Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of mappen te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen om mappen te wijzigen.
Gebruik functionele afhankelijkheden om gegevens op te schonen. Er bestaat een functionele afhankelijkheid wanneer één kolom in een semantisch model (een Power BI-gegevensset) afhankelijk is van een andere kolom. Een kolom kan bijvoorbeeld ZIP code de waarde in een city kolom bepalen. Een functionele afhankelijkheid wordt weergegeven als een een-op-veel-relatie tussen waarden in twee of meer kolommen in een DataFrame. In deze zelfstudie wordt de Synthea-gegevensset gebruikt om te laten zien hoe functionele afhankelijkheden helpen bij het detecteren van problemen met de gegevenskwaliteit.
In deze zelfstudie leert u het volgende:
- Domeinkennis toepassen om hypothesen te vormen over functionele afhankelijkheden in een semantisch model.
- Maak kennis met onderdelen van de Semantic Link Python-bibliotheek (SemPy) die gegevenskwaliteitsanalyse automatiseren. Deze onderdelen zijn onder andere:
-
FabricDataFrame— een pandas-achtige structuur met aanvullende semantische informatie. - Functies die het evalueren van hypothesen over functionele afhankelijkheden automatiseren en schendingen in uw semantische modellen identificeren.
-
Voorwaarden
Een Microsoft Fabric-abonnementophalen. Of meld u aan voor een gratis microsoft Fabric-proefversie.
Meld u aan bij Microsoft Fabric-.
Schakel over naar Fabric met behulp van de ervaringsschakelaar aan de linkerkant van de startpagina.
- Selecteer Werkruimten in het navigatiedeelvenster en selecteer vervolgens uw werkruimte om deze in te stellen als de huidige werkruimte.
Volg mee in het notitieblok
Gebruik het notebook data_cleaning_functional_dependencies_tutorial.ipynb om deze zelfstudie te volgen.
Als u het bijbehorende notitieblok voor deze zelfstudie wilt openen, volgt u de instructies in Uw systeem voorbereiden op zelfstudies voor gegevenswetenschap om het notebook in uw werkruimte te importeren.
Als u liever de code van deze pagina kopieert en plakt, kunt u een nieuw notitieblok maken.
Zorg ervoor dat u een lakehouse aan het notebook koppelt voordat u begint met het uitvoeren van code.
Het notebook instellen
In deze sectie stelt u een notebookomgeving in.
Controleer uw Spark-versie. Als u Spark 3.4 of hoger gebruikt in Microsoft Fabric, is Semantic Link standaard opgenomen, zodat u deze niet hoeft te installeren. Als u Spark 3.3 of eerder gebruikt of als u wilt bijwerken naar de meest recente Semantische koppeling, voert u de volgende opdracht uit.
%pip install -U semantic-linkImporteer de modules die u in dit notebook gebruikt.
import pandas as pd import sempy.fabric as fabric from sempy.fabric import FabricDataFrame from sempy.dependencies import plot_dependency_metadataDownload de voorbeeldgegevens. In deze zelfstudie gebruikt u de Synthea-gegevensset van synthetische medische records (kleine versie voor eenvoud).
download_synthea(which='small')
De gegevens verkennen
Initialiseer een
FabricDataFramemet de inhoud van het providers.csv-bestand .providers = FabricDataFrame(pd.read_csv("synthea/csv/providers.csv")) providers.head()Controleer op problemen met de gegevenskwaliteit met de functie van
find_dependenciesSemPy door een grafiek met automatisch gedetecteerde functionele afhankelijkheden te tekenen.deps = providers.find_dependencies() plot_dependency_metadata(deps)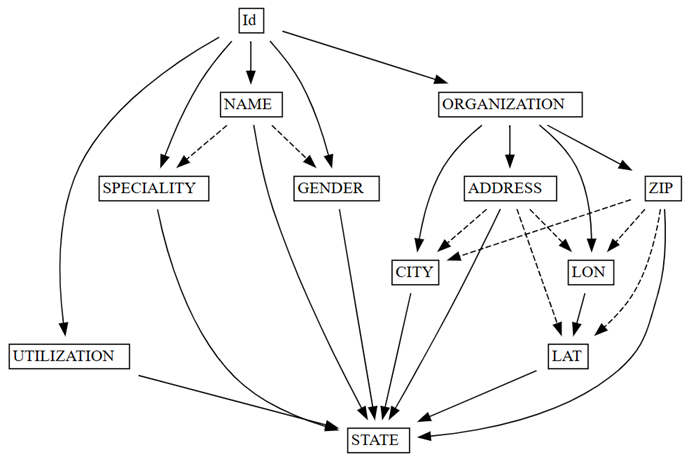
In de grafiek ziet u dat dit
IdbepaaltNAMEenORGANIZATION. Dit resultaat wordt verwacht omdatIddit uniek is.Bevestig dat dit
Iduniek is.providers.Id.is_uniqueDe code retourneert
Trueom te bevestigen datIduniek is.

Functionele afhankelijkheden uitgebreid analyseren
In de grafiek met functionele afhankelijkheden ziet u ook dat ORGANIZATION bepaalt ADDRESS en ZIP, zoals verwacht. U kunt echter verwachten dat ZIP ook CITYbepaalt, maar de stippellijn geeft aan dat de afhankelijkheid alleen bij benadering is, wat wijst naar een probleem met de gegevenskwaliteit.
Er zijn andere bijzonderheden in de grafiek.
NAME bepaalt bijvoorbeeld niet GENDER, Id, SPECIALITYof ORGANIZATION. Elk van deze eigenaardigheden kan het onderzoeken waard zijn.
- Bekijk de benaderingsrelatie tussen
ZIPenCITYmet behulp van de functie vanlist_dependency_violationsSemPy om de schendingen te vermelden:
providers.list_dependency_violations('ZIP', 'CITY')
- Teken een grafiek met de
plot_dependency_violationsvisualisatiefunctie van SemPy. Deze grafiek is handig als het aantal schendingen klein is:
providers.plot_dependency_violations('ZIP', 'CITY')
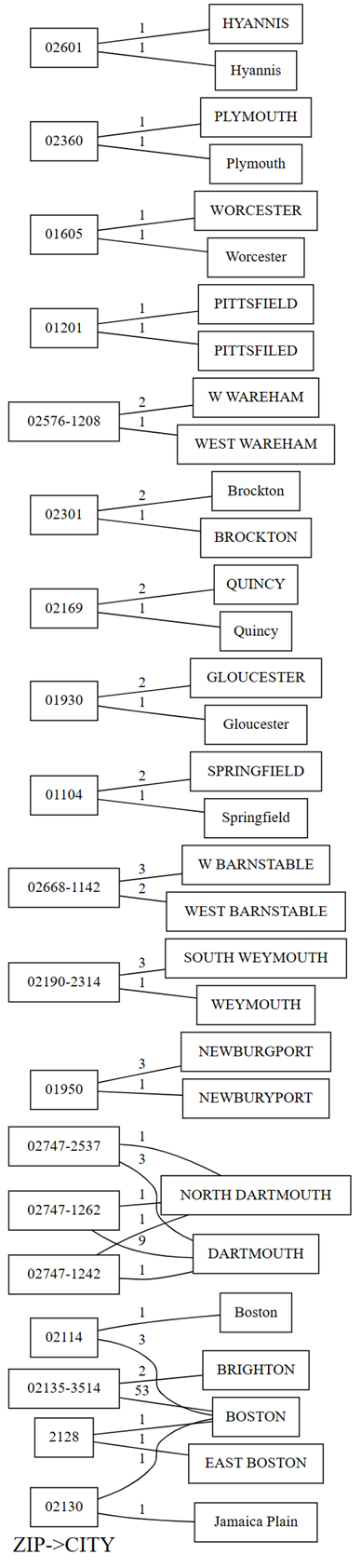
In de plot met afhankelijkheidsschendingen worden waarden weergegeven voor ZIP aan de linkerkant en waarden voor CITY aan de rechterkant. Een rand verbindt een postcode aan de linkerkant van de plot met een plaats aan de rechterkant als er een rij is die deze twee waarden bevat. De randen worden geannoteerd met het aantal van dergelijke rijen. Er zijn bijvoorbeeld twee rijen met postcode 02747-1242, één rij met plaats 'NORTH DARTHMOUTH' en de andere met plaats 'DARTHMOUTH', zoals wordt weergegeven in de vorige plot en de volgende code:
- Bevestig de waarnemingen van de plot door de volgende code uit te voeren:
providers[providers.ZIP == '02747-1242'].CITY.value_counts()
In de plot ziet u ook dat negen rijen een van 02747-1262 hebben
CITYZIPtussen de rijen met 'DARTHMOUTH'. Eén rij heeft eenZIPvan 02747-1242. Eén rij heeft eenZIPvan 02747-2537. Bevestig deze waarnemingen met de volgende code:providers[providers.CITY == 'DARTHMOUTH'].ZIP.value_counts()Er zijn andere postcodes gekoppeld aan "DARTMOUTH", maar deze postcodes worden niet weergegeven in de grafiek met afhankelijkheidsschendingen, omdat ze niet wijzen op problemen met de kwaliteit van gegevens. De postcode '02747-4302' is bijvoorbeeld uniek gekoppeld aan DARTMOUTH en wordt niet weergegeven in de grafiek met afhankelijkheidsschendingen. Bevestig door de volgende code uit te voeren:
providers[providers.ZIP == '02747-4302'].CITY.value_counts()
Problemen met gegevenskwaliteit samenvatten die zijn gedetecteerd met SemPy
In de grafiek met afhankelijkheidsschendingen ziet u verschillende problemen met gegevenskwaliteit in dit semantische model:
- Sommige plaatsnamen zijn hoofdletters. Gebruik tekenreeksmethoden om dit probleem op te lossen.
- Sommige plaatsnamen hebben kwalificaties (of voorvoegsels), zoals 'Noord' en 'Oost'. De postcode '2128' wordt bijvoorbeeld één keer toegewezen aan EAST BOSTON en één keer aan BOSTON. Er treedt een vergelijkbaar probleem op tussen NORTH DARTMOUTH en DARTMOUTH. Zet deze kwalificaties neer of wijs de postcodes toe aan de stad met het meest voorkomende exemplaar.
- Er zijn typfouten in sommige stadsnamen, zoals "PITTSFIELD" versus "PITTSFILED" en "NEWBURGPORT" versus "NEWBURYPORT". Voor 'NEWBURGPORT' lost u deze typefout op met behulp van het meest voorkomende exemplaar. Voor "PITTSFIELD" met slechts één exemplaar is automatische ondubbelzinnigheid veel moeilijker zonder externe kennis of een taalmodel.
- Soms worden voorvoegsels zoals 'West' afgekort tot de enkele letter 'W'. Vervang 'W' door 'West' als alle exemplaren van 'W' staan voor 'West'.
- De postcode "02130" wordt eenmaal toegewezen aan "BOSTON" en "Jamaica Plain" één keer. Dit probleem is niet eenvoudig op te lossen. Wijs met meer gegevens toe aan het meest voorkomende exemplaar.
De gegevens opschonen
Corrik hoofdlettergebruik door waarden te wijzigen in titelcase.
providers['CITY'] = providers.CITY.str.title()Voer de detectie van schendingen opnieuw uit om te bevestigen dat er minder dubbelzinnigheden zijn.
providers.list_dependency_violations('ZIP', 'CITY')
Verfijn de gegevens handmatig of zet rijen neer die functionele beperkingen tussen kolommen schenden met behulp van de functie van drop_dependency_violations SemPy.
Voor elke waarde van de determinante variabele drop_dependency_violations kiest u de meest voorkomende waarde van de afhankelijke variabele en verwijdert u alle rijen met andere waarden. Pas deze bewerking alleen toe als u er zeker van bent dat deze statistische heuristiek leidt tot de juiste resultaten voor uw gegevens. Schrijf anders uw eigen code om de gedetecteerde schendingen af te handelen.
Voer de
drop_dependency_violationsfunctie uit op deZIPenCITYkolommen.providers_clean = providers.drop_dependency_violations('ZIP', 'CITY')Vermeld eventuele afhankelijkheidsschendingen tussen
ZIPenCITY.providers_clean.list_dependency_violations('ZIP', 'CITY')
De code retourneert een lege lijst om aan te geven dat er geen schendingen meer zijn van de functionele beperking ZIP -> CITY.
Verwante inhoud
Zie andere zelfstudies voor semantische koppeling of SemPy:
- Zelfstudie: Functionele afhankelijkheden analyseren in een semantisch voorbeeldmodel
- Zelfstudie: Power BI-metingen extraheren en berekenen uit een Jupyter-notebook
- Zelfstudie: Relaties ontdekken in een semantisch model met behulp van een semantische koppeling
- Zelfstudie: Relaties ontdekken in de Synthea-gegevensset met behulp van een semantische koppeling
- Zelfstudie: Gegevens valideren met behulp van SemPy en Great Expectations (GX)