Zelfstudie: Grote gegevens uit Apache Spark indexeren met behulp van SynapseML en Azure AI Search
In deze zelfstudie over Azure AI Search leert u hoe u grote gegevens kunt indexeren en er query's op kunt uitvoeren die zijn geladen vanuit een Spark-cluster. Stel een Jupyter Notebook in waarmee de volgende acties worden uitgevoerd:
- Verschillende formulieren (facturen) laden in een gegevensframe in een Apache Spark-sessie
- Ze analyseren om hun functies te bepalen
- De resulterende uitvoer samenstellen in een gegevensstructuur in tabelvorm
- De uitvoer schrijven naar een zoekindex die wordt gehost in Azure AI Search
- Verkennen en query's uitvoeren op de inhoud die u hebt gemaakt
In deze zelfstudie wordt gebruik gemaakt van SynapseML, een opensource-bibliotheek die ondersteuning biedt voor massaal parallelle machine learning via big data. In SynapseML worden zoekindexering en machine learning weergegeven via transformatoren die gespecialiseerde taken uitvoeren. Transformatoren maken gebruik van een breed scala aan AI-mogelijkheden. In deze oefening gebruikt u de AzureSearchWriter-API's voor analyse en AI-verrijking.
Hoewel Azure AI Search systeemeigen AI-verrijking heeft, ziet u in deze zelfstudie hoe u toegang krijgt tot AI-mogelijkheden buiten Azure AI Search. Door SynapseML te gebruiken in plaats van indexeerfuncties of vaardigheden, bent u niet onderworpen aan gegevenslimieten of andere beperkingen die aan deze objecten zijn gekoppeld.
Tip
Bekijk een korte video van deze demo op https://www.youtube.com/watch?v=iXnBLwp7f88. De video breidt deze zelfstudie uit met meer stappen en visuals.
Vereisten
U hebt de synapseml bibliotheek en verschillende Azure-resources nodig. Gebruik indien mogelijk hetzelfde abonnement en dezelfde regio voor uw Azure-resources en plaats alles in één resourcegroep voor later opschonen. De volgende koppelingen zijn voor portal-installaties. De voorbeeldgegevens worden geïmporteerd vanaf een openbare site.
- SynapseML-pakket1
- Azure AI Search (elke laag) 2
- Azure AI-services (elke laag) 3
- Azure Databricks (elke laag) 4
1 Deze koppeling wordt omgezet in een zelfstudie voor het laden van het pakket.
2 U kunt de gratis zoeklaag gebruiken om de voorbeeldgegevens te indexeren, maar kies een hogere laag als uw gegevensvolumes groot zijn. Geef voor factureerbare lagen de zoek-API-sleutel op in de stap Afhankelijkheden instellen.
3 Deze zelfstudie maakt gebruik van Azure AI Document Intelligence en Azure AI Vertalen. Geef in de volgende instructies een sleutel met meerdere services en de regio op. Dezelfde sleutel werkt voor beide services.
4 In deze zelfstudie biedt Azure Databricks het Spark-computingplatform. We hebben de portalinstructies gebruikt om de werkruimte in te stellen.
Notitie
Alle bovenstaande Azure-resources ondersteunen beveiligingsfuncties in het Microsoft Identity-platform. Voor het gemak wordt in deze zelfstudie ervan uitgegaan dat verificatie op basis van sleutels wordt gebruikt met behulp van eindpunten en sleutels die zijn gekopieerd uit de portalpagina's van elke service. Als u deze werkstroom in een productieomgeving implementeert of de oplossing met anderen deelt, moet u de in code vastgelegde sleutels vervangen door geïntegreerde beveiliging of versleutelde sleutels.
Stap 1: Een Spark-cluster en -notebook maken
In deze sectie maakt u een cluster, installeert u de synapseml bibliotheek en maakt u een notebook om de code uit te voeren.
Zoek uw Azure Databricks-werkruimte in Azure Portal en selecteer Werkruimte starten.
Selecteer Compute in het linkermenu.
Selecteer Rekenproces maken.
Accepteer de standaardconfiguratie. Het maken van het cluster duurt enkele minuten.
Installeer de
synapsemlbibliotheek nadat het cluster is gemaakt:Selecteer Bibliotheken op de tabbladen boven aan de pagina van het cluster.
Selecteer Nieuwe installeren.
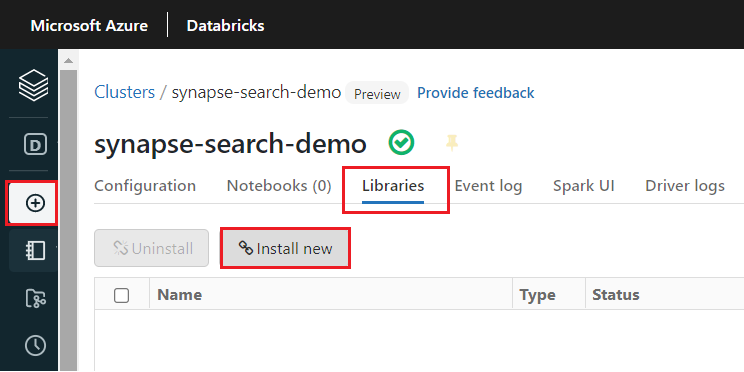
Selecteer Maven.
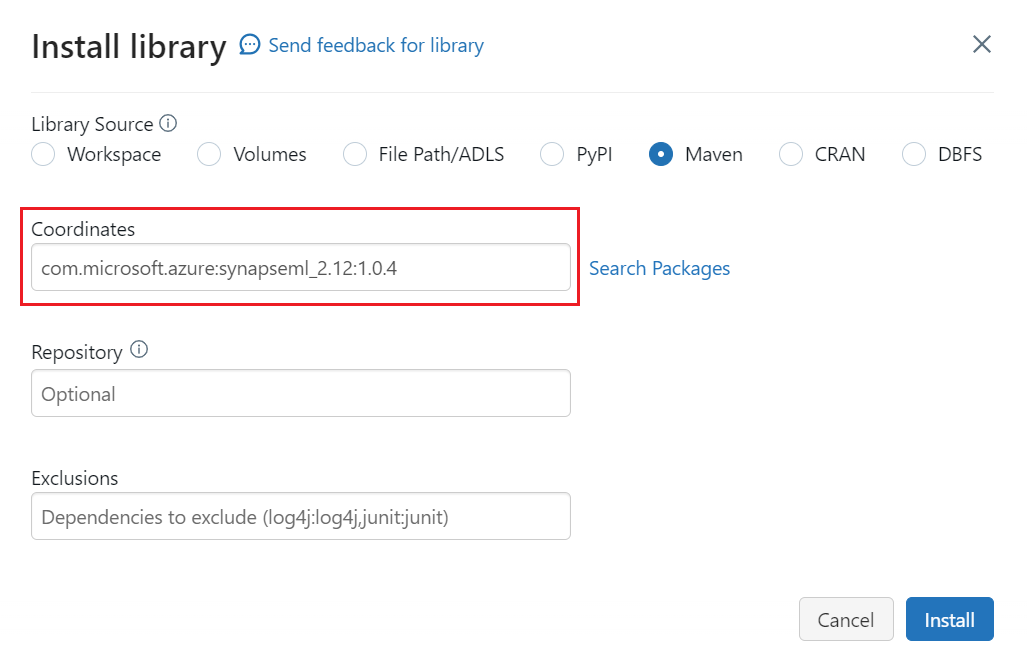
Voer in Coördinaten de tekst in
com.microsoft.azure:synapseml_2.12:1.0.4Selecteer Installeren.
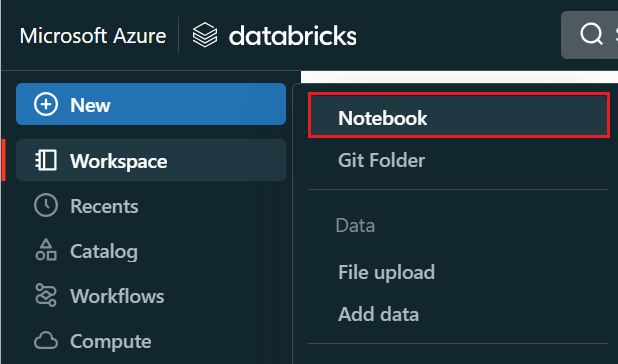
Selecteer Notitieblok maken>in het linkermenu.
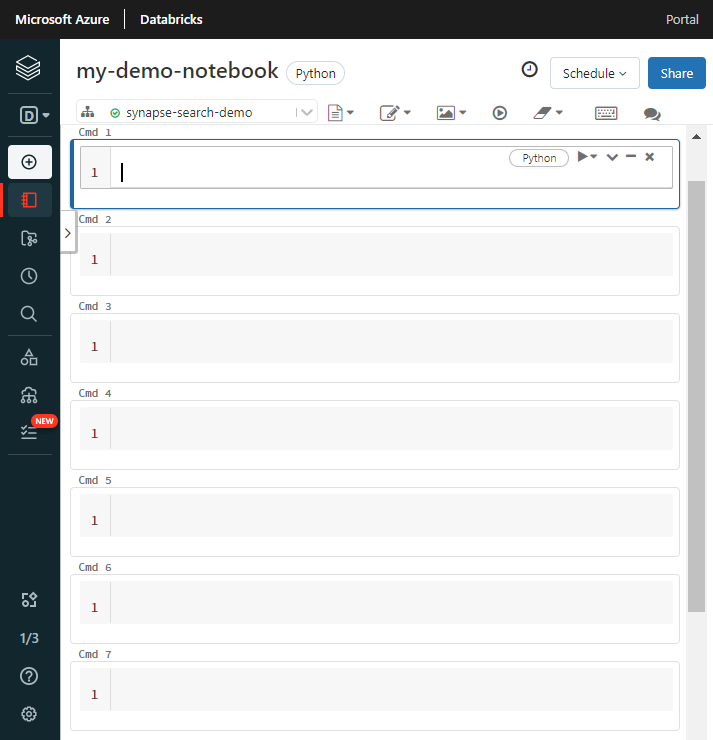
Geef het notebook een naam, selecteer Python als de standaardtaal en selecteer het cluster met de
synapsemlbibliotheek.Maak zeven opeenvolgende cellen. Plak code in elke code.
Stap 2: Afhankelijkheden instellen
Plak de volgende code in de eerste cel van uw notebook.
Vervang de tijdelijke aanduidingen door eindpunten en toegangssleutels voor elke resource. Geef een naam op voor een nieuwe zoekindex. Er zijn geen andere wijzigingen vereist, dus voer de code uit wanneer u klaar bent.
Met deze code worden meerdere pakketten geïmporteerd en toegang ingesteld tot de Azure-resources die in deze werkstroom worden gebruikt.
import os
from pyspark.sql.functions import udf, trim, split, explode, col, monotonically_increasing_id, lit
from pyspark.sql.types import StringType
from synapse.ml.core.spark import FluentAPI
cognitive_services_key = "placeholder-cognitive-services-multi-service-key"
cognitive_services_region = "placeholder-cognitive-services-region"
search_service = "placeholder-search-service-name"
search_key = "placeholder-search-service-api-key"
search_index = "placeholder-search-index-name"
Stap 3: Gegevens laden in Spark
Plak de volgende code in de tweede cel. Er zijn geen wijzigingen vereist, dus voer de code uit wanneer u klaar bent.
Met deze code worden enkele externe bestanden uit een Azure-opslagaccount geladen. De bestanden zijn verschillende facturen en ze worden in een gegevensframe gelezen.
def blob_to_url(blob):
[prefix, postfix] = blob.split("@")
container = prefix.split("/")[-1]
split_postfix = postfix.split("/")
account = split_postfix[0]
filepath = "/".join(split_postfix[1:])
return "https://{}/{}/{}".format(account, container, filepath)
df2 = (spark.read.format("binaryFile")
.load("wasbs://ignite2021@mmlsparkdemo.blob.core.windows.net/form_subset/*")
.select("path")
.limit(10)
.select(udf(blob_to_url, StringType())("path").alias("url"))
.cache())
display(df2)
Stap 4: Documentinformatie toevoegen
Plak de volgende code in de derde cel. Er zijn geen wijzigingen vereist, dus voer de code uit wanneer u klaar bent.
Met deze code wordt de transformer AnalyzeInvoices geladen en wordt een verwijzing naar het gegevensframe met de facturen doorgegeven. Het roept het vooraf samengestelde factuurmodel van Azure AI Document Intelligence aan om informatie uit de facturen te extraheren.
from synapse.ml.cognitive import AnalyzeInvoices
analyzed_df = (AnalyzeInvoices()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setImageUrlCol("url")
.setOutputCol("invoices")
.setErrorCol("errors")
.setConcurrency(5)
.transform(df2)
.cache())
display(analyzed_df)
De uitvoer van deze stap moet er ongeveer uitzien als in de volgende schermopname. U ziet hoe de formulieranalyse is verpakt in een dicht gestructureerde kolom, waarmee u moeilijk kunt werken. Met de volgende transformatie wordt dit probleem opgelost door de kolom te parseren in rijen en kolommen.
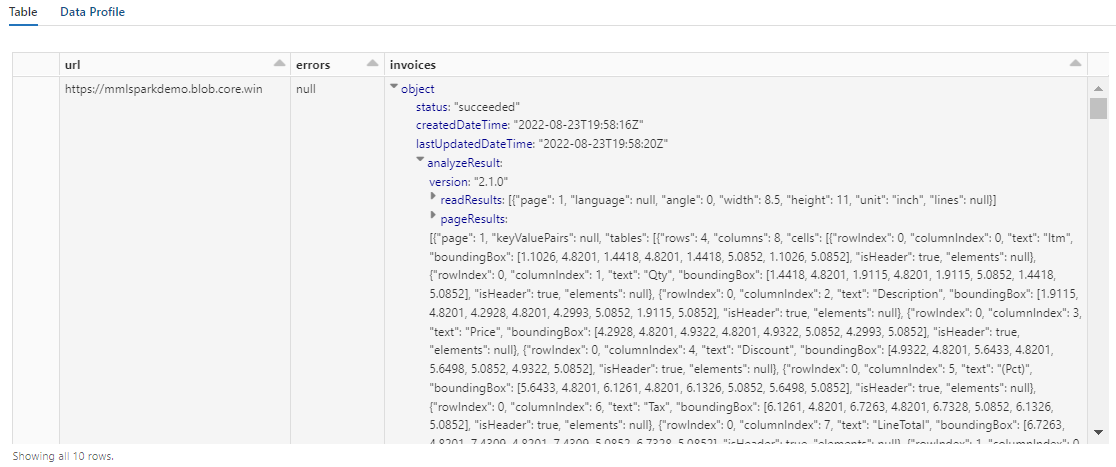
Stap 5: Document intelligence-uitvoer opnieuw structureren
Plak de volgende code in de vierde cel en voer deze uit. Er zijn geen wijzigingen vereist.
Met deze code wordt FormOntologyLearner geladen, een transformator waarmee de uitvoer van Document Intelligence-transformatoren wordt geanalyseerd en een gegevensstructuur in tabelvorm wordt afgeleid. De uitvoer van AnalyzeInvoices is dynamisch en varieert op basis van de functies die in uw inhoud zijn gedetecteerd. Bovendien consolideert de transformator de uitvoer in één kolom. Omdat de uitvoer dynamisch en geconsolideerd is, is het moeilijk om te gebruiken in downstreamtransformaties waarvoor meer structuur is vereist.
FormOntologyLearner breidt het hulpprogramma van de AnalyzeInvoices-transformator uit door te zoeken naar patronen die kunnen worden gebruikt om een tabellaire gegevensstructuur te maken. Door de uitvoer in meerdere kolommen en rijen te ordenen, kan de inhoud worden gebruikt in andere transformatoren, zoals AzureSearchWriter.
from synapse.ml.cognitive import FormOntologyLearner
itemized_df = (FormOntologyLearner()
.setInputCol("invoices")
.setOutputCol("extracted")
.fit(analyzed_df)
.transform(analyzed_df)
.select("url", "extracted.*").select("*", explode(col("Items")).alias("Item"))
.drop("Items").select("Item.*", "*").drop("Item"))
display(itemized_df)
U ziet hoe met deze transformatie de geneste velden worden gerecasteerd in een tabel, waardoor de volgende twee transformaties mogelijk zijn. Deze schermopname is ingekort voor kortheid. Als u uw eigen notitieblok volgt, hebt u 19 kolommen en 26 rijen.
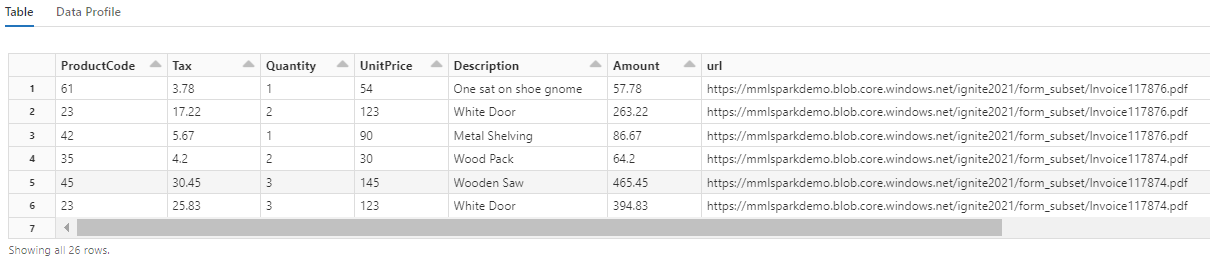
Stap 6: Vertalingen toevoegen
Plak de volgende code in de vijfde cel. Er zijn geen wijzigingen vereist, dus voer de code uit wanneer u klaar bent.
Met deze code wordt Vertalen geladen, een transformator die de Azure AI Vertalen-service aanroept in Azure AI-services. De oorspronkelijke tekst, die in het Engels in de kolom Beschrijving staat, wordt automatisch vertaald in verschillende talen. Alle uitvoer wordt samengevoegd in de matrix output.translations.
from synapse.ml.cognitive import Translate
translated_df = (Translate()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setTextCol("Description")
.setErrorCol("TranslationError")
.setOutputCol("output")
.setToLanguage(["zh-Hans", "fr", "ru", "cy"])
.setConcurrency(5)
.transform(itemized_df)
.withColumn("Translations", col("output.translations")[0])
.drop("output", "TranslationError")
.cache())
display(translated_df)
Tip
Als u wilt controleren op vertaalde tekenreeksen, schuift u naar het einde van de rijen.
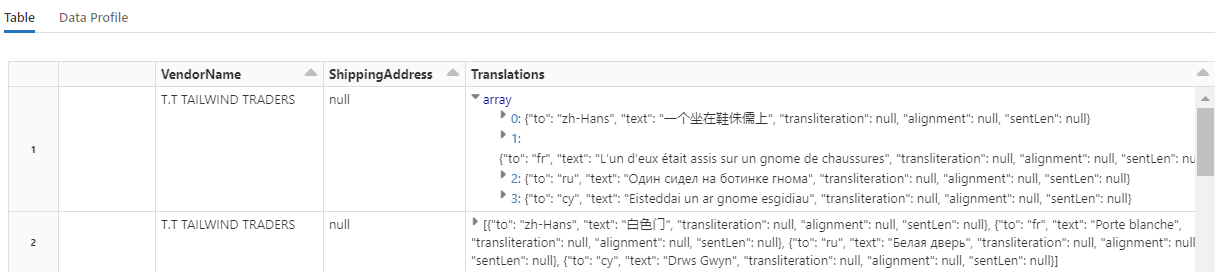
Stap 7: Een zoekindex toevoegen met AzureSearchWriter
Plak de volgende code in de zesde cel en voer deze uit. Er zijn geen wijzigingen vereist.
Met deze code wordt AzureSearchWriter geladen. Er wordt een gegevensset in tabelvorm gebruikt en wordt een zoekindexschema afgeleid dat één veld voor elke kolom definieert. Omdat de structuur van de vertalingen een matrix is, wordt deze in de index geformuleerd als een complexe verzameling met subvelden voor elke taalomzetting. De gegenereerde index heeft een documentsleutel en gebruikt de standaardwaarden voor velden die zijn gemaakt met behulp van de REST API voor index maken.
from synapse.ml.cognitive import *
(translated_df.withColumn("DocID", monotonically_increasing_id().cast("string"))
.withColumn("SearchAction", lit("upload"))
.writeToAzureSearch(
subscriptionKey=search_key,
actionCol="SearchAction",
serviceName=search_service,
indexName=search_index,
keyCol="DocID",
))
U kunt de zoekservicepagina's in Azure Portal controleren om de indexdefinitie te verkennen die is gemaakt door AzureSearchWriter.
Notitie
Als u geen standaardzoekindex kunt gebruiken, kunt u een externe aangepaste definitie opgeven in JSON, waarbij de URI wordt doorgegeven als een tekenreeks in de eigenschap indexJson. Genereer eerst de standaardindex zodat u weet welke velden u moet opgeven en volg vervolgens met aangepaste eigenschappen als u bijvoorbeeld specifieke analysefuncties nodig hebt.
Stap 8: Een query uitvoeren op de index
Plak de volgende code in de zevende cel en voer deze uit. Er zijn geen wijzigingen vereist, behalve dat u mogelijk de syntaxis wilt variëren of meer voorbeelden wilt proberen om uw inhoud verder te verkennen:
Er is geen transformator of module die query's uitgeeft. Deze cel is een eenvoudige aanroep van de REST API voor zoekdocumenten.
In dit specifieke voorbeeld wordt gezocht naar het woord 'deur' ("search": "door"). Het retourneert ook een 'telling' van het aantal overeenkomende documenten en selecteert alleen de inhoud van de velden Beschrijving en Vertalingen voor de resultaten. Als u de volledige lijst met velden wilt zien, verwijdert u de parameter 'select'.
import requests
url = "https://{}.search.windows.net/indexes/{}/docs/search?api-version=2020-06-30".format(search_service, search_index)
requests.post(url, json={"search": "door", "count": "true", "select": "Description, Translations"}, headers={"api-key": search_key}).json()
In de volgende schermopname ziet u de celuitvoer voor een voorbeeldscript.
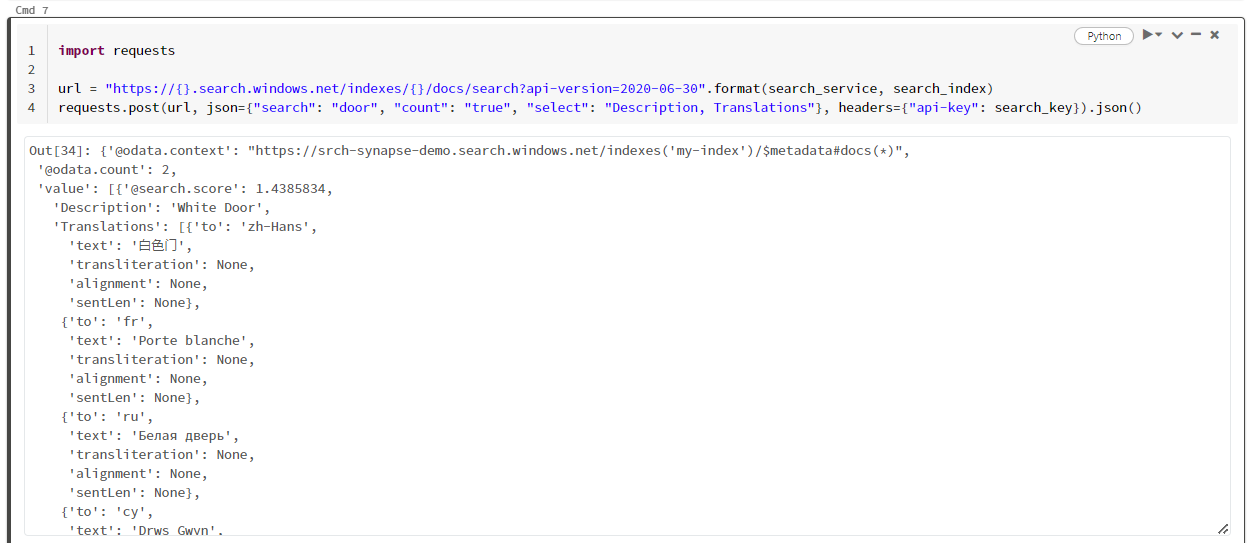
Resources opschonen
Wanneer u in uw eigen abonnement werkt, is het een goed idee om aan het einde van een project te bepalen of u de gemaakte resources nog steeds nodig hebt en of u deze moet verwijderen. Resources die actief blijven, kunnen u geld kosten. U kunt resources afzonderlijk verwijderen, maar u kunt ook de resourcegroep verwijderen als u de volledige resourceset wilt verwijderen.
U kunt resources vinden en beheren in de portal via de koppeling Alle resources of Resourcegroepen in het navigatiedeelvenster aan de linkerkant.
Volgende stappen
In deze zelfstudie hebt u geleerd over de AzureSearchWriter-transformator in SynapseML. Dit is een nieuwe manier om zoekindexen te maken en te laden in Azure AI Search. De transformator gebruikt gestructureerde JSON als invoer. De FormOntologyLearner kan de benodigde structuur bieden voor uitvoer die wordt geproduceerd door de Document Intelligence-transformatoren in SynapseML.
Als volgende stap bekijkt u de andere SynapseML-zelfstudies die getransformeerde inhoud produceren die u mogelijk wilt verkennen via Azure AI Search: