Query's uitvoeren op Delta Lake-bestanden (v1) met behulp van een serverloze SQL-pool in Azure Synapse Analytics
In dit artikel leert u hoe u een query schrijft met behulp van een serverloze Synapse SQL-pool om Delta Lake-bestanden te lezen. Delta Lake is een opensource-opslaglaag die ACID-transacties (atomiciteit, consistentie, isolatie en duurzaamheid) naar Apache Spark- en big data-workloads brengt. Meer informatie vindt u in de video over het uitvoeren van query's op Delta Lake-tabellen.
Belangrijk
De serverloze SQL-pools kunnen een query uitvoeren op Delta Lake versie 1.0. De wijzigingen die zijn geïntroduceerd sinds de Delta Lake 1.2-versie , zoals het wijzigen van de naam van kolommen, worden niet ondersteund in serverloos. Als u de hogere versies van Delta gebruikt met verwijdervectoren, v2-controlepunten en andere, kunt u overwegen andere query-engine te gebruiken, zoals Microsoft Fabric SQL-eindpunt voor Lakehouses.
Met de serverloze SQL-pool in de Synapse-werkruimte kunt u de gegevens lezen die zijn opgeslagen in Delta Lake-indeling en deze aanbieden aan rapportagehulpprogramma's. Een serverloze SQL-pool kan Delta Lake-bestanden lezen die zijn gemaakt met Apache Spark, Azure Databricks of een andere producent van de Delta Lake-indeling.
Met Apache Spark-pools in Azure Synapse kunnen data engineers Delta Lake-bestanden wijzigen met behulp van Scala, PySpark en .NET. Serverloze SQL-pools helpen gegevensanalisten bij het maken van rapporten over Delta Lake-bestanden die zijn gemaakt door data engineers.
Belangrijk
Het uitvoeren van query's op Delta Lake-indeling met behulp van de serverloze SQL-pool is algemeen beschikbare functionaliteit. Het uitvoeren van query's op Spark Delta-tabellen bevindt zich echter nog steeds in de openbare preview en is niet gereed voor productie. Er zijn bekende problemen die kunnen optreden als u query's uitvoert op Delta-tabellen die zijn gemaakt met behulp van de Spark-pools. Bekijk de bekende problemen in de serverloze SQL-pool zelfondersteuning.
Quickstart-voorbeeld
Met de functie OPENROWSET kunt u de inhoud van Delta Lake-bestanden lezen door de URL naar uw hoofdmap op te geven.
De map Delta Lake lezen
De eenvoudigste manier om de inhoud van uw DELTA bestand te bekijken, is door de bestands-URL naar de functie OPENROWSET op te geven en de indeling op te geven DELTA . Als het bestand openbaar beschikbaar is of als uw Microsoft Entra-identiteit toegang heeft tot dit bestand, moet u de inhoud van het bestand kunnen zien met behulp van een query zoals in het volgende voorbeeld:
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'https://sqlondemandstorage.blob.core.windows.net/delta-lake/covid/',
FORMAT = 'delta') as rows;
Kolomnamen en gegevenstypen worden automatisch gelezen uit Delta Lake-bestanden. De OPENROWSET functie gebruikt aanbevolen schattingstypen zoals VARCHAR(1000) voor de tekenreekskolommen.
De URI in de OPENROWSET functie moet verwijzen naar de hoofdmap Delta Lake die een submap bevat met de naam _delta_log.
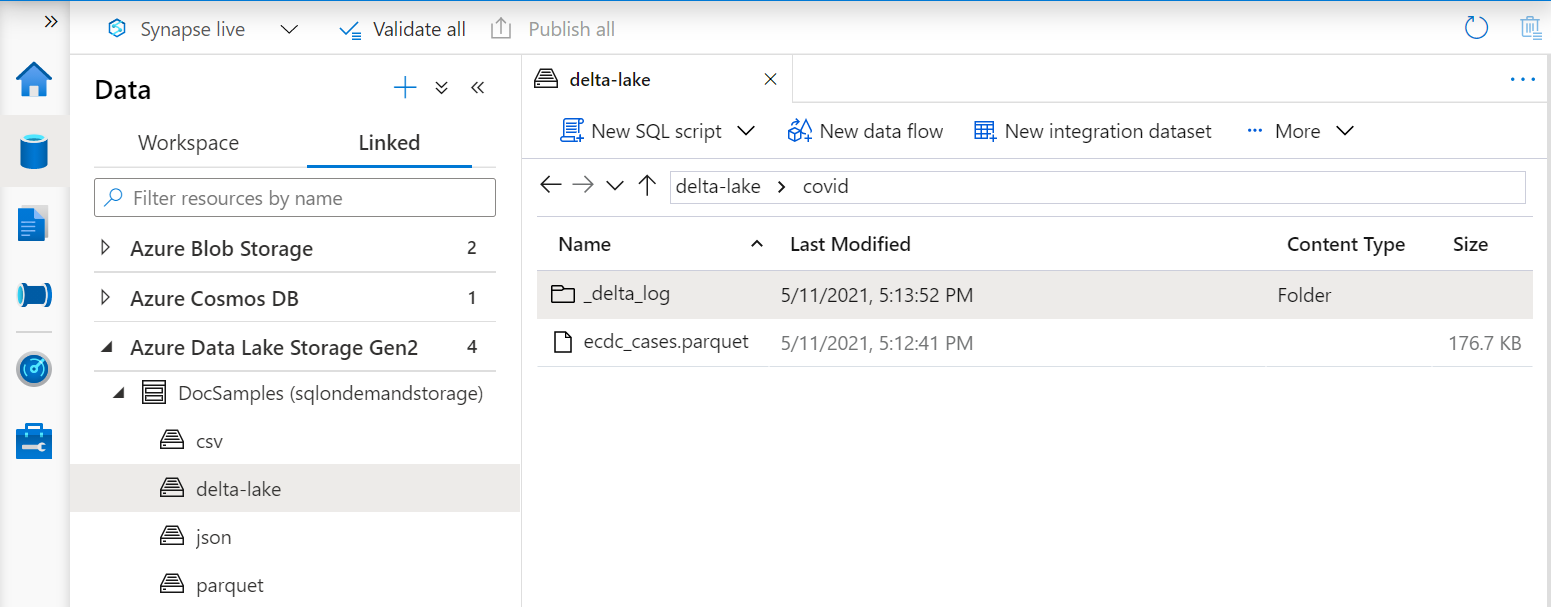
Als u deze submap niet hebt, gebruikt u geen Delta Lake-indeling. U kunt uw gewone Parquet-bestanden in de map converteren naar Delta Lake-indeling met behulp van het volgende Apache Spark Python-script:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/covid`")
Als u de prestaties van uw query's wilt verbeteren, kunt u expliciete typen in de WITH component opgeven.
Notitie
De serverloze Synapse SQL-pool maakt gebruik van schemadeductie om automatisch kolommen en hun typen te bepalen. De regels voor schemadeductie zijn hetzelfde als voor Parquet-bestanden. Voor toewijzing van Delta Lake-typen aan systeemeigen SQL-typecontroletypetoewijzing voor Parquet.
Zorg ervoor dat u toegang hebt tot uw bestand. Als uw bestand is beveiligd met een SAS-sleutel of een aangepaste Azure-identiteit, moet u een referentie op serverniveau instellen voor sql-aanmelding.
Belangrijk
Zorg ervoor dat u een UTF-8-databasesortering (bijvoorbeeld Latin1_General_100_BIN2_UTF8) gebruikt, omdat tekenreekswaarden in Delta Lake-bestanden zijn gecodeerd met behulp van UTF-8-codering.
Een onjuiste overeenkomst tussen de tekstcodering in het Delta Lake-bestand en de sortering kunnen onverwachte conversiefouten veroorzaken.
U kunt de standaardsortering van de huidige database eenvoudig wijzigen met behulp van de volgende T-SQL-instructie: ALTER DATABASE CURRENT COLLATE Latin1_General_100_BIN2_UTF8;Zie Sorteringstypen die worden ondersteund voor Synapse SQL voor meer informatie over sorteringen.
Gebruik van gegevensbronnen
In de vorige voorbeelden is het volledige pad naar het bestand gebruikt. Als alternatief kunt u een externe gegevensbron maken met de locatie die verwijst naar de hoofdmap van de opslag. Nadat u de externe gegevensbron hebt gemaakt, gebruikt u de gegevensbron en het relatieve pad naar het bestand in de OPENROWSET functie. Op deze manier hoeft u de volledige absolute URI niet te gebruiken voor uw bestanden. U kunt vervolgens ook aangepaste referenties definiëren voor toegang tot de opslaglocatie.
Belangrijk
Gegevensbronnen kunnen alleen worden gemaakt in aangepaste databases (niet in de hoofddatabase of de databases die zijn gerepliceerd vanuit Apache Spark-pools).
Als u de onderstaande voorbeelden wilt gebruiken, moet u de volgende stap uitvoeren:
- Maak een database met een gegevensbron die verwijst naar het NYC Yellow Taxi-opslagaccount .
- Initialiseer de objecten door het installatiescript uit te voeren op de database die u in stap 1 hebt gemaakt. Met dit installatiescript worden de gegevensbronnen, databasereferenties en externe bestandsindelingen gemaakt die in deze voorbeelden worden gebruikt.
Als u uw database hebt gemaakt en de context hebt gewijzigd in uw database (met behulp van USE database_name de instructie of vervolgkeuzelijst voor het selecteren van een database in een queryeditor), kunt u uw externe gegevensbron met de hoofd-URI maken naar uw gegevensset en deze gebruiken om query's uit te voeren op Delta Lake-bestanden:
CREATE EXTERNAL DATA SOURCE DeltaLakeStorage
WITH ( LOCATION = 'https://sqlondemandstorage.blob.core.windows.net/delta-lake/' );
GO
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
) as rows;
Als een gegevensbron is beveiligd met een SAS-sleutel of een aangepaste identiteit, kunt u de gegevensbron configureren met referenties binnen het databasebereik.
Schema expliciet opgeven
OPENROWSET hiermee kunt u expliciet opgeven welke kolommen u uit het bestand wilt lezen met behulp van WITH de component:
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
)
WITH ( date_rep date,
cases int,
geo_id varchar(6)
) as rows;
Met de expliciete specificatie van het schema van de resultatenset kunt u de grootte van het type minimaliseren en de nauwkeurigere typen VARCHAR(6) gebruiken voor tekenreekskolommen in plaats van pessimistische VARCHAR(1000). Het minimaliseren van typen kan de prestaties van uw query's aanzienlijk verbeteren.
Belangrijk
Zorg ervoor dat u expliciet een UTF-8-sortering (bijvoorbeeld Latin1_General_100_BIN2_UTF8) opgeeft voor alle tekenreekskolommen in de WITH component of stel een UTF-8-sortering in op databaseniveau.
Niet-overeenkomende tekstcodering in het bestand en de sortering van tekenreekskolommen kunnen onverwachte conversiefouten veroorzaken.
U kunt eenvoudig de standaardsortering van de huidige database wijzigen met behulp van de volgende T-SQL-instructie: alter database current collate Latin1_General_100_BIN2_UTF8 U kunt eenvoudig sortering instellen op de columtypen met behulp van de volgende definitie: geo_id varchar(6) collate Latin1_General_100_BIN2_UTF8
Gegevensset
NyC Yellow Taxi-gegevensset wordt in dit voorbeeld gebruikt. De oorspronkelijke PARQUET gegevensset wordt geconverteerd naar DELTA indeling en de DELTA versie wordt gebruikt in de voorbeelden.
Gepartitioneerde gegevens opvragen
De gegevensset in dit voorbeeld is onderverdeeld (gepartitioneerd) in afzonderlijke submappen.
In tegenstelling tot Parquet hoeft u geen specifieke partities te targeten met behulp van de FILEPATH functie. Hiermee OPENROWSET worden partitioneringskolommen in uw Delta Lake-mapstructuur geïdentificeerd en kunt u rechtstreeks query's uitvoeren op gegevens met behulp van deze kolommen. In dit voorbeeld ziet u de ritbedragen per jaar, maand en payment_type voor de eerste drie maanden van 2017.
SELECT
YEAR(pickup_datetime) AS year,
passenger_count,
COUNT(*) AS cnt
FROM
OPENROWSET(
BULK 'yellow',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT='DELTA'
) nyc
WHERE
nyc.year = 2017
AND nyc.month IN (1, 2, 3)
AND pickup_datetime BETWEEN CAST('1/1/2017' AS datetime) AND CAST('3/31/2017' AS datetime)
GROUP BY
passenger_count,
YEAR(pickup_datetime)
ORDER BY
YEAR(pickup_datetime),
passenger_count;
De OPENROWSET functie elimineert partities die niet overeenkomen met de year en month in de where-component. Deze methode voor het verwijderen van bestanden/partities vermindert de gegevensset aanzienlijk, verbetert de prestaties en vermindert de kosten van de query.
De mapnaam in de OPENROWSET functie (yellow in dit voorbeeld) wordt samengevoegd met behulp van de LOCATION in DeltaLakeStorage de gegevensbron en moet verwijzen naar de hoofdmap Delta Lake die een submap bevat met de naam _delta_log.
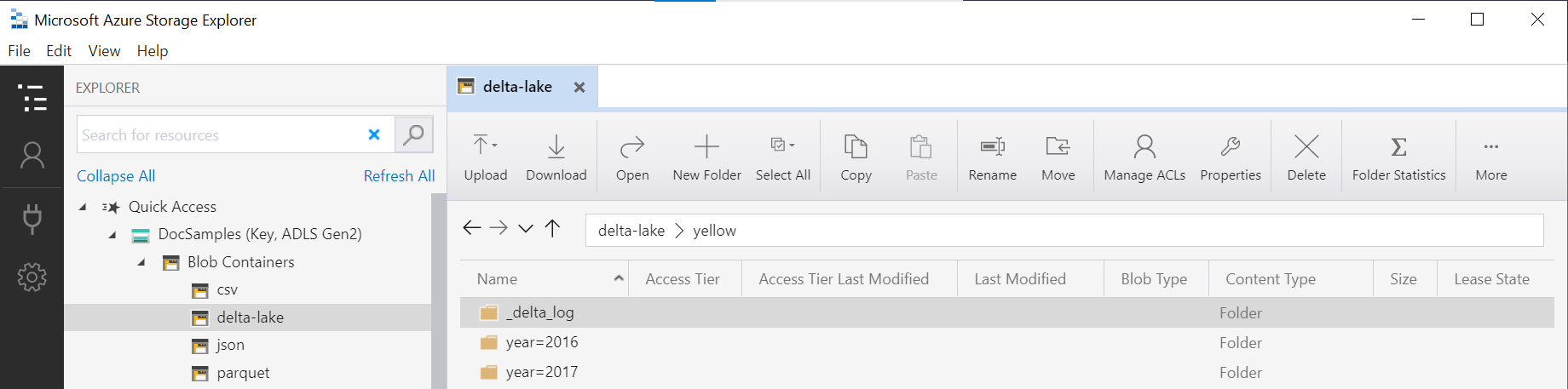
Als u deze submap niet hebt, gebruikt u geen Delta Lake-indeling. U kunt uw gewone Parquet-bestanden in de map converteren naar Delta Lake-indeling met behulp van het volgende Apache Spark Python-script:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/yellow`", "year INT, month INT")
Het tweede argument van DeltaTable.convertToDeltaLake de functie vertegenwoordigt de partitioneringskolommen (jaar en maand) die deel uitmaken van het mappatroon (year=*/month=* in dit voorbeeld) en de bijbehorende typen.
Beperkingen
- Bekijk de beperkingen en de bekende problemen op de self-helppagina van de Serverloze SQL-pool van Synapse.
Volgende stappen
Ga naar het volgende artikel voor meer informatie over het uitvoeren van query's op geneste Parquet-typen. Als u wilt doorgaan met het bouwen van een Delta Lake-oplossing, leert u hoe u weergaven of externe tabellen maakt in de map Delta Lake.