Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of mappen te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen om mappen te wijzigen.
In deze zelfstudie ziet u hoe u een Jupyter-notebook gebruikt om te communiceren met Power BI en relaties tussen tabellen met de SemPy-bibliotheek te detecteren.
In deze zelfstudie leert u het volgende:
- Ontdek relaties in een semantisch model (Power BI-gegevensset) met behulp van de Python-bibliotheek (SemPy) van semantic Link.
- Gebruik SemPy-onderdelen die integreren met Power BI en gegevenskwaliteitsanalyse automatiseren. Deze onderdelen zijn onder andere:
-
FabricDataFrame- een pandas-achtige structuur verbeterd met semantische informatie - Functies die semantische modellen uit een Fabric-werkruimte naar uw notebook halen
- Functies waarmee functionele afhankelijkheden worden getest en relatieschendingen in uw semantische modellen worden geïdentificeerd
-
Voorwaarden
Een Microsoft Fabric-abonnementophalen. Of meld u aan voor een gratis microsoft Fabric-proefversie.
Meld u aan bij Microsoft Fabric-.
Schakel over naar Fabric met behulp van de ervaringsschakelaar aan de linkerkant van de startpagina.
Ga naar Werkruimten in het navigatiedeelvenster en selecteer vervolgens uw werkruimte om deze in te stellen als de huidige werkruimte.
Download het klantwinstgevendheidsvoorbeeld.pbix en klantwinstgevendheidsvoorbeeld (auto).pbix-semantische modellen uit de GitHub-opslagplaats voor fabric-samples en upload deze vervolgens naar uw werkruimte.
Volg mee in het notitieblok
Gebruik het notebook powerbi_relationships_tutorial.ipynb om mee te doen.
Als u het bijbehorende notitieblok voor deze zelfstudie wilt openen, volgt u de instructies in Uw systeem voorbereiden op zelfstudies voor gegevenswetenschap om het notebook in uw werkruimte te importeren.
Als u liever de code van deze pagina kopieert en plakt, kunt u een nieuw notitieblok maken.
Zorg ervoor dat u een lakehouse aan het notebook koppelt voordat u begint met het uitvoeren van code.
Het notebook instellen
Stel een notebookomgeving in met de modules en gegevens die u nodig hebt.
Installeer het
semantic-linkpakket vanuit PyPI met behulp van de%pipinline-opdracht in het notebook.%pip install semantic-linkImporteer de
sempymodules die u later gaat gebruiken.import sempy.fabric as fabric from sempy.relationships import plot_relationship_metadata from sempy.relationships import find_relationships from sempy.fabric import list_relationship_violationsImporteer de
pandasbibliotheek en stel een weergaveoptie in voor uitvoeropmaak.import pandas as pd pd.set_option('display.max_colwidth', None)
## Explore semantic models
This tutorial uses the Customer Profitability Sample semantic model [_Customer Profitability Sample.pbix_](https://github.com/microsoft/fabric-samples/blob/main/docs-samples/data-science/datasets/Customer%20Profitability%20Sample.pbix). Learn about the semantic model in [Customer Profitability sample for Power BI](/power-bi/create-reports/sample-customer-profitability).
- Use SemPy's `list_datasets` function to explore semantic models in your current workspace:
```python
fabric.list_datasets()
Gebruik voor de rest van dit notebook twee versies van het semantische model Klantwinstgevendheidsvoorbeeld:
- Voorbeeld van klantwinstgevendheid: het semantische model zoals opgegeven in de Power BI-voorbeelden, met vooraf gedefinieerde tabelrelaties
- Voorbeeld van klantwinstgevendheid (automatisch): dezelfde gegevens, maar relaties zijn beperkt tot relaties die automatisch door Power BI worden gedefinieerd
Vooraf gedefinieerde relaties extraheren uit het semantische voorbeeldmodel
Laad de vooraf gedefinieerde relaties in het semantische model klantwinstgevendheidsvoorbeeld met behulp van de functie van
list_relationshipsSemPy. De functie bevat relaties uit het tabellaire objectmodel (TOM).dataset = "Customer Profitability Sample" relationships = fabric.list_relationships(dataset) relationshipsVisualiseer het
relationshipsDataFrame als een grafiek met behulp van de functie vanplot_relationship_metadataSemPy.plot_relationship_metadata(relationships)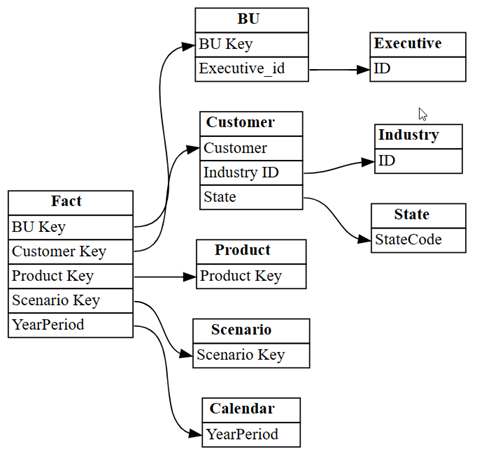
In deze grafiek ziet u de relaties tussen tabellen in dit semantische model, zoals gedefinieerd in Power BI door een expert op het gebied van onderwerp.

Aanvullende relaties ontdekken
Als u begint met relaties die automatisch door Power BI worden gedefinieerd, hebt u een kleinere set.
Visualiseer de relaties die automatisch door Power BI zijn gedetecteerd in het semantische model:
dataset = "Customer Profitability Sample (auto)" autodetected = fabric.list_relationships(dataset) plot_relationship_metadata(autodetected)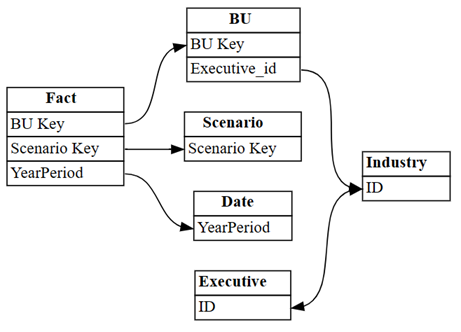
De automatische verwijdering van Power BI mist veel relaties. Bovendien zijn twee van de automatisch gedetecteerde relaties semantisch onjuist:
-
Executive[ID]->Industry[ID] -
BU[Executive_id]->Industry[ID]
-
De relaties afdrukken als een tabel:
autodetectedRijen 3 en 4 geven onjuiste relaties met de
Industrytabel weer. Verwijder deze rijen.Negeer de onjuist geïdentificeerde relaties.
# Remove rows 3 and 4 which point incorrectly to Industry[ID] autodetected = autodetected[~autodetected.index.isin([3, 4])]Nu hebt u de juiste maar onvolledige relaties. Visualiseer deze onvolledige relaties met behulp van
plot_relationship_metadata:plot_relationship_metadata(autodetected)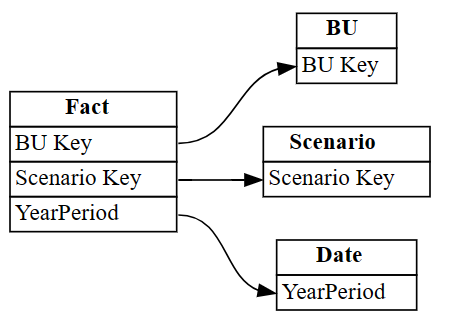
Laad alle tabellen uit het semantische model met behulp van SemPy's
list_tablesenread_tablefuncties en zoek vervolgens relaties tussen tabellen met behulp vanfind_relationships. Bekijk de logboekuitvoer om inzicht te krijgen in de werking van deze functie:suggested_relationships_all = find_relationships( tables, name_similarity_threshold=0.7, coverage_threshold=0.7, verbose=2 )Nieuw gedetecteerde relaties visualiseren:
plot_relationship_metadata(suggested_relationships_all)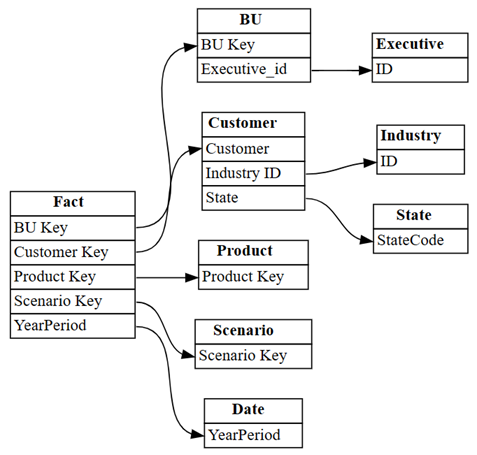
SemPy detecteert alle relaties.
Gebruik de parameter
excludeom de zoekopdracht te beperken tot aanvullende relaties die niet eerder zijn geïdentificeerd:additional_relationships = find_relationships( tables, exclude=autodetected, name_similarity_threshold=0.7, coverage_threshold=0.7 ) additional_relationships



Relaties valideren
Laad eerst gegevens uit het semantische model klantwinstgevendheidsvoorbeeld .
dataset = "Customer Profitability Sample" tables = {table: fabric.read_table(dataset, table) for table in fabric.list_tables(dataset)['Name']} tables.keys()Controleer of de primaire en refererende sleutel overlappen met de
list_relationship_violationsfunctie. Geef de uitvoer van delist_relationshipsfunctie door aanlist_relationship_violations.list_relationship_violations(tables, fabric.list_relationships(dataset))De resultaten geven nuttige inzichten weer. Een van de zeven waarden in
Fact[Product Key]is bijvoorbeeld niet aanwezig enProduct[Product Key]de ontbrekende sleutel is50.Verkennende gegevensanalyse en gegevens opschonen zijn iteratief. Wat u leert, is afhankelijk van uw vragen en hoe u de gegevens verkent. Semantische koppeling voegt hulpprogramma's toe waarmee u meer kunt doen met uw gegevens.
Verwante inhoud
Bekijk andere zelfstudies voor semantische koppeling en SemPy:
- Zelfstudie: Gegevens opschonen met functionele afhankelijkheden
- Zelfstudie: Functionele afhankelijkheden analyseren in een semantisch voorbeeldmodel
- Zelfstudie: Power BI-metingen extraheren en berekenen uit een Jupyter-notebook
- Zelfstudie: Relaties ontdekken in de Synthea-gegevensset met behulp van een semantische koppeling
- Zelfstudie: Gegevens valideren met behulp van SemPy en Great Expectations (GX)