Overzicht van Azure Synapse Data Explorer gegevensopname (preview)
Gegevensopname is het proces dat wordt gebruikt om gegevensrecords uit een of meer bronnen te laden om gegevens te importeren in een tabel in Azure Synapse Data Explorer pool. Zodra de gegevens zijn opgenomen, worden ze beschikbaar voor query's.
De Azure Synapse Data Explorer-service voor gegevensbeheer, die verantwoordelijk is voor gegevensopname, implementeert het volgende proces:
- Haalt gegevens op in batches of streaming van een externe bron en leest aanvragen uit een Azure-wachtrij die in behandeling is.
- Batchgegevens die naar dezelfde database en tabel stromen, zijn geoptimaliseerd voor opnamedoorvoer.
- De initiële gegevens worden gevalideerd en de indeling wordt waar nodig geconverteerd.
- Verdere gegevensmanipulatie, waaronder overeenkomende schema's, organiseren, indexeren, coderen en comprimeren van de gegevens.
- Gegevens worden opgeslagen in de opslag volgens het ingestelde bewaarbeleid.
- Opgenomen gegevens worden doorgevoerd in de engine, waar ze beschikbaar zijn voor query's.
Ondersteunde gegevensindelingen, eigenschappen en machtigingen
Opname-eigenschappen: de eigenschappen die van invloed zijn op hoe de gegevens worden opgenomen (bijvoorbeeld taggen, toewijzen, aanmaaktijd).
Machtigingen: voor het opnemen van gegevens zijn machtigingen op het niveau van de database vereist. Voor andere acties, zoals query's, zijn mogelijk machtigingen voor databasebeheerder, databasegebruiker of tabelbeheerder vereist.
Batchverwerking versus streamingopnamen
Batchopname voert gegevensbatch uit en is geoptimaliseerd voor een hoge opnamedoorvoer. Deze methode heeft de voorkeur en het meest presterende type opname. Gegevens worden in batches uitgevoerd op basis van opname-eigenschappen. Kleine batches met gegevens worden samengevoegd en geoptimaliseerd voor snelle queryresultaten. Het opnamebatchbeleid kan worden ingesteld voor databases of tabellen. Standaard is de maximale batchwaarde 5 minuten, 1000 items of een totale grootte van 1 GB. De gegevensgroottelimiet voor een opdracht voor batchopname is 4 GB.
Streamingopname is doorlopende gegevensopname van een streamingbron. Streamingopname maakt bijna realtime latentie mogelijk voor kleine gegevenssets per tabel. Gegevens worden in eerste instantie opgenomen in het rijarchief en vervolgens verplaatst naar gebieden van het kolomarchief.
Opnamemethoden en hulpprogramma's
Azure Synapse Data Explorer ondersteunt verschillende opnamemethoden, elk met een eigen doelscenario. Deze methoden omvatten opnamehulpprogramma's, connectors en invoegtoepassingen voor diverse services, beheerde pijplijnen, programmatische opname met behulp van SDK's en directe toegang tot opname.
Opname met behulp van beheerde pijplijnen
Voor organisaties die beheer (beperking, nieuwe pogingen, monitors, waarschuwingen en meer) willen laten uitvoeren door een externe service, is het gebruik van een connector waarschijnlijk de meest geschikte oplossing. Opname in de wachtrij is geschikt voor grote gegevensvolumes. Azure Synapse Data Explorer ondersteunt de volgende Azure-pijplijnen:
- Event Hub: een pijplijn waarmee gebeurtenissen van services naar Azure Synapse Data Explorer worden overgedragen. Zie Gegevens van Event Hub opnemen in Azure Synapse Data Explorer voor meer informatie.
- Synapse-pijplijnen: een volledig beheerde gegevensintegratieservice voor analytische workloads in Synapse-pijplijnen maakt verbinding met meer dan 90 ondersteunde bronnen om efficiënte en tolerante gegevensoverdracht te bieden. Synapse-pijplijnen bereidt, transformeert en verrijkt gegevens om inzichten te geven die op verschillende manieren kunnen worden bewaakt. Deze service kan worden gebruikt als een eenmalige oplossing, op een periodieke tijdlijn of worden geactiveerd door specifieke gebeurtenissen.
Programmatische opname met behulp van SDK's
Azure Synapse Data Explorer biedt SDK's die kunnen worden gebruikt voor query- en gegevensopname. Programmatische opname is geoptimaliseerd voor het verminderen van opnamekosten (COG's), door opslagtransacties tijdens en na het opnameproces te minimaliseren.
Voordat u begint, gebruikt u de volgende stappen om de eindpunten van de Data Explorer-pool op te halen voor het configureren van programmatische opname.
Selecteer in Synapse Studio in het linkerdeelvenster Beheren>Data Explorer pools.
Selecteer de Data Explorer groep die u wilt gebruiken om de details ervan weer te geven.
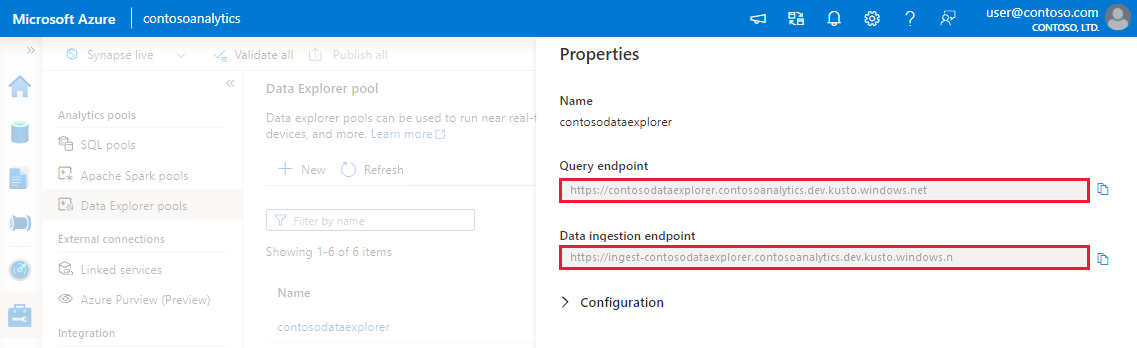
Noteer de eindpunten Query en Gegevensopname. Gebruik het eindpunt Query als het cluster bij het configureren van verbindingen met uw Data Explorer-pool. Wanneer u SDK's configureert voor gegevensopname, gebruikt u het eindpunt voor gegevensopname.
Beschikbare SDK's en opensource-projecten
Hulpprogramma's
- Opname met één klik: hiermee kunt u snel gegevens opnemen door tabellen te maken en aan te passen uit een breed scala aan brontypen. Opname met één klik suggereert automatisch tabellen en toewijzingsstructuren op basis van de gegevensbron in Azure Synapse Data Explorer. Opname met één klik kan worden gebruikt voor eenmalige opname of voor het definiëren van continue opname via Event Grid op de container waarin de gegevens zijn opgenomen.
opdrachten voor opname Kusto-querytaal
Er zijn een aantal methoden waarmee gegevens rechtstreeks in de engine kunnen worden opgenomen door Kusto-querytaal (KQL)-opdrachten. Omdat deze methode de Gegevensbeheer-services omzeilt, is deze alleen geschikt voor verkennen en prototypen. Gebruik deze methode niet in productie- of scenario's met grote volumes.
Inline-opname: een besturingsopdracht .inline opnemen wordt verzonden naar de engine, waarbij de gegevens die moeten worden opgenomen, deel uitmaken van de opdrachttekst zelf. Deze methode is bedoeld voor geïmproviseerde testdoeleinden.
Opnemen uit query: een besturingsopdracht .set, .append, .set-or-append of .set-or-replace wordt verzonden naar de engine, waarbij de gegevens indirect worden opgegeven als de resultaten van een query of een opdracht.
Opnemen uit opslag (pull): er wordt een besturingsopdracht .ingest in verzonden naar de engine, waarbij de gegevens zijn opgeslagen in een externe opslag (bijvoorbeeld Azure Blob Storage) die toegankelijk zijn voor de engine en waarnaar wordt verwezen door de opdracht .
Zie Analyseren met Data Explorer voor een voorbeeld van het gebruik van opdrachten voor opnamebeheer.
Opnameproces
Nadat u de meest geschikte opnamemethode voor uw behoeften hebt gekozen, voert u de volgende stappen uit:
Bewaarbeleid instellen
Gegevens die worden opgenomen in een tabel in Azure Synapse Data Explorer zijn onderhevig aan het effectieve bewaarbeleid van de tabel. Tenzij expliciet bewaarbeleid voor een tabel is ingesteld, wordt het geldende bewaarbeleid afgeleid van het bewaarbeleid van de database. Dynamische retentie is een functie van clustergrootte en uw bewaarbeleid. Als u meer gegevens opneemt dan er ruimte beschikbaar is, wordt de eerste in de gegevens gedwongen tot koude retentie.
Zorg ervoor dat het bewaarbeleid van de database geschikt is voor uw behoeften. Als dat niet het geval is, overschrijft u het expliciet op tabelniveau. Zie bewaarbeleid voor meer informatie.
Een tabel maken
Als u gegevens wilt opnemen, moet u van tevoren een tabel maken. Gebruik een van de volgende opties:
Maak een tabel met een opdracht. Zie Analyseren met Data Explorer voor een voorbeeld van het gebruik van de opdracht Een tabel maken.
Maak een tabel met behulp van Opname met één klik.
Notitie
Als een record onvolledig is of een veld niet kan worden geparseerd als het vereiste gegevenstype, worden de bijbehorende tabelkolommen gevuld met null-waarden.
Schematoewijzing maken
Met schematoewijzing kunt u brongegevensvelden binden aan doeltabelkolommen. Met toewijzing kunt u gegevens uit verschillende bronnen in dezelfde tabel opnemen op basis van de gedefinieerde kenmerken. Verschillende typen toewijzingen worden ondersteund, zowel rijgeoriënteerd (CSV, JSON en AVRO) als kolomgeoriënteerd (Parquet). In de meeste methoden kunnen toewijzingen ook vooraf worden gemaakt in de tabel en waarnaar wordt verwezen vanuit de opdrachtparameter ingest.
Updatebeleid instellen (optioneel)
Sommige toewijzingen van gegevensindelingen (Parquet, JSON en Avro) ondersteunen eenvoudige en nuttige opnametijdtransformaties. Wanneer voor het scenario complexere verwerking tijdens opname is vereist, gebruikt u updatebeleid, waarmee eenvoudige verwerking mogelijk is met behulp van Kusto-querytaal-opdrachten. Het updatebeleid voert automatisch extracties en transformaties uit op opgenomen gegevens in de oorspronkelijke tabel en neemt de resulterende gegevens op in een of meer doeltabellen. Stel uw updatebeleid in.
Volgende stappen
Feedback
Binnenkort: Gedurende 2024 worden GitHub Issues uitgefaseerd als het feedbackmechanisme voor inhoud. Dit wordt vervangen door een nieuw feedbacksysteem. Ga voor meer informatie naar: https://aka.ms/ContentUserFeedback.
Feedback verzenden en bekijken voor