruken av aggregasjoner på et DAX-spørringsnivå. Høyreklikk en DAX-spørring fra listen (nederst til venstre) >Drill gjennom>spørringsloggen.
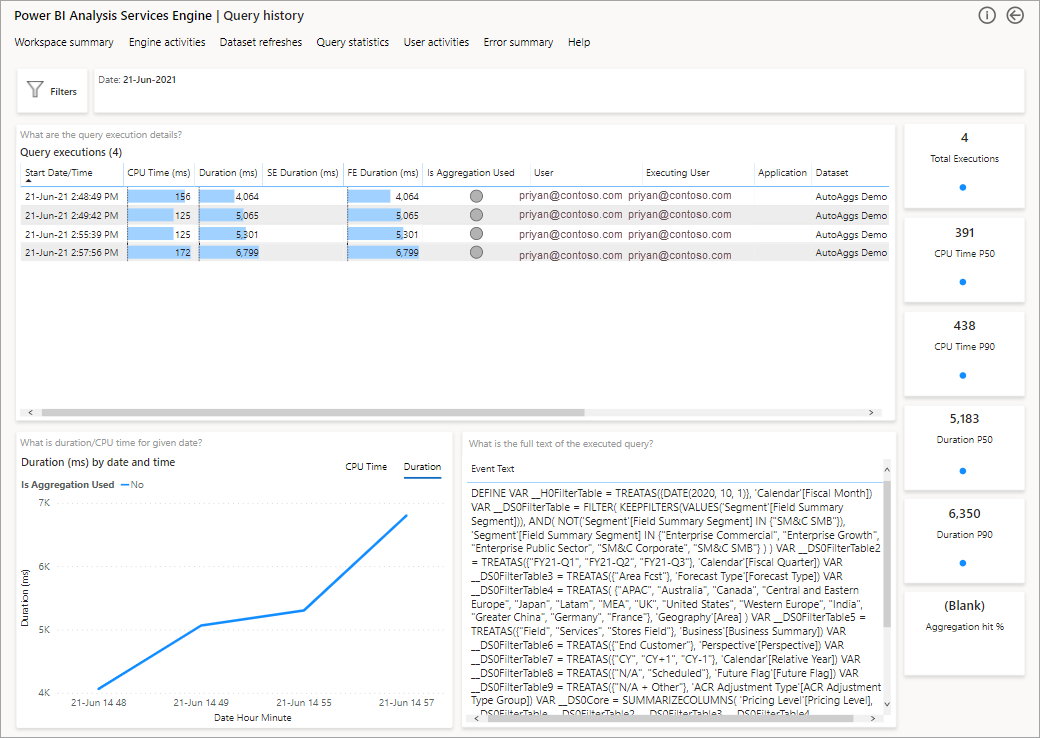
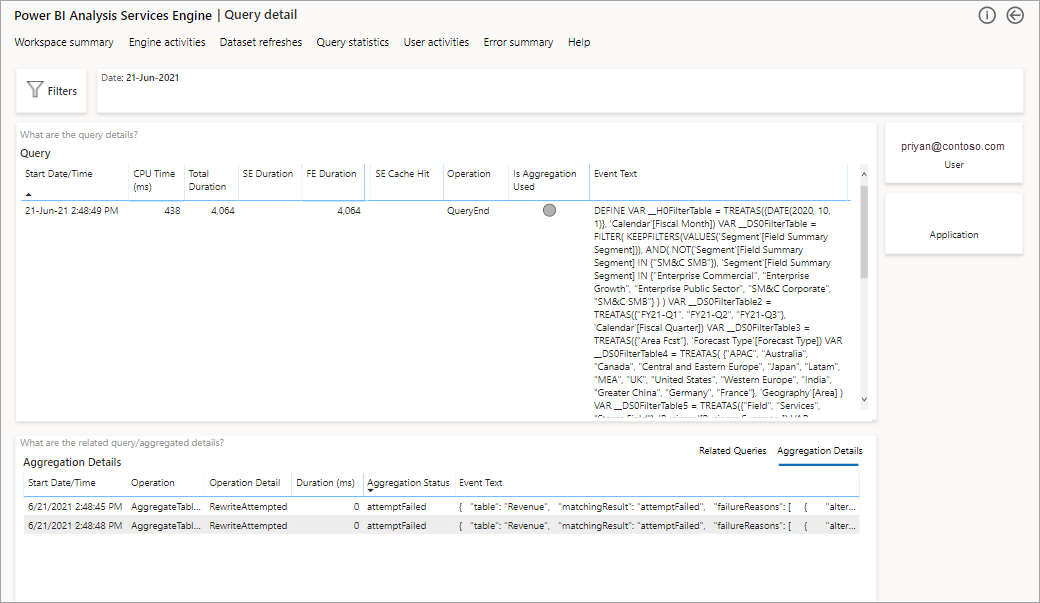
Dette gir deg en liste over alle relevante spørringer. Drill gjennom til neste nivå for å vise flere aggregasjonsdetaljer.
Administrasjon av programlivssyklus
Fra utvikling til test og fra test til produksjon, modeller med automatiske aggregasjoner aktivert har spesielle krav til ALM-løsninger.
Datasamlebånd for distribusjon
Med utrullingssamlebånd kan Power BI kopiere modellene med modellkonfigurasjonen fra gjeldende fase til målfasen. Automatiske aggregasjoner må imidlertid tilbakestilles i målfasen fordi innstillingene ikke overføres fra gjeldende til målfase. Du kan også distribuere innhold programmatisk ved hjelp av REST-API-er for utrullingssamlebånd. Hvis du vil ha mer informasjon om denne prosessen, kan du se Automatisere utrullingssamlebåndet ved hjelp av API-er og DevOps.
Egendefinerte ALM-løsninger
Hvis du bruker en egendefinert ALM-løsning basert på XMLA-endepunkter, må du huske på at løsningen kanskje kan kopiere systemgenererte og brukeropprettede aggregasjonstabeller som en del av modellmetadataene. Du må imidlertid aktivere automatiske aggregasjoner etter hvert distribusjonstrinn i målfasen manuelt. Power BI beholder konfigurasjonen hvis du overskriver en eksisterende modell.
Merk
Hvis du laster opp eller publiserer en modell på nytt som en del av en Power BI Desktop-fil (PBIX), går systemopprettede aggregasjonstabeller tapt når Power BI erstatter den eksisterende modellen med alle metadataene og dataene i målarbeidsområdet.
Endre en modell
Når du har endret en modell med automatiske aggregasjoner aktivert via XMLA-endepunkter, for eksempel legge til eller fjerne tabeller, bevarer Power BI eventuelle eksisterende aggregasjoner som kan være og fjerner de som ikke lenger er nødvendige eller relevante. Spørringsytelse kan påvirkes til neste opplæringsfase utløses.
Metadataelementer
Modeller med automatiske aggregasjoner aktivert inneholder unike systemgenererte aggregasjonstabeller. Aggregasjonstabeller er ikke synlige for brukere i rapporteringsverktøy. De er synlige gjennom XMLA-endepunktet ved hjelp av verktøy med Analysis Services-klientbiblioteker versjon 19.22.5 og nyere. Når du arbeider med modeller med automatiske aggregasjoner aktivert, må du oppgradere datamodellerings- og administrasjonsverktøyene til den nyeste versjonen av klientbibliotekene. For SQL Server Management Studio (SSMS) oppgraderer du til SSMS versjon 18.9.2 eller nyere. Tidligere versjoner av SSMS kan ikke nummerere tabeller eller skript ut disse modellene.
Automatiske aggregasjonstabeller identifiseres av en SystemManaged tabellegenskap, som er ny tabellobjektmodell (TOM) i Analysis Services-klientbiblioteker versjon 19.22.5 og nyere. Kodesnutten SystemManaged nedenfor viser egenskapen som er satt til true for automatiske aggregasjonstabeller og false for vanlige tabeller.
using System;
using System.Collections.Generic;
using System.Linq;
using Microsoft.AnalysisServices.Tabular;
namespace AutoAggs
{
class Program
{
static void Main(string[] args)
{
string workspaceUri = "<Specify the URL of the workspace where your model resides>";
string datasetName = "<Specify the name of your dataset>";
Server sourceWorkspace = new Server();
sourceWorkspace.Connect(workspaceUri);
Database dataset = sourceWorkspace.Databases.GetByName(datasetName);
// Enumerate system-managed tables.
IEnumerable<Table> aggregationsTables = dataset.Model.Tables.Where(tbl => tbl.SystemManaged == true);
if (aggregationsTables.Any())
{
Console.WriteLine("The following auto aggs tables exist in this dataset:");
foreach (Table table in aggregationsTables)
{
Console.WriteLine($"\t{table.Name}");
}
}
else
{
Console.WriteLine($"This dataset has no auto aggs tables.");
}
Console.WriteLine("\n\rPress [Enter] to exit the sample app...");
Console.ReadLine();
}
}
}
Kjøring av denne kodesnutten sender automatiske aggregasjonstabeller som for øyeblikket er inkludert i modellen i en konsoll.
Husk at aggregasjonstabeller endres hele tiden etter hvert som opplæringsoperasjoner bestemmer de optimale aggregasjonene som skal inkluderes i minneaggregasjonsbufferen.
Viktig
Power BI administrerer automatiske aggregasjoner systemgenererte tabellobjekter. Ikke slett eller endre disse tabellene selv. Hvis du gjør dette, kan det føre til redusert ytelse.
Power BI opprettholder modellkonfigurasjonen utenfor modellen. Tilstedeværelsen av en systemadministrert aggregasjonstabell i en modell betyr ikke nødvendigvis at modellen faktisk er aktivert for automatisk aggregasjonsopplæring. Hvis du med andre ord skripter ut en fullstendig modelldefinisjon for en modell med automatiske aggregasjoner aktivert, og oppretter en ny kopi av modellen (med et annet navn/arbeidsområde/kapasitet), er ikke den nye resultatmodellen aktivert for automatisk aggregasjonsopplæring. Du må fortsatt aktivere automatisk aggregasjonsopplæring for den nye modellen i modell Innstillinger.
Hensyn og begrensninger
Når du bruker automatiske aggregasjoner, må du huske på følgende:
- Aggregasjoner støtter ikke dynamiske M-spørringsparametere.
- SQL-spørringer som genereres i den innledende opplæringsfasen, kan generere betydelig belastning for datalageret. Hvis opplæringen fortsetter å fullføres ufullstendig, og du kan bekrefte på datalagersiden at spørringene støter på et tidsavbrudd, bør du vurdere å skalere datalageret midlertidig for å møte opplæringskravet.
- Aggregasjoner som er lagret i minneaggregasjonsbufferen, beregnes kanskje ikke på de nyeste dataene i datakilden. I motsetning til ren DirectQuery, og mer som vanlige importtabeller, er det en ventetid mellom oppdateringer på datakilden og aggregasjonsdata som er lagret i minneaggregasjonsbufferen. Selv om det alltid vil være en viss grad av ventetid, kan det reduseres gjennom en effektiv oppdateringsplan.
- Hvis du vil optimalisere ytelsen ytterligere, setter du alle dimensjonstabeller til dobbel modus og lar faktatabeller stå i DirectQuery-modus.
- Automatiske aggregasjoner er ikke tilgjengelige med Power BI Pro, Azure Analysis Services eller SQL Server Analysis Services.
- Power BI støtter ikke nedlasting av modeller med automatiske aggregasjoner aktivert. Hvis du lastet opp eller publiserte en Power BI Desktop-fil (PBIX) til Power BI og deretter aktiverte automatiske aggregasjoner, kan du ikke lenger laste ned PBIX-filen. Kontroller at du beholder en kopi av PBIX-filen lokalt.
- Automatiske aggregasjoner med eksterne tabeller i Azure Synapse Analytics støttes ikke. Du kan nummerere eksterne tabeller i Synapse ved hjelp av følgende SQL-spørring:
SELECT SCHEMA_NAME(schema_id) AS schema_name, name AS table_name FROM sys.external_tables. - Automatiske aggregasjoner er bare tilgjengelige for modeller som bruker forbedrede metadata. Hvis du vil aktivere automatiske aggregasjoner for en eldre modell, oppgraderer du modellen til forbedrede metadata først. Hvis du vil ha mer informasjon, kan du se Bruke forbedrede modellmetadata.
- Ikke aktiver automatiske aggregasjoner hvis DirectQuery-datakilden er konfigurert for enkel pålogging og bruker dynamiske datavisninger eller sikkerhetskontroller for å begrense dataene en bruker har tilgang til. Automatiske aggregasjoner er ikke klar over disse kontrollene på datakildenivå, noe som gjør det umulig å sikre at riktige data angis per bruker. Opplæring loggfører en advarsel i oppdateringsloggen om at den oppdaget en datakilde som er konfigurert for enkel pålogging og hoppet over tabellene som bruker denne datakilden. Hvis det er mulig, kan du deaktivere SSO for disse datakildene for å dra full nytte av de optimaliserte automatiske aggregasjonene for spørringsytelse.
- Ikke aktiver automatiske aggregasjoner hvis modellen bare inneholder hybridtabeller for å unngå unødvendig behandling av indirekte kostnader. En hybridtabell bruker både importpartisjoner og en DirectQuery-partisjon. Et vanlig scenario er trinnvis oppdatering med sanntidsdata der en DirectQuery-partisjon henter transaksjoner fra datakilden som oppstod etter den siste dataoppdateringen. Power BI importerer imidlertid aggregasjoner under oppdatering. Automatiske aggregasjoner kan ikke inkludere transaksjoner som oppstod etter den siste dataoppdateringen. Opplæring loggfører en advarsel i oppdateringsloggen om at den oppdaget og hoppet over hybridtabeller.
- Beregnede kolonner vurderes ikke for automatiske aggregasjoner. Hvis du bruker en beregnet kolonne i DirectQuery-modus, for eksempel ved å bruke
COMBINEVALUESDAX-funksjonen til å opprette en relasjon basert på flere kolonner fra to DirectQuery-tabeller, vil ikke de tilsvarende rapportspørringene treffe minneaggregasjonsbufferen. - Automatiske aggregasjoner er bare tilgjengelige i Power Bi-tjeneste. Power BI Desktop oppretter ikke systemgenererte aggregasjonstabeller.
- Hvis du endrer metadataene for en modell med automatiske aggregasjoner aktivert, kan spørringsytelsen reduseres til neste opplæringsprosess utløses. Som en anbefalt fremgangsmåte bør du slippe de automatiske aggregasjonene, gjøre endringene og deretter omskolere deg.
- Ikke endre eller slett systemgenererte aggregasjonstabeller med mindre du har automatiske aggregasjoner deaktivert og rydder opp i modellen. Systemet tar ansvar for å administrere disse objektene.
Fellesskap
Power BI har et levende fellesskap der MVPer, BI-eksperter og kolleger deler ekspertise i diskusjonsgrupper, videoer, blogger og mer. Når du lærer om automatiske aggregasjoner, må du sjekke ut disse andre ressursene: