Obs!
Tilgang til denne siden krever autorisasjon. Du kan prøve å logge på eller endre kataloger.
Tilgang til denne siden krever autorisasjon. Du kan prøve å endre kataloger.
Scene understanding provides Mixed Reality developers with a structured, high-level environment representation designed to make developing for environmentally aware applications intuitive. Scene understanding does this by combining the power of existing mixed reality runtimes, like the highly accurate but less structured spatial mapping and new AI driven runtimes. By combining these technologies, Scene understanding generates representations of 3D environments that are similar to those you may have used in frameworks such as Unity or ARKit/ARCore. The Scene understanding entry point begins with a Scene Observer, which is called by your application to compute a new scene. Today, the technology can generate 3 distinct but related object categories:
- Simplified watertight environment meshes that infer the planar room structure without clutter
- Plane regions for placement that we call Quads
- A snapshot of the spatial mapping mesh that aligns with the Quads/Watertight data that we surface

This document is intended to provide a scenario overview and to clarify the relationship that Scene understanding and Spatial mapping share. If you'd like to see Scene Understanding in action, check out our Designing Holograms - Spatial Awareness video demo below:
This video was taken from the "Designing Holograms" HoloLens 2 app. Download and enjoy the full experience here.
Developing with Scene Understanding
This article only serves to introduce the Scene Understanding runtime and concepts. If you're looking for documentation on how to develop with Scene Understanding, you may be interested in the following articles:
Scene Understanding SDK overview
You can download the Scene Understanding Sample app from the sample GitHub site:
If you don't have a device and wish to access sample scenes to try Scene Understanding out, there are scenes in the sample asset folder:
Scene Understanding Sample Scenes
SDK
If you're looking for specific details on developing with Scene Understanding, see the Scene Understanding SDK overview documentation.
Sample
Device support
| Feature | HoloLens (1st gen) | HoloLens 2 | Immersive headsets |
| Scene understanding | ❌ | ✔️ | ❌ |
Common usage scenarios
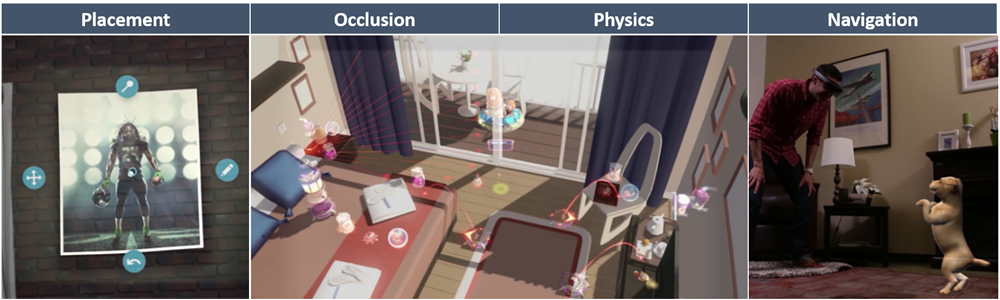
Common spatial mapping usage scenarios: placement, occlusion, physics, and navigation.
Many of the core scenarios for environmentally aware applications can be addressed by both Spatial mapping and Scene understanding. These core scenarios include placement, occlusion, physics, and so on. A core difference between Scene understanding and Spatial mapping is a tradeoff of maximal accuracy and latency to structure and simplicity. If your application requires the lowest-latency possible and mesh triangles that only you'll want to access, use Spatial Mapping directly. If you're doing higher-level processing, you may consider switching to the Scene understanding model as it should provide you with a superset of functionality. You'll always have access to the most complete and accurate spatial mapping data possible because Scene understanding provides a snapshot of the spatial mapping mesh as part of its representation.
The following sections revisit the core spatial mapping scenarios in the context of the new Scene understanding SDK.
Placement
Scene understanding provides new constructs designed to simplify placement scenarios. A scene can compute primitives called SceneQuads, which describe flat surfaces on which holograms can be placed. SceneQuads have been designed around placement and describe a 2D surface and provide an API for placement on that surface. Previously, when using the triangle mesh to do placement, one had to scan all areas of the quad and do hole filling/post-processing to identify good locations for object placement. This isn't always necessary with Quads, as the Scene understanding runtime infers which quad areas weren't scanned, and invalidate areas that aren't part of the surface.

Image #1 - SceneQuads with inference disabled, capturing placement areas for scanned regions.

Image #2 - Quads with inference enabled, placement is no longer limited to scanned areas.
If your application intends to place 2D or 3D holograms on rigid structures of your environment, the simplicity and convenience of SceneQuads for placement is preferable to computing this information from the spatial mapping mesh. For more information on this topic, see the Scene understanding SDK reference
Note For legacy placement code that depends on the spatial mapping mesh, the spatial mapping mesh can be computed along with SceneQuads by setting EnableWorldMesh setting. If Scene understanding API doesn't satisfy your application's latency requirements, we recommend you continue to use the Spatial mapping API.
Occlusion
Spatial mapping occlusion remains the least latent way to capture the real-time state of the environment. Though this may be useful to provide occlusion in highly dynamic scenes, you may wish to consider Scene understanding for occlusion for several reasons. If you use the spatial mapping mesh generated by Scene Understanding, you can request data from spatial mapping that wouldn't be stored in the local cache and isn't available from the perception APIs. Using Spatial Mapping for occlusion alongside watertight meshes will provide extra value, specifically completion of unscanned room structure.
If your requirements can tolerate the increased latency of Scene understanding, application developers should consider using the Scene understanding watertight mesh, and the spatial mapping mesh in unison with planar representations. This would provide a "best of both worlds" scenario where simplified watertight occlusion is married with finer nonplanar geometry providing the most realistic occlusion maps possible.
Physics
Scene understanding generates watertight meshes that decompose space with semantics, specifically to address many limitations to physics that spatial mapping meshes impose. Watertight structures ensure physics ray casts always hit, and semantic decomposition allows for simpler generation of nav meshes for indoor navigation. As described in the section on occlusion, creating a scene with EnableSceneObjectMeshes and EnableWorldMesh will produce the most physically complete mesh possible. The watertight property of the environment mesh prevents hit tests from failing to hit surfaces. The mesh data will ensure physics are interacting with all objects in the scene and not just the room structure.
Navigation
Planar meshes decomposed by semantic class are ideal constructs for navigation and path planning, easing many of the issues described in the Spatial mapping navigation overview. The SceneMesh objects computed in the scene are de-composed by surface type ensuring that nav-mesh generation is limited to surfaces that can be walked on. Because of the floor structures' simplicity, dynamic nav-mesh generation in 3d engines such as Unity are attainable depending on real-time requirements.
Generating accurate nav-meshes currently still requires post-processing, namely applications must still project occluders on to the floor to ensure that navigation doesn't pass through clutter/tables and so on. The most accurate way to accomplish this is to project the world mesh data, which is provided if the scene is computed with the EnableWorldMesh flag.
Visualization
While spatial mapping visualization can be used for real-time feedback of the environment, there are many scenarios where the simplicity of planar and watertight objects provides more performance or visual quality. Shadow projection and grounding techniques that are described using spatial mapping may be more pleasing if projected on the planar surfaces provided by Quads or the planar watertight mesh. This is especially true for environments/scenarios where thorough pre-scanning isn't optimal because the scene will infer, and complete environments and planar assumptions will minimize artifacts.
Additionally, the total number of surfaces returned by Spatial Mapping is limited by the internal spatial cache, while Scene understanding's version of the Spatial Mapping mesh can access spatial mapping data that isn't cached. Because of this, Scene understanding is more suited to capturing mesh representations for larger spaces (for example, larger than a single room) for visualization or further mesh processing. The world mesh returned with EnableWorldMesh will have a consistent level of detail throughout, which may yield a more pleasing visualization if rendered as wireframe.