Azure-aanbevelingen ophalen om uw SQL Server-database te migreren
De Azure SQL Migration-extensie voor Azure Data Studio helpt u bij het beoordelen van uw databasevereisten, het verkrijgen van de juiste SKU-aanbevelingen voor Azure-resources en het migreren van uw SQL Server-database naar Azure.
Meer informatie over het gebruik van deze uniforme ervaring, het verzamelen van prestatiegegevens van uw SQL Server-bronexemplaren om azure-aanbevelingen voor uw Azure SQL-doelen op de juiste grootte te krijgen.
Overzicht
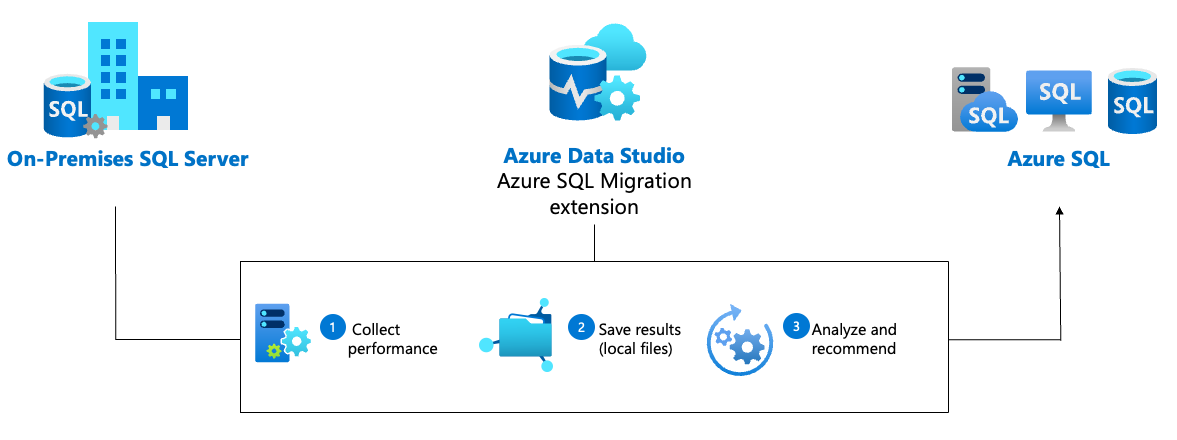
Voordat u naar Azure SQL migreert, kunt u de SQL Migration-extensie in Azure Data Studio gebruiken om aanbevelingen voor Azure SQL Database, Azure SQL Managed Instance en SQL Server op Azure Virtual Machines-doelen te genereren. Het hulpprogramma helpt u bij het verzamelen van prestatiegegevens van uw SQL-bronexemplaren (on-premises of een andere cloud) en het aanbevelen van een berekenings- en opslagconfiguratie om te voldoen aan de behoeften van uw workload.
Het diagram toont de werkstroom voor Azure-aanbevelingen in de Azure SQL Migration-extensie voor Azure Data Studio:
Notitie
Evaluatie en de azure-aanbevelingsfunctie in de Azure SQL Migration-extensie voor Azure Data Studio ondersteunt bron-SQL Server-exemplaren die worden uitgevoerd in Windows of Linux.
Vereisten
Als u aan de slag wilt gaan met Azure-aanbevelingen voor uw SQL Server-databasemigratie, moet u voldoen aan de volgende vereisten:
- Download en installeer Azure Data Studio.
- Installeer de Azure SQL Migration-extensie vanuit Azure Data Studio Marketplace.
- Zorg ervoor dat de aanmelding die u gebruikt om verbinding te maken met het SQL Server-bronexemplaren, de minimale machtigingen heeft.
Ondersteunde bronnen en doelen
Azure-aanbevelingen kunnen worden gegenereerd voor de volgende SQL Server-versies:
- SQL Server 2008 en latere versies in Windows of Linux worden ondersteund.
- SQL Server die wordt uitgevoerd in andere clouds, kan worden ondersteund, maar de nauwkeurigheid van de resultaten kan variëren
Azure-aanbevelingen kunnen worden gegenereerd voor de volgende Azure SQL-doelen:
- Azure SQL Database
- Hardwarefamilies: Standard-serie (Gen5)
- Servicelagen: Algemeen gebruik, Bedrijfskritiek, Hyperscale
- Azure SQL Managed Instance
- Hardwarefamilies: Standard-serie (Gen5), Premium-serie, Geoptimaliseerd voor geheugen
- Servicelagen: Algemeen gebruik, Bedrijfskritiek
- SQL Server op virtuele Azure-machine
- VM-families: Algemeen gebruik, geoptimaliseerd voor geheugen
- Opslagfamilies: Premium SSD
Prestatiegegevens verzamelen
Voordat aanbevelingen kunnen worden gegenereerd, moeten prestatiegegevens worden verzameld van uw SQL Server-bronexemplaren. Tijdens deze gegevensverzamelingsstap worden meerdere dynamische systeemweergaven (DMV's) van uw SQL Server-exemplaar opgevraagd om de prestatiekenmerken van uw workload vast te leggen. Het hulpprogramma legt elke 30 seconden metrische gegevens vast, waaronder CPU-, geheugen-, opslag- en IO-gebruik, en slaat de prestatiemeteritems lokaal op uw computer op als een set CSV-bestanden.
Instantieniveau
Deze prestatiegegevens worden eenmaal per SQL Server-exemplaar verzameld:
| Prestatiedimensie | Omschrijving | Dynamische beheerweergave (DMV) |
|---|---|---|
| SqlInstanceCpuPercent | De hoeveelheid CPU die het SQL Server-proces gebruikte, als percentage | sys.dm_os_ring_buffers |
| PhysicalMemoryInUse | Totale geheugenvoetafdruk van het SQL Server-proces | sys.dm_os_process_memory |
| MemoryUtilizationPercentage | Geheugengebruik van SQL Server | sys.dm_os_process_memory |
Databaseniveau
| Prestatiedimensie | Omschrijving | Dynamische beheerweergave (DMV) |
|---|---|---|
| DatabaseCpuPercent | Het totale percentage CPU dat door een database wordt gebruikt | sys.dm_exec_query_stats |
| CachedSizeInMb | Totale grootte in megabytes aan cache die door een database worden gebruikt | sys.dm_os_buffer_descriptors |
Bestandsniveau
| Prestatiedimensie | Omschrijving | Dynamische beheerweergave (DMV) |
|---|---|---|
| ReadIOInMb | Het totale aantal megabytes dat uit dit bestand is gelezen | sys.dm_io_virtual_file_stats |
| WriteIOInMb | Het totale aantal megabytes dat naar dit bestand is geschreven | sys.dm_io_virtual_file_stats |
| NumOfReads | Het totale aantal leesbewerkingen dat op dit bestand is uitgegeven | sys.dm_io_virtual_file_stats |
| NumOfWrites | Het totale aantal schrijfbewerkingen dat op dit bestand is uitgegeven | sys.dm_io_virtual_file_stats |
| ReadLatency | De I/O-leeslatentie voor dit bestand | sys.dm_io_virtual_file_stats |
| WriteLatency | De io-schrijflatentie voor dit bestand | sys.dm_io_virtual_file_stats |
Er is minimaal 10 minuten aan gegevensverzameling vereist voordat een aanbeveling kan worden gegenereerd, maar om uw werkbelasting nauwkeurig te beoordelen, is het raadzaam om de gegevensverzameling gedurende een voldoende lange periode uit te voeren om zowel het piek- als het off-piekgebruik vast te leggen.
Als u het proces voor het verzamelen van gegevens wilt initiëren, begint u met het maken van verbinding met uw bron-SQL-exemplaar in Azure Data Studio en start u vervolgens de wizard SQL-migratie. Selecteer 'Azure-aanbeveling ophalen' bij stap 2. Selecteer Nu prestatiegegevens verzamelen en selecteer een map op uw computer waar de verzamelde gegevens worden opgeslagen.
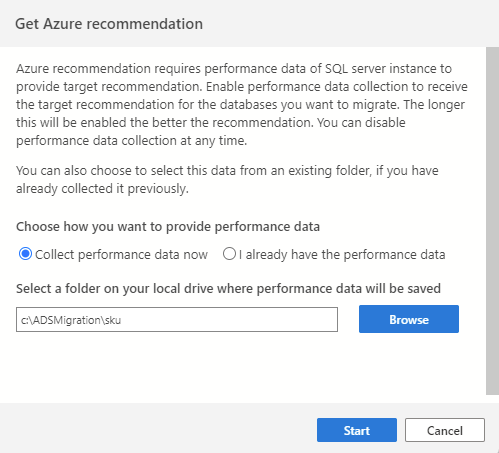
Belangrijk
Het proces voor gegevensverzameling wordt 10 minuten uitgevoerd om de eerste aanbeveling te genereren. Het is belangrijk om het proces voor het verzamelen van gegevens te starten wanneer uw actieve databaseworkload het gebruik weerspiegelt dat vergelijkbaar is met uw productiescenario's.
Nadat de eerste aanbeveling is gegenereerd, kunt u het proces voor gegevensverzameling blijven uitvoeren om aanbevelingen te verfijnen. Deze optie is vooral handig als uw gebruikspatronen in de loop van de tijd variëren.
Het proces voor het verzamelen van gegevens begint zodra u Start selecteert. Elke 10 minuten worden de verzamelde gegevenspunten geaggregeerd en worden de maximale, gemiddelde en variantie van elke teller naar de schijf geschreven naar een set van drie CSV-bestanden.
Meestal ziet u een set CSV-bestanden met de volgende achtervoegsels in de geselecteerde map:
SQLServerInstance_CommonDbLevel_Counters.csv: bevat statische configuratiegegevens over de indeling en metagegevens van het databasebestand.SQLServerInstance_CommonInstanceLevel_Counters.csv: bevat statische gegevens over de hardwareconfiguratie van het serverexemplaren.SQLServerInstance_PerformanceAggregated_Counters.csv: bevat geaggregeerde prestatiegegevens die regelmatig worden bijgewerkt.
Laat Azure Data Studio gedurende deze tijd open, maar u kunt doorgaan met andere bewerkingen. U kunt het gegevensverzamelingsproces op elk gewenst moment stoppen door terug te keren naar deze pagina en gegevensverzameling stoppen te selecteren.
Aanbevelingen op juiste grootte genereren
Als u al prestatiegegevens van een vorige sessie hebt verzameld of een ander hulpprogramma (zoals Database Migration Assistant) gebruikt, kunt u bestaande prestatiegegevens importeren door de optie te selecteren die ik al heb. Ga verder met het selecteren van de map waarin uw prestatiegegevens (drie CSV-bestanden) zijn opgeslagen en selecteer Start om het aanbevelingsproces te starten.
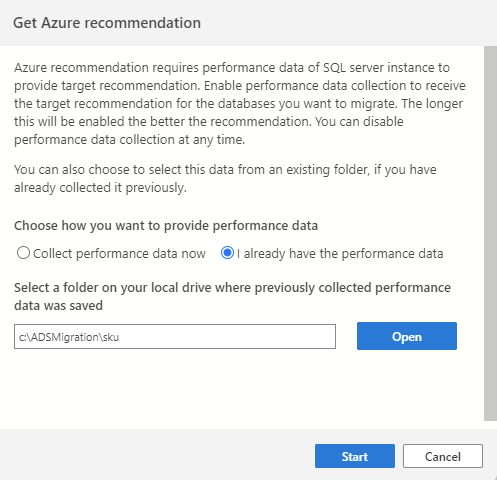
Notitie
Stap één van de sql-migratiewizard vraagt u om een set databases te selecteren die u wilt evalueren. Dit zijn de enige databases die tijdens het aanbevelingsproces in aanmerking worden genomen.
Het verzamelingsproces voor prestatiegegevens verzamelt echter prestatiemeteritems voor alle databases uit het SQL Server-bronexemplaren, niet alleen de databases die zijn geselecteerd.
Dit betekent dat eerder verzamelde prestatiegegevens kunnen worden gebruikt om herhaaldelijk aanbevelingen voor een andere subset van databases opnieuw te genereren door een andere lijst op te geven in stap 1.
Aanbevelingsparameters
Er zijn meerdere configureerbare instellingen die van invloed kunnen zijn op uw aanbevelingen.
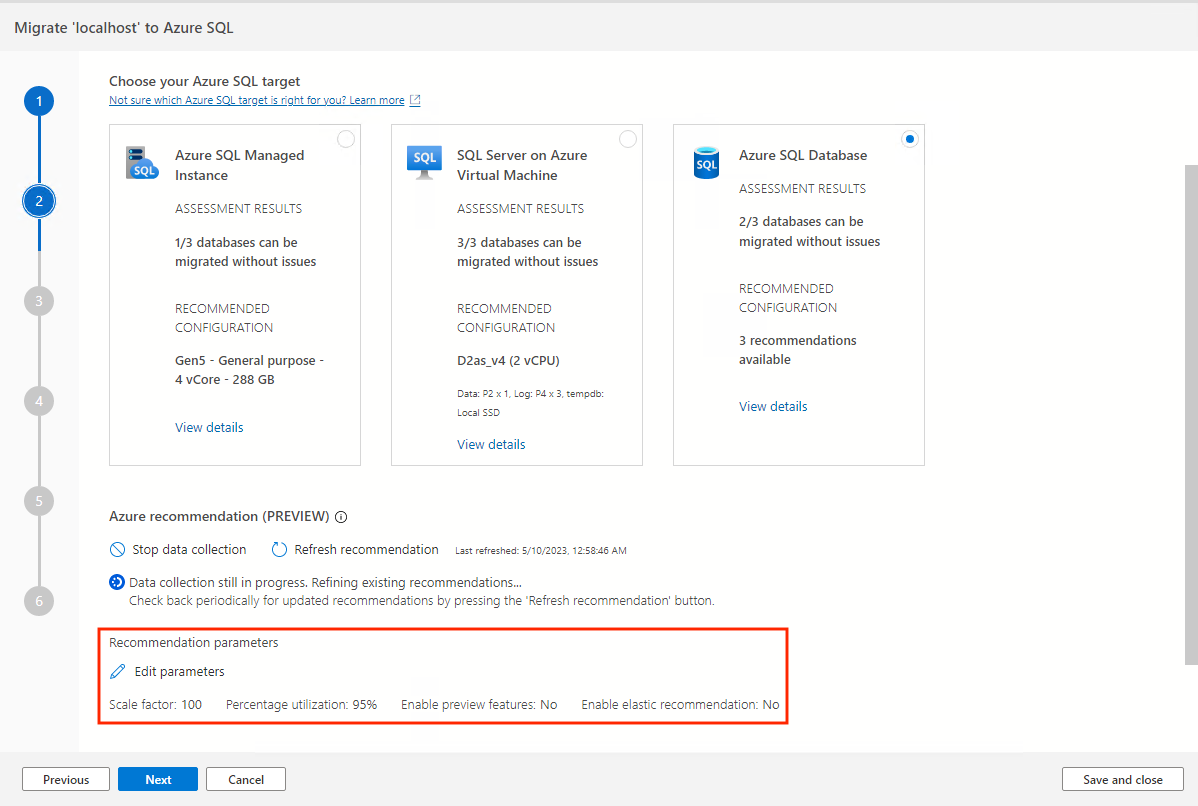
Selecteer de optie Parameters bewerken om deze parameters aan te passen aan uw behoeften.
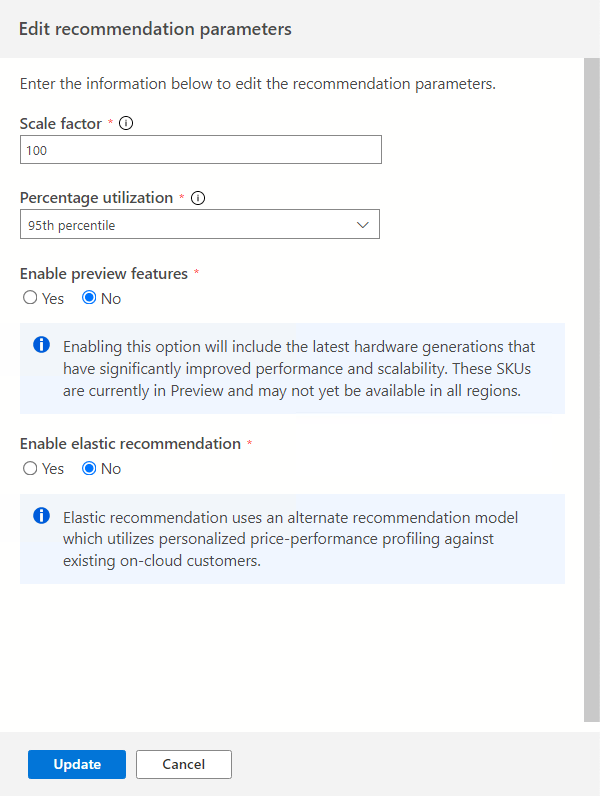
Schaalfactor:
Met deze optie kunt u een buffer opgeven die op elke prestatiedimensie kan worden toegepast. Deze optie houdt rekening met problemen zoals seizoensgebonden gebruik, korte prestatiegeschiedenis en waarschijnlijk toeneemt in toekomstig gebruik. Als u bijvoorbeeld bepaalt dat een CPU-vereiste van vier vCores een schaalfactor van 150% heeft, is de werkelijke CPU-vereiste zes vCores.Het standaardschaalfactorvolume is 100%.
Percentagegebruik:
Het percentiel van gegevenspunten dat moet worden gebruikt als prestatiegegevens worden geaggregeerd.De standaardwaarde is het 95e percentiel.
Preview-functies inschakelen:
Met deze optie kunnen configuraties worden aanbevolen die mogelijk nog niet algemeen beschikbaar zijn voor alle gebruikers in alle regio's.Deze optie is standaard uitgeschakeld.
Elastische aanbeveling inschakelen:
Deze optie maakt gebruik van een alternatief aanbevelingsmodel dat gebruikmaakt van gepersonaliseerde prijs-prestatieprofilering voor bestaande on-cloudklanten.
Deze optie is standaard uitgeschakeld.
Belangrijk
Het proces voor het verzamelen van gegevens wordt beëindigd als u Azure Data Studio sluit. De gegevens die tot dat moment zijn verzameld, worden opgeslagen in uw map.
Als u Azure Data Studio sluit terwijl gegevensverzameling wordt uitgevoerd, gebruikt u een van de volgende opties om gegevensverzameling opnieuw te starten:
- Open Azure Data Studio opnieuw en importeer de gegevensbestanden die zijn opgeslagen in uw lokale map. Genereer vervolgens een aanbeveling van de verzamelde gegevens.
- Open Azure Data Studio opnieuw en start het verzamelen van gegevens opnieuw met behulp van de migratiewizard.
Minimale machtigingen
Als u een query wilt uitvoeren op de benodigde systeemweergaven voor het verzamelen van prestatiegegevens, zijn specifieke machtigingen vereist voor de SQL Server-aanmelding die voor deze taak wordt gebruikt. U kunt een gebruiker met minimale bevoegdheden maken voor het verzamelen van evaluatie- en prestatiegegevens met behulp van het volgende script:
-- Create a login to run the assessment
USE master;
GO
CREATE LOGIN [assessment] WITH PASSWORD = '<STRONG PASSWORD>';
-- Create user in every database other than TempDB and model and provide minimal read-only permissions
EXECUTE sp_MSforeachdb '
USE [?];
IF (''?'' NOT IN (''TempDB'',''model''))
BEGIN TRY
CREATE USER [assessment] FOR LOGIN [assessment]
END TRY
BEGIN CATCH
PRINT ERROR_MESSAGE()
END CATCH'
EXECUTE sp_MSforeachdb '
USE [?];
IF (''?'' NOT IN (''tempdb'',''model''))
BEGIN TRY
GRANT SELECT ON sys.sql_expression_dependencies TO [assessment]
END TRY
BEGIN CATCH
PRINT ERROR_MESSAGE()
END CATCH'
EXECUTE sp_MSforeachdb '
USE [?];
IF (''?'' NOT IN (''tempdb'',''model''))
BEGIN TRY
GRANT VIEW DATABASE STATE TO [assessment]
END TRY
BEGIN CATCH
PRINT ERROR_MESSAGE()
END CATCH'
-- Provide server level read-only permissions
GRANT SELECT ON sys.sql_expression_dependencies TO [assessment];
GRANT SELECT ON sys.sql_expression_dependencies TO [assessment];
GRANT EXECUTE ON OBJECT::sys.xp_regenumkeys TO [assessment];
GRANT VIEW DATABASE STATE TO assessment;
GRANT VIEW SERVER STATE TO assessment;
GRANT VIEW ANY DEFINITION TO assessment;
-- Provide msdb specific permissions
USE msdb;
GO
GRANT EXECUTE ON [msdb].[dbo].[agent_datetime] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysjobsteps] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[syssubsystems] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysjobhistory] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[syscategories] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysjobs] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmaintplan_plans] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[syscollector_collection_sets] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmail_profile] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmail_profileaccount] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmail_account] TO [assessment];
-- USE master;
-- GO
-- EXECUTE sp_MSforeachdb 'USE [?]; BEGIN TRY DROP USER [assessment] END TRY BEGIN CATCH SELECT ERROR_MESSAGE() END CATCH';
-- DROP LOGIN [assessment];
Niet-ondersteunde scenario's en beperkingen
- Azure Aanbevelingen geen prijsramingen bevatten, omdat deze situatie kan variëren, afhankelijk van regio, valuta en kortingen zoals Azure Hybrid Benefit. Als u prijsschattingen wilt ophalen, gebruikt u de Azure-prijscalculator of maakt u een SQL-evaluatie in Azure Migrate.
- Aanbevelingen voor Azure SQL Database met de Aankoopmodel op basis van DTU wordt niet ondersteund.
- Momenteel worden Azure-aanbevelingen voor de serverloze rekenlaag van Azure SQL Database en elastische pools niet ondersteund.
Problemen oplossen
- Geen aanbevelingen gegenereerd
- Als er geen aanbevelingen zijn gegenereerd, kan dit betekenen dat er geen configuraties zijn geïdentificeerd die volledig aan de prestatievereisten van uw bronexemplaren kunnen voldoen. Om te zien waarom een bepaalde grootte, servicelaag of hardwarefamilie is gediskwalificeerd:
- Open de logboeken vanuit Azure Data Studio door naar de map Alle opdrachten voor het openen van extensielogboeken weer > te > geven
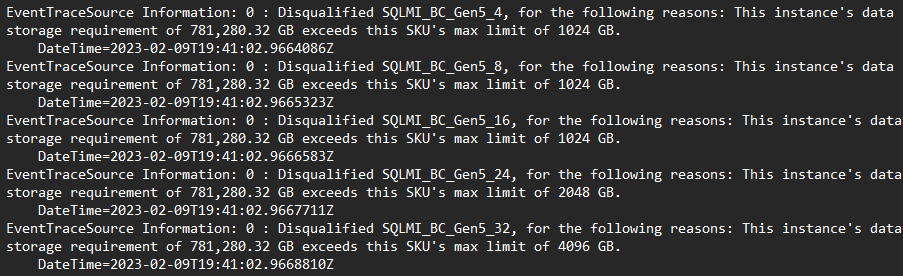
- Navigeer naar Microsoft.mssql > SqlAssessmentLogs > open SkuRecommendationEvent.log
- Het logboek bevat een tracering van elke mogelijke configuratie die is geëvalueerd en de reden waarom het niet als een in aanmerking komende configuratie wordt beschouwd:
- Probeer de aanbeveling opnieuw te genereren met elastische aanbeveling ingeschakeld. Deze optie maakt gebruik van een alternatief aanbevelingsmodel, dat gebruikmaakt van gepersonaliseerde prijs-prestatieprofilering voor bestaande on-cloudklanten.
- Als er geen aanbevelingen zijn gegenereerd, kan dit betekenen dat er geen configuraties zijn geïdentificeerd die volledig aan de prestatievereisten van uw bronexemplaren kunnen voldoen. Om te zien waarom een bepaalde grootte, servicelaag of hardwarefamilie is gediskwalificeerd: