Overzicht van automatische schaalaanpassing van clusters in Azure Kubernetes Service (AKS)
Als u wilt voldoen aan de toepassingsvereisten in Azure Kubernetes Service (AKS), moet u mogelijk het aantal knooppunten aanpassen waarop uw workloads worden uitgevoerd. Het onderdeel voor automatische schaalaanpassing van clusters controleert op pods in uw cluster die niet kunnen worden gepland vanwege resourcebeperkingen. Wanneer de automatische schaalaanpassing van clusters problemen detecteert, wordt het aantal knooppunten in de knooppuntgroep opgeschaald om te voldoen aan de vraag van de toepassing. Het controleert ook regelmatig knooppunten op een gebrek aan actieve pods en schaalt zo nodig het aantal knooppunten omlaag.
In dit artikel wordt uitgelegd hoe de automatische schaalaanpassing van clusters werkt in AKS. Het biedt ook richtlijnen, aanbevolen procedures en overwegingen bij het configureren van de automatische schaalaanpassing van clusters voor uw AKS-workloads. Als u de automatische schaalaanpassing van clusters voor uw AKS-workloads wilt inschakelen, uitschakelen of bijwerken, raadpleegt u De automatische schaalaanpassing van clusters in AKS gebruiken.
Over de automatische schaalaanpassing van clusters
Clusters hebben vaak een manier nodig om automatisch te schalen om aan te passen aan veranderende toepassingsvereisten, zoals tussen werkdagen en avonden of weekenden. AKS-clusters kunnen op de volgende manieren worden geschaald:
- De automatische schaalaanpassing van clusters controleert regelmatig op pods die niet op knooppunten kunnen worden gepland vanwege resourcebeperkingen. Het cluster verhoogt vervolgens automatisch het aantal knooppunten. Handmatig schalen is uitgeschakeld wanneer u de automatische schaalaanpassing van clusters gebruikt. Zie Hoe werkt omhoog schalen voor meer informatie?
- De horizontale automatische schaalaanpassing van pods maakt gebruik van de Metrics-server in een Kubernetes-cluster om de resourcevraag van pods te bewaken. Als een toepassing meer resources nodig heeft, wordt het aantal pods automatisch verhoogd om aan de vraag te voldoen.
- Met de verticale schaalaanpassing voor pods worden automatisch resourceaanvragen en -limieten ingesteld voor containers per workload op basis van gebruik in het verleden om ervoor te zorgen dat pods worden gepland op knooppunten met de vereiste CPU- en geheugenresources.
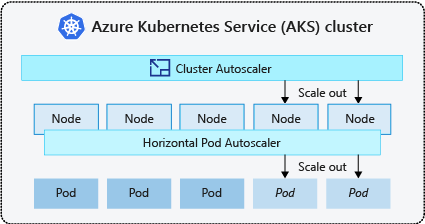
Het is gebruikelijk om automatische schaalaanpassing van clusters in te schakelen voor knooppunten en de verticale automatische schaalaanpassing van pods of horizontale automatische schaalaanpassing voor pods. Wanneer u automatische schaalaanpassing van clusters inschakelt, worden de opgegeven schaalregels toegepast wanneer de grootte van de knooppuntgroep lager is dan het minimum of groter is dan het maximum. De automatische schaalaanpassing van clusters wacht totdat een nieuw knooppunt nodig is in de knooppuntgroep of totdat een knooppunt veilig uit de huidige knooppuntgroep kan worden verwijderd. Zie Hoe werkt omlaag schalen voor meer informatie?
Best practices en overwegingen
- Bij het implementeren van beschikbaarheidszones met de automatische schaalaanpassing van clusters raden we u aan één knooppuntgroep voor elke zone te gebruiken. U kunt de
--balance-similar-node-groupsparameter instellen omTrueeen evenwichtige verdeling van knooppunten tussen zones voor uw workloads te behouden tijdens het opschalen van bewerkingen. Wanneer deze aanpak niet wordt geïmplementeerd, kunnen omlaag schalen de balans tussen knooppunten tussen zones verstoren. - Voor clusters met meer dan 400 knooppunten raden we u aan Azure CNI of Azure CNI-overlay te gebruiken.
- Als u workloads op zowel spot- als vaste knooppuntgroepen effectief wilt uitvoeren, kunt u overwegen prioriteits-uitbreidingen te gebruiken. Met deze methode kunt u pods plannen op basis van de prioriteit van de knooppuntgroep.
- Wees voorzichtig bij het toewijzen van CPU-/geheugenaanvragen op pods. De automatische schaalaanpassing van clusters wordt omhoog geschaald op basis van in behandeling zijnde pods in plaats van CPU-/geheugenbelasting op knooppunten.
- Voor clusters die gelijktijdig als host fungeren voor langlopende workloads, zoals web-apps en werkbelastingen met korte/bursty-taken, raden we u aan ze te scheiden in afzonderlijke knooppuntgroepen met uitbreidingen voor affiniteitsregels/of om PriorityClass te gebruiken om onnodige knooppuntafvoer- of schaalbewerkingen te voorkomen.
- In een knooppuntgroep met automatische schaalaanpassing kunt u knooppunten omlaag schalen door workloads te verwijderen in plaats van het aantal knooppunten handmatig te verminderen. Dit kan problematisch zijn als de knooppuntgroep al een maximale capaciteit heeft of als er actieve workloads worden uitgevoerd op de knooppunten, waardoor mogelijk onverwacht gedrag wordt veroorzaakt door de automatische schaalaanpassing van clusters
- Knooppunten worden niet omhoog geschaald als pods een PriorityClass-waarde lager dan -10 hebben. Priority -10 is gereserveerd voor overprovisioning-pods. Zie Automatische schaalaanpassing van clusters gebruiken met Pod Priority en Preemption voor meer informatie.
- Combineer geen andere mechanismen voor automatisch schalen van knooppunten, zoals automatische schaalaanpassing van virtuele-machineschaalsets, met de automatische schaalaanpassing van clusters.
- De automatische schaalaanpassing van clusters kan mogelijk niet omlaag worden geschaald als pods niet kunnen worden verplaatst, zoals in de volgende situaties:
- Een rechtstreeks gemaakte pod die niet wordt ondersteund door een controllerobject, zoals een implementatie of replicaset.
- Een budget voor podonderbreking (PDB) dat te beperkend is en het aantal pods niet onder een bepaalde drempelwaarde kan vallen.
- Een pod maakt gebruik van knooppuntkiezers of antiaffiniteit die niet kan worden uitgevoerd als deze is gepland op een ander knooppunt. Zie voor meer informatie welke typen pods kunnen voorkomen dat de automatische schaalaanpassing van clusters een knooppunt verwijdert?
Belangrijk
Breng geen wijzigingen aan in afzonderlijke knooppunten binnen de automatisch geschaalde knooppuntgroepen. Alle knooppunten in dezelfde knooppuntgroep moeten een uniforme capaciteit, labels, taints en systeempods hebben die erop worden uitgevoerd.
Profiel voor automatische schaalaanpassing van clusters
Het profiel voor automatische schaalaanpassing van clusters is een set parameters waarmee het gedrag van de automatische schaalaanpassing van clusters wordt bepaald. U kunt het profiel voor automatische schaalaanpassing van clusters configureren wanneer u een cluster maakt of een bestaand cluster bijwerkt.
Het profiel voor automatische schaalaanpassing van clusters optimaliseren
U moet de profielinstellingen voor automatische schaalaanpassing van clusters afstemmen op basis van uw specifieke workloadscenario's, terwijl u ook rekening houdt met de balans tussen prestaties en kosten. In deze sectie vindt u voorbeelden die deze compromissen demonstreren.
Het is belangrijk te weten dat de profielinstellingen voor automatische schaalaanpassing van clusters clusterbreed zijn en worden toegepast op alle knooppuntgroepen met automatische schaalaanpassing. Eventuele schaalacties die in één knooppuntgroep plaatsvinden, kunnen van invloed zijn op het gedrag van automatische schaalaanpassing van andere knooppuntgroepen, wat kan leiden tot onverwachte resultaten. Zorg ervoor dat u consistente en gesynchroniseerde profielconfiguraties toepast in alle relevante knooppuntgroepen om ervoor te zorgen dat u de gewenste resultaten krijgt.
Voorbeeld 1: Optimaliseren voor prestaties
Voor clusters die aanzienlijke en bursty workloads verwerken met een primaire focus op prestaties, raden we u aan het scan-interval verhogen en verlagen van de scale-down-utilization-threshold. Deze instellingen helpen meerdere schaalbewerkingen in één aanroep te batcheren, de schaaltijd te optimaliseren en het gebruik van quota voor lezen/schrijven berekenen te optimaliseren. Het helpt ook het risico op snelle schaalbewerkingen op onderbenutte knooppunten te beperken, waardoor de efficiëntie van de podplanning wordt verbeterd. Ook verhogen ok-total-unready-counten max-total-unready-percentage.
Voor clusters met daemonset-pods wordt u aangeraden deze instelling in te truestellenignore-daemonset-utilization, waardoor het knooppuntgebruik door daemonset-pods effectief wordt genegeerd en onnodige schaalbewerkingen voor omlaag schalen wordt geminimaliseerd. Profiel voor bursty workloads bekijken
Voorbeeld 2: Optimaliseren voor kosten
Als u een voor kosten geoptimaliseerd profiel wilt, raden we u aan de volgende parameterconfiguraties in te stellen:
- Verminderen
scale-down-unneeded-time, wat de hoeveelheid tijd is die een knooppunt niet nodig moet hebben voordat het in aanmerking komt voor omlaag schalen. - Verminderen
scale-down-delay-after-add, wat de hoeveelheid tijd is die moet worden gewacht nadat een knooppunt is toegevoegd voordat u het overweegt om omlaag te schalen. - Verhogen
scale-down-utilization-threshold, wat de gebruiksdrempel is voor het verwijderen van knooppunten. - Verhogen
max-empty-bulk-delete, wat het maximum aantal knooppunten is dat in één aanroep kan worden verwijderd. - Ingesteld
skip-nodes-with-local-storageop onwaar. - Verhogen
ok-total-unready-countenmax-total-unready-percentage
Veelvoorkomende problemen en aanbevelingen voor risicobeperking
Bekijk schaalfouten en niet geactiveerde gebeurtenissen opschalen via CLI of Portal.
Niet activeren van omhoog schalen
| Veelvoorkomende oorzaken | Aanbevelingen voor risicobeperking |
|---|---|
| Affiniteitsconflicten voor persistentVolume-knooppunten, die kunnen optreden bij het gebruik van de automatische schaalaanpassing van clusters met meerdere beschikbaarheidszones of wanneer de zone van een pod of permanent volume verschilt van de zone van het knooppunt. | Gebruik één knooppuntgroep per beschikbaarheidszone en inschakelen --balance-similar-node-groups. U kunt het volumeBindingMode veld WaitForFirstConsumer ook instellen op in de podspecificatie om te voorkomen dat het volume wordt gebonden aan een knooppunt totdat een pod met het volume wordt gemaakt. |
| Taints en toleraties/conflicten met knooppuntaffiniteit | Evalueer de taints die zijn toegewezen aan uw knooppunten en controleer de toleranties die zijn gedefinieerd in uw pods. Breng indien nodig aanpassingen aan de taints en toleranties om ervoor te zorgen dat uw pods efficiënt kunnen worden gepland op uw knooppunten. |
Bewerkingsfouten omhoog schalen
| Veelvoorkomende oorzaken | Aanbevelingen voor risicobeperking |
|---|---|
| UITPUTTING VAN IP-adres in het subnet | Voeg nog een subnet toe aan hetzelfde virtuele netwerk en voeg een andere knooppuntgroep toe aan het nieuwe subnet. |
| Kernquotumuitputting | Het goedgekeurde kernquotum is uitgeput. Vraag een quotumverhoging aan. De automatische schaalaanpassing van clusters voert een exponentiële uitstelstatus in binnen de specifieke knooppuntgroep wanneer er meerdere mislukte omhoogschaalpogingen optreden. |
| Maximale grootte van knooppuntgroep | Verhoog het maximum aantal knooppunten in de knooppuntgroep of maak een nieuwe knooppuntgroep. |
| Aanvragen/aanroepen die de frequentielimiet overschrijden | Zie 429 Te veel aanvragen. |
Bewerkingsfouten omlaag schalen
| Veelvoorkomende oorzaken | Aanbevelingen voor risicobeperking |
|---|---|
| Pod voorkomt knooppuntafvoer/kan pod niet verwijderen | • Bekijk welke typen pods omlaag kunnen schalen. • Voor pods die lokale opslag gebruiken, zoals hostPath en emptyDir, stelt u de profielvlag skip-nodes-with-local-storage voor automatische schaalaanpassing van clusters in op false. • Stel in de podspecificatie de cluster-autoscaler.kubernetes.io/safe-to-evict aantekening in op true. • Controleer uw PDB, omdat deze mogelijk beperkend is. |
| Minimale grootte van knooppuntgroep | Verklein de minimale grootte van de knooppuntgroep. |
| Aanvragen/aanroepen die de frequentielimiet overschrijden | Zie 429 Te veel aanvragen. |
| Schrijfbewerkingen vergrendeld | Breng geen wijzigingen aan in de volledig beheerde AKS-resourcegroep (zie AKS-ondersteuningsbeleid). Verwijder of stel alle resourcevergrendelingen die u eerder op de resourcegroep hebt toegepast, uit of stel deze opnieuw in. |
Overige problemen
| Veelvoorkomende oorzaken | Aanbevelingen voor risicobeperking |
|---|---|
| PriorityConfigMapNotMatchedGroup | Zorg ervoor dat u alle knooppuntgroepen toevoegt waarvoor automatisch schalen is vereist voor het configuratiebestand van de uitbreidingsfunctie. |
Knooppuntgroep in uitstel
Knooppuntgroep in uitstel is geïntroduceerd in versie 0.6.2 en zorgt ervoor dat de automatische schaalaanpassing van clusters wordt uitgeschakeld van het schalen van een knooppuntgroep na een fout.
Afhankelijk van hoelang de schaalbewerkingen fouten ondervinden, kan het tot 30 minuten duren voordat er een andere poging wordt gedaan. U kunt de uitstelstatus van de knooppuntgroep opnieuw instellen door automatische schaalaanpassing uit te schakelen en vervolgens opnieuw in te schakelen.