Aanbevolen procedures voor het schalen van ingerichte doorvoer (RU/'s)
VAN TOEPASSING OP: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Tafel
Tafel
In dit artikel worden aanbevolen procedures en strategieën beschreven voor het schalen van de doorvoer (RU/s) van uw database of container (verzameling, tabel of grafiek). De concepten zijn van toepassing wanneer u de ingerichte handmatige RU/s verhoogt of de maximale RU/s voor automatische schaalaanpassing van elke resource voor een van de Azure Cosmos DB-API's.
Vereisten
- Als u geen kennis hebt met partitioneren en schalen in Azure Cosmos DB, is het raadzaam eerst het artikel Partitioneren en horizontaal schalen in Azure Cosmos DB te lezen.
- Als u van plan bent om uw RU/s te schalen vanwege 429 uitzonderingen, raadpleegt u de richtlijnen in Azure Cosmos DB-aanvraagsnelheid te groot (429). Voordat u RU/s verhoogt, identificeert u de hoofdoorzaak van het probleem en of het verhogen van RU/s de juiste oplossing is.
Achtergrond bij het schalen van RU/s
Wanneer u een aanvraag verzendt om de RU/s van uw database of container te verhogen, afhankelijk van de aangevraagde RU/s en de huidige indeling van uw fysieke partitie, wordt de schaalbewerking onmiddellijk of asynchroon voltooid (meestal 4-6 uur).
- Direct omhoog schalen
- Wanneer uw aangevraagde RU/s kunnen worden ondersteund door de huidige indeling voor fysieke partities, hoeft Azure Cosmos DB geen nieuwe partities te splitsen of toe te voegen.
- Als gevolg hiervan wordt de bewerking onmiddellijk voltooid en zijn de RU/s beschikbaar voor gebruik.
- Asynchroon omhoog schalen
- Wanneer de aangevraagde RU/s hoger zijn dan wat kan worden ondersteund door de indeling van de fysieke partities, splitst Azure Cosmos DB bestaande fysieke partities. Dit gebeurt totdat de resource het minimale aantal partities heeft dat nodig is om de aangevraagde RU/s te ondersteunen.
- Als gevolg hiervan kan het enige tijd duren voordat de bewerking is voltooid, meestal 4-6 uur. Elke fysieke partitie kan maximaal 10.000 RU/s (van toepassing op alle API's) aan doorvoer en 50 GB aan opslag ondersteunen (geldt voor alle API's, met uitzondering van Cassandra, dat 30 GB opslagruimte heeft).
Notitie
Als u een handmatige failoverbewerking voor regio's uitvoert of een nieuwe regio toevoegt/verwijdert terwijl een asynchrone schaalbewerking wordt uitgevoerd, wordt de bewerking voor het omhoog schalen van doorvoer onderbroken. Deze wordt automatisch hervat wanneer de failover of het toevoegen/verwijderen van de regiobewerking is voltooid.
- Direct omlaag schalen
- Voor omlaag schalen hoeft Azure Cosmos DB geen nieuwe partities te splitsen of toe te voegen.
- Als gevolg hiervan wordt de bewerking onmiddellijk voltooid en zijn de RU/s beschikbaar voor gebruik,
- Het belangrijkste resultaat van deze bewerking is dat RU's per fysieke partitie worden verminderd.
RU/s omhoog schalen zonder de partitie-indeling te wijzigen
Stap 1: Het huidige aantal fysieke partities zoeken.
Navigeer naar Genormaliseerd RU-verbruik (%) door PartitionKeyRangeID voor inzichtendoorvoer>>. Tel het unieke aantal PartitionKeyRangeIds.

Notitie
In de grafiek worden maximaal 50 PartitionKeyRangeIds weergegeven. Als uw resource meer dan 50 heeft, kunt u de Azure Cosmos DB REST API gebruiken om het totale aantal partities te tellen.
Elke PartitionKeyRangeId wordt toegewezen aan één fysieke partitie en wordt toegewezen aan bewaringsgegevens voor een bereik van mogelijke hash-waarden.
Azure Cosmos DB distribueert uw gegevens over logische en fysieke partities op basis van uw partitiesleutel om horizontaal schalen mogelijk te maken. Wanneer gegevens worden geschreven, gebruikt Azure Cosmos DB de hash van de partitiesleutelwaarde om te bepalen op welke logische en fysieke partitie de gegevens zich bevinden.
Stap 2: de standaard maximale doorvoer berekenen
De hoogste RU/s waarnaar u kunt schalen zonder Azure Cosmos DB te activeren om partities te splitsen, is gelijk aan Current number of physical partitions * 10,000 RU/s. U kunt deze waarde ophalen van de Azure Cosmos DB-resourceprovider. Voer een GET-aanvraag uit op uw database- of containerdoorvoerobjecten en haal de instantMaximumThroughput eigenschap op. Deze waarde is ook beschikbaar op de pagina Schaal en instellingen van uw database of container in de portal.
Opmerking
Stel dat we een bestaande container hebben met vijf fysieke partities en 30.000 RU/s van handmatig ingerichte doorvoer. We kunnen de RU/s verhogen naar 5 * 10.000 RU/s = 50.000 RU/s direct. Als we een container met maximale RU/s voor automatische schaalaanpassing van 30.000 RU/s hadden (schaalt tussen 3000 - 30.000 RU/s), kunnen we onze maximale RU/s onmiddellijk verhogen naar 50.000 RU/s (schaalt tussen 5000 - 50.000 RU/s).
Tip
Als u RU/s omhoog schaalt om te reageren op te hoge aanvraagfrequentieuitzonderingen (429's), is het raadzaam eerst RU/s te verhogen naar de hoogste RU/s die worden ondersteund door uw huidige fysieke partitie-indeling en te beoordelen of de nieuwe RU/s voldoende zijn voordat u verder gaat.
Gelijkmatige gegevensdistributie garanderen tijdens asynchrone schaalaanpassing
Achtergrond
Wanneer u de RU/s hoger hebt dan het huidige aantal fysieke partities * 10.000 RU/s, splitst Azure Cosmos DB bestaande partities tot het nieuwe aantal partities = ROUNDUP(requested RU/s / 10,000 RU/s). Tijdens een splitsing worden bovenliggende partities gesplitst in twee onderliggende partities.
Stel dat we een container hebben met drie fysieke partities en 30.000 RU/s met handmatig ingerichte doorvoer. Als we de doorvoer hebben verhoogd naar 45.000 RU/s, splitst Azure Cosmos DB twee van de bestaande fysieke partities, zodat er in totaal = 5 fysieke partities zijn ROUNDUP(45,000 RU/s / 10,000 RU/s) .
Notitie
Toepassingen kunnen altijd gegevens opnemen of opvragen tijdens het splitsen. De AZURE Cosmos DB-client-SDK's en -service verwerken dit scenario automatisch en zorgen ervoor dat aanvragen worden gerouteerd naar de juiste fysieke partitie, zodat er geen extra gebruikersactie is vereist.
Als u een werkbelasting hebt die zeer gelijkmatig is verdeeld met betrekking tot opslag- en aanvraagvolume, meestal bereikt door partitionering door velden met hoge kardinaliteit, zoals /id, wordt aanbevolen wanneer u schaalt, stelt u RU/s zodanig in dat alle partities gelijkmatig worden gesplitst.
Laten we een voorbeeld nemen van een voorbeeld waarin we een bestaande container hebben met 2 fysieke partities, 20.000 RU/s en 80 GB aan gegevens.
Dankzij het kiezen van een goede partitiesleutel met een hoge kardinaliteit, worden de gegevens grofweg gelijkmatig verdeeld in beide fysieke partities. Aan elke fysieke partitie wordt ongeveer 50% van de keyspace toegewezen. Deze wordt gedefinieerd als het totale bereik van mogelijke hash-waarden.
Bovendien distribueert Azure Cosmos DB RU/s gelijkmatig over alle fysieke partities. Als gevolg hiervan heeft elke fysieke partitie 10.000 RU/s en 50% (40 GB) van de totale gegevens. In het volgende diagram ziet u de huidige status.

Stel dat we onze RU/s willen verhogen van 20.000 RU/s tot 30.000 RU/s.
Als we de RU/s simpelweg hebben verhoogd naar 30.000 RU/s, worden slechts één van de partities gesplitst. Na de splitsing hebben we het volgende:
- Eén partitie met 50% van de gegevens (deze partitie is niet gesplitst)
- Twee partities die 25% van de gegevens bevatten (dit zijn de resulterende onderliggende partities van de bovenliggende partitie die is gesplitst)
Omdat Azure Cosmos DB RU/s gelijkmatig over alle fysieke partities distribueert, krijgt elke fysieke partitie nog steeds 10.000 RU/s. We hebben nu echter een scheeftrekken in opslag en aanvraagdistributie.
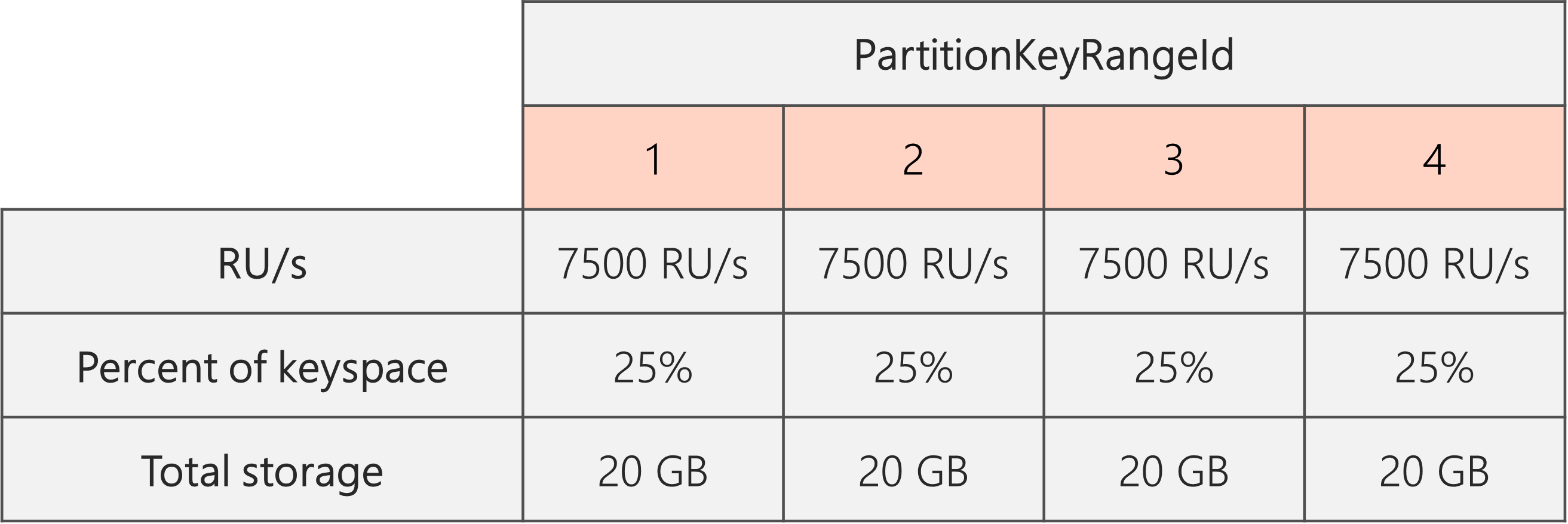
In het volgende diagram zien we dat partities 3 en 4 (de onderliggende partities van Partitie 2) elk 10.000 RU/s hebben om aanvragen voor 20 GB aan gegevens te verwerken, terwijl Partition 1 10.000 RU/s heeft voor twee keer de hoeveelheid gegevens (40 GB).

Om een gelijkmatige opslagdistributie te behouden, kunnen we eerst onze RU/s omhoog schalen om ervoor te zorgen dat elke partitie wordt gesplitst. Vervolgens kunnen we onze RU/s omlaag verlagen naar de gewenste status.
Dus als we beginnen met twee fysieke partities, om te garanderen dat de partities zelfs na het splitsen zijn, moeten we RU/s zo instellen dat we uiteindelijk vier fysieke partities hebben. Hiervoor stellen we EERST RU/s in op 4 * 10.000 RU/s per partitie = 40.000 RU/s. Nadat de splitsing is voltooid, kunnen we de RU/s verlagen tot 30.000 RU/s.
Als gevolg hiervan zien we in het volgende diagram dat elke fysieke partitie 30.000 RU/s / 4 = 7500 RU/s krijgt om aanvragen voor 20 GB aan gegevens te verwerken. Over het algemeen onderhouden we zelfs opslag en aanvraagdistributie tussen partities.
Algemene formule
Stap 1: Verhoog uw RU/s om te garanderen dat alle partities gelijkmatig worden gesplitst
Over het algemeen geldt dat als u een beginaantal fysieke partities Phebt en u een gewenste RU/s Swilt instellen:
Verhoog uw RU/s naar: 10,000 * P * (2 ^ (ROUNDUP(LOG_2 (S/(10,000 * P)))). Dit geeft de dichtstbijzijnde RU/s aan de gewenste waarde die ervoor zorgt dat alle partities gelijkmatig worden gesplitst.
Notitie
Wanneer u de RU/s van een database of container verhoogt, kan dit van invloed zijn op de minimale RU/s die u in de toekomst kunt verlagen. Normaal gesproken is de minimale RU/s gelijk aan MAX(400 RU/s, huidige opslag in GB * 1 RU/s, hoogste RU/s ooit ingericht / 100). Als de hoogste RU/s die u ooit hebt geschaald bijvoorbeeld 100.000 RU/s is, zijn de laagste RU/s die u in de toekomst kunt instellen 1000 RU/s. Meer informatie over minimale RU/s.
Stap 2: uw RU/s verlagen naar de gewenste RU/s
Stel dat we vijf fysieke partities hebben, 50.000 RU/s en willen schalen naar 150.000 RU/s. We moeten eerst instellen: 10,000 * 5 * (2 ^ (ROUND(LOG_2(150,000/(10,000 * 5)))) = 200.000 RU/s en vervolgens lager dan 150.000 RU/s.
Wanneer we omhoog schalen naar 200.000 RU/s, zijn de laagste handmatige RU/s die we nu in de toekomst kunnen instellen 2000 RU/s. De laagste ru/s voor automatische schaalaanpassing die we kunnen instellen, is 20.000 RU/s (schaalt tussen 2000 en 20.000 RU/s). Omdat onze doel-RU/s 150.000 RU/s zijn, worden we niet beïnvloed door de minimale RU/s.
RU/s optimaliseren voor grote gegevensopname
Wanneer u van plan bent om een grote hoeveelheid gegevens naar Azure Cosmos DB te migreren of op te nemen, is het raadzaam om de RU/s van de container zo in te stellen dat Azure Cosmos DB vooraf de fysieke partities instelt die nodig zijn om de totale hoeveelheid gegevens op te slaan die u vooraf wilt opnemen. Anders moet Azure Cosmos DB tijdens opname mogelijk partities splitsen, waardoor er meer tijd wordt toegevoegd aan de gegevensopname.
We kunnen profiteren van het feit dat Azure Cosmos DB tijdens het maken van een container gebruikmaakt van de heuristische formule van het starten van RU/s om het aantal fysieke partities te berekenen waarmee moet worden begonnen.
Stap 1: De keuze van de partitiesleutel controleren
Volg de aanbevolen procedures voor het kiezen van een partitiesleutel om ervoor te zorgen dat u na de migratie zelfs distributie van aanvraagvolume en opslag hebt.
Stap 2: het aantal fysieke partities berekenen dat u nodig hebt
Number of physical partitions = Total data size in GB / Target data per physical partition in GB
Elke fysieke partitie kan maximaal 50 GB opslagruimte bevatten (30 GB voor API voor Cassandra). De waarde die u moet kiezen, Target data per physical partition in GB is afhankelijk van hoe volledig verpakt u wilt dat de fysieke partities zijn en hoeveel u verwacht dat de opslag na de migratie groeit.
Als u bijvoorbeeld verwacht dat de opslag blijft groeien, kunt u ervoor kiezen om de waarde in te stellen op 30 GB. Ervan uitgaande dat u een goede partitiesleutel hebt gekozen die gelijkmatig opslag distribueert, is elke partitie ongeveer 60% vol (30 GB van 50 GB). Wanneer toekomstige gegevens worden geschreven, kunnen deze worden opgeslagen op de bestaande set fysieke partities, zonder dat de service onmiddellijk meer fysieke partities hoeft toe te voegen.
Als u daarentegen denkt dat de opslag na de migratie niet aanzienlijk zal toenemen, kunt u ervoor kiezen om de waarde hoger in te stellen, bijvoorbeeld 45 GB. Dit betekent dat elke partitie ~90% vol is (45 GB van 50 GB). Dit minimaliseert het aantal fysieke partities waarover uw gegevens worden verdeeld, wat betekent dat elke fysieke partitie een groter deel van de totale ingerichte RU/s kan krijgen.
Stap 3: het aantal RU/s berekenen waarmee moet worden gestart voor alle partities
Starting RU/s for all partitions = Number of physical partitions * Initial throughput per physical partition.
Laten we beginnen met een voorbeeld met een willekeurig aantal doel-RU/s per fysieke partitie.
Initial throughput per physical partition= 10.000 RU/s per fysieke partitie bij gebruik van automatische schaalaanpassing of gedeelde doorvoerdatabasesInitial throughput per physical partition= 6000 RU/s per fysieke partitie bij gebruik van handmatige doorvoer
Opmerking
Stel dat we 1 TB (1000 GB) aan gegevens hebben die we willen opnemen en dat we handmatige doorvoer willen gebruiken. Elke fysieke partitie in Azure Cosmos DB heeft een capaciteit van 50 GB. Laten we aannemen dat we partities willen inpakken om 80% vol te zijn (40 GB), waardoor we ruimte hebben voor toekomstige groei.
Dit betekent dat we voor 1 TB aan gegevens 1000 GB / 40 GB = 25 fysieke partities nodig hebben. Om ervoor te zorgen dat we 25 fysieke partities krijgen, als we handmatige doorvoer gebruiken, richten we eerst 25 * 6000 RU/s = 150.000 RU/s in. Nadat de container is gemaakt, kunnen we de RU/s verhogen naar 250.000 RU/s voordat de opname begint (gebeurt direct omdat we al 25 fysieke partities hebben). Hierdoor kan elke partitie maximaal 10.000 RU/s ophalen.
Als we automatische schaalaanpassing van doorvoer of een gedeelde doorvoerdatabase gebruiken om 25 fysieke partities op te halen, richten we eerst 25 * 10.000 RU/s = 250.000 RU/s in. Omdat we zich al op de hoogste RU/s bevinden die kunnen worden ondersteund met 25 fysieke partities, zouden we onze ingerichte RU/s niet verder verhogen vóór de opname.
In theorie, met 250.000 RU/s en 1 TB aan gegevens, als we ervan uitgaan dat documenten van 1 kB en 10 RU's vereist zijn voor schrijven, de opname kan theoretisch worden voltooid in: 1000 GB * (1.000.000 kb / 1 GB) * (1 document / 1 kb) * (10 RU / document) * (1 sec / 250.000 RU) * (1 uur / 3600 seconden) = 11,1 uur.
Deze berekening is een schatting ervan uitgaande dat de client die de opname uitvoert, de doorvoer volledig kan verzadigen en schrijfbewerkingen over alle fysieke partities kan distribueren. Het wordt aanbevolen om uw gegevens aan de clientzijde te 'willekeurige' volgorde te geven. Dit zorgt ervoor dat elke seconde, de client naar veel afzonderlijke logische (en dus fysieke) partities schrijft.
Zodra de migratie is afgelopen, kunnen we de RU/s verlagen of indien nodig automatisch schalen inschakelen.
Volgende stappen
- Controleer het genormaliseerde RU/s-verbruik van uw database of container.
- Problemen met te grote aanvragen vaststellen en oplossen (429) uitzonderingen.
- Schakel automatisch schalen in voor een database of container.