Een gestructureerd of vrij documentverwerkingsmodel trainen in Microsoft Syntex
Volg de instructies in Een model maken in Syntex om een gestructureerd of vrij documentverwerkingsmodel te maken in een inhoudscentrum. Of volg de instructies in Een model maken op een lokale SharePoint-site om het model op een lokale site te maken. Gebruik vervolgens dit artikel om uw model te trainen.

Voer de volgende stappen uit om een gestructureerd of vrij documentverwerkingsmodel te trainen:
- Stap 1: documenten toevoegen en analyseren
- Stap 2: Velden en tabellen taggen
- Stap 3: uw model trainen en publiceren
- Stap 4: uw model gebruiken
Stap 1: documenten toevoegen en analyseren
Nadat u uw gestructureerde of vrije documentverwerkingsmodel hebt gemaakt, wordt de pagina Gegevens kiezen om te extraheren geopend. Hier geeft u alle gegevens weer die het AI-model uit uw documenten wilt ophalen, zoals Naam, Adres of Bedrag.
Opmerking
Wanneer u zoekt naar voorbeeldbestanden die u wilt gebruiken, raadpleegt u de documentvereisten en optimalisatietips voor het invoermodel van het documentverwerkingsmodel.
Je definieert eerst de velden en tabellen die je het model wilt leren uitpakken op de pagina Kies informatie om te extraheren. Zie Te extraheren velden en tabellen definiëren voor gedetailleerde stappen.
Je kunt zoveel verzamelingen documentindelingen maken als je wilt dat je model verwerkt. Zie Documenten groeperen op verzamelingenvoor gedetailleerde stappen.
Nadat u uw verzamelingen hebt gemaakt en hiervoor ten minste vijf voorbeeldbestanden hebt toegevoegd, onderzoekt AI Builder op Syntex de geüploade documenten om de velden en tabellen te detecteren. Dit proces duurt meestal enkele seconden. Wanneer de analyse is voltooid, kun je doorgaan met het taggen van de documenten.
Stap 2: Velden en tabellen taggen
Je moet de documenten taggen om het model te leren begrijpen welke velden en tabelgegevens je wilt extraheren. Zie Documenten taggen voor gedetailleerde stappen.
Stap 3: uw model trainen en publiceren
Nadat je het model hebt gemaakt en getraind, kun je het publiceren en gebruiken in SharePoint. Als u het model wilt publiceren, selecteert u Publiceren. Zie Uw documentverwerkingsmodel trainen en publiceren voor gedetailleerde stappen.
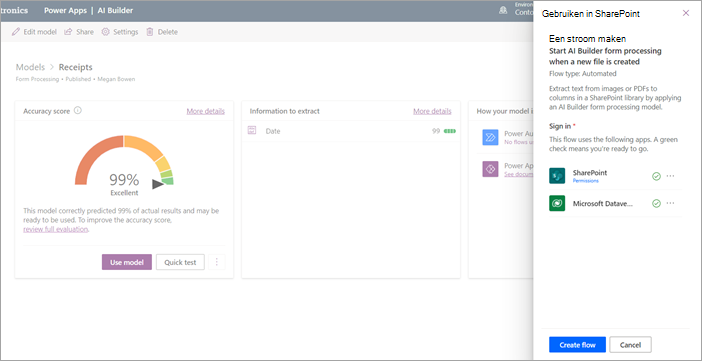
Nadat het model is gepubliceerd, gaat u naar de startpagina van het model. Vervolgens hebt u de mogelijkheid om het model toe te passen op een documentbibliotheek.
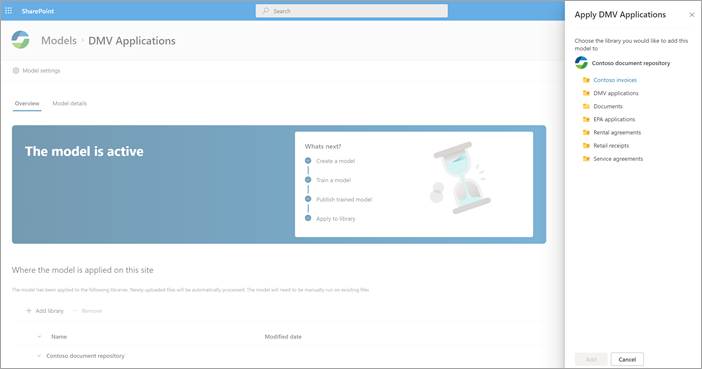
Stap 4: uw model gebruiken
Je ziet dat de velden die je hebt geselecteerd nu als kolommen worden weergegeven in de documentbibliotheekmodelweergave.
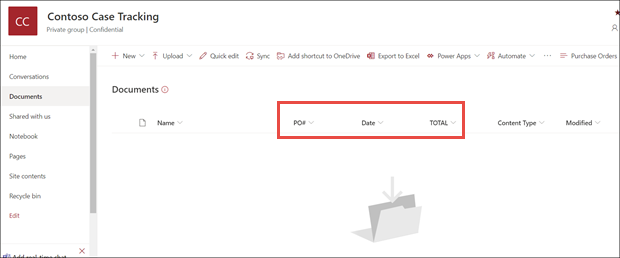
Zoals je ziet, geeft de informatiekoppeling naast Documenten aan dat een formulierverwerkingsmodel is toegepast op deze documentbibliotheek.
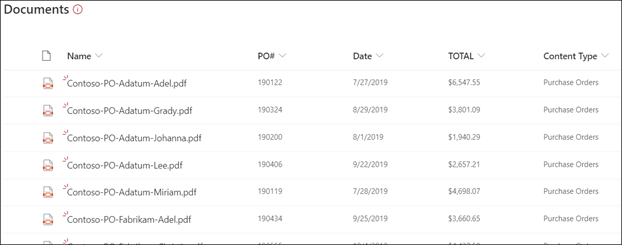
Upload bestanden naar je documentbibliotheek. Alle bestanden die door het model zijn geïdentificeerd als het juiste inhoudstype, worden weergegeven in de lijst met de bestanden in de weergave en de geëxtraheerde gegevens worden weergegeven in de kolommen.
Opmerking
Als een gestructureerd of vrij documentverwerkingsmodel en een ongestructureerd documentverwerkingsmodel zijn toegepast op dezelfde bibliotheek, wordt het bestand geclassificeerd met behulp van het niet-gestructureerde documentverwerkingsmodel en eventuele getrainde extractors voor dat model. Als er lege kolommen zijn die overeenkomen met het documentverwerkingsmodel, worden de kolommen ingevuld met deze geëxtraheerde waarden.
Veld Classificatiedatum
Wanneer een aangepast model wordt toegepast op een documentbibliotheek, wordt het veld Classificatiedatum opgenomen in het bibliotheekschema. Dit veld is standaard leeg. Wanneer documenten echter worden verwerkt en geclassificeerd door een model, wordt dit veld bijgewerkt met een datum-tijdstempel van voltooiing.
Wanneer een model is gestempeld met de classificatiedatum, kunt u de e-mail verzenden nadat Syntex een bestandsstroom verwerkt , gebruiken om gebruikers te informeren dat een nieuw bestand is verwerkt en geclassificeerd door een model in de SharePoint-documentbibliotheek.
De stroom uitvoeren:
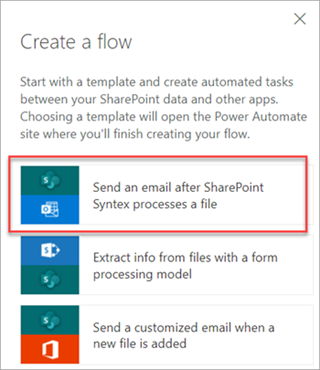
Selecteer een bestand en selecteer vervolgensPower Automate>Een stroom makenintegreren>.
Selecteer in het deelvenster Een stroom makende optie Een e-mail verzenden nadat Syntex een bestand heeft verwerkt.
Stromen gebruiken om informatie te extraheren
Belangrijk
De informatie in deze sectie is niet van toepassing op de nieuwste versie van Syntex. Het blijft alleen als referentie over voor de formulierverwerkingsmodellen die in eerdere releases zijn gemaakt. In de nieuwste versie hoeft u de stromen niet meer te configureren om bestaande bestanden te verwerken.
Er zijn twee stromen beschikbaar voor het verwerken van een geselecteerd bestand of een batch bestanden in een bibliotheek waar een gestructureerd documentverwerkingsmodel of een vrije vorm is toegepast.
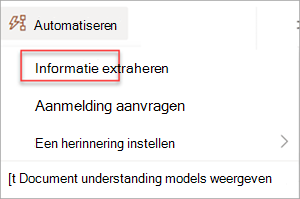
Extraheren van informatie uit een afbeelding of PDF-bestand met een documentverwerkingsmodel : gebruik deze optie om tekst uit een geselecteerde afbeelding of PDF-bestand te extraheren door een documentverwerkingsmodel uit te voeren. Ondersteunt één geselecteerd bestand tegelijk en ondersteunt alleen PDF-bestanden en afbeeldingsbestanden (.png, .jpg en .jpeg). Als u de stroom wilt uitvoeren, selecteert u een bestand en selecteert u vervolgens Gegevens uitpakken automatiseren>.
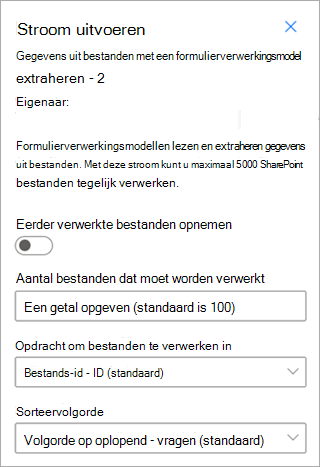
Gegevens extraheren uit bestanden met een documentverwerkingsmodel : gebruik dit met documentverwerkingsmodellen om informatie uit een batch bestanden te lezen en te extraheren. Verwerkt maximaal 5000 SharePoint-bestanden tegelijk. Wanneer u deze stroom uitvoert, kunt u bepaalde parameters instellen. U kunt:
- Kies of u eerder verwerkte bestanden wilt opnemen (de standaardinstelling is niet dat eerder verwerkte bestanden worden opgenomen).
- Selecteer het aantal bestanden dat moet worden verwerkt (de standaardwaarde is 100 bestanden).
- Geef de volgorde op waarin de bestanden moeten worden verwerkt (de keuzen zijn op bestands-id, bestandsnaam, tijdstip waarop het bestand is gemaakt of het tijdstip waarop het laatst is gewijzigd).
- Geef op hoe u de volgorde wilt sorteren (oplopende of aflopende volgorde).
Opmerking
De stroom Gegevens extraheren uit een afbeelding of PDF-bestand met een documentverwerkingsmodel is automatisch beschikbaar voor een bibliotheek waarvoor een documentverwerkingsmodel is gekoppeld. De stroom Gegevens extraheren uit bestanden met een documentverwerkingsmodel is een sjabloon die indien nodig aan de bibliotheek moet worden toegevoegd.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor