Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of mappen te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen om mappen te wijzigen.
Opmerking
Fabric Runtime 2.0 bevindt zich momenteel in een experimentele previewfase. Zie de beperkingen en notities voor meer informatie.
Fabric Runtime biedt naadloze integratie binnen het Microsoft Fabric-ecosysteem en biedt een robuuste omgeving voor data engineering- en data science-projecten die mogelijk worden gemaakt door Apache Spark.
In dit artikel maakt u kennis met Fabric Runtime 2.0 Experimenteel (preview), de nieuwste runtime die is ontworpen voor big data-berekeningen in Microsoft Fabric. Het markeert de belangrijkste functies en onderdelen die deze release een belangrijke stap voorwaarts maken voor schaalbare analyses en geavanceerde workloads.
Fabric Runtime 2.0 bevat de volgende onderdelen en upgrades die zijn ontworpen om uw gegevensverwerkingsmogelijkheden te verbeteren:
- Apache Spark 4.0
- Besturingssysteem: Azure Linux 3.0 (Mariner 3.0)
- Java: 21
- Scala: 2.13
- Python: 3.12
- Delta Lake: 4.0
Runtime 2.0 inschakelen
U kunt Runtime 2.0 inschakelen op werkruimteniveau of op het itemniveau van de omgeving. Gebruik de werkruimte-instelling om Runtime 2.0 toe te passen als de standaardinstelling voor alle Spark-workloads in uw werkruimte. Naast dat kunt u een omgevingsitem maken met Runtime 2.0 voor gebruik met specifieke notebooks of Spark-taakdefinities, waarmee de standaardinstelling van de werkruimte wordt overschreven.
Runtime 2.0 inschakelen in werkruimte-instellingen
Runtime 2.0 instellen als de standaardinstelling voor uw hele werkruimte:
Navigeer naar het tabblad Werkruimte-instellingen in uw Infrastructuurwerkruimte.
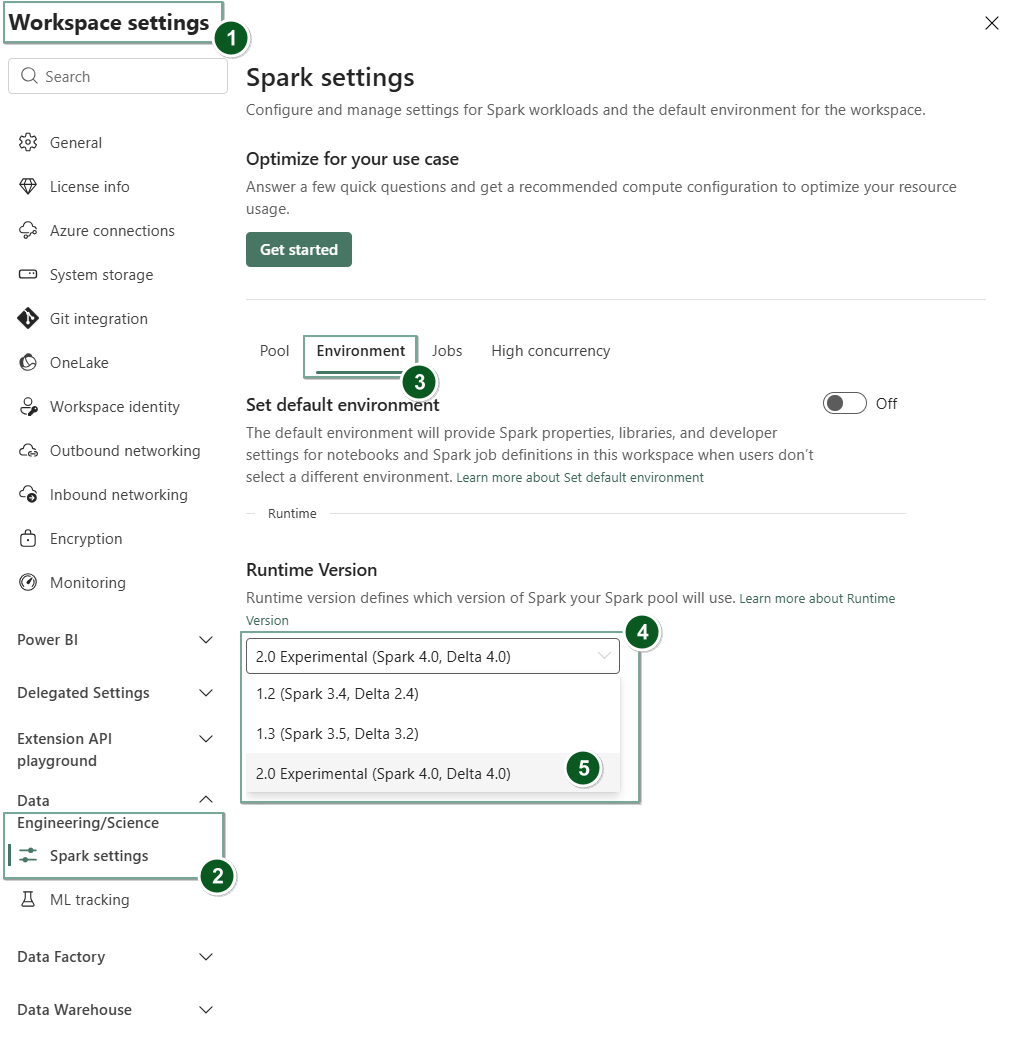
Ga naar het tabblad Data Engineering/Science en selecteer Spark-instellingen.
Selecteer het tabblad Omgeving.
Selecteer in de vervolgkeuzelijst runtimeversie2.0 Experimenteel (Spark 4.0, Delta 4.0) en sla uw wijzigingen op. Met deze actie wordt Runtime 2.0 ingesteld als de standaardruntime voor uw werkruimte.

Runtime 2.0 inschakelen in een omgevingselement
Runtime 2.0 gebruiken met specifieke notebooks of Spark-taakdefinities:
Maak een nieuw Omgevingsitem of open een bestaande.
Selecteer in de vervolgkeuzelijst Runtime2.0 Experimenteel (Spark 4.0, Delta 4.0)
SaveenPublishuw wijzigingen.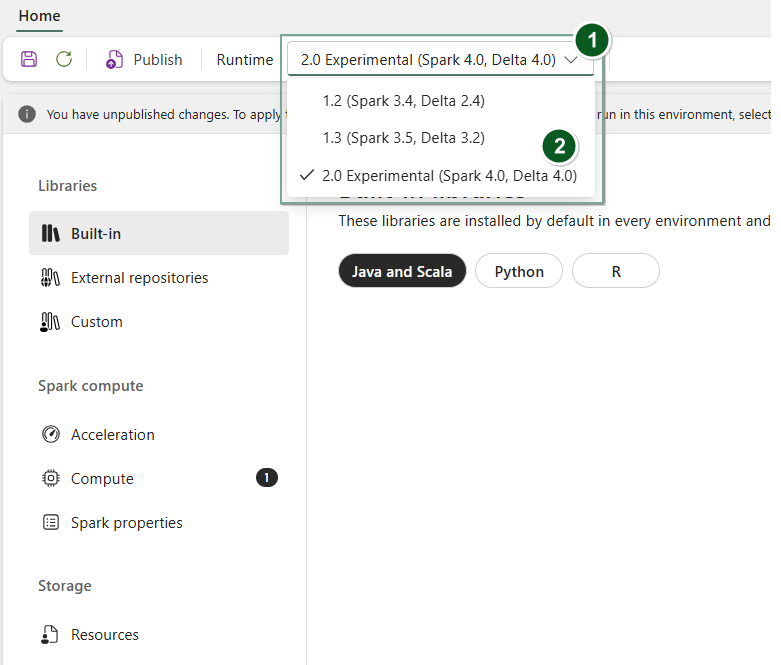
Belangrijk
Het kan ongeveer 2-5 minuten duren voordat Spark 2.0-sessies zijn gestart, omdat starterpools geen deel uitmaken van de vroege experimentele release.
Vervolgens kunt u deze omgeving gebruiken met uw
NotebookofSpark Job Definition.

U kunt nu experimenteren met de nieuwste verbeteringen en functionaliteiten die zijn geïntroduceerd in Fabric Runtime 2.0 (Spark 4.0 en Delta Lake 4.0).
Experimentele publiek voorproef
De experimentele previewfase van Fabric Runtime 2.0 biedt u vroege toegang tot nieuwe functies en API's van zowel Spark 4.0 als Delta Lake 4.0. Met de preview kunt u de nieuwste verbeteringen op basis van Spark direct gebruiken, zodat u een soepele gereedheid en overgang kunt garanderen voor toekomstige wijzigingen, zoals de nieuwere Java-, Scala- en Python-versies.
Aanbeveling
Voor actuele informatie, een gedetailleerde lijst met wijzigingen en specifieke releaseopmerkingen voor Fabric-runtimes, controleert en abonneert u Spark Runtime-releases en -updates.
Beperkingen en aantekeningen
Fabric Runtime 2.0 bevindt zich momenteel in een experimentele openbare preview-fase, ontworpen voor gebruikers om de nieuwste functies en API's van Spark en Delta Lake te verkennen en te experimenteren in de ontwikkel- of testomgevingen. Hoewel deze versie toegang biedt tot kernfunctionaliteiten, zijn er bepaalde beperkingen:
U kunt Spark 4.0-sessies gebruiken, code schrijven in notebooks, Spark-taakdefinities plannen en gebruiken met PySpark, Scala en Spark SQL. R-taal wordt echter niet ondersteund in deze vroege release.
U kunt bibliotheken rechtstreeks in uw code installeren met pip en conda. U kunt Spark-instellingen instellen via de %%configure-opties in notebooks en Spark-taakdefinities (SJD's).
U kunt lezen en schrijven naar het Lakehouse met Delta Lake 4.0, maar sommige geavanceerde functies zoals V-order, native Parquet-schrijfbewerking, autocompactie, schrijven optimaliseren, low-shuffle merge, merge, schema-evolutie en tijdreizen zijn niet opgenomen in deze vroege versie.
Spark Advisor is momenteel niet beschikbaar. Bewakingshulpprogramma's zoals de Spark-gebruikersinterface en logboeken worden echter ondersteund in deze vroege release.
Functies zoals Data Science-integraties, waaronder Copilot en connectors, waaronder Kusto, SQL Analytics, Cosmos DB en MySQL Java Connector, worden momenteel niet ondersteund in deze vroege release. Data Science-bibliotheken worden niet ondersteund in PySpark-omgevingen. PySpark werkt alleen met een eenvoudige Conda-installatie, waaronder Alleen PySpark zonder extra bibliotheken.
Integraties met omgevingsitem en Visual Studio Code worden niet ondersteund in deze vroege release.
Het biedt geen ondersteuning voor het lezen en schrijven van gegevens naar Azure Storage-accounts voor algemeen gebruik v2 (GPv2) met WASB- of ABFS-protocollen.
Opmerking
Deel uw feedback over Fabric Runtime in het Ideeën-platform. Vermeld de versie- en releasefase waarnaar u verwijst. We waarderen feedback van community's en geven prioriteit aan verbeteringen op basis van stemmen, zodat we voldoen aan de behoeften van de gebruiker.
Belangrijke hoogtepunten
Apache Spark 4.0
Apache Spark 4.0 markeert een belangrijke mijlpaal als de inaugurele release in de 4.x-serie, die de collectieve inspanning van de levendige opensource-community bekrachtigt.
In deze versie is Spark SQL aanzienlijk verrijkt met krachtige nieuwe functies die zijn ontworpen om expressiviteit en veelzijdigheid voor SQL-workloads te verbeteren, zoals ondersteuning voor VARIANT-gegevenstypen, door de gebruiker gedefinieerde SQL-functies, sessievariabelen, pijpsyntaxis en tekenreekssortering. PySpark ziet continue toewijding aan zowel de functionele breedte als de algehele ontwikkelaarservaring, waarbij een systeemeigen plotting-API, een nieuwe Python-gegevensbron-API, ondersteuning voor Python UDTFs en geïntegreerde profilering voor PySpark UDF's wordt geboden, naast tal van andere verbeteringen. Structured Streaming ontwikkelt zich met belangrijke toevoegingen die meer controle en eenvoudigere foutopsporing bieden, met name de introductie van de Willekeurige status-API v2 voor flexibeler statusbeheer en de statusgegevensbron voor eenvoudiger foutopsporing.
U kunt hier de volledige lijst en gedetailleerde wijzigingen controleren: https://spark.apache.org/releases/spark-release-4-0-0.html.
Opmerking
In Spark 4.0 is SparkR afgeschaft en mogelijk verwijderd in een toekomstige versie.
Delta Lake 4.0
Delta Lake 4.0 markeert een collectieve toezegging om Delta Lake interoperabel te maken tussen verschillende indelingen, gemakkelijker te werken en beter te presteren. Delta 4.0 is een mijlpaalrelease met krachtige nieuwe functies, prestatieoptimalisaties en fundamentele verbeteringen voor de toekomst van open data lakehouses.
U kunt hier de volledige lijst en gedetailleerde wijzigingen bekijken die zijn geïntroduceerd met Delta Lake 3.3 en 4.0: https://github.com/delta-io/delta/releases/tag/v3.3.0. https://github.com/delta-io/delta/releases/tag/v4.0.0.
Belangrijk
Delta Lake 4.0-specifieke functies zijn experimenteel en werken alleen aan Spark-ervaringen, zoals notebooks en Spark-taakdefinities. Als u dezelfde Delta Lake-tabellen wilt gebruiken voor meerdere Microsoft Fabric-workloads, schakelt u deze functies niet in. Lees de interoperabiliteit van Delta Lake-tabelindelingen voor meer informatie over welke protocolversies en -functies compatibel zijn in alle Microsoft Fabric-ervaringen.
Verwante inhoud
- Apache Spark Runtimes in Fabric : overzicht, versiebeheer en ondersteuning voor meerdere runtimes
- Spark Core-migratiehandleiding
- Migratiehandleidingen voor SQL, Gegevenssets en DataFrame
- Migratiehandleiding voor gestructureerd streamen
- Migratiehandleiding voor MLlib (Machine Learning)
- Migratiehandleiding voor PySpark (Python op Spark)
- Migratiehandleiding voor SparkR (R in Spark)