Azure Machine Learning-pijplijnen uitvoeren in Azure Data Factory en Synapse Analytics
VAN TOEPASSING OP:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
Voer uw Azure Machine Learning-pijplijnen uit als een stap in uw Azure Data Factory- en Synapse Analytics-pijplijnen. Met de Machine Learning Execute Pipeline-activiteit zijn batchvoorspellingsscenario's mogelijk, zoals het identificeren van mogelijke standaardinstellingen voor leningen, het bepalen van sentiment en het analyseren van gedragspatronen van klanten.
De onderstaande video bevat een zes minuten durende inleiding en demonstratie van deze functie.
Een Machine Learning Execute Pipeline-activiteit maken met de gebruikersinterface
Voer de volgende stappen uit om een Machine Learning Execute Pipeline-activiteit in een pijplijn te gebruiken:
Zoek naar Machine Learning in het deelvenster Pijplijnactiviteiten en sleep een Machine Learning-pijplijnactiviteit naar het pijplijncanvas.
Selecteer de nieuwe Machine Learning Execute Pipeline-activiteit op het canvas als deze nog niet is geselecteerd en het tabblad Instellingen om de details ervan te bewerken.
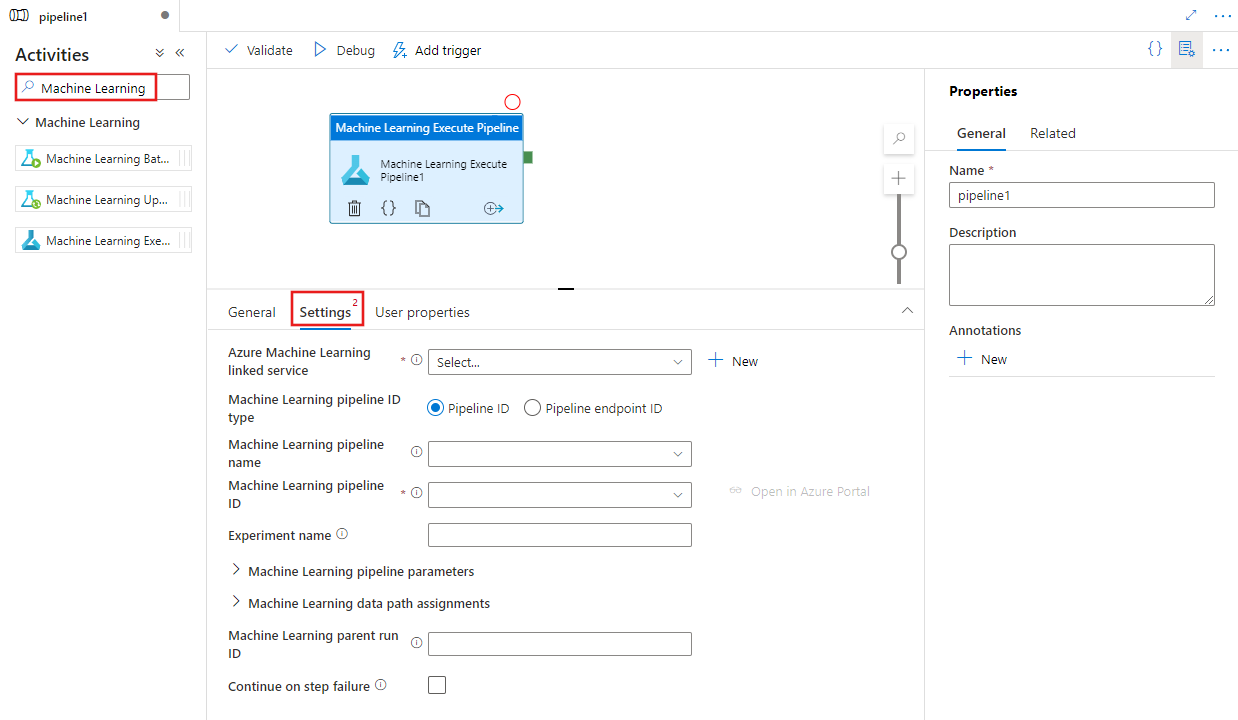
Selecteer een bestaande of maak een nieuwe gekoppelde Azure Machine Learning-service en geef details op van de pijplijn en het experiment en eventuele pijplijnparameters of gegevenspadtoewijzingen die vereist zijn voor de pijplijn.
Syntaxis
{
"name": "Machine Learning Execute Pipeline",
"type": "AzureMLExecutePipeline",
"linkedServiceName": {
"referenceName": "AzureMLService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"mlPipelineId": "machine learning pipeline ID",
"experimentName": "experimentName",
"mlPipelineParameters": {
"mlParameterName": "mlParameterValue"
}
}
}
Typeeigenschappen
| Eigenschappen | Beschrijving | Toegestane waarden | Vereist |
|---|---|---|---|
| naam | Naam van de activiteit in de pijplijn | String | Ja |
| type | Het type activiteit is 'AzureMLExecutePipeline' | String | Ja |
| linkedServiceName | Gekoppelde service aan Azure Machine Learning | Naslaginformatie over gekoppelde services | Ja |
| mlPipelineId | Id van de gepubliceerde Azure Machine Learning-pijplijn | Tekenreeks (of expressie met resultType van tekenreeks) | Ja |
| experimentName | Uitvoeringsgeschiedenisexperimentnaam van de Machine Learning-pijplijnuitvoering | Tekenreeks (of expressie met resultType van tekenreeks) | Nee |
| mlPipelineParameters | Sleutel, waardeparen die moeten worden doorgegeven aan het gepubliceerde Azure Machine Learning-pijplijneindpunt. Sleutels moeten overeenkomen met de namen van pijplijnparameters die zijn gedefinieerd in de gepubliceerde Machine Learning-pijplijn | Object met sleutel-waardeparen (of expressie met resultType-object) | Nee |
| mlParentRunId | De bovenliggende azure Machine Learning-pijplijnuitvoerings-id | Tekenreeks (of expressie met resultType van tekenreeks) | Nee |
| dataPathAssignments | Woordenlijst die wordt gebruikt voor het wijzigen van gegevenspaden in Azure Machine Learning. Hiermee schakelt u gegevenspaden over | Object met sleutel-waardeparen | Nee |
| continueOnStepFailure | Of u wilt doorgaan met het uitvoeren van andere stappen in de Machine Learning-pijplijn als een stap mislukt | boolean | Nr. |
Notitie
Als u de vervolgkeuzelijstitems in de naam en id van de Machine Learning-pijplijn wilt vullen, moet de gebruiker gemachtigd zijn om ML-pijplijnen weer te geven. De gebruikersinterface roept AzureMLService-API's rechtstreeks aan met behulp van de referenties van de aangemelde gebruiker. De detectietijd voor de vervolgkeuzelijstitems is veel langer bij het gebruik van privé-eindpunten.
Gerelateerde inhoud
Zie de volgende artikelen waarin wordt uitgelegd hoe u gegevens op andere manieren kunt transformeren: