Wereldwijde gegevensdistributie met Azure Cosmos DB - onder de schermen
VAN TOEPASSING OP: ![]() Nosql
Nosql ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Tabel
Tabel
Azure Cosmos DB is een fundamentele service in Azure, dus deze wordt geïmplementeerd in alle Azure-regio's wereldwijd, waaronder de openbare, onafhankelijke, Ministerie van Defensie (DoD) en overheidsclouds.
Op hoog niveau worden azure Cosmos DB-containergegevens horizontaal gepartitioneerd in veel replicasets, die schrijfbewerkingen repliceren in elke regio. Replicasets voeren duurzaam schrijfbewerkingen door met behulp van een meerderheidsquorum.
Elke regio bevat alle gegevenspartities van een Azure Cosmos DB-container en kan leesbewerkingen en schrijfbewerkingen verwerken wanneer schrijfbewerkingen voor meerdere regio's zijn ingeschakeld. Als uw Azure Cosmos DB-account is verdeeld over N Azure-regio's, zijn er ten minste N x 4 kopieën van al uw gegevens.
Binnen een datacenter implementeren en beheren we de Azure Cosmos DB op enorme stempels van machines, elk met toegewezen lokale opslag. Binnen een datacenter wordt Azure Cosmos DB geïmplementeerd in veel clusters, die elk mogelijk meerdere generaties hardware uitvoeren. Machines binnen een cluster zijn doorgaans verspreid over 10-20 foutdomeinen voor hoge beschikbaarheid binnen een regio. In de volgende afbeelding ziet u de wereldwijde distributiesysteemtopologie van Azure Cosmos DB:
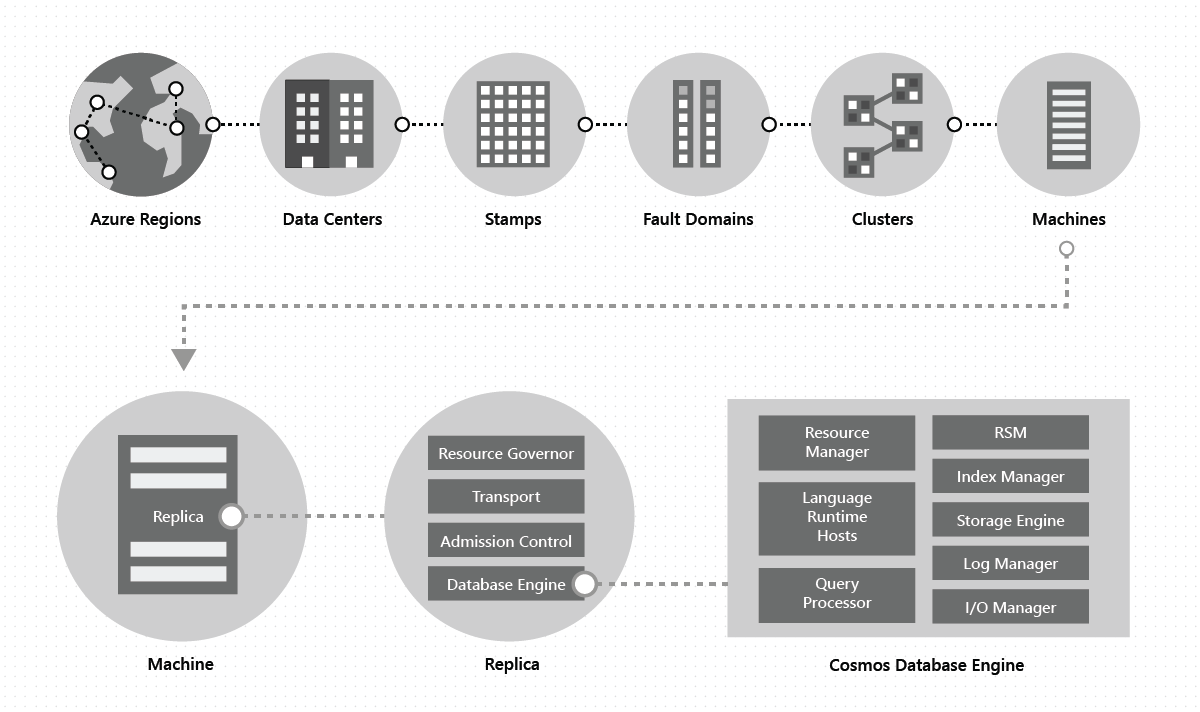
Wereldwijde distributie in Azure Cosmos DB is kant-en-klare sleutel: u kunt op elk gewenst moment met een paar klikken of programmatisch met één API-aanroep de geografische regio's toevoegen of verwijderen die zijn gekoppeld aan uw Azure Cosmos DB-database. Een Azure Cosmos DB-database bestaat op zijn beurt uit een set Azure Cosmos DB-containers. In Azure Cosmos DB fungeren containers als logische distributie- en schaalbaarheidseenheden. De verzamelingen, tabellen en grafieken die u maakt, zijn (intern) alleen Azure Cosmos DB-containers. Containers zijn volledig schemaneutraal en bieden een bereik voor een query. Gegevens in een Azure Cosmos DB-container worden automatisch geïndexeerd bij opname. Met automatisch indexeren kunnen gebruikers query's uitvoeren op de gegevens zonder problemen met schema- of indexbeheer, met name in een wereldwijd gedistribueerde installatie.
In een bepaalde regio worden gegevens binnen een container gedistribueerd met behulp van een partitiesleutel, die u opgeeft en transparant wordt beheerd door de onderliggende fysieke partities (lokale distributie).
Elke fysieke partitie wordt ook gerepliceerd in geografische regio's (wereldwijde distributie).
Wanneer een app die Azure Cosmos DB gebruikt, de doorvoer elastisch schaalt op een Azure Cosmos DB-container of meer opslag verbruikt, verwerkt Azure Cosmos DB transparant partitiebeheerbewerkingen (splitsen, klonen, verwijderen) in alle regio's. Onafhankelijk van de schaal, distributie of storingen blijft Azure Cosmos DB één systeeminstallatiekopie bieden van de gegevens in de containers, die wereldwijd worden gedistribueerd over een willekeurig aantal regio's.
Zoals in de volgende afbeelding wordt weergegeven, worden de gegevens binnen een container verdeeld over twee dimensies: binnen een regio en in verschillende regio's, wereldwijd:
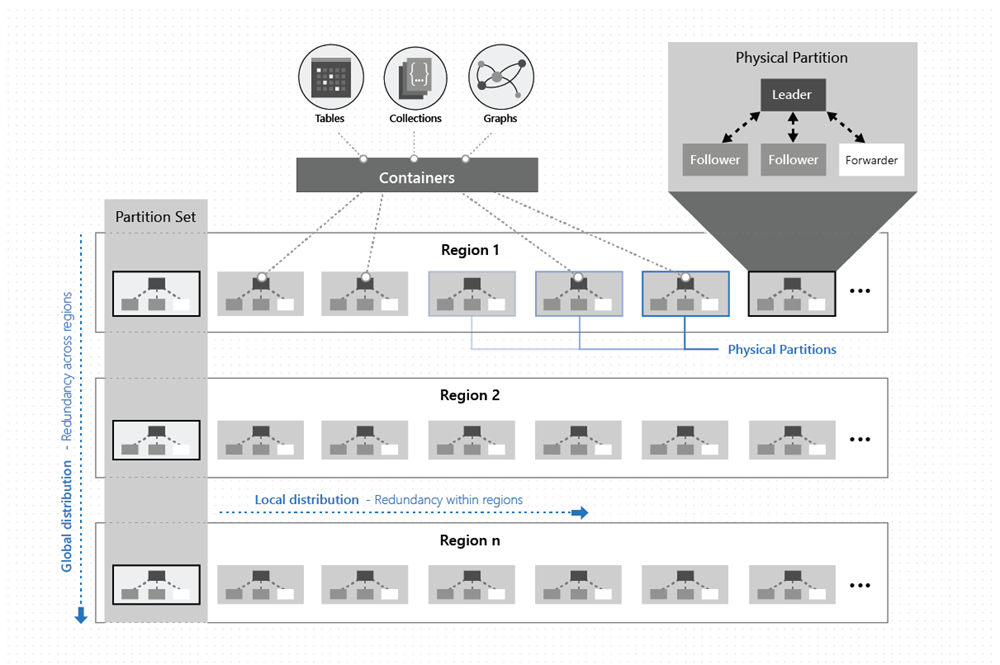
Een fysieke partitie wordt geïmplementeerd door een groep replica's, een replicaset genaamd. Elke machine host honderden replica's die overeenkomen met verschillende fysieke partities binnen een vaste set processen, zoals wordt weergegeven in de bovenstaande afbeelding. Replica's die overeenkomen met de fysieke partities, worden dynamisch geplaatst en verdeeld over de computers binnen een cluster en datacenters binnen een regio.
Een replica maakt uniek deel uit van een Azure Cosmos DB-tenant. Elke replica fungeert als host voor een exemplaar van de database-engine van Azure Cosmos DB, waarmee de resources en de bijbehorende indexen worden beheerd. De Azure Cosmos DB-database-engine werkt op een typesysteem op basis van atom-record-sequence (ARS). De engine is neutraal voor het concept van een schema, waardoor de grens tussen de structuur- en instantiewaarden van records wordt vervaagd. Azure Cosmos DB bereikt volledig schemaagnosticisme door alles automatisch te indexeren op een efficiënte manier, zodat gebruikers hun wereldwijd gedistribueerde gegevens kunnen doorzoeken zonder dat ze te maken hebben met schema- of indexbeheer.
De Azure Cosmos DB-database-engine bestaat uit onderdelen, waaronder de implementatie van verschillende coördinatieprimitief, taalruntimes, de queryprocessor en de subsystemen voor opslag en indexering die verantwoordelijk zijn voor respectievelijk transactionele opslag en indexering van gegevens. Om duurzaamheid en hoge beschikbaarheid te bieden, bewaart de database-engine de gegevens en index op DEHD's en repliceert deze tussen de exemplaren van de database-engine in respectievelijk de replicaset(s). Grotere tenants komen overeen met een hogere schaal van doorvoer en opslag en hebben grotere of meer replica's of beide. Elk onderdeel van het systeem is volledig asynchroon: geen thread blokkeert ooit en elke thread werkt kortstondig zonder onnodige threadswitches te maken. Snelheidsbeperking en rugdruk worden over de hele stapel verpruimd van het toegangsbeheer tot alle I/O-paden. Azure Cosmos DB-database-engine is ontworpen om gebruik te maken van fijnmazige gelijktijdigheid en om hoge doorvoer te leveren terwijl het werkt binnen kleine hoeveelheden systeemresources.
De wereldwijde distributie van Azure Cosmos DB is afhankelijk van twee belangrijke abstracties: replicasets en partitiesets. Een replicaset is een modulair Lego-blok voor coördinatie en een partitieset is een dynamische overlay van een of meer geografisch gedistribueerde fysieke partities. Om te begrijpen hoe wereldwijde distributie werkt, moeten we deze twee belangrijke abstracties begrijpen.
Replicasets
Een fysieke partitie wordt gerealiseerd als een zelfbeheerde en dynamisch taakverdelingsgroep van replica's verspreid over meerdere foutdomeinen, een replicaset genoemd. Deze set implementeert gezamenlijk het gerepliceerde statusmachineprotocol om de gegevens binnen de fysieke partitie maximaal beschikbaar, duurzaam en consistent te maken. Het replicasetlidmaatschap N is dynamisch. Het blijft fluctueren tussen NMin en NMax op basis van de fouten, beheerbewerkingen en de tijd voor mislukte replica's om opnieuw te genereren/herstellen. Op basis van de lidmaatschapswijzigingen configureert het replicatieprotocol ook de grootte van lees- en schrijfquorums opnieuw. Om de doorvoer die is toegewezen aan een bepaalde fysieke partitie uniform te verdelen, gebruiken we twee ideeën:
Ten eerste zijn de kosten voor het verwerken van de schrijfaanvragen op de leider hoger dan de kosten voor het toepassen van de updates op de volger. Op dezelfde manier wordt de leider meer systeemresources gebudgetteerd dan de volgers.
Ten tweede bestaat het leesquorum voor een bepaald consistentieniveau zo veel mogelijk uitsluitend uit de volgreplica's. We voorkomen dat contact wordt opgenomen met de leider voor het uitvoeren van leesbewerkingen, tenzij dit vereist is. We gebruiken een aantal ideeën uit het onderzoek dat is uitgevoerd op de relatie tussen belasting en capaciteit in de quorumsystemen voor de vijf consistentiemodellen die Door Azure Cosmos DB worden ondersteund.
Partitiesets
Een groep fysieke partities, één van de geconfigureerde met de Azure Cosmos DB-databaseregio's, bestaat uit het beheren van dezelfde set sleutels die zijn gerepliceerd in alle geconfigureerde regio's. Deze hogere coördinatieprimitief wordt een partitieset genoemd: een geografisch gedistribueerde dynamische overlay van fysieke partities die een bepaalde set sleutels beheren. Hoewel een bepaalde fysieke partitie (een replicaset) binnen een cluster valt, kan een partitieset clusters, datacenters en geografische regio's omvatten, zoals wordt weergegeven in de onderstaande afbeelding:
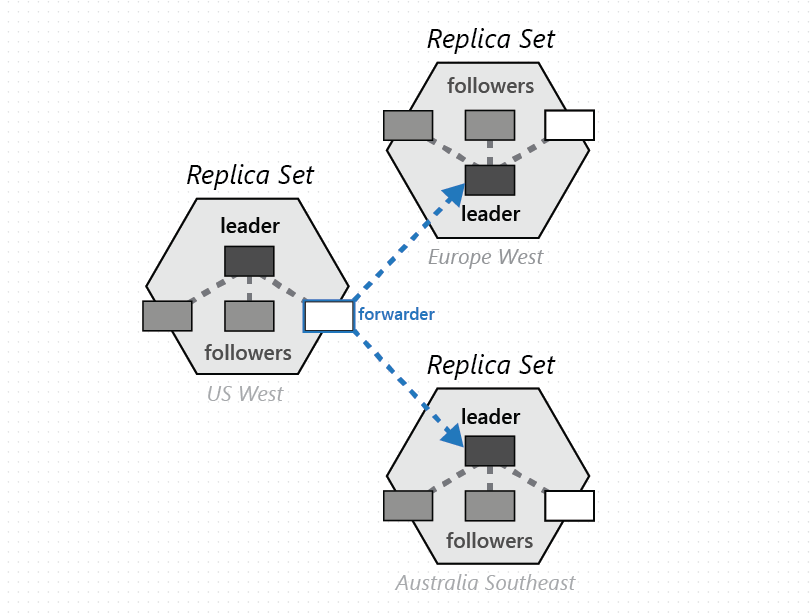
U kunt een partitieset beschouwen als een geografisch verspreide superreplicaset, die bestaat uit meerdere replicasets die eigenaar zijn van dezelfde set sleutels. Net als bij een replicaset is het lidmaatschap van een partitieset ook dynamisch: deze fluctueert op basis van impliciete bewerkingen voor beheer van fysieke partities om nieuwe partities toe te voegen aan/te verwijderen uit een bepaalde partitieset (bijvoorbeeld wanneer u doorvoer op een container uitschaalt, een regio toevoegt of verwijdert aan uw Azure Cosmos DB-database of wanneer er fouten optreden). Omdat elk van de partities (van een partitieset) het lidmaatschap van de partitieset binnen een eigen replicaset beheert, is het lidmaatschap volledig gedecentraliseerd en maximaal beschikbaar. Tijdens de herconfiguratie van een partitieset wordt ook de topologie van de overlay tussen fysieke partities tot stand gebracht. De topologie wordt dynamisch geselecteerd op basis van het consistentieniveau, de geografische afstand en de beschikbare netwerkbandbreedte tussen de bron en de fysieke doelpartities.
Met de service kunt u uw Azure Cosmos DB-databases configureren met één schrijfregio of meerdere schrijfregio's. Afhankelijk van de keuze worden partitiesets geconfigureerd om schrijfbewerkingen in precies één of alle regio's te accepteren. Het systeem maakt gebruik van een geneste consensusprotocol op twee niveaus: één niveau werkt binnen de replica's van een replicaset van een fysieke partitie die de schrijfbewerkingen accepteert en de andere werkt op het niveau van een partitieset om volledige volgordegaranties te bieden voor alle vastgelegde schrijfbewerkingen binnen de partitieset. Deze geneste consensus met meerdere lagen is essentieel voor de implementatie van onze strenge SLA's voor hoge beschikbaarheid, evenals de implementatie van de consistentiemodellen, die Azure Cosmos DB aan haar klanten biedt.
Oplossing van conflicten
Ons ontwerp voor het doorgeven van updates, conflictoplossing en causaliteitstracering is geïnspireerd op het vorige werk over epidemische algoritmen en het Bayou-systeem . Hoewel de kernels van de ideeën hebben overleefd en een handig referentiekader bieden voor het communiceren van het systeemontwerp van Azure Cosmos DB, hebben ze ook een aanzienlijke transformatie ondergaan terwijl we ze hebben toegepast op het Azure Cosmos DB-systeem. Dit was nodig, omdat de vorige systemen niet zijn ontworpen met de resourcegovernance, noch met de schaal waarop Azure Cosmos DB moet werken, noch om de mogelijkheden (bijvoorbeeld gebonden verouderingsconsistentie) en de strenge en uitgebreide SLA's die Azure Cosmos DB aan haar klanten levert te bieden.
Zoals u weet, wordt een partitieset verdeeld over meerdere regio's en volgt u het replicatieprotocol van Azure Cosmos DB (schrijfbewerkingen in meerdere regio's) om de gegevens te repliceren tussen de fysieke partities die uit een bepaalde partitieset bestaan. Elke fysieke partitie (van een partitieset) accepteert schrijfbewerkingen en dient doorgaans leesbewerkingen voor de clients die lokaal in die regio zijn. Schrijfbewerkingen die worden geaccepteerd door een fysieke partitie binnen een regio, worden duurzaam doorgevoerd en maximaal beschikbaar gemaakt binnen de fysieke partitie voordat ze aan de client worden bevestigd. Dit zijn voorlopige schrijfbewerkingen en worden doorgegeven aan andere fysieke partities binnen de partitieset met behulp van een anti-entropiekanaal. Clients kunnen voorlopige of vastgelegde schrijfbewerkingen aanvragen door een aanvraagheader door te geven. De anti-entropiedoorgifte (inclusief de frequentie van doorgifte) is dynamisch, op basis van de topologie van de partitieset, regionale nabijheid van de fysieke partities en het geconfigureerde consistentieniveau. Binnen een partitieset volgt Azure Cosmos DB een primair doorvoerschema met een dynamisch geselecteerde arbiterpartitie. De arbiterselectie is dynamisch en is een integraal onderdeel van de herconfiguratie van de partitieset op basis van de topologie van de overlay. De vastgelegde schrijfbewerkingen (inclusief updates met meerdere rijen/batches) worden gegarandeerd geordend.
We gebruiken gecodeerde vectorklokken (met regio-id's en logische klokken die overeenkomen met elk consensusniveau in de replicaset en partitieset, respectievelijk) voor causaliteitstracering en versievectors om updateconflicten te detecteren en op te lossen. De topologie en het peerselectie-algoritme zijn ontworpen om vaste en minimale opslag en minimale netwerkoverhead van versievectors te garanderen. Het algoritme garandeert de strikte convergentie-eigenschap.
Voor de Azure Cosmos DB-databases die zijn geconfigureerd met meerdere schrijfregio's, biedt het systeem een aantal flexibele beleidsregels voor automatische conflictoplossing waaruit de ontwikkelaars kunnen kiezen, waaronder:
- Last-Write-Wins (LWW), die standaard een door het systeem gedefinieerde tijdstempeleigenschap gebruikt (die is gebaseerd op het tijdsynchronisatieklokprotocol). Met Azure Cosmos DB kunt u ook opgeven welke andere aangepaste numerieke eigenschap moet worden gebruikt voor conflictoplossing.
- Toepassingsgedefinieerde (aangepaste) conflictoplossingsbeleid (uitgedrukt via samenvoegprocedures), dat is ontworpen voor door de toepassing gedefinieerde semantiekafstemming van conflicten. Deze procedures worden aangeroepen bij het detecteren van schrijf-schrijfconflicten onder het toezicht van een databasetransactie aan de serverzijde. Het systeem biedt precies eenmaal garantie voor de uitvoering van een samenvoegprocedure als onderdeel van het toezeggingsprotocol. Er zijn verschillende voorbeelden voor conflictoplossing beschikbaar waarmee u kunt spelen.
Consistentiemodellen
Of u nu uw Azure Cosmos DB-database configureert met één of meerdere schrijfregio's, u kunt kiezen uit de vijf goed gedefinieerde consistentiemodellen. Met meerdere schrijfregio's zijn de volgende enkele belangrijke aspecten van de consistentieniveaus:
De consistentie gebonden veroudering garandeert dat alle leesbewerkingen binnen K-voorvoegsels of T seconden van de meest recente schrijfbewerking in een van de regio's vallen. Bovendien zijn leesbewerkingen met gebonden verouderingsconsistentie gegarandeerd monotone en met consistente voorvoegselgaranties. Het anti-entropieprotocol werkt op een snelheidslimiet en zorgt ervoor dat de voorvoegsels niet accumuleren en dat de tegendruk op de schrijfbewerkingen niet hoeft te worden toegepast. Sessieconsistentie garandeert monotone lees-, monotone schrijfbewerkingen, lezen van uw eigen schrijfbewerkingen, schrijven volgt lees- en consistente voorvoegselgaranties, wereldwijd. Voor de databases die zijn geconfigureerd met sterke consistentie, zijn de voordelen (lage schrijflatentie, hoge schrijfbeschikbaarheid) van meerdere schrijfregio's niet van toepassing vanwege synchrone replicatie tussen regio's.
De semantiek van de vijf consistentiemodellen in Azure Cosmos DB worden hier beschreven en wiskundig beschreven met behulp van een TLA+-specificaties op hoog niveau.
Volgende stappen
Hierna leert u hoe u wereldwijde distributie configureert met behulp van de volgende artikelen:
- Regio's toevoegen aan/verwijderen uit uw databaseaccount
- Een aangepast conflictoplossingsbeleid maken
- Wilt u capaciteitsplanning uitvoeren voor een migratie naar Azure Cosmos DB? U kunt informatie over uw bestaande databasecluster gebruiken voor capaciteitsplanning.
- Als alles wat u weet het aantal vcores en servers in uw bestaande databasecluster is, leest u meer over het schatten van aanvraageenheden met behulp van vCores of vCPU's
- Als u typische aanvraagtarieven voor uw huidige databaseworkload kent, leest u meer over het schatten van aanvraageenheden met behulp van azure Cosmos DB-capaciteitsplanner