Richtlijnen en patronen voor migratie van Azure Data Lake Storage
U kunt uw gegevens, workloads en toepassingen migreren van Azure Data Lake Storage Gen1 naar Azure Data Lake Storage Gen2. In dit artikel wordt de aanbevolen migratiebenadering uitgelegd en worden de verschillende migratiepatronen behandeld en wanneer u deze kunt gebruiken. Voor eenvoudiger lezen gebruikt dit artikel de term Gen1 om te verwijzen naar Azure Data Lake Storage Gen1 en de term Gen2 om te verwijzen naar Azure Data Lake Storage Gen2.
Notitie
Azure Data Lake Storage Gen1 is nu buiten gebruik gesteld. Bekijk hier de aankondiging van de buitengebruikstelling. Data Lake Storage Gen1-resources zijn niet meer toegankelijk. Als u speciale hulp nodig hebt, neem dan contact met ons op.
Azure Data Lake Storage Gen2 is gebouwd op Azure Blob Storage en biedt een reeks mogelijkheden die zijn toegewezen aan big data-analyses. Data Lake Storage Gen2 combineert functies van Azure Data Lake Storage Gen1, zoals semantiek van bestandssysteem, map- en bestandsniveaubeveiliging en schaal met goedkope, gelaagde opslag, mogelijkheden voor hoge beschikbaarheid/herstel na noodgevallen vanuit Azure Blob Storage.
Notitie
Omdat Gen1 en Gen2 verschillende services zijn, is er geen in-place upgrade-ervaring. Zie Azure Data Lake Storage migreren van Gen1 naar Gen2 met behulp van Azure Portal om de migratie naar Gen2 te vereenvoudigen met behulp van Azure Portal.
Aanbevolen benadering
Als u wilt migreren van Gen1 naar Gen2, raden we de volgende methode aan.
Stap 1: Gereedheid beoordelen
Stap 2: De migratie voorbereiden
Stap 3: gegevens- en toepassingsworkloads migreren
Stap 4: Cutover van Gen1 naar Gen2
Stap 1: Gereedheid beoordelen
Meer informatie over het Data Lake Storage Gen2-aanbod, de voordelen, kosten en algemene architectuur.
Vergelijk de mogelijkheden van Gen1 met die van Gen2.
Bekijk een lijst met bekende problemen om eventuele hiaten in de functionaliteit te beoordelen.
Gen2 biedt ondersteuning voor Blob Storage-functies, zoals diagnostische logboekregistratie, toegangslagen en levenscyclusbeheerbeleid voor Blob Storage. Als u een van deze functies interessant vindt, bekijkt u het huidige ondersteuningsniveau.
Bekijk de huidige status van azure-ecosysteemondersteuning om ervoor te zorgen dat Gen2 alle services ondersteunt waarvan uw oplossingen afhankelijk zijn.
Stap 2: De migratie voorbereiden
Identificeer de gegevenssets die u gaat migreren.
Neem deze kans om gegevenssets op te schonen die u niet meer gebruikt. Neem deze tijd om logische groepen gegevens te identificeren die u in fasen kunt migreren, tenzij u van plan bent om al uw gegevens tegelijk te migreren.
Voer een verouderingsanalyse (of vergelijkbaar) uit op uw Gen1-account om te bepalen welke bestanden of mappen gedurende lange tijd in voorraad blijven of misschien verouderd zijn.
Bepaal de impact die een migratie op uw bedrijf heeft.
Denk bijvoorbeeld na of u downtime kunt veroorloven terwijl de migratie plaatsvindt. Deze overwegingen kunnen u helpen bij het identificeren van een geschikt migratiepatroon en het kiezen van de meest geschikte hulpprogramma's.
Maak een migratieplan.
We raden deze migratiepatronen aan. U kunt een van deze patronen kiezen, deze combineren of zelf een aangepast patroon ontwerpen.
Stap 3: Gegevens, workloads en toepassingen migreren
Gegevens, workloads en toepassingen migreren met behulp van het gewenste patroon. U wordt aangeraden scenario's incrementeel te valideren.
Maak een opslagaccount en schakel de hiërarchische naamruimtefunctie in.
Uw gegevens migreren.
Configureer services in uw workloads om naar uw Gen2-eindpunt te verwijzen.
Voor HDInsight-clusters kunt u configuratie-instellingen voor opslagaccounts toevoegen aan het bestand %HADOOP_HOME%/conf/core-site.xml. Als u van plan bent om externe Hive-tabellen van Gen1 naar Gen2 te migreren, moet u ook opslagaccountinstellingen toevoegen aan het bestand %HIVE_CONF_DIR%/hive-site.xml.
U kunt de instellingen voor elk bestand wijzigen met behulp van Apache Ambari. Zie Hadoop Azure Support: ABFS — Azure Data Lake Storage Gen2 voor informatie over de instellingen van het opslagaccount. In dit voorbeeld wordt de
fs.azure.account.keyinstelling gebruikt om autorisatie van gedeelde sleutels in te schakelen:<property> <name>fs.azure.account.key.abfswales1.dfs.core.windows.net</name> <value>your-key-goes-here</value> </property>Zie Azure-services die ondersteuning bieden voor Azure Data Lake Storage Gen2 voor koppelingen naar artikelen over het configureren van HDInsight, Azure Databricks en andere Azure-services voor het gebruik van Gen2.
Toepassingen bijwerken voor het gebruik van Gen2-API's. Zie de volgende handleidingen:
Werk scripts bij voor het gebruik van Data Lake Storage Gen2 PowerShell-cmdlets en Azure CLI-opdrachten.
Zoek naar URI-verwijzingen die de tekenreeks
adl://bevatten in codebestanden of in Databricks-notebooks, Apache Hive HQL-bestanden of een ander bestand dat wordt gebruikt als onderdeel van uw workloads. Vervang deze verwijzingen door de gen2-geformatteerde URI van uw nieuwe opslagaccount. Bijvoorbeeld: de Gen1-URI:adl://mydatalakestore.azuredatalakestore.net/mydirectory/myfilekan wordenabfss://myfilesystem@mydatalakestore.dfs.core.windows.net/mydirectory/myfile.Configureer de beveiliging voor uw account om Azure-rollen, beveiliging op bestand- en mapniveau en Azure Storage-firewalls en virtuele netwerken op te nemen.
Stap 4: Cutover van Gen1 naar Gen2
Nadat u zeker weet dat uw toepassingen en workloads stabiel zijn op Gen2, kunt u Gen2 gaan gebruiken om te voldoen aan uw bedrijfsscenario's. Schakel alle resterende pijplijnen uit die worden uitgevoerd op Gen1 en buiten gebruik stellen van uw Gen1-account.
Gen1 versus Gen2-mogelijkheden
In deze tabel worden de mogelijkheden van Gen1 vergeleken met die van Gen2.
Gen1 tot Gen2-patronen
Kies een migratiepatroon en pas dat patroon vervolgens zo nodig aan.
| Migratiepatroon | DETAILS |
|---|---|
| Lift and Shift | Het eenvoudigste patroon. Ideaal als uw gegevenspijplijnen downtime kunnen bieden. |
| Incrementele kopie | Vergelijkbaar met lift-and-shift, maar met minder downtime. Ideaal voor grote hoeveelheden gegevens die langer duren om te kopiëren. |
| Dubbele pijplijn | Ideaal voor pijplijnen die geen downtime kunnen betalen. |
| Bidirectionele synchronisatie | Vergelijkbaar met dubbele pijplijn, maar met een meer gefaseerde benadering die geschikt is voor complexere pijplijnen. |
Laten we elk patroon eens nader bekijken.
Lift-and-shift-patroon
Dit is het eenvoudigste patroon.
Stop alle schrijfbewerkingen naar Gen1.
Gegevens verplaatsen van Gen1 naar Gen2. We raden Azure Data Factory aan of met behulp van Azure Portal. ACL's kopiëren met de gegevens.
Puntopnamebewerkingen en werkbelastingen naar Gen2.
Buiten bedrijf stellen Gen1.
Bekijk onze voorbeeldcode voor het lift- en shift-patroon in ons lift- en shift-migratievoorbeeld.
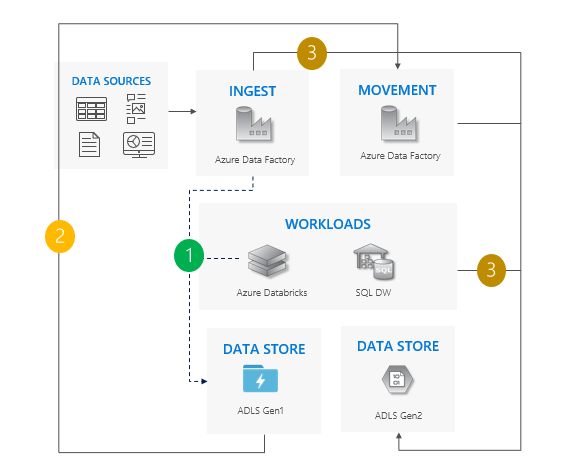
Overwegingen voor het gebruik van het lift- en shift-patroon
Cutover van Gen1 naar Gen2 voor alle workloads tegelijk.
Verwacht downtime tijdens de migratie en de cutover-periode.
Ideaal voor pijplijnen die downtime kunnen bieden en alle apps tegelijk kunnen worden bijgewerkt.
Tip
Overweeg om azure Portal te gebruiken om downtime te verkorten en het aantal stappen te verminderen dat u nodig hebt om de migratie te voltooien.
Incrementeel kopieerpatroon
Begin met het verplaatsen van gegevens van Gen1 naar Gen2. We raden Azure Data Factory aan. ACL's kopiëren met de gegevens.
Incrementeel nieuwe gegevens uit Gen1 kopiëren.
Nadat alle gegevens zijn gekopieerd, stopt u alle schrijfbewerkingen naar Gen1 en wijst u werkbelastingen naar Gen2 aan.
Buiten bedrijf stellen Gen1.
Bekijk onze voorbeeldcode voor het incrementele kopieerpatroon in ons voorbeeld van incrementele kopieermigratie.
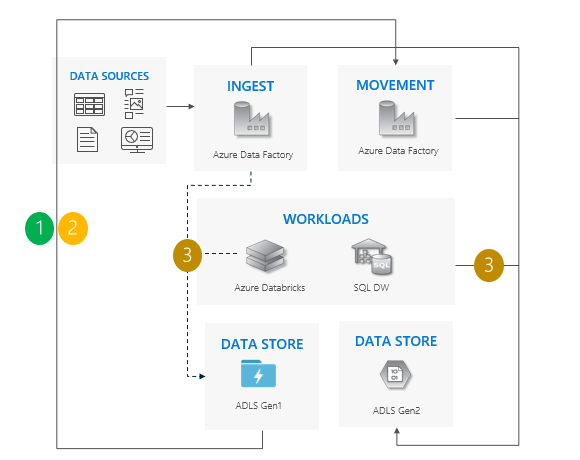
Overwegingen voor het gebruik van het incrementele kopieerpatroon
Cutover van Gen1 naar Gen2 voor alle workloads tegelijk.
Verwacht alleen downtime tijdens de cutover-periode.
Ideaal voor pijplijnen waarbij alle apps tegelijk zijn bijgewerkt, maar het kopiëren van gegevens vereist meer tijd.
Patroon voor dubbele pijplijn
Gegevens verplaatsen van Gen1 naar Gen2. We raden Azure Data Factory aan. ACL's kopiëren met de gegevens.
Nieuwe gegevens opnemen in zowel Gen1 als Gen2.
Werkbelastingen verwijzen naar Gen2.
Stop alle schrijfbewerkingen naar Gen1 en schakel vervolgens Gen1 uit bedrijf.
Bekijk onze voorbeeldcode voor het dubbele pijplijnpatroon in ons voorbeeld van een dual-pijplijnmigratie.
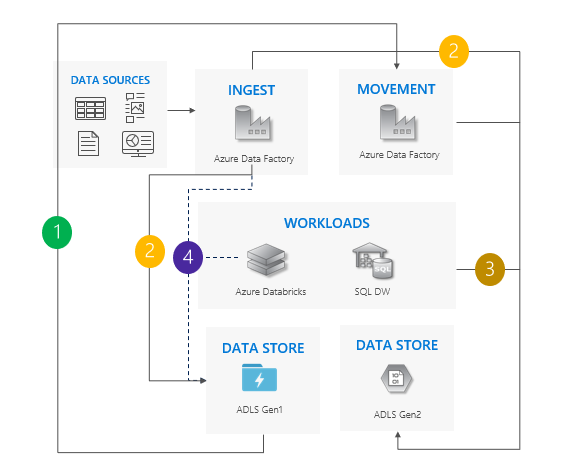
Overwegingen voor het gebruik van het patroon voor dubbele pijplijnen
Gen1- en Gen2-pijplijnen worden naast elkaar uitgevoerd.
Ondersteunt geen downtime.
Ideaal in situaties waarin uw workloads en toepassingen zich geen downtime kunnen veroorloven en u kunt deze opnemen in beide opslagaccounts.
Bidirectioneel synchronisatiepatroon
Stel bidirectionele replicatie tussen Gen1 en Gen2 in. We raden WanDisco aan. Het biedt een reparatiefunctie voor bestaande gegevens.
Wanneer alle verplaatsingen zijn voltooid, stopt u alle schrijfbewerkingen naar Gen1 en schakelt u bidirectionele replicatie uit.
Buiten bedrijf stellen Gen1.
Bekijk onze voorbeeldcode voor het synchronisatiepatroon in twee richtingen in ons voorbeeld van de migratie van bidirectionele synchronisatie.
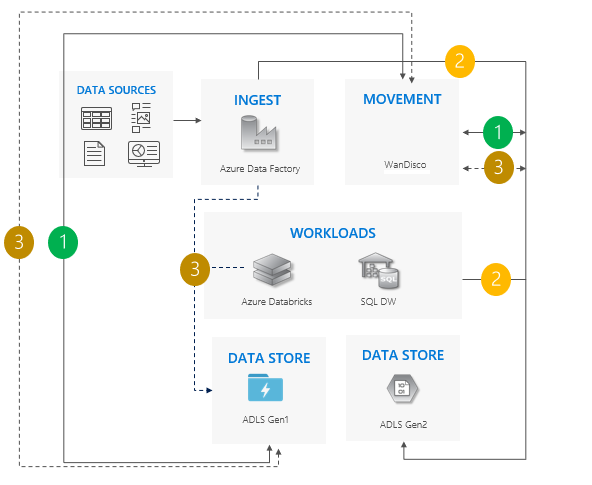
Overwegingen voor het gebruik van het bidirectionele synchronisatiepatroon
Ideaal voor complexe scenario's die betrekking hebben op een groot aantal pijplijnen en afhankelijkheden waarbij een gefaseerde benadering logischer kan zijn.
Migratie is hoog, maar biedt naast elkaar ondersteuning voor Gen1 en Gen2.
Volgende stappen
- Meer informatie over de verschillende onderdelen van het instellen van beveiliging voor een opslagaccount. Zie de Beveiligingshandleiding voor Azure Storage voor meer informatie.
- Optimaliseer de prestaties voor uw Data Lake Store. Zie Azure Data Lake Storage Gen2 optimaliseren voor prestaties
- Bekijk de aanbevolen procedures voor het beheren van uw Data Lake Store. Zie aanbevolen procedures voor het gebruik van Azure Data Lake Storage Gen2