Opprett visualiseringer for viktige påvirkere
GJELDER FOR:![]() Power BI Desktop
Power BI Desktop ![]() Power Bi-tjeneste
Power Bi-tjeneste
Visualobjektet for viktige påvirkere hjelper deg med å forstå faktorene som driver en metrikkverdi du er interessert i. Den analyserer dataene dine, rangerer faktorene som betyr noe, og viser dem som viktige påvirkere. Anta for eksempel at du vil finne ut hva som påvirker ansattes omsetning, som også kalles frafall. En faktor kan være lengden på ansettelseskontrakten, og en annen faktor kan være pendlingstid.
Når du skal bruke viktige påvirkere
Visualobjektet for viktige påvirkere er et godt valg hvis du vil:
- Se hvilke faktorer som påvirker måleverdien som analyseres.
- Sammenlign den relative betydningen av disse faktorene. Påvirker for eksempel kortsiktige kontrakter frafall mer enn langsiktige kontrakter?
Funksjoner i visualobjektet for viktige påvirkere
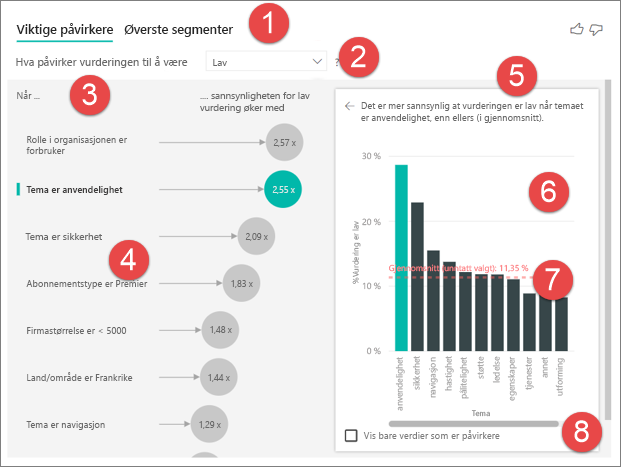
Faner: Velg en fane for å bytte mellom visninger. Viktige påvirkere viser deg de viktigste bidragsyterne til den valgte metriske verdien. De øverste segmentene viser deg de øverste segmentene som bidrar til den valgte metriske verdien. Et segment består av en kombinasjon av verdier. Ett segment kan for eksempel være forbrukere som har vært kunder i minst 20 år og bor i det vestlige området.
Rullegardinboks: Verdien av metrikkverdien som undersøkes. I dette eksemplet kan du se på metrisk vurdering. Den valgte verdien er Lav.
Omskriving: Det hjelper deg med å tolke visualobjektet i den venstre ruten.
Venstre rute: Ruten til venstre inneholder ett visualobjekt. I dette tilfellet viser den venstre ruten en liste over de viktigste påvirkerne.
Omskriving: Det hjelper deg med å tolke visualobjektet i ruten til høyre.
Høyre rute: Ruten til høyre inneholder ett visualobjekt. I dette tilfellet viser stolpediagrammet alle verdiene for det viktige påvirkertemaet som ble valgt i ruten til venstre. Den spesifikke verdien av brukervennlighet fra den venstre ruten vises i grønt. Alle de andre verdiene for tema vises i svart.
Gjennomsnittslinje: Gjennomsnittet beregnes for alle mulige verdier for Tema unntatt brukervennlighet (som er den valgte påvirkeren). Beregningen gjelder derfor for alle verdiene i svart. Den forteller deg hvilken prosentandel av de andre temaene som hadde en lav vurdering. I dette tilfellet hadde 11,35 % lav vurdering (vist av den prikkede linjen).
Avmerkingsboks: Filtrerer ut visualobjektet i ruten til høyre for bare å vise verdier som er påvirkere for dette feltet. I dette eksemplet filtreres visualobjektet for å vise brukervennlighet, sikkerhet og navigasjon.
Analysere en metrikkverdi som er kategorisk
Se denne videoen for å lære hvordan du oppretter et visualobjekt for viktige påvirkere med en kategorisk metrikkverdi. Følg deretter trinnene for å opprette en.
Merk
Denne videoen kan bruke tidligere versjoner av Power BI Desktop eller Power Bi-tjeneste.
- Produktsjefen vil at du skal finne ut hvilke faktorer som fører til at kundene legger igjen negative vurderinger om skytjenesten. Hvis du vil følge med i Power BI Desktop, åpner du PBIX-filen for tilbakemelding fra kunder.
Merk
Datasettet kundetilbakemelding er basert på [Moro et al., 2014] S. Moro, P. Cortez og P. Rita. "En datadrevet tilnærming til å forutsi suksessen til banktelemarketing." Beslutningsstøttesystemer, Elsevier, 62:22-31, juni 2014.
Velg ikonet Viktige påvirkere under Bygg visualobjekt i Visualiseringer-ruten.
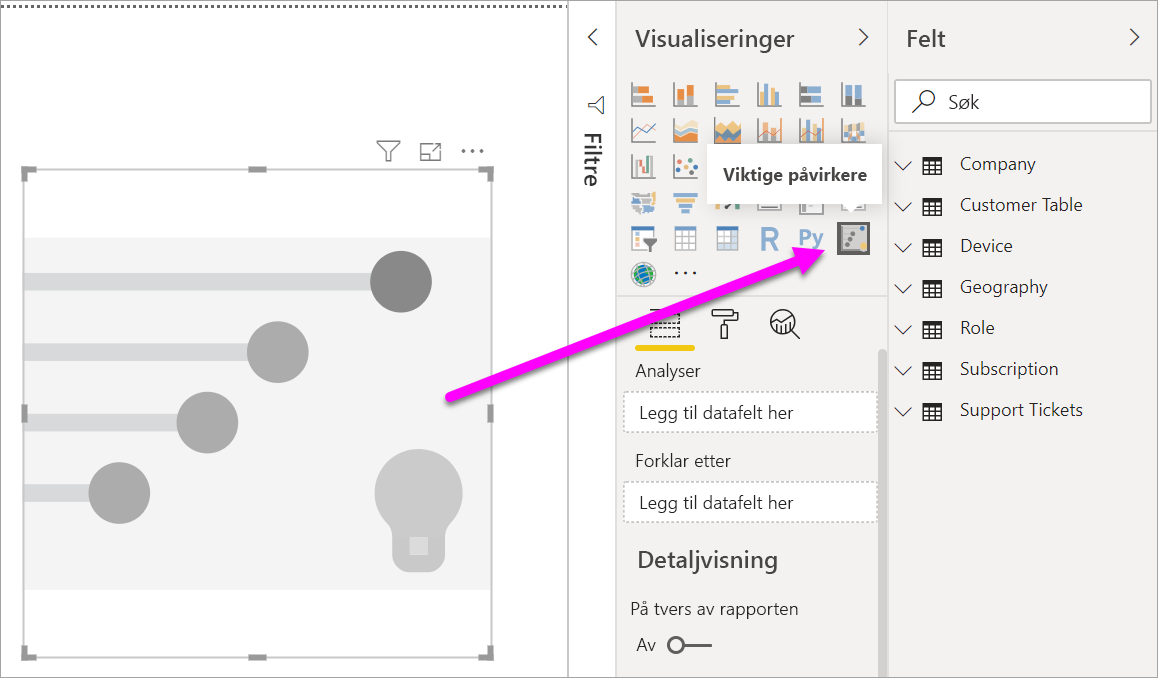
Flytt måleverdien du vil undersøke, til Analyser-feltet . Hvis du vil se hva som driver en kundevurdering av tjenesten til å være lav, velger du Kundetabellvurdering>.
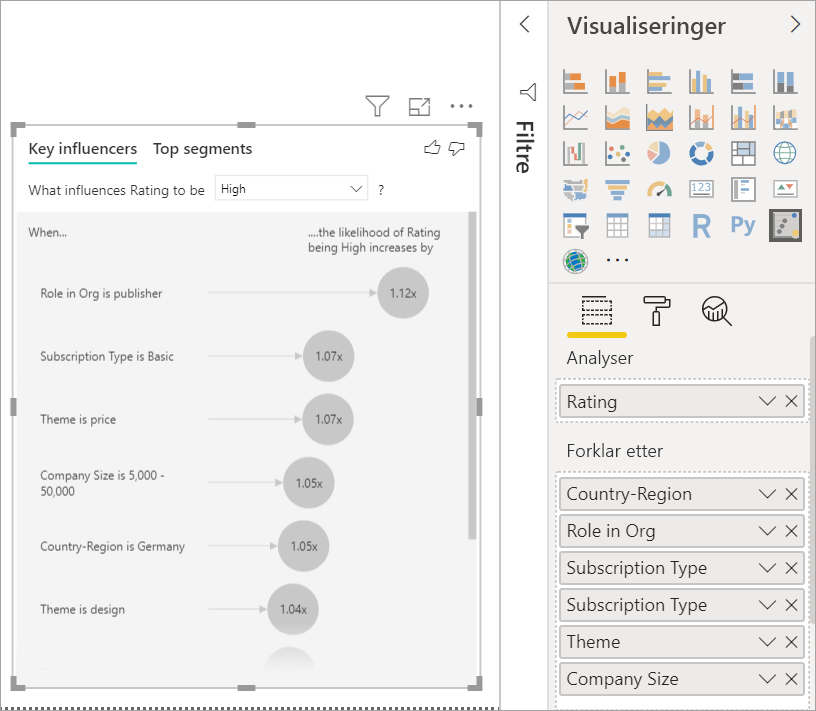
Flytt felt som du tror kan påvirke vurdering til Forklar etter-feltet . Du kan flytte så mange felt du vil. I dette tilfellet begynner du med:
- Country-Region
- Rolle i organisasjonen
- Abonnementstype
- Firmastørrelse
- Theme
La Utvid etter-feltet stå tomt. Dette feltet brukes bare når du analyserer et mål eller et summert felt.
Hvis du vil fokusere på de negative vurderingene, velger du Lav i rullegardinlisten Hva påvirker vurdering som skal være.
Analysen kjører på tabellnivået i feltet som analyseres. I dette tilfellet er det metrikkverdien for vurdering . Denne måleverdien er definert på kundenivå. Hver kunde har gitt enten en høy poengsum eller en lav poengsum. Alle forklarende faktorer må defineres på kundenivå for at visualobjektet skal kunne benytte seg av dem.
I det forrige eksemplet har alle forklarende faktorer enten en en-til-en eller en mange-til-en-relasjon med metrikkverdien. I dette tilfellet tilordnet hver kunde et enkelt tema til vurderingen. På samme måte kommer kunder fra ett land eller område, har én medlemstype og har én rolle i organisasjonen. Forklarende faktorer er allerede attributter for en kunde, og ingen transformasjoner er nødvendig. Visualobjektet kan gjøre umiddelbar bruk av dem.
Senere i opplæringen ser du på mer komplekse eksempler som har én-til-mange-relasjoner. I slike tilfeller må kolonnene først aggregeres ned til kundenivået før du kan kjøre analysen.
Mål og aggregater som brukes som forklarende faktorer, evalueres også på tabellnivå i analysemetrikken . Noen eksempler vises senere i denne artikkelen.
Tolke kategoriske viktige påvirkere
La oss ta en titt på de viktigste påvirkerne for lave vurderinger.
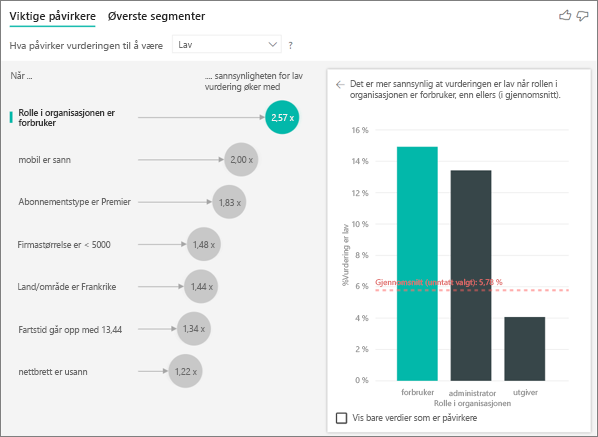
Topp enkeltfaktor som påvirker sannsynligheten for en lav vurdering
Kunden i dette eksemplet kan ha tre roller: forbruker, administrator og utgiver. Å være forbruker er den viktigste faktoren som bidrar til en lav vurdering.
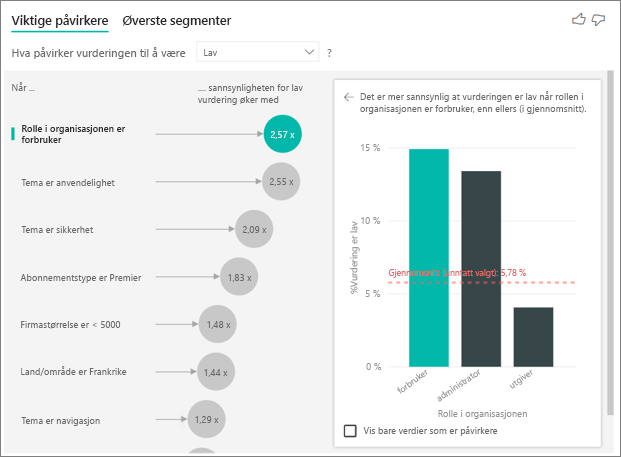
Mer nøyaktig, forbrukerne er 2,57 ganger mer sannsynlig å gi tjenesten en negativ score. Diagrammet for viktige påvirkere viser rolle i organisasjonen som forbruker først i listen til venstre. Ved å velge Rolle i organisasjonen er forbruker, viser Power BI flere detaljer i ruten til høyre. Den komparative effekten av hver rolle på sannsynligheten for en lav vurdering vises.
- 14,93% av forbrukerne gir en lav score.
- I gjennomsnitt gir alle andre roller en lav poengsum 5,78 % av tiden.
- Forbrukerne er 2,57 ganger mer sannsynlig å gi en lav score sammenlignet med alle andre roller. Du kan bestemme denne poengsummen ved å dele den grønne linjen med den røde prikkede linjen.
Andre enkeltfaktor som påvirker sannsynligheten for en lav vurdering
Visualobjektet for viktige påvirkere sammenligner og rangerer faktorer fra mange forskjellige variabler. Den andre påvirkeren har ingenting å gjøre med Role in Org. Velg den andre påvirkeren i listen, som er Tema er brukervennlighet.
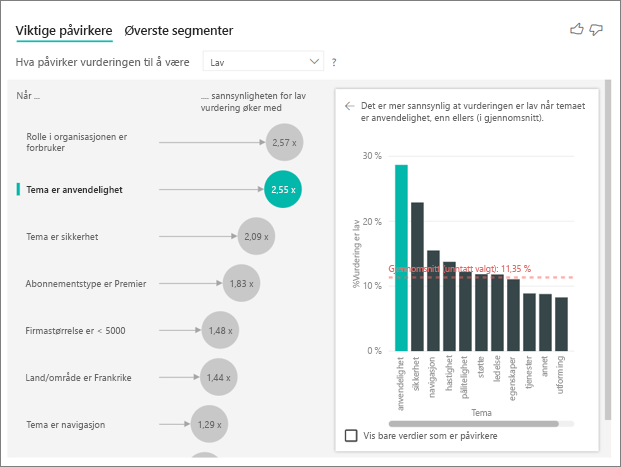
Den nest viktigste faktoren er relatert til temaet for kundens gjennomgang. Kunder som kommenterte brukervennligheten til produktet, hadde 2,55 ganger større sannsynlighet for å gi en lav poengsum sammenlignet med kunder som kommenterte andre temaer, for eksempel pålitelighet, design eller hastighet.
Mellom visualobjektene ble gjennomsnittet, som vises av den røde prikkede linjen, endret fra 5,78 % til 11,35 %. Gjennomsnittet er dynamisk fordi det er basert på gjennomsnittet av alle andre verdier. For den første påvirkeren ekskluderte gjennomsnittet kunderollen. For den andre påvirkeren utelukket det brukervennlighetstemaet.
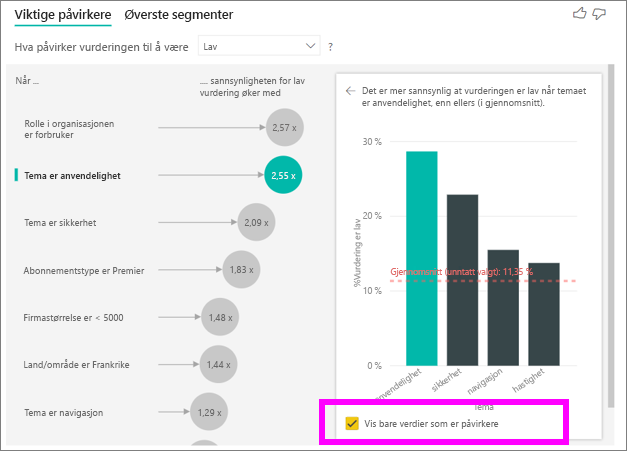
Merk av for Vis bare verdier som er påvirkere for å filtrere ved hjelp av bare de innflytelsesrike verdiene. I dette tilfellet er de rollene som driver en lav poengsum. 12 temaer reduseres til de fire som Power BI identifiserte som temaene som driver lave vurderinger.
Samhandle med andre visualobjekter
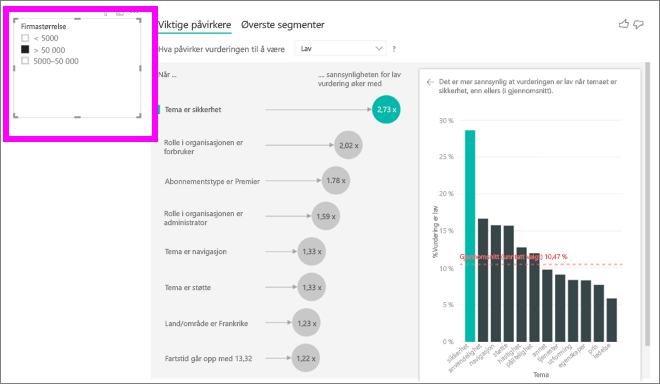
Hver gang du velger en slicer, et filter eller et annet visualobjekt på lerretet, kjører visualobjektet for viktige påvirkere analysen på nytt på den nye delen av dataene. Du kan for eksempel flytte firmastørrelse til rapporten og bruke den som slicer. Bruk den til å se om de viktigste påvirkerne for bedriftskundene er annerledes enn den generelle populasjonen. En bedriftsstørrelse er større enn 50 000 ansatte.
Velg >50 000 for å kjøre analysen på nytt, og du kan se at påvirkerne endret seg. For store bedriftskunder har den beste påvirkeren for lave vurderinger et tema relatert til sikkerhet. Det kan være lurt å undersøke nærmere for å se om det finnes bestemte sikkerhetsfunksjoner som de store kundene er misfornøyde med.
Tolke kontinuerlige viktige påvirkere
Så langt har du sett hvordan du bruker visualobjektet til å utforske hvordan ulike kategoriske felt påvirker lave vurderinger. Det er også mulig å ha kontinuerlige faktorer som alder, høyde og pris i Forklar etter-feltet . La oss se på hva som skjer når Tenure flyttes fra kundetabellen til Explain by. Tenure viser hvor lenge en kunde har brukt tjenesten.
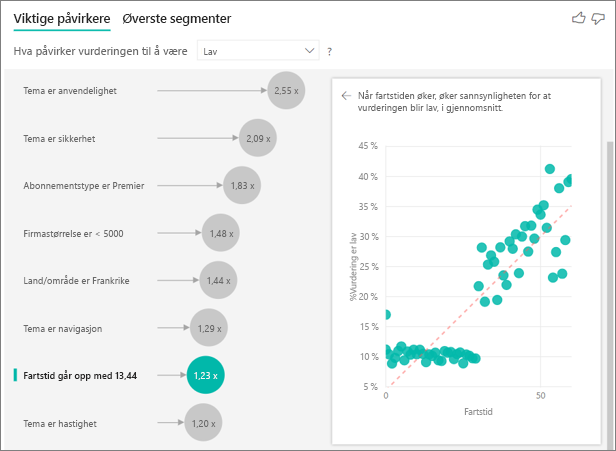
Etter hvert som perioden øker, øker sannsynligheten for å få en lavere vurdering også. Denne trenden tyder på at de langsiktige kundene er mer sannsynlig å gi en negativ score. Denne innsikten er interessant, og en som du kanskje vil følge opp senere.
Visualiseringen viser at hver gang perioden går opp med 13,44 måneder, øker sannsynligheten for en lav vurdering i gjennomsnitt med 1,23 ganger. I dette tilfellet viser 13,44 måneder standardavviket for tid. Så innsikten du får, ser på hvordan økende periode med et standardbeløp, som er standardavviket for tid, påvirker sannsynligheten for å motta en lav vurdering.
Punkttegningen i den høyre ruten tegner inn den gjennomsnittlige prosentandelen av lave vurderinger for hver verdi av tid. Det uthever skråningen med en trendlinje.
Binned kontinuerlige viktige påvirkere
I noen tilfeller kan det hende at kontinuerlige faktorer automatisk ble gjort om til kategoriske faktorer. Hvis relasjonen mellom variablene ikke er lineær, kan vi ikke beskrive relasjonen som ganske enkelt å øke eller redusere (som vi gjorde i eksemplet ovenfor).
Vi kjører korrelasjonstester for å finne ut hvor lineær påvirkeren er med hensyn til målet. Hvis målet er kontinuerlig, kjører vi Pearson-korrelasjon, og hvis målet er kategorisk, kjører vi punktbierialkorrelasjonstester. Hvis vi oppdager at relasjonen ikke er tilstrekkelig lineær, utfører vi overvåket binning og genererer maksimalt fem hyller. Hvis du vil finne ut hvilke hyller som gir mest mening, bruker vi en binningmetode med tilsyn som ser på forholdet mellom forklarende faktor og målet som analyseres.
Tolke mål og aggregater som viktige påvirkere
Du kan bruke mål og aggregater som forklarende faktorer i analysen. Det kan for eksempel hende du vil se hvilken effekt antallet kundestøtteforespørsler eller gjennomsnittlig varighet for en åpen billett har på poengsummen du mottar.
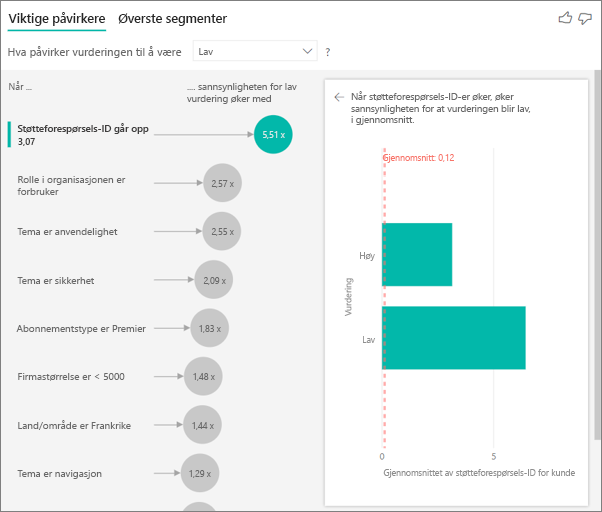
I dette tilfellet vil du se om antall støtteforespørsler som en kunde har påvirker poengsummen de gir. Nå henter du inn støtteforespørsels-ID fra støttebilletttabellen. Siden en kunde kan ha flere støtteforespørsler, aggregerer du ID-en til kundenivået. Aggregasjon er viktig fordi analysen kjører på kundenivå, så alle drivere må defineres på dette nivået av detaljnivå.
La oss se på antall ID-er. Hver kunderad har et antall støtteforespørsler som er knyttet til den. I dette tilfellet, etter hvert som antall støttebilletter øker, går sannsynligheten for at vurderingen er lav opp 4,08 ganger. Visualobjektet til høyre viser gjennomsnittlig antall støtteforespørsler etter ulike vurderingsverdier evaluert på kundenivå.
Tolke resultatene: De øverste segmentene
Du kan bruke fanen Viktige påvirkere til å vurdere hver faktor enkeltvis. Du kan også bruke fanen Øverste segmenter for å se hvordan en kombinasjon av faktorer påvirker måleverdien du analyserer.
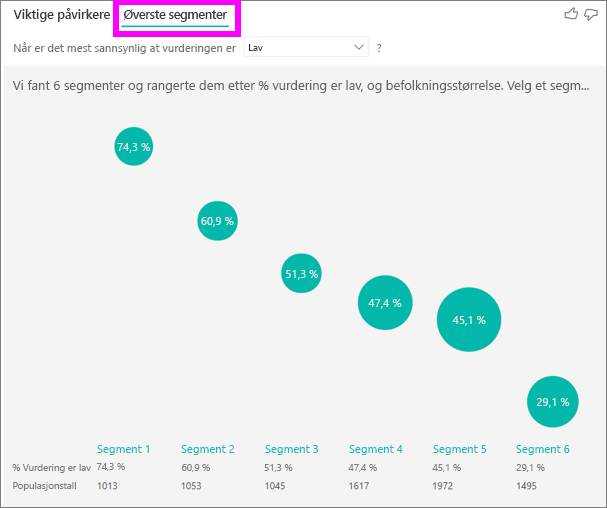
De øverste segmentene viser først en oversikt over alle segmentene som Power BI oppdaget. Følgende eksempel viser at seks segmenter ble funnet. Disse segmentene rangeres etter prosentandelen av lave vurderinger i segmentet. Segment 1 har for eksempel 74,3 % kundevurderinger som er lave. Jo høyere boblen er, jo høyere er andelen lave vurderinger. Størrelsen på boblen representerer hvor mange kunder som er innenfor segmentet.
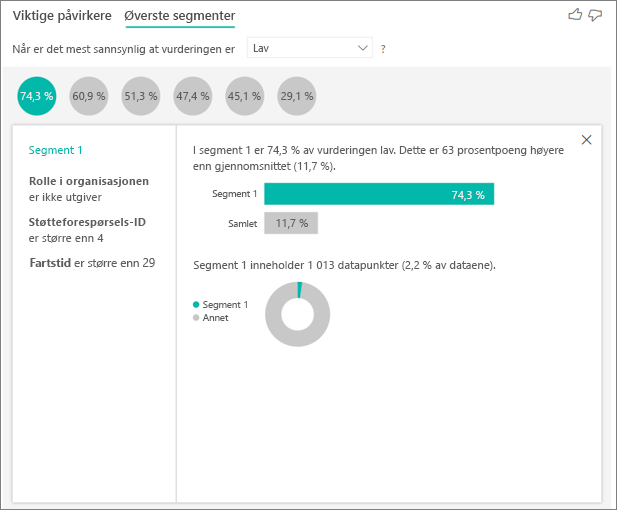
Hvis du velger en boble, vises detaljene for segmentet. Hvis du for eksempel velger Segment 1, finner du ut at det består av relativt etablerte kunder. De har vært kunder i over 29 måneder og har mer enn fire støttebilletter. Til slutt er de ikke utgivere, så de er enten forbrukere eller administratorer.
I denne gruppen ga 74,3 % av kundene en lav vurdering. Den gjennomsnittlige kunden ga en lav vurdering 11,7% av tiden, så dette segmentet har en større andel av lave vurderinger. Det er 63 prosentpoeng høyere. Segment 1 inneholder også omtrent 2,2 % av dataene, så det representerer en adresserbar del av populasjonen.
Legge til antall
Noen ganger kan en påvirker ha en betydelig effekt, men representerer lite av dataene. Tema er for eksempel brukervennlighet er den tredje største påvirkeren for lave vurderinger. Det kan imidlertid bare ha vært en håndfull kunder som klaget over brukervennlighet. Antall kan hjelpe deg med å prioritere hvilke påvirkere du vil fokusere på.
Du kan aktivere antall gjennom Analyse-kortet i formateringsruten.
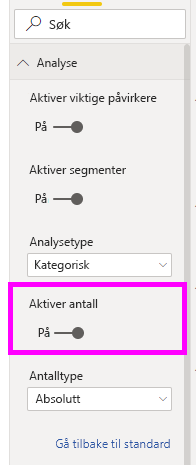
Når antall er aktivert, ser du en ring rundt boblen til hver påvirker, som representerer den omtrentlige prosentandelen av data som påvirkeren inneholder. Jo mer av boblen ringsirklene er, jo mer data inneholder den. Vi kan se at tema er brukervennlighet inneholder en liten andel data.
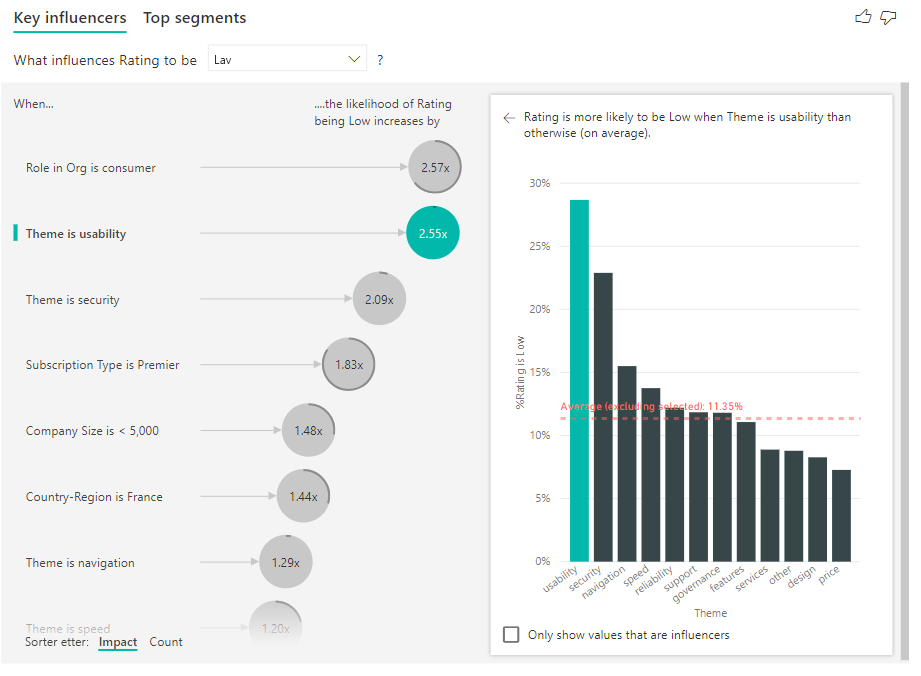
Du kan også bruke veksleknappen Sorter etter nederst til venstre i visualobjektet for å sortere boblene etter antall først i stedet for innvirkning. Abonnementstype er Premier er den beste påvirkeren basert på antall.
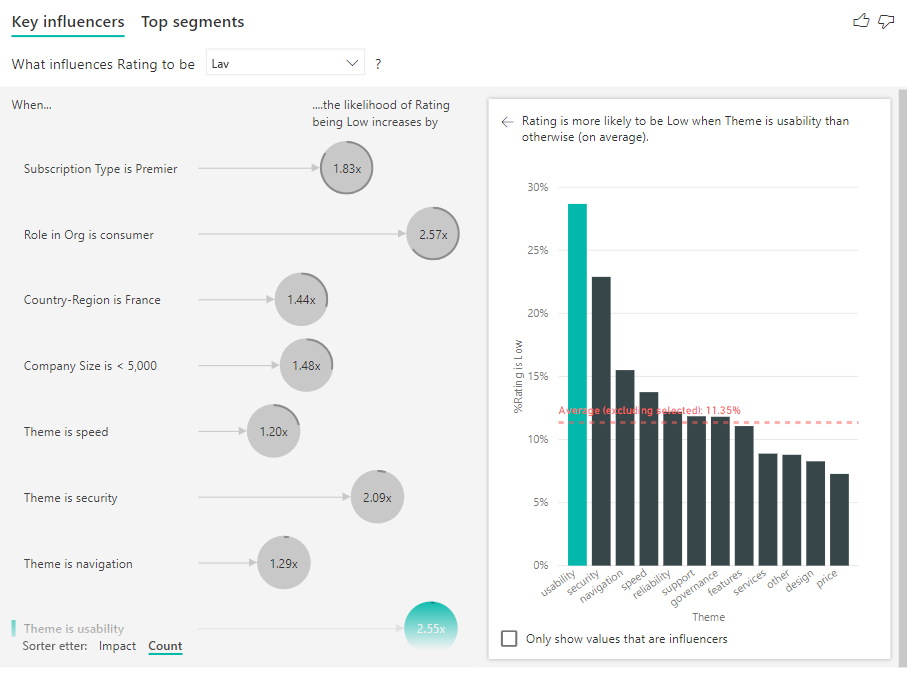
Å ha en full ring rundt sirkelen betyr at påvirkeren inneholder 100 % av dataene. Du kan endre antalltypen slik at den er relativ til den maksimale påvirkeren ved hjelp av rullegardinlisten Antall typer i Analyse-kortet i formateringsruten. Nå vil påvirkeren med mest datamengde representeres av en full ring, og alle andre tellinger vil være i forhold til den.
Analysere en metrikkverdi som er numerisk
Hvis du flytter et usammendragsfelt til Analyser-feltet , har du et valg om hvordan du skal håndtere dette scenarioet. Du kan endre virkemåten til visualobjektet ved å gå inn i formateringsruten og bytte mellom kategorisk analysetype og kontinuerlig analysetype.
En kategorisk analysetype fungerer som beskrevet ovenfor. Hvis du for eksempel så på undersøkelsesresultater fra 1 til 10, kan du spørre «Hva påvirker undersøkelsesresultatene til å være 1?»
En kontinuerlig analysetype endrer spørsmålet til en kontinuerlig. I eksemplet ovenfor vil vårt nye spørsmål være «Hva påvirker undersøkelsesresultatene til å øke/redusere?»
Dette skillet er nyttig når du har mange unike verdier i feltet du analyserer. I eksemplet nedenfor ser vi på huspriser. Det er ikke meningsfylt å spørre 'Hva påvirker husprisen til å være 156.214?' siden det er veldig spesifikt, og vi sannsynligvis ikke har nok data til å utlede et mønster.
I stedet vil vi kanskje spørre: 'Hva påvirker husprisen til å øke'? som gjør at vi kan behandle boligprisene som et område i stedet for distinkte verdier.
Tolke resultatene: Viktige påvirkere
Merk
Eksemplene i denne delen bruker offentlige husprisdata. Du kan laste ned eksempeldatasettet hvis du vil følge med.
I dette scenariet ser vi på "Hva påvirker husprisen til å øke". En rekke forklarende faktorer kan påvirke en huspris som Year Built (år huset ble bygget), KitchenQual (kjøkkenkvalitet) og YearRemodAdd (år huset ble ombygd).
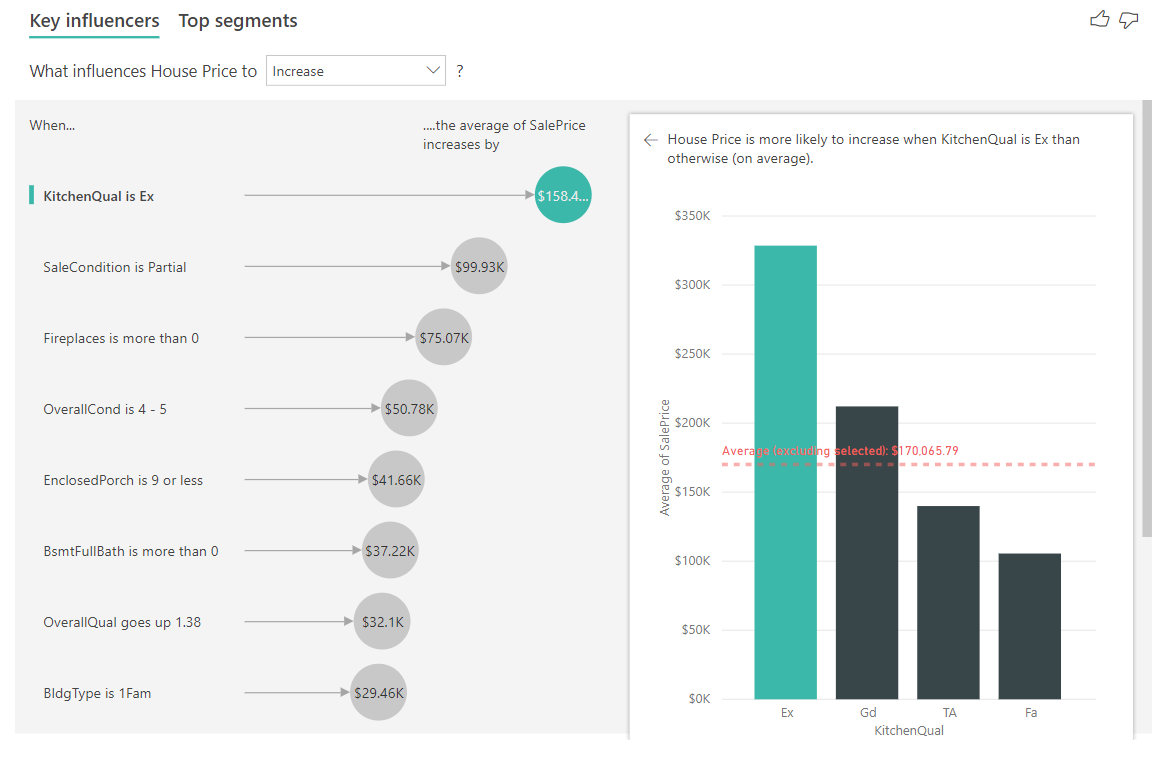
I eksemplet nedenfor ser vi på vår beste påvirker som er kjøkkenkvalitet er utmerket. Resultatene ligner på de vi så da vi analyserte kategoriske måledata med noen viktige forskjeller:
- Stolpediagrammet til høyre ser på gjennomsnittene i stedet for prosentdeler. Det viser oss derfor hva den gjennomsnittlige husprisen på et hus med et utmerket kjøkken er (grønn bar) sammenlignet med den gjennomsnittlige husprisen på et hus uten et utmerket kjøkken (prikket linje)
- Tallet i boblen er fortsatt forskjellen mellom den røde prikkede linjen og den grønne linjen, men det uttrykkes som et tall ($158.49K) i stedet for en sannsynlighet (1,93x). Så i gjennomsnitt er hus med utmerkede kjøkken nesten $ 160K dyrere enn hus uten gode kjøkken.
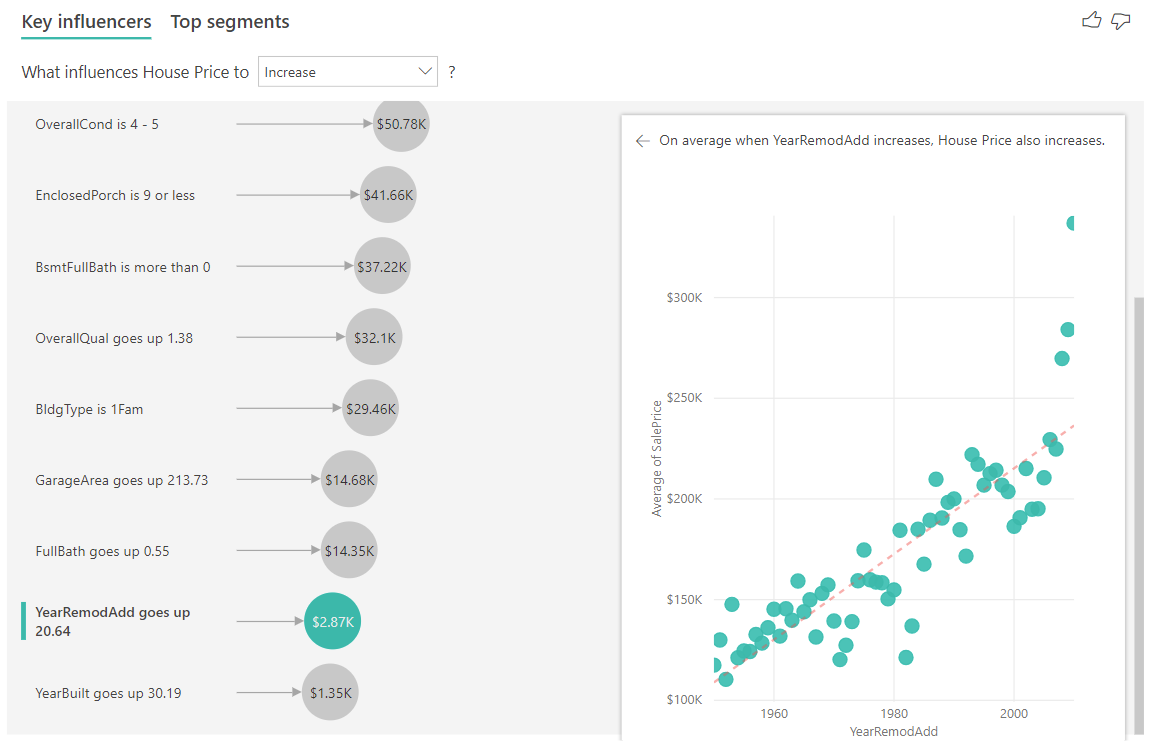
I eksemplet nedenfor ser vi på virkningen en kontinuerlig faktor (året huset ble ombygd) har på huspris. Forskjellene i forhold til hvordan vi analyserer kontinuerlige påvirkere for kategoriske måledata, er som følger:
- Punkttegningen i den høyre ruten tegner inn den gjennomsnittlige husprisen for hver distinkte verdi av året som er ombygd.
- Verdien i boblen viser hvor mye den gjennomsnittlige boligprisen øker (i dette tilfellet $ 2.87k) når året huset ble ombygd øker med standardavviket (i dette tilfellet 20 år)
Til slutt, når det gjelder tiltak, ser vi på det gjennomsnittlige året et hus ble bygget. Analysen er som følger:
- Punktplottet i den høyre ruten tegner inn den gjennomsnittlige husprisen for hver distinkte verdi i tabellen
- Verdien i boblen viser hvor mye den gjennomsnittlige husprisen øker (i dette tilfellet USD 1,35 000) når gjennomsnittsåret øker med standardavviket (i dette tilfellet 30 år)
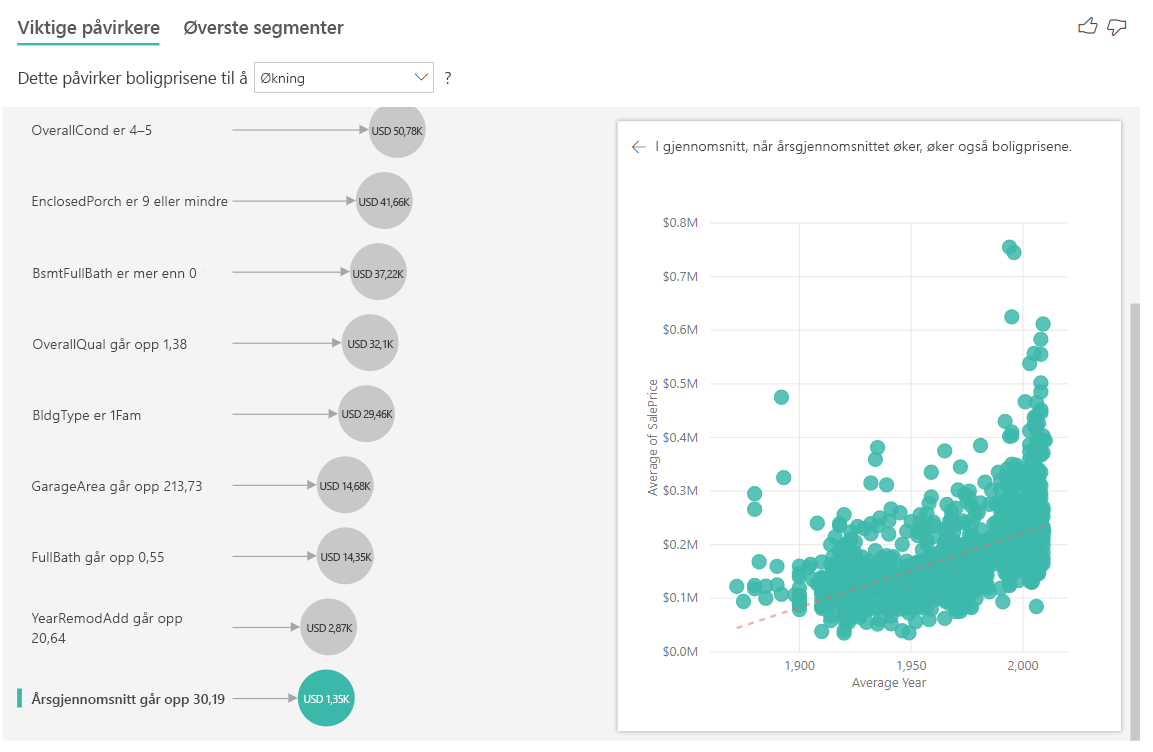
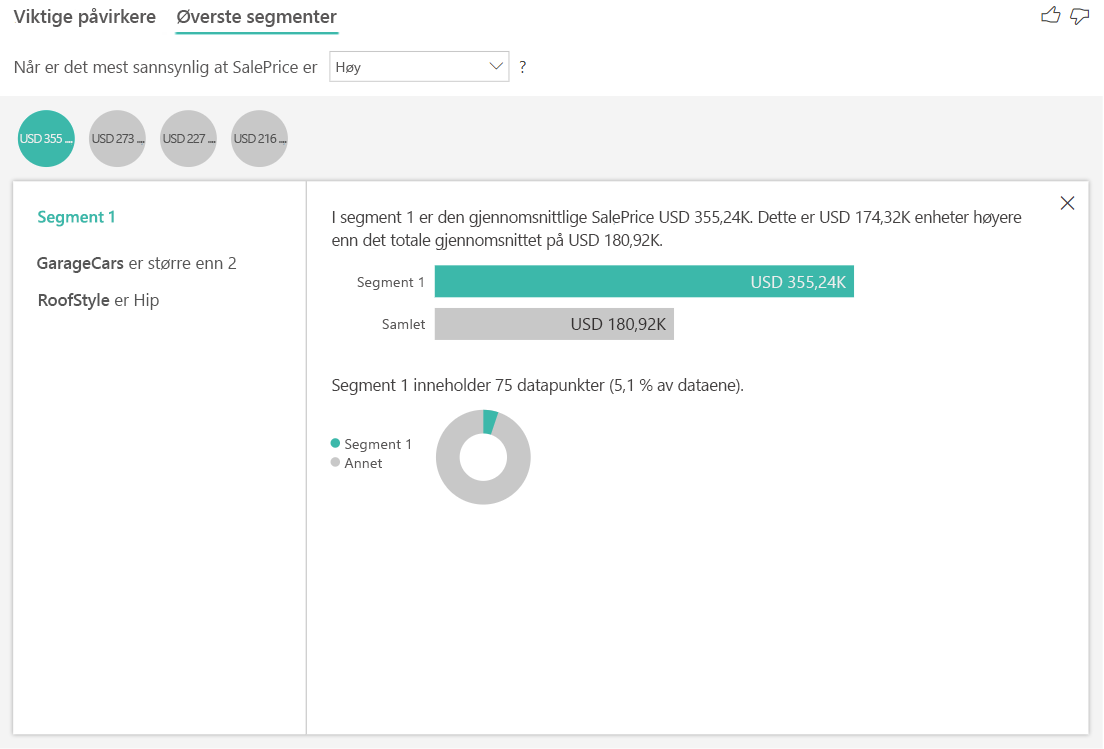
Tolke resultatene: Øverste segmenter
De øverste segmentene for numeriske mål viser grupper der boligprisene i gjennomsnitt er høyere enn i det totale datasettet. Nedenfor kan vi for eksempel se at Segment 1 består av hus der GarageCars (antall biler garasjen kan passe) er større enn 2 og RoofStyle er Hip. Hus med disse egenskapene har en gjennomsnittlig pris på $ 355K sammenlignet med det totale gjennomsnittet i dataene som er $ 180K.
Analysere en metrikkverdi som er et mål eller en oppsummert kolonne
Når det gjelder et mål eller en summert kolonne, er analysen standard for den kontinuerlige analysetypen som er beskrevet ovenfor. Verdien kan endres. Den største forskjellen mellom å analysere en mål-/summert kolonne og en ikke-summert numerisk kolonne er nivået som analysen kjører på.
Når det gjelder ikke-summerte kolonner, kjører analysen alltid på tabellnivå. I boligpriseksempelet ovenfor analyserte vi husprismålingen for å se hva som påvirker en boligpris for å øke/redusere. Analysen kjøres automatisk på tabellnivå. Tabellen vår har en unik ID for hvert hus, slik at analysen kjører på et husnivå.
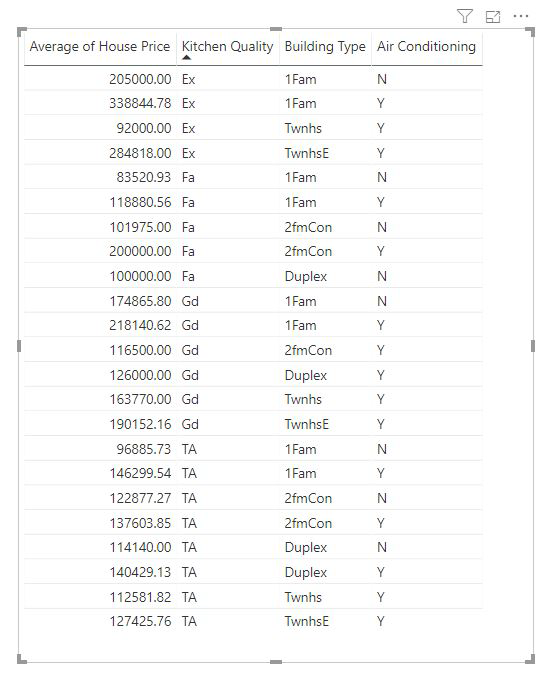
For mål og summerte kolonner vet vi ikke umiddelbart hvilket nivå vi skal analysere dem på. Hvis husprisen ble oppsummert som et gjennomsnitt, må vi vurdere hvilket nivå vi ønsker at denne gjennomsnittlige husprisen skal beregnes. Er det den gjennomsnittlige husprisen på et nabolagsnivå? Eller kanskje et regionalt nivå?
Mål og summerte kolonner analyseres automatisk på nivået i Explain by-feltene som brukes. Tenk deg at vi har tre felt i Explain By vi er interessert i: Kjøkkenkvalitet, bygningstype og klimaanlegg. Gjennomsnittlig huspris beregnes for hver unike kombinasjon av disse tre feltene. Det er ofte nyttig å bytte til en tabellvisning for å ta en titt på hvordan dataene som evalueres, ser ut.
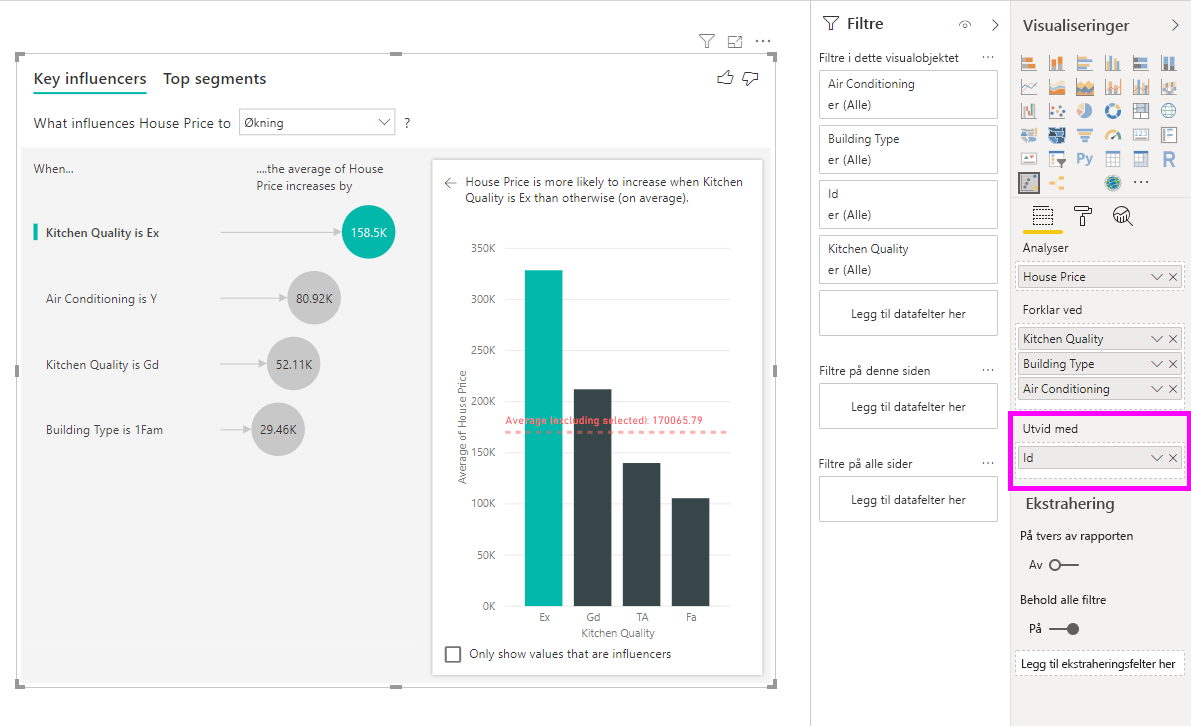
Denne analysen er svært oppsummert, og det vil derfor være vanskelig for regresjonsmodellen å finne mønstre i dataene den kan lære av. Vi bør kjøre analysen på et mer detaljert nivå for å få bedre resultater. Hvis vi ønsker å analysere husprisen på husnivå, må vi eksplisitt legge til ID-feltet i analysen. Likevel vil vi ikke at hus-ID-en skal betraktes som en påvirker. Det er ikke nyttig å lære at når hus-ID øker, øker prisen på et hus. Alternativet Utvid etter-feltet er nyttig her. Du kan bruke Utvid etter til å legge til felt du vil bruke til å angi analysenivået uten å lete etter nye påvirkere.
Ta en titt på hvordan visualiseringen ser ut når vi legger til ID-en i Utvid etter. Når du har definert nivået du vil at målet skal evalueres på, er tolkning av påvirkere nøyaktig det samme som for ikke-summerte numeriske kolonner.
Hvis du vil lære mer om hvordan du kan analysere mål med visualiseringen av viktige påvirkere, kan du se følgende video. Hvis du vil lære hvordan Power BI bruker ML.NET bak kulissene til å forstå data og overflateinnsikt på en naturlig måte, kan du se Power BI identifisere viktige påvirkere ved hjelp av ML.NET.
Merk
Denne videoen kan bruke tidligere versjoner av Power BI Desktop eller Power Bi-tjeneste.
Hensyn og feilsøking
Hva er begrensningene for visualobjektet?
Visualobjektet for viktige påvirkere har noen begrensninger:
- Direktespørring støttes ikke
- Live Koble til ion til Azure Analysis Services og SQL Server Analysis Services støttes ikke
- Publisering på nettet støttes ikke
- .NET Framework 4.6 eller nyere kreves
- Innebygging av SharePoint Online støttes ikke
Jeg ser en feil om at ingen påvirkere eller segmenter ble funnet. Hvorfor det?
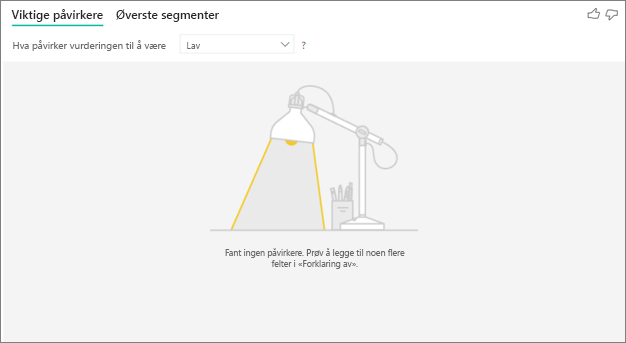
Denne feilen oppstår når du inkluderte felt i Explain by , men ingen påvirkere ble funnet.
- Du inkluderte måleverdien du analyserte i både Analyser og Forklar etter. Fjern den fra Explain by.
- De forklarende feltene har for mange kategorier med få observasjoner. Denne situasjonen gjør det vanskelig for visualiseringen å avgjøre hvilke faktorer som er påvirkere. Det er vanskelig å generalisere basert på bare noen få observasjoner. Hvis du analyserer et numerisk felt, kan det være lurt å bytte fra kategorisk analyse til kontinuerlig analyse i formateringsruten under Analyse-kortet .
- Dine forklarende faktorer har nok observasjoner til å generalisere, men visualiseringen fant ingen meningsfulle korrelasjoner å rapportere.
Jeg ser en feil som måleverdien jeg analyserer, ikke har nok data til å kjøre analysen på. Hvorfor det?
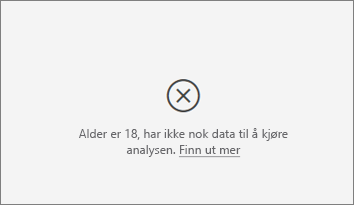
Visualiseringen fungerer ved å se på mønstre i dataene for én gruppe sammenlignet med andre grupper. Det ser for eksempel ut for kunder som ga lave vurderinger sammenlignet med kunder som ga høye vurderinger. Hvis dataene i modellen bare har noen få observasjoner, er mønstre vanskelige å finne. Hvis visualiseringen ikke har nok data til å finne meningsfulle påvirkere, angir den at mer data er nødvendig for å kjøre analysen.
Vi anbefaler at du har minst 100 observasjoner for den valgte tilstanden. I dette tilfellet er staten kunder som churn. Du trenger også minst 10 observasjoner for statene du bruker til sammenligning. I dette tilfellet er sammenligningstilstanden kunder som ikke faller fra.
Hvis du analyserer et numerisk felt, kan det være lurt å bytte fra kategorisk analyse til kontinuerlig analyse i formateringsruten under Analyse-kortet .
Jeg ser en feilmelding om at når Analyser ikke oppsummeres, kjører analysen alltid på radnivå i den overordnede tabellen. Det er ikke tillatt å endre dette nivået via «Utvid etter»-felt. Hvorfor det?
Når du analyserer en numerisk eller kategorisk kolonne, kjører analysen alltid på tabellnivå. Hvis du for eksempel analyserer huspriser og tabellen inneholder en ID-kolonne, kjøres analysen automatisk på hus-ID-nivå.
Når du analyserer et mål eller en oppsummert kolonne, må du eksplisitt angi hvilket nivå du vil at analysen skal kjøre på. Du kan bruke Utvid ved å endre analysenivået for mål og summerte kolonner uten å legge til nye påvirkere. Hvis husprisen ble definert som et mål, kan du legge til hus-ID-kolonnen til Utvid ved å endre nivået på analysen.
Jeg ser en feilmelding om at et felt i Explain by ikke er unikt relatert til tabellen som inneholder metrikkverdien jeg analyserer. Hvorfor det?
Analysen kjører på tabellnivået i feltet som analyseres. Hvis du for eksempel analyserer tilbakemeldinger fra kunder for tjenesten, kan det hende du har en tabell som forteller deg om en kunde ga en høy vurdering eller en lav vurdering. I dette tilfellet kjører analysen på kundetabellnivå.
Hvis du har en relatert tabell som er definert på et mer detaljert nivå enn tabellen som inneholder metrikkverdien, ser du denne feilen. Her er et eksempel:
- Du analyserer hva som driver kundene til å gi lave vurderinger av tjenesten.
- Du vil se om enheten kunden bruker tjenesten på, påvirker vurderingene de gir.
- En kunde kan bruke tjenesten på flere forskjellige måter.
- I eksemplet nedenfor bruker kunde 100000000 både en nettleser og et nettbrett til å samhandle med tjenesten.
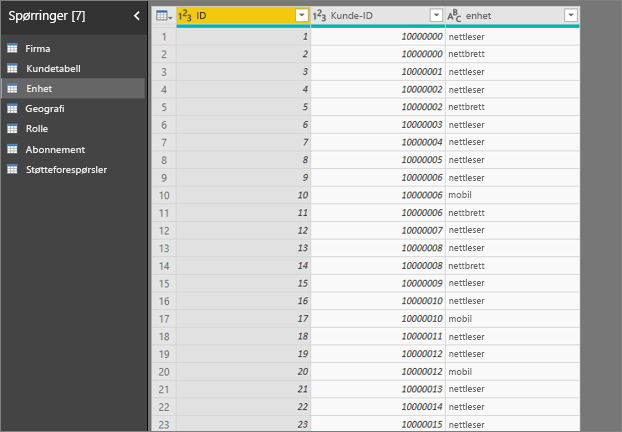
Hvis du prøver å bruke enhetskolonnen som en forklarende faktor, ser du følgende feil:
Denne feilen vises fordi enheten ikke er definert på kundenivå. Én kunde kan bruke tjenesten på flere enheter. For at visualiseringen skal kunne finne mønstre, må enheten være et attributt for kunden. Det finnes flere løsninger som avhenger av din forståelse av virksomheten:
- Du kan endre sammendraget av enheter til å telle. Bruk for eksempel antall hvis antall enheter kan påvirke poengsummen som en kunde gir.
- Du kan pivotere enhetskolonnen for å se om bruk av tjenesten på en bestemt enhet påvirker kundens vurdering.
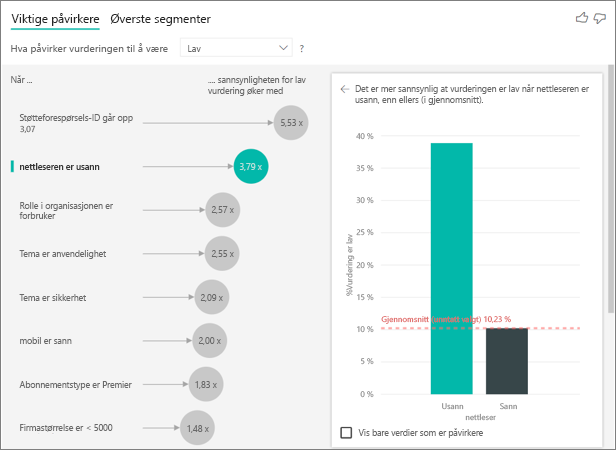
I dette eksemplet ble dataene pivotert for å opprette nye kolonner for nettleser, mobil og nettbrett (sørg for at du sletter og oppretter relasjonene dine på nytt i modelleringsvisningen etter at du har pivotert dataene). Du kan nå bruke disse bestemte enhetene i Explain by. Alle enheter viser seg å være påvirkere, og nettleseren har størst effekt på kundepoengsummen.
Mer nøyaktig, kunder som ikke bruker nettleseren til å bruke tjenesten er 3,79 ganger mer sannsynlig å gi en lav score enn kundene som gjør. Nederst ned i listen, for mobil er den inverse sann. Kunder som bruker mobilappen, har større sannsynlighet for å gi en lav poengsum enn kundene som ikke gjør det.
Jeg ser en advarsel om at mål ikke var inkludert i analysen min. Hvorfor det?
Analysen kjører på tabellnivået i feltet som analyseres. Hvis du analyserer kundefrafall, kan det hende du har en tabell som forteller deg om en kunde frafaller eller ikke. I dette tilfellet kjører analysen på kundetabellnivå.
Mål og aggregater analyseres som standard på tabellnivå. Hvis det var et mål for gjennomsnittlig månedlig forbruk, analyseres det på kundetabellnivå.
Hvis kundetabellen ikke har en unik identifikator, kan du ikke evaluere målet, og det ignoreres av analysen. Hvis du vil unngå denne situasjonen, må du kontrollere at tabellen med måleverdien har en unik identifikator. I dette tilfellet er det kundetabellen, og den unike identifikatoren er kunde-ID. Det er også enkelt å legge til en indekskolonne ved hjelp av Power Query.
Jeg ser en advarsel om at måleverdien jeg analyserer, har mer enn 10 unike verdier, og at dette beløpet kan påvirke kvaliteten på analysen. Hvorfor det?
Visualiseringen av kunstig intelligens kan analysere kategoriske felt og numeriske felt. Når det gjelder kategoriske felt, kan et eksempel være Frafall er Ja eller Nei, og kundetilfredshet er høy, middels eller lav. Hvis du øker antall kategorier som skal analyseres, er det færre observasjoner per kategori. Denne situasjonen gjør det vanskeligere for visualiseringen å finne mønstre i dataene.
Når du analyserer numeriske felt, har du et valg mellom å behandle de numeriske feltene, for eksempel tekst, i så fall kjører du den samme analysen som du gjør for kategoriske data (kategorisk analyse). Hvis du har mange distinkte verdier, anbefaler vi at du bytter analysen til Kontinuerlig analyse , da det betyr at vi kan utlede mønstre fra når tallene øker eller reduseres i stedet for å behandle dem som distinkte verdier. Du kan bytte fra kategorisk analyse til kontinuerlig analyse i formateringsruten under Analyse-kortet .
Hvis du vil finne sterkere påvirkere, anbefaler vi at du grupperer lignende verdier i én enkelt enhet. Hvis du for eksempel har en metrikkverdi for pris, får du sannsynligvis bedre resultater ved å gruppere lignende priser i kategoriene Høy, Middels og Lav kontra individuelle prispunkter.
Det er faktorer i dataene mine som ser ut som de bør være viktige påvirkere, men det er de ikke. Hvordan kan det skje?
I eksemplet nedenfor gir kunder som er forbrukere lave vurderinger, med 14,93 % av vurderingene som er lave. Administratorrollen har også en høy andel lave vurderinger, på 13,42 %, men den regnes ikke som en påvirker.
Årsaken til denne avgjørelsen er at visualiseringen også vurderer antall datapunkter når den finner påvirkere. Følgende eksempel har mer enn 29 000 forbrukere og 10 ganger færre administratorer, omtrent 2900. Bare 390 av dem ga en lav vurdering. Visualobjektet har ikke nok data til å avgjøre om det fant et mønster med administratorvurderinger eller om det bare er en sjanse for å finne.
Hva er datapunktgrensene for viktige påvirkere? Vi kjører analysen på et utvalg på 10 000 datapunkter. Boblene på den ene siden viser alle påvirkerne som ble funnet. Stolpediagrammene og punktplotene på den andre siden overholder samplingsstrategiene for disse kjernevisualobjektene.
Hvordan beregner du viktige påvirkere for kategorisk analyse?
Ai-visualiseringen bruker ML.NET til å kjøre en logistisk regresjon for å beregne viktige påvirkere bak kulissene. En logistisk regresjon er en statistisk modell som sammenligner forskjellige grupper med hverandre.
Hvis du vil se hva som driver lave vurderinger, ser den logistiske regresjonen på hvordan kunder som ga en lav poengsum, skiller seg fra kundene som ga en høy poengsum. Hvis du har flere kategorier, for eksempel høye, nøytrale og lave poengsummer, ser du på hvordan kundene som ga en lav vurdering, skiller seg fra kundene som ikke ga en lav vurdering. I dette tilfellet, hvordan skiller kundene som ga en lav poengsum, seg fra kundene som ga en høy vurdering eller en nøytral vurdering?
Den logistiske regresjonen søker etter mønstre i dataene og ser etter hvordan kunder som ga en lav vurdering, kan avvike fra kundene som ga en høy vurdering. Det kan for eksempel hende at kunder med flere støtteforespørsler gir en høyere prosentandel av lave vurderinger enn kunder med få eller ingen støtteforespørsler.
Den logistiske regresjonen vurderer også hvor mange datapunkter som finnes. Hvis for eksempel kunder som spiller en administratorrolle gir proporsjonalt flere negative poengsummer, men det bare er noen få administratorer, anses ikke denne faktoren som innflytelsesrik. Denne avgjørelsen gjøres fordi det ikke er nok datapunkter tilgjengelig til å utlede et mønster. En statistisk test, kjent som en Wald-test, brukes til å avgjøre om en faktor regnes som en påvirker. Visualobjektet bruker en p-verdi på 0,05 til å bestemme terskelen.
Hvordan beregner du viktige påvirkere for numerisk analyse?
I bakgrunnen bruker AI-visualiseringen ML.NET til å kjøre en lineær regresjon for å beregne viktige påvirkere. En lineær regresjon er en statistisk modell som ser på hvordan resultatet av feltet analyserer endringer basert på forklarende faktorer.
Hvis vi for eksempel analyserer boligprisene, vil en lineær regresjon se på effekten som det å ha et utmerket kjøkken vil ha på husprisen. Har hus med utmerkede kjøkken generelt lavere eller høyere boligpriser sammenlignet med hus uten gode kjøkken?
Den lineære regresjonen vurderer også antall datapunkter. For eksempel, hvis hus med tennisbaner har høyere priser, men vi har få hus med en tennisbane, anses ikke denne faktoren som innflytelsesrik. Denne avgjørelsen gjøres fordi det ikke er nok datapunkter tilgjengelig til å utlede et mønster. En statistisk test, kjent som en Wald-test, brukes til å avgjøre om en faktor regnes som en påvirker. Visualobjektet bruker en p-verdi på 0,05 til å bestemme terskelen.
Hvordan beregner du segmenter?
I bakgrunnen bruker AI-visualiseringen ML.NET til å kjøre et beslutningstre for å finne interessante undergrupper. Målet med beslutningstreet er å ende opp med en undergruppe med datapunkter som er relativt høy i måleverdien du er interessert i. Det kan være kunder med lave rangeringer eller hus med høye priser.
Beslutningstreet tar hver forklarende faktor og prøver å resonnere hvilken faktor som gir den den beste splitten. Hvis du for eksempel filtrerer dataene slik at de bare inkluderer store bedriftskunder, skiller dette ut kunder som gav en høy vurdering kontra en lav vurdering? Eller er det kanskje bedre å filtrere dataene slik at de bare inkluderer kunder som kommenterte sikkerhet?
Når beslutningstreet har delt seg, tar det undergruppen med data og bestemmer den nest beste delingen for disse dataene. I dette tilfellet er undergruppen kunder som kommenterte sikkerheten. Etter hver deling vurderer beslutningstreet også om det har nok datapunkter for denne gruppen til å være representativt nok til å utlede et mønster fra eller om det er en anomali i dataene og ikke et reelt segment. En annen statistisk test brukes til å kontrollere den statistiske betydningen av den delte betingelsen med p-verdien 0,05.
Når beslutningstreet er ferdig med å kjøre, tar det alle delingene, for eksempel sikkerhetskommentarer og store virksomheter, og oppretter Power BI-filtre. Denne kombinasjonen av filtre pakkes opp som et segment i visualobjektet.
Hvorfor blir visse faktorer påvirkere eller slutter å være påvirkere når jeg flytter flere felt til Forklar etter-feltet?
Visualiseringen evaluerer alle forklarende faktorer sammen. En faktor kan være en påvirker av seg selv, men når den vurderes med andre faktorer, kan det ikke. La oss si at du vil analysere hva som driver en huspris til å være høy, med soverom og husstørrelse som forklarende faktorer:
- I seg selv kan flere soverom være en sjåfør for boligprisene å være høy.
- Inkludert husstørrelse i analysen betyr at du nå ser på hva som skjer med soverom mens husstørrelsen forblir konstant.
- Hvis husstørrelsen er fast på 1500 kvadratmeter, er det lite sannsynlig at en kontinuerlig økning i antall soverom vil dramatisk øke husprisen.
- Soverom er kanskje ikke så viktig for en faktor som det var før husstørrelsen ble vurdert.
Deling av rapporten med en Power BI-kollega krever at dere begge har individuelle Power BI Pro-lisenser eller at rapporten lagres i Premium-kapasitet. Se delingsrapporter.