Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of mappen te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen om mappen te wijzigen.
Tip
Microsoft Fabric Data Warehouse is een relationeel warehouse op ondernemingsniveau op data lake-basis, met een architectuur die klaar is voor de toekomst, ingebouwde AI en nieuwe functies. Als u nieuw bent in gegevensopslag, begin dan met Fabric Data Warehouse. Bestaande dediceerde SQL-poolworkloads kunnen upgraden naar Fabric voor toegang tot nieuwe mogelijkheden in data science, realtime analyses en rapportage.
Met de functie OPENROWSET(BULK...) kunt u toegang krijgen tot bestanden in Azure Storage.
OPENROWSET functie leest inhoud van een externe gegevensbron (bijvoorbeeld bestand) en retourneert de inhoud als een set rijen. Binnen de serverloze SQL-poolresource wordt de OPENROWSET-bulkrijsetprovider geopend door de functie OPENROWSET aan te roepen en de optie BULK op te geven.
Er kan naar de functie worden verwezen in de FROM clausule van een query alsof het een tabelnaam betreft OPENROWSET. Het biedt ondersteuning voor bulkbewerkingen via een ingebouwde BULK-provider waarmee gegevens uit een bestand kunnen worden gelezen en geretourneerd als een rijenset.
Opmerking
De functie OPENROWSET wordt niet ondersteund in een toegewezen SQL-pool.
Gegevensbron
De functie OPENROWSET in Synapse SQL leest de inhoud van de bestanden uit een gegevensbron. De gegevensbron is een Azure opslagaccount en kan expliciet worden verwezen in de functie OPENROWSET of dynamisch worden afgeleid van de URL van de bestanden die u wilt lezen.
De OPENROWSET functie kan eventueel een DATA_SOURCE parameter bevatten om de gegevensbron op te geven die bestanden bevat.
OPENROWSETzonderDATA_SOURCEkan worden gebruikt om de inhoud van de bestanden rechtstreeks te lezen vanaf de URL-locatie die is opgegeven alsBULKoptie:SELECT * FROM OPENROWSET(BULK 'http://<storage account>.dfs.core.windows.net/container/folder/*.parquet', FORMAT = 'PARQUET') AS [file]
Dit is een snelle en eenvoudige manier om de inhoud van de bestanden te lezen zonder vooraf te configureren. Met deze optie kunt u de basisverificatieoptie gebruiken voor toegang tot de opslag (Microsoft Entra passthrough voor Microsoft Entra aanmeldingen en SAS-token voor SQL-aanmeldingen).
OPENROWSETmetDATA_SOURCEkan worden gebruikt voor toegang tot bestanden in het opgegeven opslagaccount:SELECT * FROM OPENROWSET(BULK '/folder/*.parquet', DATA_SOURCE='storage', --> Root URL is in LOCATION of DATA SOURCE FORMAT = 'PARQUET') AS [file]Met deze optie kunt u de locatie van het opslagaccount in de gegevensbron configureren en de verificatiemethode opgeven die moet worden gebruikt voor toegang tot opslag.
Belangrijk
OPENROWSETzonderDATA_SOURCEbiedt een snelle en eenvoudige manier om toegang te krijgen tot de opslagbestanden, maar biedt beperkte verificatieopties. Als voorbeeld hebben Microsoft Entra principals alleen toegang tot bestanden met hun Microsoft Entra identiteit of openbaar beschikbare bestanden. Als u krachtigere verificatieopties nodig hebt, gebruiktDATA_SOURCEu de optie en definieert u de referenties die u wilt gebruiken voor toegang tot opslag.
Beveiliging
Een databasegebruiker moet gemachtigd zijn ADMINISTER BULK OPERATIONS om de OPENROWSET functie te kunnen gebruiken.
De opslagbeheerder moet een gebruiker ook toegang geven tot de bestanden door een geldig SAS-token op te geven of Microsoft Entra principal toegang te geven tot opslagbestanden. Meer informatie over toegangsbeheer voor opslag vindt u in dit artikel.
OPENROWSET gebruik de volgende regels om te bepalen hoe verificatie bij opslag moet worden uitgevoerd:
- In
OPENROWSET, bij afwezigheid vanDATA_SOURCE, is het authenticatiemechanisme afhankelijk van het type aanroeper.- Elke gebruiker kan
OPENROWSETzonderDATA_SOURCEgebruiken om openbaar beschikbare bestanden op Azure-opslag te lezen. - Microsoft Entra aanmeldingen hebben toegang tot beveiligde bestanden met hun eigen Microsoft Entra identiteit als Azure opslag de Microsoft Entra gebruiker toegang geeft tot onderliggende bestanden (bijvoorbeeld als de beller
Storage Readermachtiging heeft voor Azure-opslag). - SQL-aanmeldingen kunnen ook
OPENROWSETgebruiken zonderDATA_SOURCEtoegang te verkrijgen tot openbaar beschikbare bestanden, bestanden die zijn beveiligd met behulp van een SAS-token of een Beheerde Identiteit van de Synapse-werkruimte. U moet een serveromvattende referentie maken om toegang tot opslagbestanden te geven.
- Elke gebruiker kan
- In
OPENROWSETcombinatie metDATA_SOURCEverificatiemechanisme wordt gedefinieerd in databasereferenties die zijn toegewezen aan de gegevensbron waarnaar wordt verwezen. Met deze optie kunt u toegang krijgen tot openbaar beschikbare opslag of toegang krijgen tot opslag met behulp van sas-token, beheerde identiteit van werkruimte of Microsoft Entra identiteit van aanroeper (als aanroeper Microsoft Entra principal is). AlsDATA_SOURCEverwijst naar Azure opslag die niet openbaar is, moet u referenties voor databasebereik maken en ernaar verwijzen inDATA SOURCEom toegang tot opslagbestanden toe te staan.
Aanroeper moet REFERENCES toestemming hebben voor gebruik van het referentiegegeven om te authenticeren naar opslag.
Syntax
--OPENROWSET syntax for reading Parquet or Delta Lake files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT= ['PARQUET' | 'DELTA'] }
)
[WITH ( {'column_name' 'column_type' }) ]
[AS] table_alias(column_alias,...n)
--OPENROWSET syntax for reading delimited text files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT = 'CSV'
[ <bulk_options> ]
[ , <reject_options> ] }
)
WITH ( {'column_name' 'column_type' [ 'column_ordinal' | 'json_path'] })
[AS] table_alias(column_alias,...n)
<bulk_options> ::=
[ , FIELDTERMINATOR = 'char' ]
[ , ROWTERMINATOR = 'char' ]
[ , ESCAPECHAR = 'char' ]
[ , FIRSTROW = 'first_row' ]
[ , FIELDQUOTE = 'quote_characters' ]
[ , DATA_COMPRESSION = 'data_compression_method' ]
[ , PARSER_VERSION = 'parser_version' ]
[ , HEADER_ROW = { TRUE | FALSE } ]
[ , DATAFILETYPE = { 'char' | 'widechar' } ]
[ , CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' } ]
[ , ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}' ]
<reject_options> ::=
{
| MAXERRORS = reject_value,
| ERRORFILE_DATA_SOURCE = <data source name>,
| ERRORFILE_LOCATION = '/REJECT_Directory'
}
Argumenten
U hebt drie opties voor invoerbestanden die de doelgegevens bevatten voor het uitvoeren van query's. Geldige waarden zijn:
'CSV': bevat een tekstbestand met scheidingstekens voor rijen en kolommen. Elk teken kan worden gebruikt als veldscheidingsteken, zoals TSV: FIELDTERMINATOR = tab.
'PARQUET' - Binair bestand in Parquet-formaat.
'DELTA': een set Parquet-bestanden die zijn georganiseerd in de Delta Lake (preview)-indeling.
Waarden met lege spaties zijn niet geldig. CSV is bijvoorbeeld geen geldige waarde.
'unstructured_data_path'
Het unstructured_data_path waarmee een pad naar de gegevens wordt vastgesteld, kan een absoluut of relatief pad zijn:
- Absoluut pad in de indeling
\<prefix>://\<storage_account_path>/\<storage_path>stelt een gebruiker in staat om de bestanden rechtstreeks te lezen. - Relatief pad in de indeling
<storage_path>dat moet worden gebruikt met deDATA_SOURCEparameter en beschrijft het bestandspatroon binnen de locatie <storage_account_path> die is gedefinieerd inEXTERNAL DATA SOURCE.
Hieronder vindt u de relevante <waarden voor het opslagaccountpad> die worden gekoppeld aan uw specifieke externe gegevensbron.
| Externe gegevensbron | Prefix | Pad van opslagaccount |
|---|---|---|
| Azure Blob Storage (Microsoft's oplossing voor objectopslag in de cloud) | http[s] | < >storage_account.blob.core.windows.net/path/file |
| Azure Blob Storage (Microsoft's oplossing voor objectopslag in de cloud) | wasb[s] | <container>@<storage_account.blob.core.windows.net/path/file> |
| Azure Data Lake Store Gen1 | http[s] | < >storage_account.azuredatalakestore.net/webhdfs/v1 |
| Azure Data Lake Store Gen2 | http[s] | < >storage_account.dfs.core.windows.net/path/file |
| Azure Data Lake Store Gen2 | abfs[s] | <file_system>@<account_name>.dfs.core.windows.net/path/file |
'<storage_path>'
Hiermee geeft u een pad in uw opslag op dat verwijst naar de map of het bestand dat u wilt lezen. Als het pad verwijst naar een container of map, worden alle bestanden gelezen uit die specifieke container of map. Bestanden in submappen worden niet opgenomen.
U kunt jokertekens gebruiken om meerdere bestanden of mappen te targeten. Het gebruik van meerdere niet-consecutieve jokertekens is toegestaan.
Hieronder ziet u een voorbeeld dat alle CSV-bestanden leest die beginnen met populatie uit alle mappen die beginnen met /csv/population:
https://sqlondemandstorage.blob.core.windows.net/csv/population*/population*.csv
Als u de unstructured_data_path opgeeft als map, haalt een serverloze SQL-poolquery bestanden op uit die map.
U kunt serverloze SQL-pool instrueren om mappen te doorlopen door /* op te geven aan het einde van het pad, zoals in voorbeeld: https://sqlondemandstorage.blob.core.windows.net/csv/population/**
Opmerking
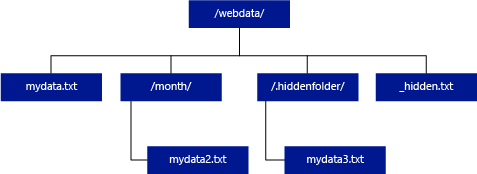
In tegenstelling tot Hadoop en PolyBase retourneert een serverloze SQL-pool geen submappen, tenzij u /** opgeeft aan het einde van het pad. Net als Hadoop en PolyBase worden er geen bestanden geretourneerd waarvoor de bestandsnaam begint met een onderstreping (_) of een punt (.).
In het onderstaande voorbeeld retourneert een serverloze SQL-poolquery rijen uit mydata.txt indien de unstructured_data_path=https://mystorageaccount.dfs.core.windows.net/webdata/. Het retourneert geen mydata2.txt en mydata3.txt omdat deze zich in een submap bevinden.
[WITH ( {'column_name' 'column_type' [ 'column_ordinal'] }) ]
Met de WITH-component kunt u kolommen opgeven die u wilt lezen uit bestanden.
Als u alle kolommen wilt lezen, geeft u kolomnamen en de bijbehorende gegevenstypen op voor CSV-gegevensbestanden. Als u een subset van kolommen wilt, gebruikt u ordinaalnummers om de kolommen te kiezen uit de oorspronkelijke gegevensbestanden op basis van ordinaliteit. Kolommen worden gebonden door de ordinale aanduiding. Als HEADER_ROW = TRUE wordt gebruikt, wordt het kolombindingsproces uitgevoerd via kolomnaam in plaats van door ordinale positie.
Tip
U kunt ook de WITH-component weglaten voor CSV-bestanden. Gegevenstypen worden automatisch afgeleid van bestandsinhoud. U kunt HEADER_ROW argument gebruiken om het bestaan van veldnamenrij op te geven in welk geval kolomnamen worden gelezen uit de veldnamenrij. Controleer de automatische schemadetectie voor meer informatie.
Geef voor Parquet- of Delta Lake-bestanden kolomnamen op die overeenkomen met de kolomnamen in de oorspronkelijke gegevensbestanden. Kolommen worden afhankelijk van de naam en zijn hoofdlettergevoelig. Als de WITH-component wordt weggelaten, worden alle kolommen uit Parquet-bestanden geretourneerd.
Belangrijk
Kolomnamen in Parquet- en Delta Lake-bestanden zijn hoofdlettergevoelig. Als u de kolomnaam opgeeft met een andere hoofdletter dan de kolomnaam in de bestanden, worden de
NULLwaarden voor die kolom geretourneerd.
column_name = Naam voor de uitvoerkolom. Indien opgegeven, overschrijft deze naam de kolomnaam in het bronbestand en de kolomnaam die is opgegeven in het JSON-pad als er een is. Als json_path niet is opgegeven, wordt deze automatisch toegevoegd als $.column_name. Controleer json_path argument op gedrag.
column_type = Gegevenstype voor de uitvoerkolom. De impliciete conversie van het gegevenstype vindt hier plaats.
column_ordinal = rangnummer van de kolom in de bronbestand(en). Dit argument wordt genegeerd voor Parquet-bestanden, omdat binding wordt uitgevoerd op naam. In het volgende voorbeeld wordt alleen een tweede kolom uit een CSV-bestand geretourneerd:
WITH (
--[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2 2
--[year] smallint,
--[population] bigint
)
json_path = JSON-padexpressie naar kolom of geneste eigenschap. De standaardpadmodus is lax.
Opmerking
In de strikte modus zal de query met een fout mislukken als het opgegeven pad niet bestaat. De query in de lax-modus slaagt en de JSON-padexpressie resulteert in NULL.
<bulk_options>
FIELDTERMINATOR ='field_terminator'
Hiermee specificeert u de veldaanduiding die moet worden gebruikt. Het standaardveldeindteken is een komma (",").
ROWTERMINATOR ='row_terminator'`
Geeft het rijeindteken aan dat moet worden gebruikt. Als er geen rijeindteken is opgegeven, wordt een van de standaardeindtekens gebruikt. Standaardeindtekens voor PARSER_VERSION = '1,0' zijn \r\n, \n en \r. Standaardeindtekens voor PARSER_VERSION = '2,0' zijn \r\n en \n.
Opmerking
Wanneer u PARSER_VERSION='1.0' gebruikt en \n (nieuwe regel) opgeeft als het rijeindteken, wordt deze automatisch voorafgegaan door een \r (regelterugloopteken), wat leidt tot een rijeindteken van \r\n.
ESCAPE_CHAR = 'char'
Hiermee geeft u het teken in het bestand dat wordt gebruikt om zichzelf te ontsnappen en alle scheidingstekens in het bestand. Als het escape-teken wordt gevolgd door een andere waarde dan het teken zelf, of een van de scheidingstekens, wordt het escape-teken genegeerd bij het lezen van de waarde.
De ESCAPECHAR-parameter wordt toegepast, ongeacht of de FIELDQUOTE wel of niet is ingeschakeld. Het wordt niet gebruikt om het aanhalingsteken te maskeren. Het aanhalingsteken moet worden voorafgegaan door een ander aanhalingsteken. Het aanhalingsteken kan alleen in de kolomwaarde voorkomen als de waarde is ingekapseld door aanhalingstekens.
FIRSTROW = 'first_row'
Hiermee geeft u het nummer op van de eerste rij die moet worden geladen. De standaardwaarde is 1 en geeft de eerste rij in het opgegeven gegevensbestand aan. De rijnummers worden bepaald door de rijeindtekens te tellen. FIRSTROW is gebaseerd op 1.
FIELDQUOTE = 'field_quote'
Hiermee geeft u een teken op dat wordt gebruikt als het aanhalingsteken in het CSV-bestand. Als dit niet is opgegeven, wordt het aanhalingsteken (") gebruikt.
DATA_COMPRESSION = "data_compression_method"
Specificeert de compressiemethode. Alleen ondersteund in PARSER_VERSION='1.0'. De volgende compressiemethode wordt ondersteund:
- GZIP
PARSER_VERSION = 'parser_version'
Hiermee specificeert u welke parser versie moet worden gebruikt bij het lezen van bestanden. Momenteel ondersteunde csv-parserversies zijn 1.0 en 2.0:
- PARSER_VERSION = '1,0'
- PARSER_VERSION = '2,0'
CSV-parserversie 1.0 is standaard en bevat uitgebreide functies. Versie 2.0 is gebouwd voor prestaties en biedt geen ondersteuning voor alle opties en coderingen.
Specificaties van CSV-parser-versie 1.0:
- De volgende opties worden niet ondersteund: HEADER_ROW.
- Standaardeindtekens zijn \r\n, \n en \r.
- Als u \n (nieuwe regel) opgeeft als het rijeindteken, wordt deze automatisch voorafgegaan door een \r (regelterugloopteken), wat resulteert in een rijeindteken van \r\n.
Details van CSV-parserversie 2.0:
- Niet alle gegevenstypen worden ondersteund.
- De maximale lengte van de tekenkolom is 8000.
- De maximale grootte van een rij is 8 MB.
- De volgende opties worden niet ondersteund: DATA_COMPRESSION.
- De lege tekenreeks tussen aanhalingstekens ("") wordt geïnterpreteerd als een lege tekenreeks.
- De optie DATEFORMAT SET wordt niet gehonoreerd.
- Ondersteunde indeling voor het gegevenstype DATE: JJJJ-MM-DD
- Ondersteunde indeling voor tijd-datatype: HH:MM:SS[.fractionele seconden]
- Ondersteunde indeling voor DATETIME2 gegevenstype: JJJJ-MM-DD UU:MM:SS[.fractionele seconden]
- Standaardeindtekens zijn \r\n en \n.
HEADER_ROW = { TRUE | FALSE }
Hiermee geeft u op of een CSV-bestand veldnamenrij bevat. De standaardinstelling FALSE. wordt ondersteund in PARSER_VERSION='2.0'. Als WAAR is, worden de kolomnamen gelezen uit de eerste rij volgens het argument FIRSTROW. Als TRUE is en het schema wordt gespecificeerd met WITH, vindt de binding van kolomnamen plaats op basis van kolomnaam in plaats van volgordeposities.
DATAFILETYPE = { 'char' | 'widechar' }
Hiermee geeft u codering op: char wordt gebruikt voor UTF8, widechar wordt gebruikt voor UTF16-bestanden.
CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' }
Hiermee geeft u de codepagina van de gegevens in het gegevensbestand. De standaardwaarde is 65001 (UTF-8-codering). Bekijk hier meer informatie over deze optie.
ROWSET_OPTIONS = {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}'
Met deze optie wordt de controle van bestandswijziging uitgeschakeld tijdens de uitvoering van de query en worden de bestanden gelezen die worden bijgewerkt terwijl de query wordt uitgevoerd. Dit is een handige optie om alleen-bijvoegen-bestanden te lezen die worden aangevuld terwijl de query wordt uitgevoerd. In de toevoegbare bestanden wordt de bestaande inhoud niet bijgewerkt en worden alleen nieuwe rijen toegevoegd. Daarom wordt de kans op verkeerde resultaten geminimaliseerd in vergelijking met de bijwerkbare bestanden. Met deze optie kunt u mogelijk de vaak toegevoegde bestanden lezen zonder de fouten te verwerken. Zie meer informatie in de sectie toevoegbare CSV-bestanden opvragen .
Opties voor weigeren
Opmerking
De functie Afgewezen rijen bevindt zich in openbare proefversie. Houd er rekening mee dat de functie geweigerde rijen werkt voor tekstbestanden met scheidingstekens en PARSER_VERSION 1.0.
U kunt geweigerde parameters opgeven die bepalen hoe de service vuile records verwerkt die worden opgehaald uit de externe gegevensbron. Een gegevensrecord wordt beschouwd als 'vuil' als de werkelijke gegevenstypen niet overeenkomen met de kolomdefinities van de externe tabel.
Wanneer u geen opties voor weigeren opgeeft of wijzigt, gebruikt de service standaardwaarden. Service gebruikt de weigeringsopties om het aantal rijen te bepalen dat kan worden geweigerd voordat de werkelijke query mislukt. De query retourneert (gedeeltelijke) resultaten totdat de drempelwaarde voor weigeren is overschreden. Het mislukt vervolgens met het juiste foutbericht.
MAXERRORS = reject_value
Hiermee geeft u het aantal rijen op dat kan worden geweigerd voordat de query mislukt. MAXERRORS moet een geheel getal tussen 0 en 2.147.483.647 zijn.
ERRORFILE_DATA_SOURCE = gegevensbron
Hiermee geeft u de gegevensbron op waarbij geweigerde rijen en het bijbehorende foutbestand moeten worden geschreven.
ERRORFILE_LOCATION = Directorylocatie
Hiermee specificeert u de map binnen de DATA_SOURCE, of ERROR_FILE_DATASOURCE indien opgegeven, waarin de geweigerde rijen en het bijbehorende foutbestand moeten worden geschreven. Als het opgegeven pad niet bestaat, maakt de service er een namens u. Er wordt een onderliggende map gemaakt met de naam "rejectedrows". Het speciale teken "" zorgt ervoor dat de map wordt beschermd voor andere gegevensverwerking, tenzij deze expliciet wordt genoemd in de locatieparameter. In deze map is er een map gemaakt op basis van het tijdstip van het indienen van de workload volgens het formaat YearMonthDay_HourMinuteSecond_StatementID (bijvoorbeeld 20180330-173205-559EE7D2-196D-400A-806D-3BF5D007F891). U kunt de verklarings-ID gebruiken om de map te correleren met de query die deze heeft voortgebracht. In deze map worden twee bestanden geschreven: error.json bestand en het gegevensbestand.
error.json bestand bevat json-matrix met fouten met betrekking tot geweigerde rijen. Elk element dat een fout vertegenwoordigt, bevat de volgende kenmerken:
| Attribuut | Beschrijving |
|---|---|
| Fout | Reden waarom rij wordt geweigerd. |
| Rij | Afgekeurd ordinaal rijnummer in het bestand. |
| Kolom | Afgekeurd kolomnummer. |
| Waarde | Geweigerde kolomwaarde. Als de waarde groter is dan 100 tekens, worden alleen de eerste 100 tekens weergegeven. |
| Bestand | Pad naar het bestand waartoe die rij behoort. |
Snelle tekstparsering met delimiters
Er zijn twee versies van tekstparser met scheidingstekens die u kunt gebruiken. CSV-parserversie 1.0 is standaard en bevat uitgebreide functies, terwijl parserversie 2.0 is gebouwd voor prestaties. Prestatieverbetering in parser 2.0 is afkomstig van geavanceerde parseringstechnieken en multithreading. Het verschil in snelheid zal groter zijn naarmate de bestandsgrootte toeneemt.
Automatische schemadetectie
U kunt eenvoudig query's uitvoeren op zowel CSV- als Parquet-bestanden zonder dat u het schema kent of opgeeft door de WITH-component weg te laten. Kolomnamen en gegevenstypen worden afgeleid uit bestanden.
Parquet-bestanden bevatten kolommetagegevens, die worden gelezen, typetoewijzingen zijn te vinden in typetoewijzingen voor Parquet. Controleer het lezen van Parquet-bestanden zonder het schema voor voorbeelden op te geven .
Voor de CSV-bestanden kunnen kolomnamen worden gelezen uit de veldnamenrij. U kunt opgeven of de veldnamenrij bestaat met behulp van HEADER_ROW argument. Als HEADER_ROW = ONWAAR, worden algemene kolomnamen gebruikt: C1, C2, ... Cn waarbij n het aantal kolommen in het bestand is. Gegevenstypen worden afgeleid van de eerste 100 gegevensrijen. Controleer het lezen van CSV-bestanden zonder het schema voor voorbeelden op te geven .
Houd er rekening mee dat als u meerdere bestanden tegelijkertijd leest, het schema wordt afgeleid van het eerste bestand dat de service uit de opslag verkrijgt. Dit kan betekenen dat sommige van de verwachte kolommen worden weggelaten, allemaal omdat het bestand dat door de service wordt gebruikt om het schema te definiëren deze kolommen niet bevat. In dat geval gebruikt u de OPENROWSET WITH-clause.
Belangrijk
Er zijn gevallen waarin het juiste gegevenstype niet kan worden afgeleid als gevolg van gebrek aan informatie en in plaats daarvan wordt het grotere gegevenstype gebruikt. Dit zorgt voor extra prestatiebelasting en is vooral belangrijk voor tekstkolommen die als varchar(8000) worden afgeleid. Voor optimale prestaties controleert u de uitgestelde gegevenstypen en gebruikt u de juiste gegevenstypen.
Typetoewijzing voor Parquet
Parquet- en Delta Lake-bestanden bevatten typebeschrijvingen voor elke kolom. In de volgende tabel wordt beschreven hoe Parquet-typen worden toegewezen aan systeemeigen SQL-typen.
| Parquetsoort | Parquet-logisch type (aantekening) | SQL-gegevenstype |
|---|---|---|
| Booleaans | bit | |
| BINARY/BYTE_ARRAY | varbinary | |
| DUBBEL | float | |
| FLOAT | echt | |
| INT32 | int | |
| INT64 | bigint | |
| INT96 | datetime2 | |
| FIXED_LEN_BYTE_ARRAY | binary | |
| Binair | UTF8 | varchar *(UTF8 collatie) |
| Binair | String | varchar *(UTF8-collatie) |
| BINARY | ENUM | varchar *(UTF8-collatie) |
| FIXED_LEN_BYTE_ARRAY | UUID | uniqueidentifier |
| BINARY | DECIMAL | decimaal |
| BINARY | JSON | varchar(8000) *(UTF8-collatie) |
| Binair | BSON | Niet ondersteund |
| FIXED_LEN_BYTE_ARRAY | DECIMAL | decimaal |
| Byte Array | interval | Niet ondersteund |
| INT32 | INT(8, true) | smallint |
| INT32 | INT(16, true) | smallint |
| INT32 | INT(32, true) | int |
| INT32 | INT(8, false) | tinyint |
| INT32 | INT(16, false) | int |
| INT32 | INT(32, false) | bigint |
| INT32 | DATUM | datum |
| INT32 | DECIMAL | decimaal |
| INT32 | TIJD (MILLISECONDEN) | tijd |
| INT64 | INT(64, true) | bigint |
| INT64 | INT(64, onwaar) | decimal(20,0) |
| INT64 | DECIMAL | decimaal |
| INT64 | TIJD (MICROS) | tijd |
| INT64 | TIJD (NANOSEC) | Niet ondersteund |
| INT64 | TIMESTAMP (genormaliseerd tot UTC) (MILLIS / MICROS) | datetime2 |
| INT64 | TIMESTAMP (niet genormaliseerd tot utc) (MILLIS/MICROS) | bigint: zorg ervoor dat u de waarde expliciet aanpast bigint met de tijdzone-offset voordat u deze converteert naar een datum/tijd-waarde. |
| INT64 | TIMESTAMP (NANOS) | Niet ondersteund |
| Complex type | LIJST | varchar(8000), geserialiseerd in JSON |
| Complex type | KAART | varchar(8000), geserialiseerd in JSON |
Voorbeelden
CSV-bestanden lezen zonder schema op te geven
In het volgende voorbeeld wordt een CSV-bestand met veldnamenrij gelezen zonder kolomnamen en gegevenstypen op te geven:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
HEADER_ROW = TRUE) as [r]
In het volgende voorbeeld wordt een CSV-bestand gelezen dat geen veldnamenrij bevat zonder kolomnamen en gegevenstypen op te geven:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0') as [r]
Parquet-bestanden lezen zonder schema op te geven
In het volgende voorbeeld worden alle kolommen van de eerste rij uit de gegevensset volkstelling geretourneerd, in Parquet-indeling en zonder kolomnamen en gegevenstypen op te geven:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
) AS [r]
Delta Lake-bestanden lezen zonder schema op te geven
In het volgende voorbeeld worden alle kolommen van de eerste rij uit de gegevensset volkstelling geretourneerd, in Delta Lake-indeling en zonder kolomnamen en gegevenstypen op te geven:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='DELTA'
) AS [r]
Specifieke kolommen uit CSV-bestand lezen
In het volgende voorbeeld worden slechts twee kolommen geretourneerd met rangnummer 1 en 4 uit de populatie*.csv bestanden. Omdat er geen koprij in de bestanden staat, begint met lezen vanaf de eerste regel.
SELECT
*
FROM OPENROWSET(
BULK 'https://sqlondemandstorage.blob.core.windows.net/csv/population/population*.csv',
FORMAT = 'CSV',
FIRSTROW = 1
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2 1,
[population] bigint 4
) AS [r]
Specifieke kolommen uit Parquet-bestand lezen
In het volgende voorbeeld worden slechts twee kolommen van de eerste rij uit de volkstellingsgegevensset geretourneerd, in Parquet-indeling.
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
[stateName] VARCHAR (50),
[population] bigint
) AS [r]
Kolommen opgeven met behulp van JSON-paden
In het volgende voorbeeld ziet u hoe u JSON-padexpressies in de WITH-component kunt gebruiken en het verschil laat zien tussen strikte en lax-padmodi:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
--lax path mode samples
[stateName] VARCHAR (50), -- this one works as column name casing is valid - it targets the same column as the next one
[stateName_explicit_path] VARCHAR (50) '$.stateName', -- this one works as column name casing is valid
[COUNTYNAME] VARCHAR (50), -- STATEname column will contain NULLs only because of wrong casing - it targets the same column as the next one
[countyName_explicit_path] VARCHAR (50) '$.COUNTYNAME', -- STATEname column will contain NULLS only because of wrong casing and default path mode being lax
--strict path mode samples
[population] bigint 'strict $.population' -- this one works as column name casing is valid
--,[population2] bigint 'strict $.POPULATION' -- this one fails because of wrong casing and strict path mode
)
AS [r]
Meerdere bestanden/mappen opgeven in BULK-pad
In het volgende voorbeeld ziet u hoe u meerdere bestands-/mappaden in bulkparameter kunt gebruiken:
SELECT
TOP 10 *
FROM
OPENROWSET(
BULK (
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2000/*.parquet',
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2010/*.parquet'
),
FORMAT='PARQUET'
)
AS [r]
Volgende stappen
Zie de quickstart voor querygegevensopslag voor meer voorbeelden en leer hoe u OPENROWSET kunt gebruiken om CSV-, PARQUET-, DELTA LAKE-, en JSON-bestanden te lezen. Controleer de aanbevolen procedures voor het bereiken van optimale prestaties. U kunt ook leren hoe u de resultaten van uw query opslaat in Azure Storage met behulp van CETAS.