Bulksgewijs kopiëren vanuit een database met een besturingstabel
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
Als u gegevens wilt kopiëren van een datawarehouse in Oracle Server, Netezza, Teradata of SQL Server naar Azure Synapse Analytics, moet u grote hoeveelheden gegevens uit meerdere tabellen laden. Normaal gesproken moeten de gegevens in elke tabel worden gepartitioneerd, zodat u rijen met meerdere threads parallel vanuit één tabel kunt laden. In dit artikel wordt een sjabloon beschreven die in deze scenario's moet worden gebruikt.
Notitie
Als u gegevens uit een klein aantal tabellen met relatief klein gegevensvolume naar Azure Synapse Analytics wilt kopiëren, is het efficiënter om het hulpprogramma Azure Data Factory Copy Data te gebruiken. De sjabloon die in dit artikel wordt beschreven, is meer dan u nodig hebt voor dat scenario.
Over deze oplossingssjabloon
Met deze sjabloon wordt een lijst met brondatabasepartities opgehaald die moeten worden gekopieerd uit een externe besturingstabel. Vervolgens wordt elke partitie in de brondatabase herhaald en worden de gegevens naar het doel gekopieerd.
De sjabloon bevat drie activiteiten:
- Met opzoeken wordt de lijst met bepaalde databasepartities opgehaald uit een externe besturingstabel.
- ForEach haalt de partitielijst op uit de lookup-activiteit en doorloopt elke partitie naar de Copy-activiteit.
- Kopieert elke partitie uit het brondatabasearchief naar het doelarchief.
De sjabloon definieert de volgende parameters:
- Control_Table_Name is de tabel voor extern beheer, waarin de partitielijst voor de brondatabase wordt opgeslagen.
- Control_Table_Schema_PartitionID is de naam van de kolomnaam in de tabel voor extern beheer waarin elke partitie-id wordt opgeslagen. Zorg ervoor dat de partitie-id uniek is voor elke partitie in de brondatabase.
- Control_Table_Schema_SourceTableName is de externe besturingstabel waarin elke tabelnaam uit de brondatabase wordt opgeslagen.
- Control_Table_Schema_FilterQuery is de naam van de kolom in de externe besturingstabel waarin de filterquery wordt opgeslagen om de gegevens op te halen uit elke partitie in de brondatabase. Als u de gegevens bijvoorbeeld per jaar hebt gepartitioneerd, kan de query die in elke rij is opgeslagen, vergelijkbaar zijn met 'select * in de gegevensbron waarbij LastModifytime >= ''2015-01-01 00:00'' en LastModifytime <= ''2015-12-31 23:59:59.999' is.'
- Data_Destination_Folder_Path is het pad waar de gegevens naar uw doelarchief worden gekopieerd (van toepassing als de bestemming die u kiest' 'Bestandssysteem' of 'Azure Data Lake Storage Gen1').
- Data_Destination_Container is het pad naar de hoofdmap waarnaar de gegevens worden gekopieerd in het doelarchief.
- Data_Destination_Directory is het mappad onder de hoofdmap waar de gegevens naar uw doelarchief worden gekopieerd.
De laatste drie parameters, die het pad in uw doelarchief definiëren, zijn alleen zichtbaar als de bestemming die u kiest bestandsopslag is. Als u Azure Synapse Analytics als doelarchief kiest, zijn deze parameters niet vereist. Maar de tabelnamen en het schema in Azure Synapse Analytics moeten hetzelfde zijn als de namen in de brondatabase.
Deze oplossingssjabloon gebruiken
Maak een besturingstabel in SQL Server of Azure SQL Database om de partitielijst van de brondatabase op te slaan voor bulksgewijs kopiëren. In het volgende voorbeeld zijn er vijf partities in de brondatabase. Drie partities zijn voor de datasource_table en twee voor de project_table. De kolom LastModifytime wordt gebruikt om de gegevens in de tabel te partitioneren datasource_table uit de brondatabase. De query die wordt gebruikt om de eerste partitie te lezen, is 'select * from datasource_table where LastModifytime >= ''2015-01-01 00:00'' en LastModifytime <= ''2015-12-31 23:59:59.999'''. U kunt een vergelijkbare query gebruiken om gegevens uit andere partities te lezen.
Create table ControlTableForTemplate ( PartitionID int, SourceTableName varchar(255), FilterQuery varchar(255) ); INSERT INTO ControlTableForTemplate (PartitionID, SourceTableName, FilterQuery) VALUES (1, 'datasource_table','select * from datasource_table where LastModifytime >= ''2015-01-01 00:00:00'' and LastModifytime <= ''2015-12-31 23:59:59.999'''), (2, 'datasource_table','select * from datasource_table where LastModifytime >= ''2016-01-01 00:00:00'' and LastModifytime <= ''2016-12-31 23:59:59.999'''), (3, 'datasource_table','select * from datasource_table where LastModifytime >= ''2017-01-01 00:00:00'' and LastModifytime <= ''2017-12-31 23:59:59.999'''), (4, 'project_table','select * from project_table where ID >= 0 and ID < 1000'), (5, 'project_table','select * from project_table where ID >= 1000 and ID < 2000');Ga naar de sjabloon bulksgewijs kopiëren vanuit de databasesjabloon . Maak een nieuwe verbinding met de tabel voor extern beheer die u in stap 1 hebt gemaakt.

Maak een nieuwe verbinding met de brondatabase waaruit u gegevens kopieert.

Maak een nieuwe verbinding met het doelgegevensarchief waarnaar u de gegevens kopieert.
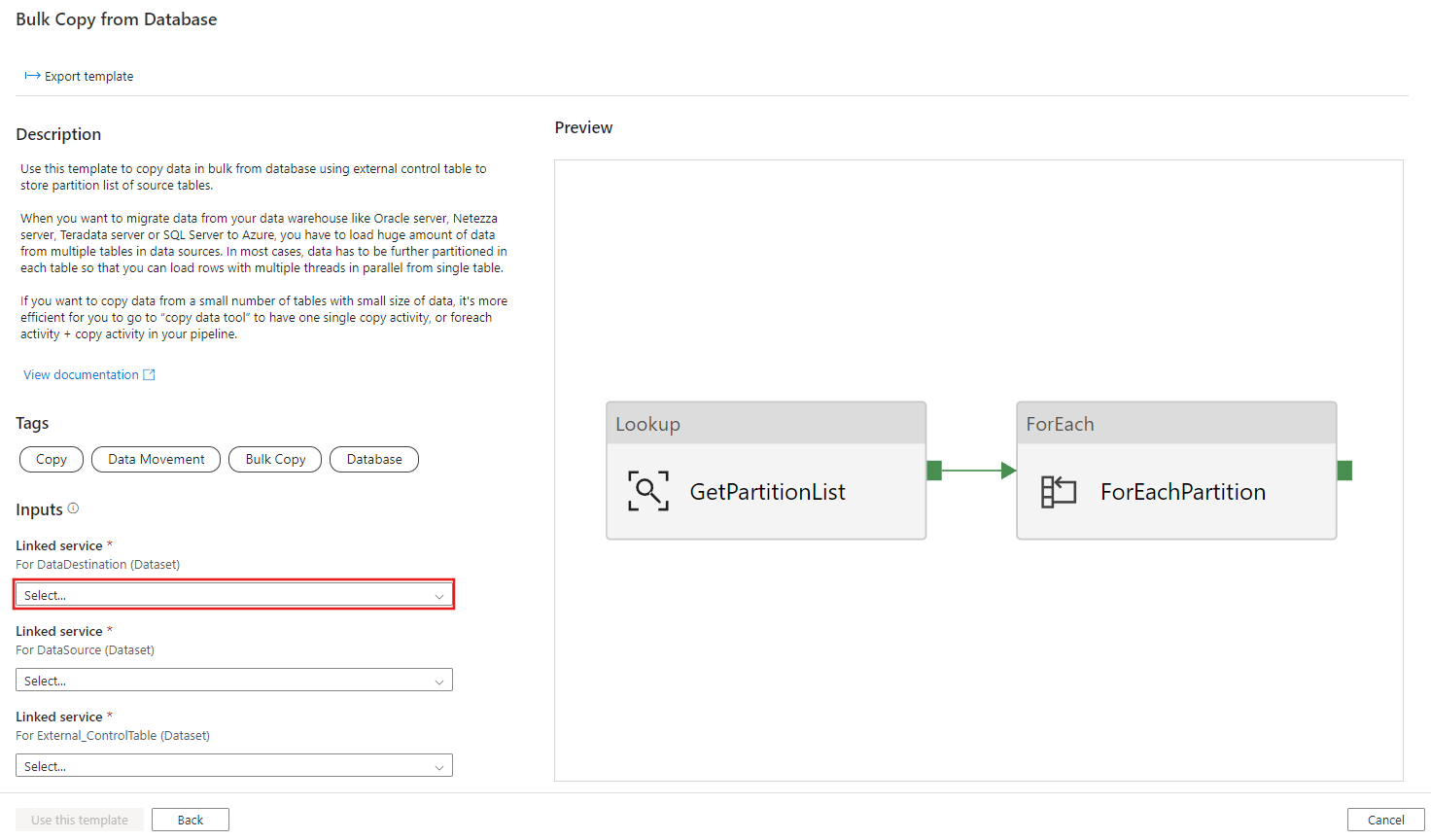
Selecteer Deze sjabloon gebruiken.
U ziet de pijplijn, zoals wordt weergegeven in het volgende voorbeeld:

Selecteer Fouten opsporen, voer de parameters in en selecteer Voltooien.

U ziet resultaten die vergelijkbaar zijn met het volgende voorbeeld:

(Optioneel) Als u 'Azure Synapse Analytics' als de gegevensbestemming hebt gekozen, moet u een verbinding met Azure Blob Storage invoeren voor fasering, zoals vereist door Azure Synapse Analytics Polybase. De sjabloon genereert automatisch een containerpad voor uw Blob-opslag. Controleer of de container is gemaakt nadat de pijplijn is uitgevoerd.
