Diagnose van standaard load balancer met metrische gegevens, meldingen en resourcestatus
Azure Load Balancer biedt de volgende diagnostische mogelijkheden:
Multidimensionale metrische gegevens en waarschuwingen: biedt multidimensionale diagnostische mogelijkheden via Azure Monitor voor Azure Load Balancer-configuraties. U kunt uw standard load balancer-resources bewaken, beheren en problemen oplossen.
Resourcestatus: De status van de resourcestatus van uw load balancer is beschikbaar op de pagina Resourcestatus onder Controleren. Deze automatische controle informeert u over de huidige beschikbaarheid van uw load balancer-resource.
Dit artikel bevat een korte rondleiding over deze mogelijkheden en biedt manieren om ze te gebruiken voor een standaard load balancer.
Multidimensionale metrische gegevens
Azure Load Balancer biedt multidimensionale metrische gegevens via de metrische gegevens van Azure in Azure Portal en helpt u realtime diagnostische inzichten te krijgen in uw load balancer-resources. Houd er rekening mee dat multidimensionale metrische gegevens niet worden ondersteund voor Basic Load Balancers
De verschillende load balancer-configuraties bieden de volgende metrische gegevens:
| Metrische gegevens | Brontype | Beschrijving | Aanbevolen aggregatie |
|---|---|---|---|
| Beschikbaarheid van gegevenspad | Openbare en interne load balancer | Een load balancer maakt continu gebruik van het gegevenspad vanuit een regio naar de front-end van de load balancer naar het netwerk dat uw VIRTUELE machine ondersteunt. Zolang er gezonde exemplaren blijven, volgt de meting hetzelfde pad als het verkeer met gelijke taakverdeling van uw toepassing. Het gegevenspad dat wordt gebruikt, wordt gevalideerd. De meting is onzichtbaar voor uw toepassing en heeft geen invloed op andere bewerkingen. | Gemiddeld |
| Status van de statustest | Openbare en interne load balancer | Een load balancer maakt gebruik van een gedistribueerde statustestservice die de status van uw toepassingseindpunt bewaakt volgens uw configuratie-instellingen. Deze metriek biedt een gefilterde weergave van een aggregatie of per-eindpunt van elk exemplaareindpunt in de load balancer-groep. U kunt zien hoe load balancer de status van uw toepassing bekijkt, zoals wordt aangegeven door uw statustestconfiguratie. | Gemiddeld |
| Aantal SYN | Openbare en interne load balancer | Een load balancer beëindigt tcp-verbindingen (Transmission Control Protocol) niet of communiceert met TCP- of UDP-stromen (User Data-gram Packet). Stromen en hun handshakes vinden altijd plaats de bron en het VM-exemplaar. U kunt tellers voor SYN-pakketten gebruiken om te ontdekken hoeveel TCP-verbindingspogingen zijn ondernomen, om problemen in uw scenario’s voor TCP-protocollen beter te kunnen oplossen. Via de metriek wordt het aantal TCP SYN-pakketten gerapporteerd dat is ontvangen. | Sum |
| Aantal SNAT-verbindingen (Source Network Address Translation) | Openbare load balancer | Een load balancer rapporteert het aantal uitgaande stromen dat zich vervelend voor de front-end van het openbare IP-adres. SNAT-poorten zijn een uitgeputte resource. Met deze metriek kan een indicatie worden gegeven van hoe sterk de toepassing vertrouwt op SNAT voor uitgaande stromen. Tellers voor geslaagde en mislukte uitgaande SNAT-stromen worden gerapporteerd. De tellers kunnen worden gebruikt om problemen op te lossen en inzicht te hebben in de status van uw uitgaande stromen. | Sum |
| Toegewezen SNAT-poorten | Openbare load balancer | Een load balancer rapporteert het aantal SNAT-poorten dat per back-endinstantie is toegewezen | Gemiddeld. |
| Gebruikte SNAT-poorten | Openbare load balancer | Een load balancer rapporteert het aantal SNAT-poorten dat per back-endinstantie wordt gebruikt. | Gemiddeld |
| Aantal bytes | Openbare en interne load balancer | Een load balancer rapporteert de gegevens die per front-end worden verwerkt. U ziet mogelijk dat de bytes niet gelijkmatig worden verdeeld over de back-endinstanties. Dit wordt verwacht omdat het Azure Load Balancer-algoritme is gebaseerd op stromen | Sum |
| Aantal pakketten | Openbare en interne load balancer | Een load balancer rapporteert de pakketten die per front-end zijn verwerkt. | Sum |
Notitie
Metrische gegevens met betrekking tot bandbreedte, zoals SYN-pakket, byteaantal en aantal pakketten, leggen geen verkeer vast naar een interne load balancer via een UDR (bijvoorbeeld van een NVA of firewall).
Maximum- en minimale aggregaties zijn niet beschikbaar voor het SYN-aantal, pakketaantal, het aantal SNAT-verbindingen en de metrische byteaantallen. Aggregatie van aantallen wordt niet aanbevolen voor beschikbaarheid van gegevenspaden en statusteststatus. Gebruik in plaats daarvan het gemiddelde voor de beste weergegeven statusgegevens.
Metrische gegevens van uw load balancer weergeven in Azure Portal
Azure Portal toont de metrische gegevens van de load balancer via de pagina Metrische gegevens. Deze pagina is beschikbaar op zowel de resourcepagina van de load balancer voor een bepaalde resource als de Azure Monitor-pagina.
Notitie
Azure Load Balancer verzendt geen statustests naar de toewijzing van virtuele machines ongedaan gemaakt. Wanneer de toewijzing van virtuele machines ongedaan wordt gemaakt, stopt de load balancer met het rapporteren van metrische gegevens voor dat exemplaar. Metrische gegevens die niet beschikbaar zijn, worden weergegeven als een stippellijn in de portal of geven een foutbericht weer dat aangeeft dat metrische gegevens niet kunnen worden opgehaald.
De metrische gegevens voor uw load balancer-resources weergeven:
Ga naar de pagina met metrische gegevens en voer een van de volgende taken uit:
Selecteer op de resourcepagina van de load balancer het metrische type in de vervolgkeuzelijst.
Selecteer op de pagina Azure Monitor de load balancer-resource.
Stel het juiste aggregatietype voor metrische gegevens in.
Configureer desgewenst de vereiste filters en groeperingen.
Configureer eventueel het tijdsbereik en de aggregatie. Standaard wordt de tijd weergegeven in UTC.
Notitie
Tijdaggregatie is belangrijk bij het interpreteren van bepaalde metrische gegevens, omdat er eenmaal per minuut een steekproef wordt genomen van gegevens. Als tijdaggregatie is ingesteld op vijf minuten en het aggregatietype Sum wordt gebruikt voor metrische gegevens zoals SNAT-toewijzing, wordt in uw grafiek vijf keer de totale toegewezen SNAT-poorten weergegeven.
Aanbeveling: bij het analyseren van het aggregatietype Som en Aantal metrische gegevens raden we u aan een tijdaggregatiewaarde te gebruiken die groter is dan één minuut.

Afbeelding: Metrische gegevens voor beschikbaarheid van gegevenspaden voor een standaard load balancer
Programmatisch multidimensionale metrische gegevens ophalen via API's
Zie voor API-richtlijnen voor het ophalen van multidimensionale metrische definities en waarden van Azure Monitoring REST API. Deze metrische gegevens kunnen naar een opslagaccount worden geschreven door een diagnostische instelling toe te voegen voor de categorie Alle metrische gegevens.
Veelvoorkomende diagnostische scenario's en aanbevolen weergaven
Is het gegevenspad beschikbaar voor de front-end van mijn load balancer?
Uitbreiden
De metrische gegevens over beschikbaarheid van gegevenspaden beschrijven de status binnen de regio van het gegevenspad naar de rekenhost waar uw VM's zich bevinden. De metrische waarde is een weerspiegeling van de status van uw load balancer, op basis van uw configuratie en de Azure-infrastructuur. U kunt de metrische waarde gebruiken om het volgende te doen:
Controleer de externe beschikbaarheid van uw service.
Onderzoek het platform waar uw service is geïmplementeerd en bepaal of deze in orde is. Bepaal of uw gast-besturingssysteem of toepassingsexemplaren in orde zijn.
Isoleren of een gebeurtenis is gerelateerd aan uw service of het onderliggende gegevensvlak. Verwar deze metrische waarde niet met de metrische status van de statustest.
De beschikbaarheid van het gegevenspad voor uw load balancer-resources ophalen:
Zorg ervoor dat de juiste load balancer-resource is geselecteerd.
Selecteer in de vervolgkeuzelijst Metrische gegevens de optie Beschikbaarheid van gegevenspaden.
Selecteer Avg in de vervolgkeuzelijst Aggregatie.
Voeg bovendien een filter toe aan het front-end-IP-adres of de front-endpoort als de dimensie met het vereiste front-end-IP-adres of de front-endpoort. Groepeer ze vervolgens op de geselecteerde dimensie.
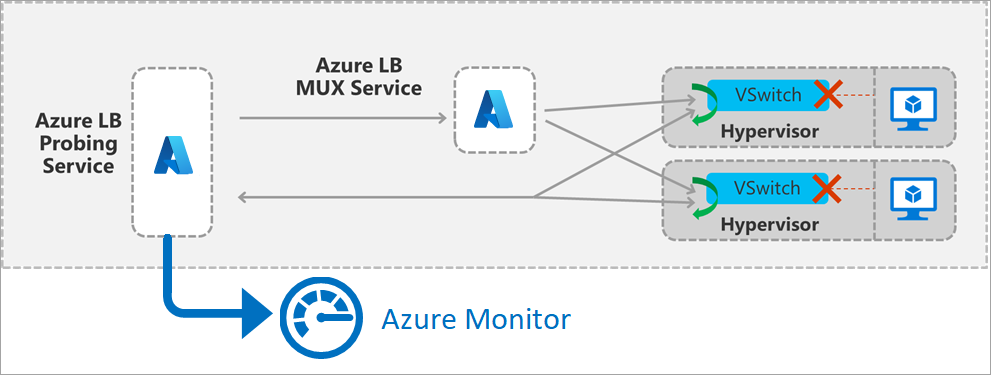
Afbeelding: Details van front-end van load balancer-front-end
De metrische waarde wordt gegenereerd door een testservice binnen de regio die verkeer simuleert. De testservice genereert periodiek een pakket dat overeenkomt met de front-end- en taakverdelingsregel van uw implementatie. Het pakket gaat vervolgens door de regio van de bron naar de host van een VIRTUELE machine in de back-endpool. De load balancer-infrastructuur voert dezelfde taakverdelings- en vertaalbewerkingen uit als voor al het andere verkeer. Nadat de test op de host is binnengekomen, waar een VM in de back-endpool zich bevindt, genereert de host een reactie op de testservice. Dit verkeer wordt niet weergegeven op uw VM.
Houd er rekening mee dat de metrische gegevens over beschikbaarheid van gegevenspaden alleen worden gegenereerd in front-end-IP-configuraties met taakverdelingsregels.
De metrische gegevens over beschikbaarheid van gegevenspaden kunnen om de volgende redenen worden gedegradeerd:
Uw implementatie heeft geen vm's die in orde zijn in de back-endpool.
Er is een storing in de infrastructuur opgetreden.
Voor diagnostische doeleinden kunt u de metrische waarde gebruiken voor beschikbaarheid van gegevenspaden samen met de statusteststatus.
Gebruik Gemiddelde als de aggregatie voor de meeste scenario's.
Reageren de back-endinstanties voor mijn load balancer op tests?
Uitbreiden
De metrische status van de statustest beschrijft de status van uw toepassingsimplementatie die door u is geconfigureerd wanneer u de statustest van uw load balancer configureert. De load balancer gebruikt de status van de statustest om te bepalen waar nieuwe stromen moeten worden verzonden. Statustests zijn afkomstig van een Azure-infrastructuuradres en zijn zichtbaar in het gastbesturingssystemen van de VIRTUELE machine.
De metrische status van de statustest voor uw load balancer-resources ophalen:
Selecteer de metriek Status van de statustest met aggregatietype Gem.
Pas een filter toe op het vereiste IP-adres of de poort van de front-end (of beide).
Statustests mislukken om de volgende redenen:
U configureert een statustest voor een poort die niet luistert of niet reageert of het verkeerde protocol gebruikt. Als uw service directe server retour- of zwevende IP-regels gebruikt, controleert u of de service luistert op het IP-adres van de IP-configuratie van de NIC en de loopback die is geconfigureerd met het front-end-IP-adres.
Uw netwerkbeveiligingsgroep, de firewall van het gastbesturingssystemen van de VIRTUELE machine of de filters van de toepassingslaag staan het statustestverkeer niet toe.
Gebruik Gemiddelde als de aggregatie voor de meeste scenario's.
Hoe kan ik mijn statistieken voor uitgaande verbindingen controleren?
Uitbreiden
De metrische gegevens voor SNAT-verbindingen beschrijven het volume van geslaagde en mislukte verbindingen voor uitgaande stromen.
Een mislukt verbindingsvolume van meer dan nul geeft aan dat de SNAT-poortuitputting is uitgeput. U moet verder onderzoeken wat deze fouten kunnen veroorzaken. SNAT-poortuitputting manifesten als een fout bij het tot stand brengen van een uitgaande stroom. Lees het artikel over uitgaande verbindingen om inzicht te krijgen in de scenario's en mechanismen op het werk en om te leren hoe u SNAT-poortuitputting kunt beperken en ontwerpen.
Ga als volgt te werk om SNAT-verbindingsstatistieken op te halen:
Selecteer het metrische gegevenstype SNAT Connections en Sum als aggregatie.
Groeperen op verbindingsstatus voor geslaagde en mislukte SNAT-verbindingsaantallen die worden vertegenwoordigd door verschillende regels.

Afbeelding: Aantal SNAT-verbindingen van load balancer
Hoe kan ik het gebruik en de toewijzing van mijn SNAT-poort controleren?
Uitbreiden
Met de metrische gegevens van de gebruikte SNAT-poorten wordt bijgehouden hoeveel SNAT-poorten worden gebruikt om uitgaande stromen te onderhouden. Deze metrische waarde geeft aan hoeveel unieke stromen er tot stand zijn gebracht tussen een internetbron en een back-end-VM of virtuele-machineschaalset die zich achter een load balancer bevindt en geen openbaar IP-adres heeft. Door het aantal SNAT-poorten dat u gebruikt te vergelijken met de metrische gegevens toegewezen SNAT-poorten, kunt u bepalen of uw service last heeft van SNAT-uitputting en het gevolg is van een storing in de uitgaande stroom.
Als uw metrische gegevens het risico van een storing in de uitgaande stroom aangeven, raadpleegt u het artikel en voert u stappen uit om dit te verhelpen om de servicestatus te waarborgen.
Gebruik en toewijzing van SNAT-poorten weergeven:
Stel de tijdaggregatie van de grafiek in op 1 minuut om ervoor te zorgen dat de gewenste gegevens worden weergegeven.
Selecteer Gebruikte SNAT-poorten en/of toegewezen SNAT-poorten als het metrische type en gemiddelde als de aggregatie.
Deze metrische gegevens zijn standaard het gemiddelde aantal SNAT-poorten dat is toegewezen aan of gebruikt door elke back-end-VM of virtuele-machineschaalset. Ze komen overeen met alle openbare IP-adressen van de front-end die zijn toegewezen aan de load balancer, geaggregeerd via TCP en UDP.
Als u het totale aantal SNAT-poorten wilt weergeven dat wordt gebruikt door of toegewezen voor de load balancer, gebruikt u sum voor metrische aggregatie.
Filter op een specifiek protocoltype, een set back-end-IP-adressen en/of front-end-IP's.
Als u de status per back-end- of front-endexemplaren wilt bewaken, past u splitsing toe.
- Bij het splitsen van notities kan slechts één metrische waarde tegelijk worden weergegeven.
Als u bijvoorbeeld het SNAT-gebruik voor TCP-stromen per machine wilt bewaken, aggregeren op gemiddelde, gesplitst op BACK-end-IP-adressen en filteren op protocoltype.

Afbeelding: Gemiddelde TCP SNAT-poorttoewijzing en -gebruik voor een set back-end-VM's

Afbeelding: TCP SNAT-poortgebruik per back-endexemplaren
Hoe kan ik binnenkomende/uitgaande verbindingspogingen voor mijn service controleren?
Vouw
een metrische waarde voor SYN-pakketten uit om het volume van TCP SYN-pakketten te beschrijven, die zijn aangekomen of verzonden voor uitgaande stromen die zijn gekoppeld aan een specifieke front-end. U kunt deze metrische waarde gebruiken om inzicht te verkrijgen in TCP-verbindingspogingen naar uw service.Gebruik Sum als de aggregatie voor de meeste scenario's.

Afbeelding: Syn-telling van load balancer
Hoe kan ik het verbruik van mijn netwerkbandbreedte controleren?
Uitbreiden
De metrische gegevens van bytes en pakkettellers beschrijven het volume van bytes en pakketten die per front-end door uw service worden verzonden of ontvangen.
Gebruik Sum als de aggregatie voor de meeste scenario's.
Statistieken over byte- of pakketaantallen ophalen:
Selecteer het metrische type Bytes Count en/of Packet Count , waarbij Sum als aggregatie wordt gebruikt.
Voer een van de volgende bewerkingen uit:
Pas een filter toe op een specifieke front-end-IP, front-endpoort, back-end-IP of back-endpoort.
Haal algemene statistieken op voor uw load balancer-resource zonder te filteren.

Afbeelding: Aantal load balancer-bytes
Hoe kan ik mijn load balancer-implementatie diagnosticeren?
Uitbreiden
Met behulp van een combinatie van de metrische gegevens over de beschikbaarheid en statustest van het gegevenspad in één grafiek, kunt u bepalen waar het probleem moet worden gezocht en het probleem kan worden opgelost. U kunt er zeker van zijn dat Azure correct werkt en deze kennis gebruiken om te bepalen of de configuratie of toepassing de hoofdoorzaak is.
U kunt metrische statustestgegevens gebruiken om te begrijpen hoe Azure de status van uw implementatie bekijkt volgens de configuratie die u hebt opgegeven. Het bekijken van statustests is altijd een goede eerste stap bij het bewaken of bepalen van een oorzaak.
U kunt dit nog een stap verder doen en metrische gegevens over beschikbaarheid van gegevenspaden gebruiken om inzicht te krijgen in de status van het onderliggende gegevensvlak dat verantwoordelijk is voor uw specifieke implementatie. Wanneer u beide metrische gegevens combineert, kunt u isoleren waar de fout zich kan bevinden, zoals wordt geïllustreerd in dit voorbeeld:

Afbeelding: Beschikbaarheid van gegevenspaden en metrische gegevens over statustest combineren
In de grafiek ziet u de volgende informatie:
De infrastructuur die als host fungeert voor uw VM's was niet beschikbaar en 0 procent aan het begin van de grafiek. Later was de infrastructuur in orde en waren de VM's bereikbaar en werd meer dan één VIRTUELE machine in de back-end geplaatst. Deze informatie wordt aangegeven door de blauwe trace voor beschikbaarheid van gegevenspaden, die later op 100 procent lag.
De status van de statustest, aangegeven door de paarse trace, ligt aan het begin van de grafiek op 0 procent. Het omcirkelde gebied in groen markeert waar de status van de statustest in orde werd en op welk moment de implementatie van de klant nieuwe stromen kon accepteren.
In de grafiek kunnen klanten zelf problemen met de implementatie oplossen zonder dat ze ondersteuning hoeven te raden of te vragen of er andere problemen optreden. De service was niet beschikbaar omdat statustests mislukken vanwege een onjuiste configuratie of een mislukte toepassing.
Waarschuwingen configureren voor multidimensionale metrische gegevens
Azure Load Balancer ondersteunt eenvoudig configureerbare waarschuwingen voor multidimensionale metrische gegevens. Configureer aangepaste drempelwaarden voor specifieke metrische gegevens om waarschuwingen te activeren met verschillende ernstniveaus, zodat er geen aanraakresourcebewaking mogelijk is.
Waarschuwingen configureren:
Ga naar de waarschuwingspagina voor de load balancer
Nieuwe waarschuwingsregel maken
Waarschuwingsvoorwaarde configureren (Opmerking: om ruiswaarschuwingen te voorkomen, raden we u aan waarschuwingen te configureren met het aggregatietype ingesteld op Gemiddelde, terug te kijken naar een gegevensvenster van vijf minuten en met een drempelwaarde van 95%)
(Optioneel) Actiegroep toevoegen voor automatisch herstellen
Ernst, naam en beschrijving van waarschuwing toewijzen die intuïtieve reactie mogelijk maakt
Waarschuwingen voor inkomende beschikbaarheid
Notitie
Als de back-endpools van uw load balancer leeg zijn, heeft de load balancer geen geldige gegevenspaden om te testen. Als gevolg hiervan is de metrische gegevens over beschikbaarheid van gegevenspaden niet beschikbaar en worden geconfigureerde Azure-waarschuwingen op het metrische gegevenspad niet geactiveerd.
Als u wilt waarschuwen voor binnenkomende beschikbaarheid, kunt u twee afzonderlijke waarschuwingen maken met behulp van de metrische gegevens over de beschikbaarheid van het gegevenspad en de statusteststatus. Klanten kunnen verschillende scenario's hebben waarvoor specifieke waarschuwingslogica is vereist, maar de onderstaande voorbeelden zijn handig voor de meeste configuraties.
Met beschikbaarheid van gegevenspaden kunt u waarschuwingen activeren wanneer een specifieke taakverdelingsregel niet meer beschikbaar is. U kunt deze waarschuwing configureren door een waarschuwingsvoorwaarde in te stellen voor de beschikbaarheid van het gegevenspad en te splitsen op alle huidige waarden en toekomstige waarden voor zowel front-endpoort- als front-end-IP-adres. Als u de waarschuwingslogica instelt op minder dan of gelijk aan 0, wordt deze waarschuwing geactiveerd wanneer een taakverdelingsregel niet meer reageert. Stel de aggregatiegranulariteit en de frequentie van de evaluatie in op basis van de gewenste evaluatie.
Met de status van de statustest kunt u waarschuwen wanneer een bepaald back-endexemplaren gedurende een aanzienlijke tijd niet op de statustest reageren. Stel uw waarschuwingsvoorwaarde in om de metrische status van de statustest te gebruiken en te splitsen op back-end-IP-adres en back-endpoort. Dit zorgt ervoor dat u afzonderlijk kunt waarschuwen voor de mogelijkheid van elk afzonderlijk back-endexemplaren om verkeer op een specifieke poort te leveren. Gebruik het aggregatietype Gemiddelde en stel de drempelwaarde in op basis van hoe vaak uw back-endexemplaren worden onderzocht en de drempelwaarde die als in orde wordt beschouwd.
U kunt ook waarschuwen op het niveau van een back-endpool door geen dimensies te splitsen en het aggregatietype Gemiddelde te gebruiken. Hiermee kunt u waarschuwingsregels instellen, zoals een waarschuwing wanneer 50% van de leden van mijn back-endpool niet in orde is.
Waarschuwingen voor uitgaande beschikbaarheid
Voor uitgaande beschikbaarheid kunt u twee afzonderlijke waarschuwingen configureren met behulp van het aantal SNAT-verbindingen en metrische gegevens over de gebruikte SNAT-poort.
Als u uitgaande verbindingsfouten wilt detecteren, configureert u een waarschuwing met behulp van het aantal SNAT-verbindingen en filtert u op Verbindingsstatus = Mislukt. Gebruik de totaalaggregatie . Vervolgens kunt u dit splitsen op back-end-IP-adres dat is ingesteld op alle huidige en toekomstige waarden om afzonderlijk te waarschuwen voor elk back-endexemplaren met mislukte verbindingen. Stel de drempelwaarde in op groter dan nul of een hoger getal als u verwacht dat er een aantal uitgaande verbindingsfouten optreden.
Met gebruikte SNAT-poorten kunt u een waarschuwing ontvangen over een hoger risico op SNAT-uitputting en een storing in de uitgaande verbinding. Zorg ervoor dat u splitst op back-end-IP-adres en -protocol wanneer u deze waarschuwing gebruikt. Gebruik de aggregatie Gemiddelde . Stel in dat de drempelwaarde groter is dan een percentage van het aantal poorten dat u per instantie hebt toegewezen, onveilig is. Configureer bijvoorbeeld een waarschuwing met een lage ernst wanneer een back-endinstantie 75% van de toegewezen poorten gebruikt. Configureer een waarschuwing met hoge ernst wanneer deze 90% of 100% van de toegewezen poorten gebruikt.
Status van resource
De status van de standaard load balancer-resources wordt weergegeven via de bestaande resourcestatus onder Monitor > Servicestatus. Deze wordt om de twee minuten geëvalueerd door de beschikbaarheid van gegevenspaden te meten die bepalen of uw front-end-eindpunten voor taakverdeling beschikbaar zijn.
| Integriteitsstatus van de resource | Beschrijving |
|---|---|
| Beschikbaar | Uw standaard load balancer-resource is in orde en beschikbaar. |
| Verminderd beschikbaar | Uw standaard load balancer heeft door het platform of de gebruiker geïnitieerde gebeurtenissen die van invloed zijn op de prestaties. De metrische waarde voor beschikbaarheid van gegevenspaden heeft minder dan 90% gerapporteerd, maar gedurende ten minste twee minuten een status van meer dan 25%. Met deze status ondervindt u gemiddeld tot ernstig prestatie-effect. Volg de RHC-handleiding voor probleemoplossing om te bepalen of er door de gebruiker geïnitieerde gebeurtenissen zijn die van invloed zijn op uw beschikbaarheid. |
| Niet beschikbaar | Uw standard load balancer-resource is niet in orde. De metrische waarde voor beschikbaarheid van gegevenspaden heeft minder dan 25% gerapporteerd gedurende ten minste twee minuten. Met deze status ondervindt u een aanzienlijk prestatie-effect of een gebrek aan beschikbaarheid voor binnenkomende connectiviteit. Er kunnen gebruikers- of platformevenementen zijn die onbeschikbaarheid veroorzaken. Volg de RHC-handleiding voor probleemoplossing om te bepalen of er door de gebruiker geïnitieerde gebeurtenissen zijn die van invloed zijn op uw beschikbaarheid. |
| Onbekend | De status van uw load balancer-resource is niet bijgewerkt of heeft gedurende de afgelopen tien minuten geen informatie ontvangen over de beschikbaarheid van het gegevenspad. Dit hoort slechts tijdelijk het geval te zijn. De juiste status wordt weergegeven zodra er gegevens worden ontvangen. |
De status van uw openbare load balancer-resources weergeven:
Selecteer Monitor> Servicestatus.

Afbeelding: De servicestatuskoppeling in Azure Monitor
Selecteer Resourcestatus en zorg ervoor dat abonnements-id en resourcetype = load balancer zijn geselecteerd.

Afbeelding: Resource selecteren voor de statusweergave
Selecteer in de lijst de load balancer-resource om de historische status ervan weer te geven.

Afbeelding: Status van resource
Een algemene beschrijving van de status van een resource is beschikbaar in de documentatie over de resourcestatus.
Resource Health-waarschuwingen
Azure Resource Health-waarschuwingen kunnen u bijna in realtime waarschuwen wanneer de status van uw Load Balancer-resource verandert. Het is raadzaam om resourcestatuswaarschuwingen in te stellen om u op de hoogte te stellen wanneer uw Load Balancer-resource de status Gedegradeerd of Niet beschikbaar heeft.
Wanneer u Azure Resource Health-waarschuwingen voor Load Balancer maakt, verzendt Azure resourcestatusmeldingen naar uw Azure-abonnement. U kunt waarschuwingen maken en aanpassen op basis van:
- Het betrokken abonnement
- De betrokken resourcegroep
- Het betrokken resourcetype (Load Balancer)
- De specifieke resource (elke Load Balancer-resource waarvoor u een waarschuwing wilt instellen)
- De gebeurtenisstatus van de betrokken Load Balancer-resource
- De huidige status van de betrokken Load Balancer-resource
- De vorige status van de betrokken Load Balancer-resource
- Het redentype van de betrokken Load Balancer-resource
U kunt ook configureren naar wie de waarschuwing moet worden verzonden:
- Een nieuwe actiegroep (die kan worden gebruikt voor toekomstige waarschuwingen)
- Een bestaande actiegroep
Zie voor meer informatie over het instellen van deze resourcestatuswaarschuwingen:
- Waarschuwingen voor resourcestatus met behulp van De Azure-portal
- Resource health-waarschuwingen met Resource Manager-sjablonen
Volgende stappen
- Meer informatie over Network Analytics.
- Meer informatie over het gebruik van Inzichten om deze metrische gegevens weer te geven die vooraf zijn geconfigureerd voor uw load balancer.
- Meer informatie over Standard load balancer.