Quickstart: Een nieuwe serverloze Apache Spark-pool maken met behulp van Azure Portal
Azure Synapse Analytics biedt diverse analyse-engines waarmee u uw gegevens kunt opnemen, transformeren, modelleren, analyseren en distribueren. Een Apache Spark-pool biedt opensource rekenmogelijkheden voor big data. Nadat u een Apache Spark-pool in uw Synapse-werkruimte hebt gemaakt, kunnen gegevens worden geladen, gemodelleerd, verwerkt en gedistribueerd voor sneller analyse-inzicht.
In deze quickstart leert u hoe u een Apache Spark-pool in een Synapse-werkruimte kunt maken met behulp van de Azure-portal.
Belangrijk
Spark-instanties worden pro rato per minuut gefactureerd, ongeacht of u ze wel of niet gebruikt. Zorg er daarom voor dat u de Spark-instantie afsluit wanneer u deze niet meer nodig hebt of stel een korte time-out in. Zie voor meer informatie de sectie Resources opschonen van dit artikel.
Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint.
Vereisten
- U hebt een Azure-abonnement nodig. Maak indien nodig een gratis Azure-account
- U gebruikt de Synapse-werkruimte.
Meld u aan bij Azure Portal
Meld u aan bij Azure Portal
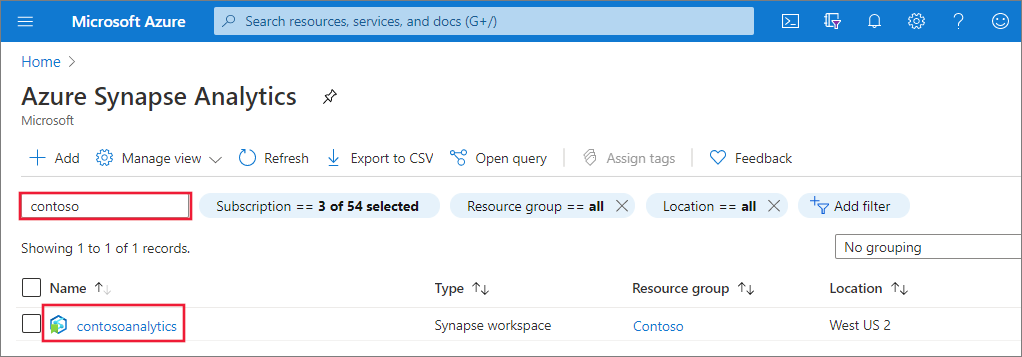
Navigeer naar de Synapse-werkruimte
Navigeer naar de Synapse-werkruimte waar de Apache Spark-pool wordt gemaakt door de servicenaam (of de resourcenaam) rechtstreeks in de zoekbalk te typen.
Typ in de lijst met werkruimten de naam (of een deel van de naam) van de werkruimte die u wilt openen. In dit voorbeeld gebruiken we een werkruimte met de naam contosoanalytics.


Nieuwe Apache Spark-pool maken
Belangrijk
Azure Synapse Runtime voor Apache Spark 2.4 is afgeschaft en wordt officieel niet ondersteund sinds september 2023. Gezien Spark 3.1 en Spark 3.2 ook het einde van de ondersteuning worden aangekondigd, raden we klanten aan om te migreren naar Spark 3.3.
Selecteer in de Synapse-werkruimte waar u de Apache Spark-pool wilt maken de opdracht Nieuwe Apache Spark-pool in de bovenste balk.

Voer de volgende gegevens in op het tabblad Basisinformatie:
Instelling Voorgestelde waarde Beschrijving Naam van Apache Spark-pool Een geldige poolnaam, zoals contososparkDit is de naam die de Apache Spark-pool krijgt. Knooppuntgrootte Klein (4 vCPU / 32 GB) Stel dit in op de kleinste grootte om de kosten voor deze quickstart te verlagen Automatisch schalen Uitgeschakeld Automatisch schalen voor deze quickstart is niet vereist Aantal knooppunten 5 Gebruik een kleine grootte om de kosten voor deze quickstart te beperken 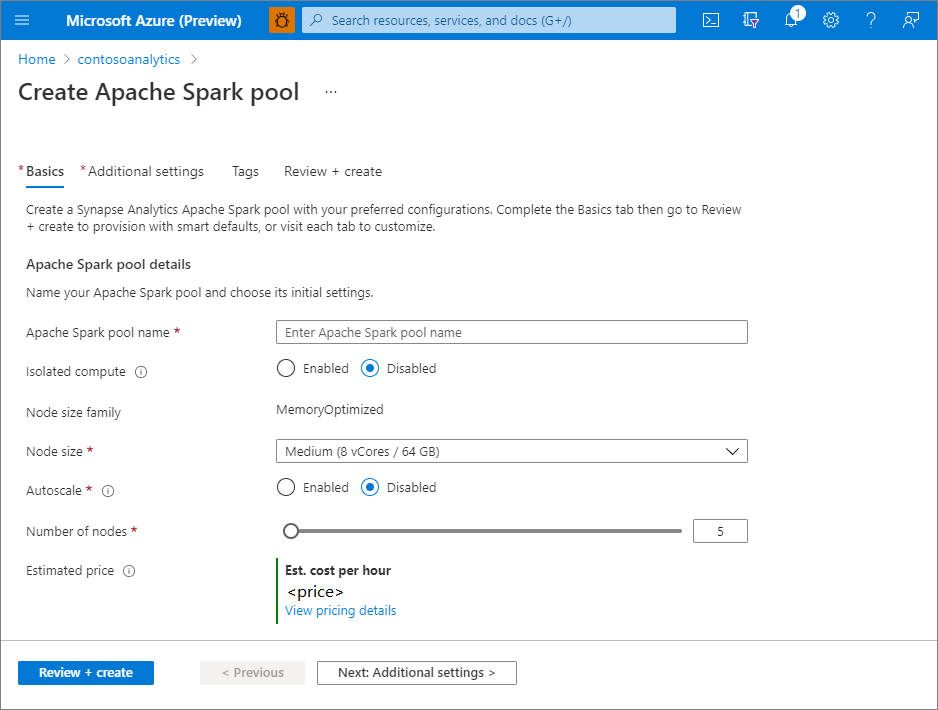
Belangrijk
Er zijn specifieke beperkingen voor de namen die Apache Spark-pools kunnen gebruiken. Namen mogen alleen letters of cijfers bevatten, moeten uit maximaal 15 tekens bestaan, moeten beginnen met een letter, mogen geen gereserveerde woorden bevatten en moeten uniek zijn in de werkruimte.
Selecteer Volgende: extra instellingen en controleer de standaardinstellingen. Wijzig geen standaardinstellingen.

Volgende: tags selecteren. Overweeg het gebruik van Azure-tags. Bijvoorbeeld de tag 'Eigenaar' of 'CreatedBy' om te bepalen wie de resource heeft gemaakt en de tag 'Omgeving' om te bepalen of deze resource zich in Productie, Ontwikkeling, enzovoort bevindt. Zie Uw naamgevings- en tagstrategie voor Azure-resources ontwikkelen voor meer informatie.

Selecteer Controleren + maken.
Zorg ervoor dat de gegevens juist zijn en zijn gebaseerd op wat eerder is ingevoerd en selecteer Maken.

Op dit punt wordt de stroom voor de resource-inrichting gestart en het wordt aangegeven zodra deze klaar is.

Als u nadat het inrichten is voltooid weer naar de werkruimte gaat, wordt hier een nieuwe vermelding voor de zojuist gemaakte Apache Spark-pool weergegeven.

Op dit moment worden er geen resources uitgevoerd, worden er geen kosten in rekening gebracht voor Spark, u hebt metagegevens gemaakt over de Spark-exemplaren die u wilt maken.







Resources opschonen
Met de volgende stappen verwijdert u de Apache Spark-pool uit de werkruimte.
Waarschuwing
Als u een Apache Spark-pool verwijdert, wordt de analyse-engine uit de werkruimte verwijderd. Het is niet langer mogelijk om verbinding te maken met de pool en alle query's, pijplijnen en notebooks die deze Apache Spark-pool gebruiken, werken niet meer.
Als u de Apache Spark-pool wilt verwijderen, voert u de volgende stappen uit:
- Navigeer naar het deelvenster Apache Spark-pools in de werkruimte.
- Selecteer de Apache Spark-pool die u wilt verwijderen (in dit geval contosospark).
- Selecteer Verwijderen.

- Bevestig de verwijdering en selecteer de knop Verwijderen .

- Wanneer het proces is voltooid, wordt de Apache Spark-pool niet meer weergegeven in de werkruimteresources.
