Genormaliseerde RU/s bewaken voor een Azure Cosmos DB-container of een account
VAN TOEPASSING OP: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Tafel
Tafel
Azure Monitor voor Azure Cosmos DB biedt een metrische weergave voor het bewaken van uw account en het maken van dashboards. De metrische gegevens van Azure Cosmos DB worden standaard verzameld. Voor deze functie hoeft u niets expliciet in of te configureren.
Definitie van metrische gegevens
De metrische gegevens voor genormaliseerd RU-verbruik zijn een metrische waarde tussen 0% en 100% die wordt gebruikt om het gebruik van ingerichte doorvoer in een database of container te meten. De metrische waarde wordt verzonden met intervallen van 1 minuut en wordt gedefinieerd als het maximale RU/s-gebruik voor alle partitiesleutelbereiken in het tijdsinterval. Elk partitiesleutelbereik wordt toegewezen aan één fysieke partitie en wordt toegewezen om gegevens te bewaren voor een bereik van mogelijke hash-waarden. Over het algemeen geldt: hoe hoger het percentage genormaliseerde RU/s, hoe meer u gebruik hebt gemaakt van ingerichte doorvoer. De metrische waarde kan ook worden gebruikt om het gebruik van afzonderlijke partitiesleutelbereiken in een database of container weer te geven.
Stel dat u een container hebt waarin u de maximale doorvoer voor automatische schaalaanpassing van 20.000 RU/s instelt (schaalt tussen 2000 - 20.000 RU/s) en u twee partitiesleutelbereiken (fysieke partities) P1 en P2 hebt. Omdat Azure Cosmos DB de ingerichte doorvoer gelijkmatig over alle partitiesleutelbereiken distribueert, kunnen P1 en P2 schalen tussen 1000 en 10.000 RU/s. Stel dat P1 in een interval van 1 minuut in een bepaalde seconde 6000 aanvraageenheden verbruikt en P2 8000 aanvraageenheden heeft verbruikt. Het genormaliseerde RU-verbruik van P1 is 60% en 80% voor P2. Het totale genormaliseerde RU-verbruik van de hele container is MAX(60%, 80%) = 80%.
Als u geïnteresseerd bent in het verbruik van de aanvraageenheid met een interval per seconde, samen met het bewerkingstype, kunt u de diagnostische logboeken voor opt-in-functies gebruiken en de tabel PartitionKeyRUConsumption opvragen. Als u een algemeen overzicht wilt krijgen van de bewerkingen en statuscode die uw toepassing uitvoert op de Azure Cosmos DB-resource, kunt u de ingebouwde metrische gegevens van Azure Monitor Total Requests (API for NoSQL), Mongo-aanvragen, Gremlin-aanvragen of Cassandra-aanvragen gebruiken. Later kunt u filteren op deze aanvragen door de 429-statuscode en deze splitsen op bewerkingstype.
Wat u kunt verwachten en doen wanneer genormaliseerde RU/s hoger is
Wanneer het genormaliseerde RU-verbruik 100% bereikt voor het opgegeven bereik van de partitiesleutel en als een client nog steeds aanvragen indient in dat tijdvenster van 1 seconde naar dat specifieke partitiesleutelbereik, ontvangt deze een frequentielimietfout (429).
Dit betekent niet noodzakelijkerwijs dat er een probleem is met uw resource. Standaard worden de SDK's en hulpprogramma's voor gegevensimport van de Azure Cosmos DB-client, zoals Azure Data Factory en de bulkexecutorbibliotheek, automatisch opnieuw geprobeerd op 429s. Ze proberen het meestal maximaal 9 keer. Als gevolg hiervan kunnen er 429s in de metrische gegevens worden weergegeven, maar deze fouten zijn mogelijk niet eens geretourneerd naar uw toepassing.
Voor een productieworkload geldt in het algemeen dat als 1-5% van de aanvragen 429-fouten oplevert en uw end-to-end-latentie acceptabel is, dit een goed teken is dat de RU's/s volledig worden gebruikt. In dit geval betekent het genormaliseerde ru-verbruik dat 100% bereikt, alleen dat in een bepaalde seconde ten minste één partitiesleutelbereik alle ingerichte doorvoer heeft gebruikt. Dit is acceptabel omdat de totale frequentie van 429-fouten nog steeds laag is. Er is geen verdere actie vereist.
Als u wilt bepalen welk percentage van uw aanvragen voor uw database of container heeft geresulteerd in 429's, gaat u vanaf de blade van uw Azure Cosmos DB-account naar Inzichtenaanvragen>>voor totaal aantal aanvragen per statuscode. Filteren op een specifieke database en container. Voor API voor Gremlin gebruikt u de metrische gegevens voor Gremlin-aanvragen .
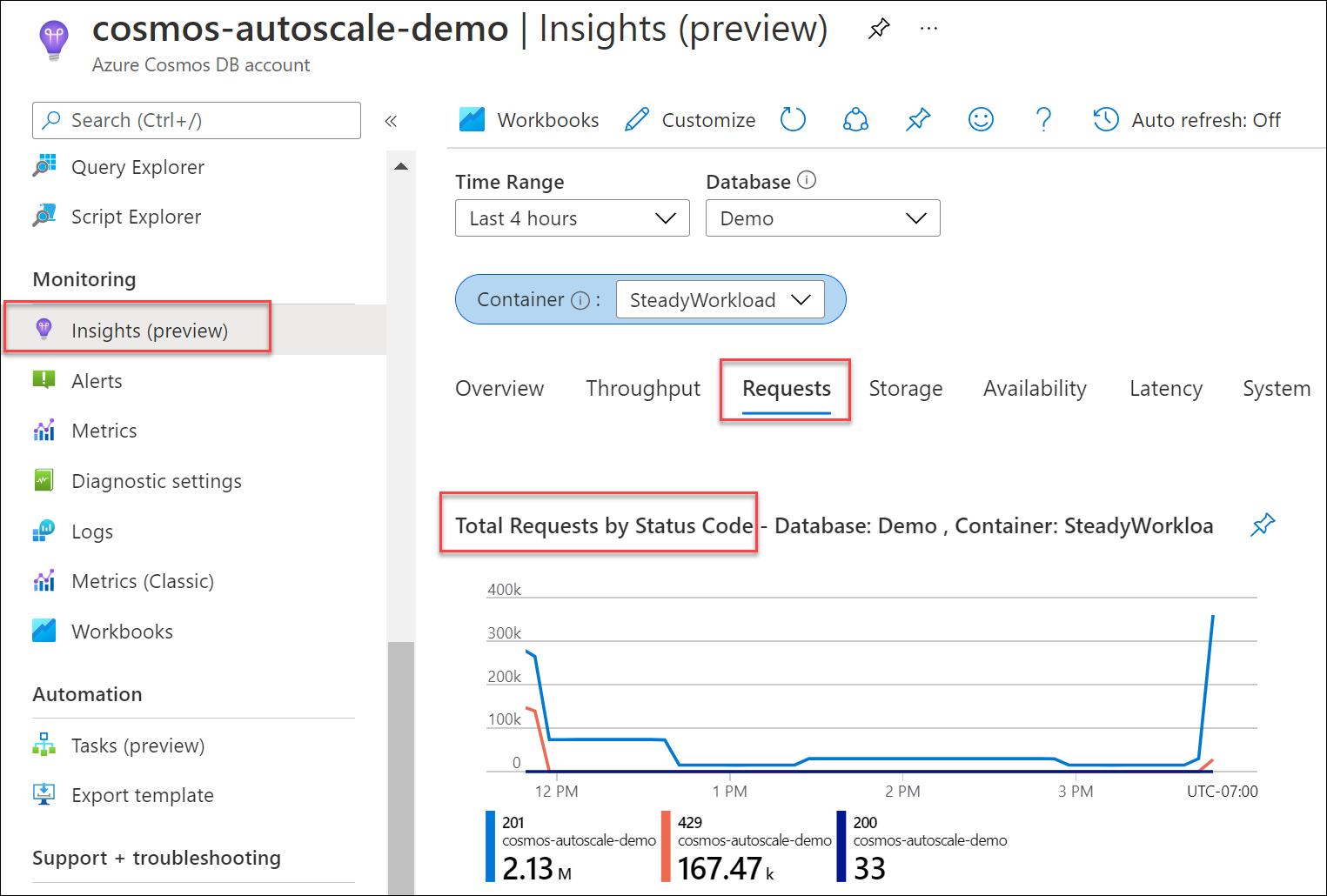
Als de metrische waarde voor genormaliseerd RU-verbruik consistent 100% is voor meerdere partitiesleutelbereiken en de snelheid van 429's groter is dan 5%, is het raadzaam om de doorvoer te verhogen. U kunt erachter komen welke bewerkingen zwaar zijn en wat hun piekgebruik is met behulp van de metrische gegevens van Azure Monitor en diagnostische logboeken van Azure Monitor. Volg de best practices voor het schalen van ingerichte doorvoer (RU/s).
Het is niet altijd het geval dat u een 429 frequentiebeperkingsfout ziet, alleen omdat de genormaliseerde RU 100% heeft bereikt. Dat komt doordat de genormaliseerde RU één waarde is die het maximale gebruik vertegenwoordigt voor alle partitiesleutelbereiken. Het ene partitiesleutelbereik is mogelijk bezet, maar de andere partitiesleutelbereiken kunnen aanvragen zonder problemen verwerken. Een enkele bewerking, zoals een opgeslagen procedure die alle RU/s in een partitiesleutelbereik verbruikt, leidt bijvoorbeeld tot een korte piek in de genormaliseerde metrische RU-verbruik. In dergelijke gevallen zijn er geen onmiddellijke frequentiebeperkingsfouten als de totale aanvraagsnelheid laag is of aanvragen worden verzonden naar andere partities op verschillende partitiesleutelbereiken.
Meer informatie over het interpreteren en opsporen van snelheidsbeperkende 429-fouten.
Controleren op dynamische partities
De metrische gegevens voor genormaliseerd RU-verbruik kunnen worden gebruikt om te controleren of uw workload een dynamische partitie heeft. Er ontstaat een dynamische partitie wanneer een of enkele logische partitiesleutels een onevenredige hoeveelheid ru/s verbruiken vanwege een hoger aanvraagvolume. Dit kan worden veroorzaakt door een partitiesleutelontwerp dat geen aanvragen gelijkmatig distribueert. Het resulteert in veel aanvragen die worden omgeleid naar een kleine subset van logische partities (wat partitiesleutelbereiken impliceert) die 'dynamisch' worden. Omdat alle gegevens voor een logische partitie zich op één partitiesleutelbereik bevinden en het totale aantal RU/s gelijkmatig wordt verdeeld over alle partitiesleutelbereiken, kan een dynamische partitie leiden tot 429's en inefficiënt gebruik van doorvoer.
Bepalen of er een dynamische partitie is
Als u wilt controleren of er een dynamische partitie is, gaat u naar Genormaliseerd RU-verbruik voor inzichten>>(%) op PartitionKeyRangeID. Filteren op een specifieke database en container.
Elke PartitionKeyRangeId wordt toegewezen aan één fysieke partitie. Als er één PartitionKeyRangeId is met een aanzienlijk hoger genormaliseerd RU-verbruik dan andere (een is bijvoorbeeld consistent op 100%, maar andere op 30% of minder), kan dit een teken zijn van een dynamische partitie.
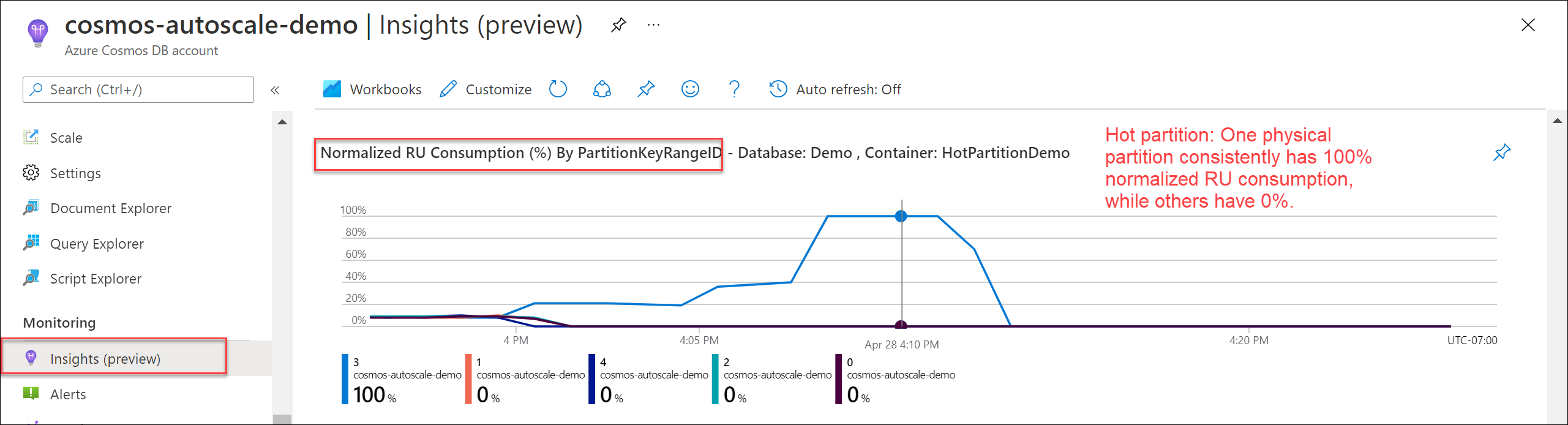
Als u de logische partities wilt identificeren die de meeste RU/s gebruiken, evenals aanbevolen oplossingen, raadpleegt u het artikel Azure Cosmos DB-aanvraagsnelheid te groot (429) uitzonderingen vaststellen en oplossen.
Genormaliseerd RU-verbruik en automatische schaalaanpassing
De metrische waarde voor genormaliseerd RU-verbruik wordt weergegeven als 100% als ten minste één partitiesleutelbereik alle toegewezen RU/s gebruikt in een seconde in het tijdsinterval. Een veelvoorkomende vraag die zich voordoet, is, waarom is genormaliseerd RU-verbruik met 100%, maar Azure Cosmos DB heeft de RU/s niet geschaald naar de maximale doorvoer met automatische schaalaanpassing?
Notitie
De onderstaande informatie beschrijft de huidige implementatie van automatische schaalaanpassing en kan in de toekomst worden gewijzigd.
Wanneer u automatische schaalaanpassing gebruikt, schaalt Azure Cosmos DB de RU/s alleen naar de maximale doorvoer wanneer het genormaliseerde RU-verbruik 100% is voor een langdurige, continue periode in een interval van 5 seconden. Dit wordt gedaan om ervoor te zorgen dat de schaallogica kostenvriendelijk is voor de gebruiker, omdat het ervoor zorgt dat enkele tijdelijke pieken niet leiden tot onnodig schalen en hogere kosten. Wanneer er momentele pieken zijn, wordt het systeem meestal omhoog geschaald naar een waarde die hoger is dan de eerder geschaalde RU/s, maar lager is dan de maximale RU/s.
Stel dat u een container hebt met maximale doorvoer voor automatische schaalaanpassing van 20.000 RU/s (schaalt tussen 2000 - 20.000 RU/s) en 2 partitiesleutelbereiken. Elk partitiesleutelbereik kan worden geschaald tussen 1000 - 10.000 RU/s. Omdat met automatische schaalaanpassing alle vereiste resources vooraf worden uitgevoerd, kunt u op elk gewenst moment maximaal 20.000 RU/s gebruiken. Stel dat u een onregelmatige piek in het verkeer hebt, waarbij voor één seconde het gebruik van een van de partitiesleutelbereiken 10.000 RU/s is. Voor volgende seconden gaat het gebruik terug naar 1000 RU/s. Omdat metrische gegevens over genormaliseerd RU-verbruik het hoogste gebruik in de periode voor alle partities weergeven, wordt 100% weergegeven. Omdat het gebruik echter slechts 100% voor 1 seconde was, wordt automatisch schalen niet automatisch geschaald naar het maximum.
Als gevolg hiervan kon u, ook al schaalt automatisch schalen niet naar het maximum, nog steeds de totale BESCHIKBARE RU/s gebruiken. Als u uw RU/s-verbruik wilt controleren, kunt u de diagnostische logboeken voor opt-infuncties gebruiken om een query uit te voeren op het totale RU/s-verbruik op een niveau per seconde voor alle partitiesleutelbereiken.
CDBPartitionKeyRUConsumption
| where TimeGenerated >= (todatetime('2022-01-28T20:35:00Z')) and TimeGenerated <= todatetime('2022-01-28T20:40:00Z')
| where DatabaseName == "MyDatabase" and CollectionName == "MyContainer"
| summarize sum(RequestCharge) by bin(TimeGenerated, 1sec), PartitionKeyRangeId
| render timechart
Over het algemeen geldt dat voor een productieworkload met automatische schaalaanpassing, als u ziet tussen 1-5% van de aanvragen met 429's en uw end-to-endlatentie acceptabel is, is dit een goed teken dat de RU/s volledig worden gebruikt. Zelfs als het genormaliseerde RU-verbruik af en toe 100% bereikt en automatische schaalaanpassing niet omhoog schaalt naar de maximale RU/s, is dit ok omdat de totale snelheid van 429's laag is. Er is geen actie vereist.
Tip
Als u automatische schaalaanpassing gebruikt en merkt dat genormaliseerd RU-verbruik consistent 100% is en u consistent wordt geschaald naar de maximale RU/s, is dit een teken dat het gebruik van handmatige doorvoer rendabeler kan zijn. Als u wilt bepalen of automatische schaalaanpassing of handmatige doorvoer het meest geschikt is voor uw workload, raadpleegt u hoe u kunt kiezen tussen standaard (handmatig) en ingerichte doorvoer voor automatische schaalaanpassing. Azure Cosmos DB verzendt ook aanbevelingen voor Azure Advisor op basis van uw workloadpatronen om handmatige doorvoer of doorvoer voor automatische schaalaanpassing aan te bevelen.
De metrische gegevens over het genormaliseerde verbruik van aanvraageenheden weergeven
Meld u aan bij het Azure-portaal.
Selecteer Monitor in de linkernavigatiebalk en selecteer Metrische gegevens.
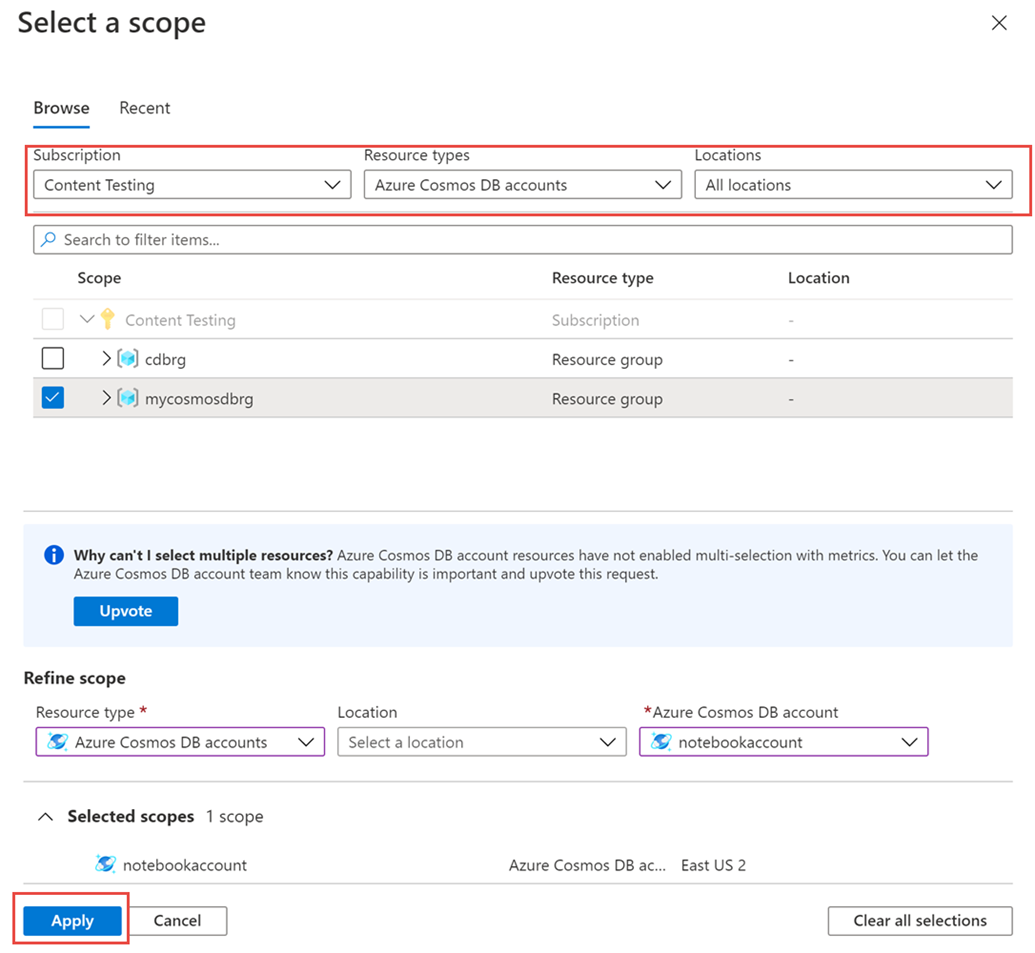
Selecteer een resource> in het deelvenster> Metrische gegevens het vereiste abonnement en de resourcegroep. Voor het resourcetype selecteert u Azure Cosmos DB-accounts, kiest u een van uw bestaande Azure Cosmos DB-accounts en selecteert u Toepassen.
Vervolgens kunt u een metrische waarde selecteren in de lijst met beschikbare metrische gegevens. U kunt metrische gegevens selecteren die specifiek zijn voor het aanvragen van eenheden, opslag, latentie, beschikbaarheid, Cassandra en andere. Zie het artikel Metrische gegevens per categorie voor meer informatie over alle beschikbare metrische gegevens in deze lijst. In dit voorbeeld selecteren we de metrische waarde genormaliseerd RU-verbruik en Max als de aggregatiewaarde.
Naast deze details kunt u ook het tijdsbereik en de tijdgranulariteit van de metrische gegevens selecteren. U kunt maximaal metrische gegevens bekijken voor de afgelopen 30 dagen. Nadat u het filter hebt toegepast, wordt een grafiek weergegeven op basis van uw filter.

Filters voor metrische gegevens over genormaliseerd RU-verbruik
U kunt ook metrische gegevens en de grafiek filteren die worden weergegeven door een specifieke CollectionName, DatabaseName, PartitionKeyRangeID en Region. Als u de metrische gegevens wilt filteren, selecteert u Filter toevoegen en kiest u de vereiste eigenschap, zoals CollectionName en de bijbehorende waarde waarin u geïnteresseerd bent. In de grafiek worden vervolgens de genormaliseerde metrische ru-verbruiksgegevens voor de container voor de geselecteerde periode weergegeven.
U kunt metrische gegevens groeperen met behulp van de optie Splitsen toepassen . Voor gedeelde doorvoerdatabases toont de genormaliseerde RU-metrische gegevens alleen gegevens in de granulariteit van de database. Er worden geen gegevens per verzameling weergegeven. Voor een gedeelde doorvoerdatabase ziet u dus geen gegevens wanneer u splitst op naam van de verzameling.
De metrische gegevens voor genormaliseerd verbruik van aanvraageenheden voor elke container worden weergegeven, zoals wordt weergegeven in de volgende afbeelding:

Volgende stappen
- Azure Cosmos DB-gegevens bewaken met behulp van diagnostische instellingen in Azure.
- Azure Cosmos DB-besturingsvlakbewerkingen controleren
- Diagnose en roblemen oplossen met te hoge aanvraagsnelheid (429) van Azure Cosmos DB