Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of mappen te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen om mappen te wijzigen.
In dit artikel wordt uitgelegd hoe Git-integratie- en implementatiepijplijnen werken voor gespiegelde databases in Microsoft Fabric. Meer informatie over het instellen van een verbinding met uw opslagplaats, het beheren van uw gespiegelde databases via Git en het implementeren ervan in verschillende omgevingen.
Git-integratie met gespiegelde databases
Vanuit uw werkruimte-instellingen kunt u eenvoudig een verbinding met uw opslagplaats instellen om wijzigingen door te voeren en te synchroniseren. Zie het artikel Aan de slag met Git-integratie om de verbinding in te stellen.
Nadat u verbinding hebt gemaakt, wordt in de werkruimte informatie weergegeven over broncodebeheer waarmee u de verbonden vertakking, de status van elk item in de vertakking en de tijd van de laatste synchronisatie kunt bekijken.
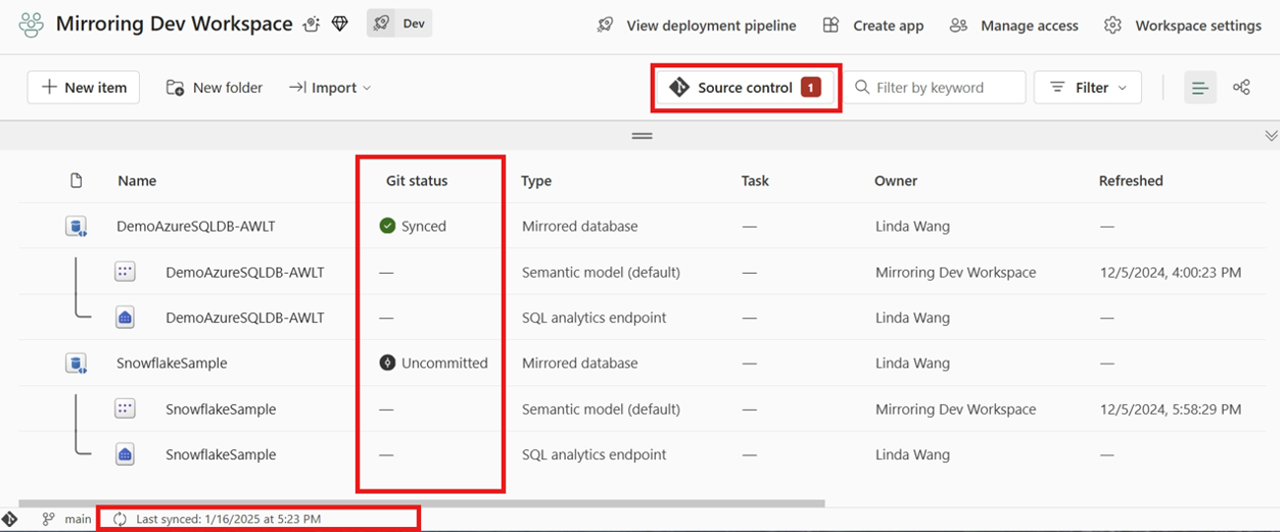
U kunt de wijzigingen in de gespiegelde database doorvoeren in Git of de werkruimte bijwerken vanuit Git door op het besturingselement Bron te klikken.
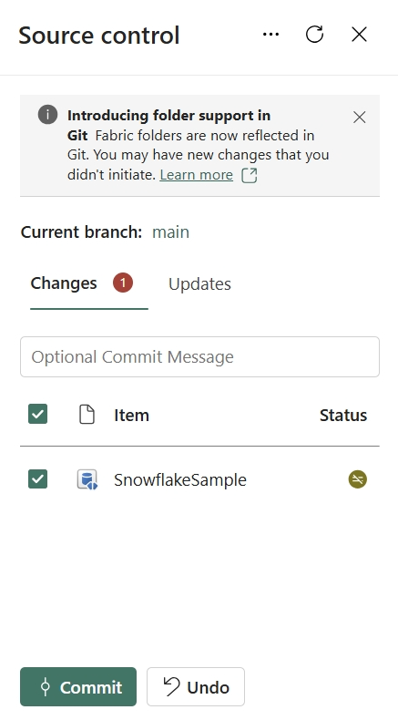
Gespiegelde databaseweergave in Git
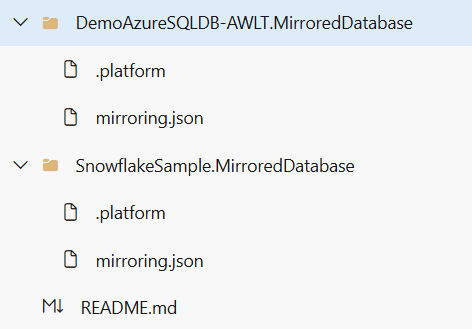
Wanneer u het gespiegelde database-item doorvoert in de Git-opslagplaats, wordt er een map gemaakt voor elk item en wordt deze genoemd {display name}.MirroredDatabase. Het bevat twee bestanden:
-
mirroring.jsonbestand dat de definitie vormt van de gespiegelde database. Meer informatie over definitie van gespiegeld database-item -
.platformbestand dat automatisch wordt gegenereerd door het systeem. Meer informatie over systeembestanden.
Opmerking
Alleen het gespiegelde database-item wordt bijgehouden in Git. Het SQL-analytics-eindpunt, weergaven en andere onderliggende items worden niet bijgehouden.
Gespiegelde database in implementatiepijplijnen
U kunt een Fabric-implementatiepijplijn gebruiken om uw gespiegelde database te implementeren in verschillende omgevingen, zoals ontwikkeling, testen en productie. En u kunt implementatieregels gebruiken om de brondatabases zo aan te passen dat ze worden gespiegeld.
Voer de volgende stappen uit om uw gespiegelde database te implementeren met behulp van een implementatiepijplijn:
Maak een implementatiepijplijn en raadpleeg Aan de slag met implementatiepijplijnen.
Wijs werkruimten toe aan verschillende fasen op basis van uw implementatiedoelen.
Items selecteren, weergeven en vergelijken, inclusief gespiegelde database tussen verschillende fasen.
Selecteer Implementeren om uw gespiegelde database in de fasen te implementeren. U ziet mogelijk een waarschuwing dat het item (SQL Analytics-eindpunt) niet wordt ondersteund, genegeerd en doorgaan
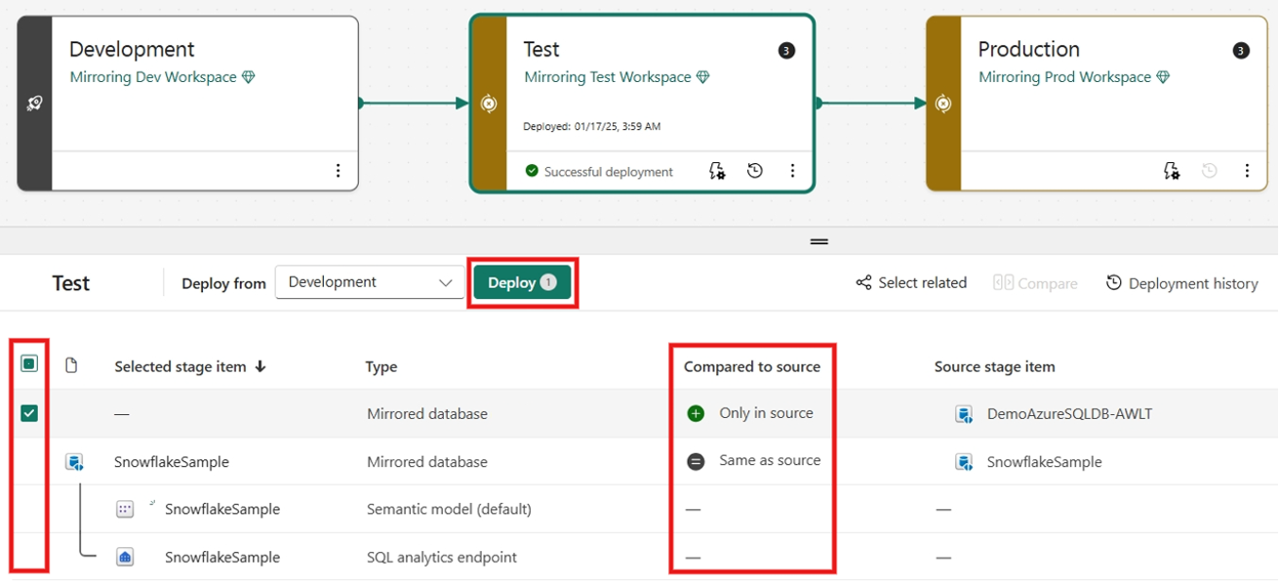
(Optioneel) Als u een andere brondatabase uit de vorige fase wilt spiegelen, selecteert u Implementatieregels om implementatieregels te maken voor een implementatieproces. De invoer van de implementatieregels bevindt zich in de doelfase van een uitrolproces.

Fabric ondersteunt het parameteriseren van de brondatabase voor elk gespiegeld database-item bij het implementeren met implementatieregels. Selecteer de bijbehorende gespiegelde database -> Gegevensbronregels -> + Regel toevoegen, voer de doelverbindings-id in en eventueel een database indien van toepassing op uw brondatabasetype. U vindt de verbindings-id in Verbindingen en gateways beheren :> zoek de gemaakte verbinding in de lijst -> Instellingen -> Verbindings-id.
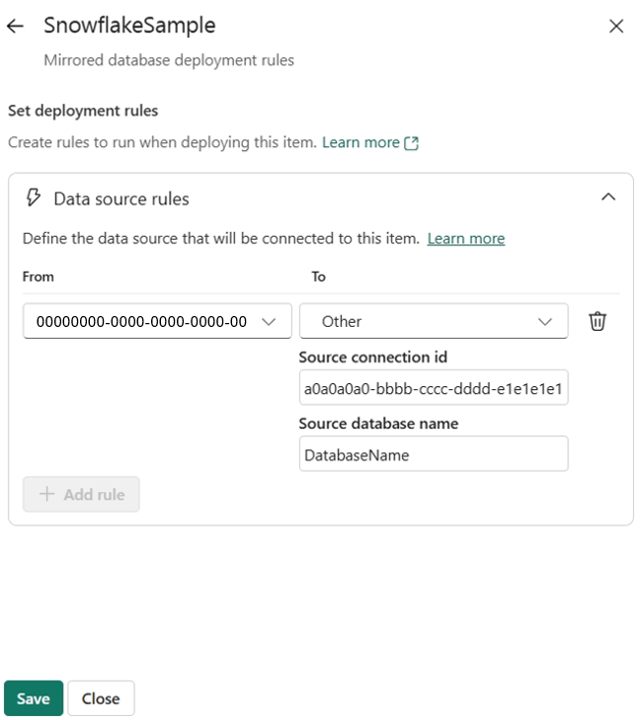
Nadat u de implementatieregels hebt gemaakt, implementeert u de gespiegelde databases met de zojuist gemaakte regels uit de bronfase in de doelfase waarin de regels zijn gemaakt. Uw regels worden pas van kracht nadat u de gespiegelde database van de bron naar de doelfase hebt geïmplementeerd.
Bewaak de implementatiestatus vanuit de implementatiegeschiedenis.
Belangrijk
Gespiegelde database wordt niet gestart na de implementatie. U moet deze handmatig of via API starten.
Belangrijk
Als u gegevens uit Azure SQL Database, Azure SQL Managed Instance, Azure Database for PostgreSQL of SQL Server 2025 wilt spiegelen, moet u ook het volgende doen voordat u begint met spiegelen:
- Schakel de beheerde identiteit van uw logische Azure SQL-server, Azure SQL Managed Instance, Azure Database for PostgreSQL of SQL Server in.
- Geef de beheerde identiteit Lees- en Schrijfmachtigingen toe aan de gespiegelde database. Op dit moment moet u dit doen in de Fabric-portal. U kunt de beheerde identiteit werkruimterol ook verlenen met behulp van de API voor het toevoegen van roltoewijzingen aan werkruimtes.
Opmerking
Op dit moment worden subitems, zoals bijvoorbeeld gemaakte weergaven, niet over verschillende stappen geïmplementeerd.