Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of mappen te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen om mappen te wijzigen.
Van toepassing op:![]() SQL Server 2019 (15.x) en latere versies
SQL Server 2019 (15.x) en latere versies
Op 28 februari 2025 is SQL Server 2019 Big Data Clusters buiten gebruik gesteld. Zie de blogpost voor aankondigingen voor meer informatie.
Wijzigingen in PolyBase-ondersteuning in SQL Server
Gerelateerd aan de buitengebruikstelling van BIG Data-clusters van SQL Server 2019 zijn enkele functies met betrekking tot het uitschalen van query's.
De functie PolyBase scale-outgroepen van Microsoft SQL Server is buiten gebruik gesteld. De functionaliteit van uitschalende groepen wordt verwijderd uit het product in SQL Server 2022 (16.x). In-market versies van SQL Server 2019, SQL Server 2017 en SQL Server 2016 blijven de functionaliteit ondersteunen tot het einde van de levensduur van deze producten. PolyBase-gegevensvirtualisatie wordt nog steeds volledig ondersteund als een functie voor omhoog schalen in SQL Server.
Cloudera (CDP) en Hortonworks (HDP) Hadoop externe gegevensbronnen worden ook buiten gebruik gesteld voor alle in-market versies van SQL Server en zijn niet opgenomen in SQL Server 2022. Ondersteuning voor externe gegevensbronnen is beperkt tot productversies in basisondersteuning door de desbetreffende leverancier. U wordt aangeraden de nieuwe integratie van objectopslag te gebruiken die beschikbaar is in SQL Server 2022 (16.x).
In SQL Server 2022 (16.x) en latere versies moeten gebruikers hun externe gegevensbronnen configureren voor het gebruik van nieuwe connectors wanneer ze verbinding maken met Azure Storage. De volgende tabel bevat een overzicht van de wijziging:
| Externe gegevensbron | From | To |
|---|---|---|
| Azure Blob Storage (opslagdienst van Azure) | wasb[s] |
abs |
| ADLS Gen 2 | abfs[s] |
adls |
Note
Voor Azure Blob Storage (abs) is het gebruik van Shared Access Signature (SAS) vereist voor het GEHEIM in de referentie voor het databasebereik. In SQL Server 2019 en eerder gebruikte de wasb[s]-connector de sleutel van het opslagaccount met een database-specifieke referentie voor authenticatie bij het Azure Storage-account.
Inzicht krijgen in de architectuur voor big data-clusters voor vervangings- en migratieopties
Als u uw vervangingsoplossing voor een big data-opslag- en verwerkingssysteem wilt maken, is het belangrijk om te begrijpen wat SQL Server 2019 Big Data Clusters heeft geleverd en de architectuur kan u helpen uw keuzes te informeren. De architectuur van een big data-cluster was:

Deze architectuur biedt de volgende functionaliteitstoewijzing:
| Component | Benefit |
|---|---|
| Kubernetes | Opensource-orchestrator voor het implementeren en beheren van op containers gebaseerde toepassingen op schaal. Biedt een declaratieve methode voor het maken en beheren van tolerantie, redundantie en draagbaarheid voor de hele omgeving met elastische schaal. |
| Controller voor big data-clusters | Biedt beheer en beveiliging voor het cluster. Het bevat de besturingsservice, het configuratiearchief en andere services op clusterniveau, zoals Kibana, Grafana en Elastic Search. |
| Rekengroep | Biedt rekenbronnen voor het cluster. Het bevat knooppunten met SQL Server op Linux-pods. De pods in de rekengroep zijn onderverdeeld in SQL Compute-exemplaren voor specifieke verwerkingstaken. Dit onderdeel biedt ook Gegevensvirtualisatie met PolyBase om query's uit te voeren op externe gegevensbronnen zonder de gegevens te verplaatsen of te kopiëren. |
| Gegevensgroep | Biedt gegevenspersistentie voor het cluster. De gegevensgroep bestaat uit een of meer pods met SQL Server op Linux. Het wordt gebruikt voor het opnemen van gegevens uit SQL-query's of Spark-taken. |
| Opslaggroep | De opslagpool bestaat uit opslagpoolpods die bestaan uit SQL Server op Linux, Spark en HDFS. Alle opslagknooppunten in een big data-cluster zijn lid van een HDFS-cluster. |
| App-pool | Maakt de implementatie van toepassingen in een big data-cluster mogelijk door interfaces te bieden voor het maken, beheren en uitvoeren van toepassingen. |
Zie Inleiding tot BIG Data-clusters van SQL Server voor meer informatie over deze functies.
Opties voor functionaliteitsvervanging voor Big Data en SQL Server
De operationele gegevensfunctie die wordt gefaciliteerd door SQL Server in de Big Data-clusters, kan worden vervangen door SQL Server on-premises in een hybride configuratie of met behulp van het Microsoft Azure-platform. Microsoft Azure biedt een keuze uit volledig beheerde relationele databases, NoSQL en in-memory databases, die eigen en opensource-engines omvatten, zodat ze voldoen aan de behoeften van moderne app-ontwikkelaars. Infrastructuurbeheer, inclusief schaalbaarheid, beschikbaarheid en beveiliging, is geautomatiseerd, bespaart u tijd en geld en kunt u zich richten op het bouwen van toepassingen terwijl door Azure beheerde databases uw taak eenvoudiger maken door inzicht in prestaties te verkrijgen via ingesloten intelligentie, schalen zonder limieten en beveiligingsrisico's te beheren. Zie Azure-databases voor meer informatie.
Het volgende beslissingspunt is de locaties van reken- en gegevensopslag voor analyse. De twee architectuurkeuzen zijn in-cloud- en hybride implementaties. De meeste analytische workloads kunnen worden gemigreerd naar het Microsoft Azure-platform. Gegevens die zijn geboren in de cloud (afkomstig uit cloudtoepassingen) zijn uitstekende kandidaten voor deze technologieën en services voor gegevensverplaatsing kunnen grootschalige on-premises gegevens veilig en snel migreren. Zie Oplossingen voor gegevensoverdracht voor meer informatie over opties voor gegevensverplaatsing.
Microsoft Azure heeft systemen en certificeringen die veilige gegevens en gegevensverwerking in verschillende hulpprogramma's mogelijk maken. Zie het Vertrouwenscentrum voor meer informatie over deze certificeringen.
Note
Het Microsoft Azure-platform biedt een zeer hoog beveiligingsniveau, meerdere certificeringen voor verschillende branches en respecteert gegevenssoevereine voor overheidsvereisten. Microsoft Azure heeft ook een speciaal cloudplatform voor overheidsworkloads. Beveiliging alleen mag niet het primaire beslissingspunt zijn voor on-premises systemen. U moet het beveiligingsniveau van Microsoft Azure zorgvuldig evalueren voordat u besluit om uw big data-oplossingen on-premises te behouden.
In de optie voor de architectuur in de cloud bevinden alle onderdelen zich in Microsoft Azure. Uw verantwoordelijkheid ligt bij de gegevens en code die u maakt voor opslag en verwerking van uw workloads. Deze opties worden in dit artikel uitgebreider besproken.
- Deze optie werkt het beste voor een groot aantal onderdelen voor het opslaan en verwerken van gegevens, en wanneer u zich wilt richten op gegevens- en verwerkingsconstructies in plaats van infrastructuur.
In de opties voor hybride architectuur worden sommige onderdelen on-premises bewaard en worden andere onderdelen in een cloudprovider geplaatst. Connectiviteit tussen de twee is ontworpen voor de optimale plaatsing van verwerking ten opzichte van gegevens.
- Deze optie werkt het beste wanneer u een aanzienlijke investering hebt in on-premises technologieën en architecturen, maar u de aanbiedingen van Microsoft Azure wilt gebruiken, of wanneer u verwerkings- en toepassingsdoelen hebt die zich on-premises of voor een wereldwijd publiek bevinden.
Zie Een schaalbaar systeem bouwen voor enorme gegevens voor meer informatie over het bouwen van schaalbare architecturen.
In-cloud
Azure SQL met Synapse
U kunt de functionaliteit van SQL Server Big Data-clusters vervangen door een of meer Azure SQL-databaseopties te gebruiken voor operationele gegevens en Microsoft Azure Synapse voor uw analyseworkloads.
Microsoft Azure Synapse is een zakelijke analyseservice die de tijd voor inzicht in datawarehouses en big data-systemen versnelt met behulp van gedistribueerde verwerking en gegevensconstructies. Azure Synapse combineert SQL-technologieën die worden gebruikt in zakelijke datawarehousing, Spark-technologieën die worden gebruikt voor big data, pijplijnen voor gegevensintegratie en ETL/ELT, en diepgaande integratie met andere Azure-services, zoals Power BI, Cosmos DB en Azure Machine Learning.
Gebruik Microsoft Azure Synapse als vervanging voor BIG Data-clusters van SQL Server 2019 wanneer u het volgende moet doen:
- Gebruik zowel serverloze als toegewezen resourcemodellen. Voor voorspelbare prestaties en kosten kunt u toegewezen SQL-pools maken om verwerkingskracht te reserveren voor gegevens die zijn opgeslagen in SQL-tabellen.
- Niet-geplande of burst-workloads verwerken, toegang krijgen tot een altijd beschikbaar, serverloos SQL-eindpunt.
- Gebruik ingebouwde streamingmogelijkheden om gegevens uit cloudgegevensbronnen in SQL-tabellen te landen.
- Integreer AI met SQL met behulp van machine learning-modellen om gegevens te scoren met behulp van de T-SQL PREDICT-functie.
- ML-modellen gebruiken met SparkML-algoritmen en Azure Machine Learning-integratie voor Apache Spark 2.4 die worden ondersteund voor Linux Foundation Delta Lake.
- Gebruik een vereenvoudigd resourcemodel waarmee u zich geen zorgen hoeft te maken over het beheren van clusters.
- Gegevens verwerken waarvoor snelle opstart van Spark en intensieve automatische schaalaanpassing vereist is.
- Gegevens verwerken using.NET voor Spark, zodat u uw C#-expertise en bestaande .NET-code in een Spark-toepassing opnieuw kunt gebruiken.
- Werken met tabellen die zijn gedefinieerd in bestanden in de datalake, waarbij ze naadloos worden gebruikt door Spark of Hive.
- Gebruik SQL met Spark om Parquet-, CSV-, TSV- en JSON-bestanden die zijn opgeslagen in een data lake rechtstreeks te verkennen en te analyseren.
- Zorg voor snel en schaalbaar laden van gegevens tussen SQL- en Spark-databases.
- Gegevens opnemen uit meer dan 90 gegevensbronnen.
- Schakel ETL zonder code in met gegevensstroomactiviteiten.
- Orkestreren van notebooks, Spark-taken, opgeslagen procedures, SQL-scripts en meer.
- Bewaak resources, gebruik en gebruikers in SQL en Spark.
- Gebruik op rollen gebaseerd toegangsbeheer om de toegang tot analysebronnen te vereenvoudigen.
- Schrijf SQL- of Spark-code en integreer met CI/CD-processen voor ondernemingen.
De architectuur van Microsoft Azure Synapse is als volgt:

Voor meer informatie over Microsoft Azure Synapse, zie Wat is Azure Synapse Analytics?
Azure SQL plus Azure Machine Learning
U kunt de functionaliteit van SQL Server Big Data-clusters vervangen door een of meer Azure SQL-databaseopties te gebruiken voor operationele gegevens en Microsoft Azure Machine Learning voor uw voorspellende workloads.
Azure Machine Learning is een cloudservice die kan worden gebruikt voor elk type machine learning, van klassieke ML tot deep learning, supervisie en leren zonder supervisie. Of u nu liever Python- of R-code schrijft met de SDK of werkt met opties zonder code/weinig code in de studio, u kunt machine learning- en deep learning-modellen bouwen, trainen en volgen in een Azure Machine Learning-werkruimte. Met Azure Machine Learning kunt u beginnen met trainen op uw lokale computer en vervolgens uitschalen naar de cloud. De service werkt ook samen met populaire opensource-hulpprogramma's voor deep learning en versterking, zoals PyTorch, TensorFlow, scikit-learn en Ray RLlib.
Gebruik Microsoft Azure Machine Learning als vervanging voor SQL Server 2019 Big Data-clusters wanneer u het volgende nodig hebt:
- Een webomgeving op basis van een ontwerpfunctie voor Machine Learning: sleep-n-drop-modules om uw experimenten te bouwen en implementeer vervolgens pijplijnen in een omgeving met weinig code.
- Jupyter-notebooks: gebruik onze voorbeeldnotebooks of maak uw eigen notebooks om onze SDK te gebruiken voor Python-voorbeelden voor uw machine learning.
- R-scripts of notebooks waarin u de SDK voor R gebruikt om uw eigen code te schrijven of de R-modules in de ontwerpfunctie te gebruiken.
- De Oplossingsversneller veel modellen bouwt voort op Azure Machine Learning en stelt u in staat om honderden of zelfs duizenden machine learning-modellen te trainen, te gebruiken en te beheren.
- Machine learning-extensies voor Visual Studio Code (preview) bieden u een volledige ontwikkelomgeving voor het bouwen en beheren van uw machine learning-projecten.
- Azure Machine Learning omvat een Machine Learning Command-Line-interface (CLI), inclusief een Azure CLI-extensie die opdrachten biedt voor het beheren van Azure Machine Learning-resources vanaf de opdrachtregel.
- Integratie met opensource-frameworks zoals PyTorch, TensorFlow en scikit-learn en nog veel meer voor het trainen, implementeren en beheren van het end-to-end machine learning-proces.
- Bekrachtigingsleren met Ray RLlib.
- MLflow voor het bijhouden van metrische gegevens en het implementeren van modellen of Kubeflow om end-to-end-werkstroompijplijnen te bouwen.
De architectuur van een Microsoft Azure Machine Learning-implementatie is als volgt:

Zie Hoe Azure Machine Learning werkt voor meer informatie over Microsoft Azure Machine Learning.
Azure SQL van Databricks
U kunt de functionaliteit van SQL Server Big Data-clusters vervangen met behulp van een of meer Azure SQL-databaseopties voor operationele gegevens en Microsoft Azure Databricks voor uw analyseworkloads.
Azure Databricks is een platform voor gegevensanalyse dat is geoptimaliseerd voor het Microsoft Azure-cloudservicesplatform. Azure Databricks biedt twee omgevingen voor het ontwikkelen van gegevensintensieve toepassingen: Azure Databricks SQL Analytics en Azure Databricks Workspace.
Azure Databricks SQL Analytics biedt een gebruiksvriendelijk platform voor analisten die SQL-query's willen uitvoeren op hun data lake, meerdere visualisatietypen maken om queryresultaten vanuit verschillende perspectieven te verkennen en dashboards te bouwen en te delen.
Azure Databricks Workspace biedt een interactieve werkruimte waarmee gegevenstechnici, gegevenswetenschappers en machine learning-engineers kunnen samenwerken. Voor een big data-pijplijn worden de gegevens (onbewerkt of gestructureerd) opgenomen in Azure via Azure Data Factory in batches of bijna in realtime gestreamd met behulp van Apache Kafka, Event Hubs of IoT Hub. Deze gegevens komen terecht in een data lake voor langdurige persistente opslag, in Azure Blob Storage of Azure Data Lake Storage. Als onderdeel van uw analysewerkstroom gebruikt u Azure Databricks om gegevens uit meerdere gegevensbronnen te lezen en om te zetten in baanbrekende inzichten met behulp van Spark.
Gebruik Microsoft Azure Databricks als vervanging voor SQL Server 2019 Big Data Clusters wanneer u het volgende nodig hebt:
- Volledig beheerde Spark-clusters met Spark SQL en DataFrames.
- Streaming voor realtime gegevensverwerking en -analyse voor analytische en interactieve toepassingen, integreren met HDFS, Flume en Kafka.
- Toegang tot de MLlib-bibliotheek, bestaande uit algemene leeralgoritmen en hulpprogramma's, waaronder classificatie, regressie, clustering, gezamenlijke filtering, dimensionaliteitsreductie en onderliggende optimalisatieprimitieven.
- Documentatie van je voortgang in notebooks in R, Python, Scala of SQL.
- Visualisatie van gegevens in een paar stappen, met behulp van vertrouwde hulpprogramma's zoals Matplotlib, ggplot of d3.
- Interactieve dashboards voor het maken van dynamische rapporten.
- GraphX, voor grafieken en grafiekberekeningen voor een breed scala aan gebruiksvoorbeelden van cognitieve analyses tot gegevensverkenning.
- Het maken van clusters in seconden, met dynamische automatische schaalaanpassing van clusters, die ze delen tussen teams.
- Programmatische clustertoegang met behulp van REST API's.
- Directe toegang tot de nieuwste Apache Spark-functies met elke release.
- Een Spark Core-API: bevat ondersteuning voor R, SQL, Python, Scala en Java.
- Een interactieve werkruimte voor verkenning en visualisatie.
- Volledig beheerde SQL-eindpunten in de cloud.
- SQL-query's die worden uitgevoerd op volledig beheerde SQL-eindpunten, afhankelijk van de querylatentie en het aantal gelijktijdige gebruikers.
- Integratie met Microsoft Entra ID (voorheen Azure Active Directory).
- Op rollen gebaseerde toegang voor verfijnde gebruikersmachtigingen voor notebooks, clusters, taken en gegevens.
- SLA's op bedrijfsniveau.
- Dashboards voor het delen van inzichten, het combineren van visualisaties en tekst om inzichten te delen die zijn opgehaald uit uw query's.
- Met waarschuwingen kunt u bewaken en integreren en een melding ontvangen wanneer een veld dat door een query wordt geretourneerd, voldoet aan een drempelwaarde. Gebruik waarschuwingen om uw bedrijf te monitoren of integreer ze met bepaalde tools voor het starten van werkstromen, zoals het onboarden van gebruikers of ondersteuningstickets.
- Bedrijfsbeveiliging, waaronder Integratie van Microsoft Entra-id's, besturingselementen op basis van rollen en SLA's die uw gegevens en uw bedrijf beschermen.
- Integratie met Azure-services en Azure-databases en -archieven, waaronder Synapse Analytics, Cosmos DB, Data Lake Store en Blob Storage.
- Integratie met Power BI en andere BI-hulpprogramma's, zoals Tableau Software.
De architectuur van een Microsoft Azure Databricks-implementatie is als volgt:
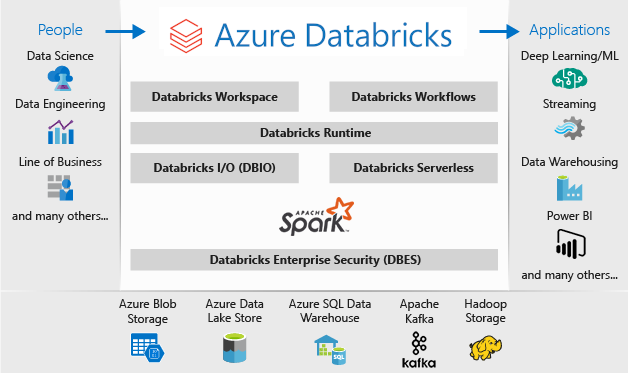
Voor meer informatie over Microsoft Azure Databricks, zie
Hybrid
Spiegelen in Microsoft Fabric
Als een datareplicatie-optie is Databasespiegeling in Fabric een goedkope en lage latentie oplossing om gegevens uit verschillende systemen samen te brengen in één analytisch platform. U kunt uw bestaande gegevensomgeving continu rechtstreeks repliceren naar OneLake van Fabric, inclusief gegevens van SQL Server 2016+, Azure SQL Database, Azure SQL Managed Instance, Oracle, Snowflake, Cosmos DB en meer.
Met de meest recente gegevens in een doorzoekbare indeling in OneLake kunt u nu alle verschillende services in Fabric gebruiken, zoals het uitvoeren van analyses met Spark, het uitvoeren van notebooks, gegevenstechniek, het visualiseren via Power BI-rapporten en meer.
Spiegeling in Fabric biedt een eenvoudige ervaring om de time-to-value voor inzichten en beslissingen te versnellen en om gegevenssilo's tussen technologieoplossingen op te splitsen, zonder dure ETL-processen (Extract, Transform en Load) te ontwikkelen om gegevens te verplaatsen.
Met Mirroring in Fabric hoeft u geen verschillende services van meerdere leveranciers samen te voegen. In plaats daarvan kunt u genieten van een zeer geïntegreerd, end-to-end en gebruiksvriendelijk product dat is ontworpen om uw analysebehoeften te vereenvoudigen en gebouwd voor openheid en samenwerking tussen technologieoplossingen die de opensource Delta Lake-tabelindeling kunnen lezen.
Voor meer informatie, zie:
- Gespiegelde Microsoft Fabric-databases
- Bewaking van gespiegelde Microsoft Fabric-databases
- Gegevens in uw gespiegelde database verkennen met Behulp van Microsoft Fabric
- Wat is Microsoft Fabric?
- Modelgegevens in het standaard semantische Power BI-model in Microsoft Fabric
- Wat is het SQL-analyse-eindpunt voor een Lakehouse?
- Direct Lake
Microsoft SQL Server op Windows, Apache Spark en objectopslag on-premises
U kunt SQL Server installeren in Windows of Linux en de hardwarearchitectuur omhoog schalen met behulp van de objectopslagfunctie van SQL Server 2022 (16.x) en de PolyBase-functie om query's in te schakelen voor alle gegevens in uw systeem.
Door een uitschaalplatform zoals Apache Hadoop of Apache Spark te installeren en te configureren, kunt u query's uitvoeren op niet-relationele gegevens op schaal. Met behulp van een centrale set Object-Storage systemen die ondersteuning bieden voor de S3-API kunnen zowel SQL Server 2022 (16.x) als Spark toegang krijgen tot dezelfde set gegevens in alle systemen.
U kunt ook het Kubernetes-containerindelingssysteem voor uw implementatie gebruiken. Hierdoor kan een declaratieve architectuur on-premises of in elke cloud worden uitgevoerd die Kubernetes of het Red Hat OpenShift-platform ondersteunt. Zie Een SQL Server-containercluster implementeren in Azure of het implementeren van SQL Server 2019 in Kubernetes bekijken voor meer informatie over het implementeren van SQL Server in een Kubernetes-omgeving.
Gebruik SQL Server en Hadoop/Spark on-premises als vervanging voor SQL Server 2019 Big Data Clusters wanneer u het volgende moet doen:
- De volledige oplossing on-premises behouden
- Toegewezen hardware gebruiken voor alle onderdelen van de oplossing
- Toegang tot relationele en niet-relationele gegevens uit dezelfde architectuur, in beide richtingen
- Deel een enkele set niet-relationele gegevens tussen SQL Server en het schaalbare niet-relationele systeem.
De migratie uitvoeren
Zodra u een locatie (In-Cloud of hybride) voor uw migratie hebt gekozen, moet u de downtime en kostenvectoren wegen om te bepalen of u een nieuw systeem uitvoert en de gegevens van het vorige systeem verplaatst naar de nieuwe in realtime (naast elkaar staande migratie) of een back-up en herstel, of een nieuw begin van het systeem vanuit bestaande gegevensbronnen (in-place migratie).
De volgende beslissing bestaat uit het herschrijven van de huidige functionaliteit in uw systeem met behulp van de nieuwe architectuurkeuze of het verplaatsen van zoveel mogelijk code naar het nieuwe systeem. Hoewel de vorige keuze langer kan duren, kunt u de nieuwe methoden, concepten en voordelen van de nieuwe architectuur gebruiken. In dat geval zijn de gegevenstoegang en functionaliteitskaarten de belangrijkste planningsinspanningen waarop u zich moet richten.
Als u van plan bent om het huidige systeem met zo weinig mogelijk codewijziging te migreren, is de taalcompatibiliteit uw primaire focus voor het plannen.
Codemigratie
De volgende stap is het controleren van de code die het huidige systeem gebruikt en welke wijzigingen het moet uitvoeren op de nieuwe omgeving.
Er zijn twee primaire vectoren voor codemigratie om rekening mee te houden:
- Bronnen en verzamelpunten
- Migratie van functionaliteit
Bronnen en verzamelpunten
De eerste taak in codemigratie is het identificeren van de verbindingsmethoden, tekenreeksen of API's van de gegevensbron die door de code worden gebruikt voor toegang tot de gegevens die worden geïmporteerd, het pad en de uiteindelijke bestemming. Documenteer deze bronnen en maak een kaart naar de locaties van de nieuwe architectuur.
- Als de huidige oplossing gebruikmaakt van een pijplijnsysteem om de gegevens door het systeem te verplaatsen, wijst u de nieuwe architectuurbronnen, stappen en sinks toe aan de onderdelen van de pijplijn.
- Als de nieuwe oplossing ook de pijplijnarchitectuur vervangt, behandelt u het systeem als een nieuwe installatie voor planningsdoeleinden, zelfs als u de hardware of het cloudplatform opnieuw gebruikt als vervanging.
Migratie van functionaliteit
Het meest complexe werk dat nodig is in een migratie, is om te verwijzen naar, bij te werken of de documentatie te maken van de functionaliteit van het huidige systeem. Als u een in-place upgrade plant en probeert de hoeveelheid herschrijven van code zoveel mogelijk te verminderen, duurt deze stap de meeste tijd.
Een migratie van een eerdere technologie is echter vaak een optimale tijd om uzelf bij te werken over de nieuwste ontwikkelingen in technologie en te profiteren van de constructies die het biedt. Vaak kunt u meer beveiliging, prestaties, functiekeuzen en zelfs kostenoptimalisaties krijgen door uw huidige systeem opnieuw te schrijven.
In beide gevallen hebt u twee primaire factoren die betrokken zijn bij de migratie: de code en talen die het nieuwe systeem ondersteunt, en de keuzes voor gegevensverplaatsing. Normaal gesproken moet u verbindingsreeksen van het huidige big data-cluster kunnen wijzigen in het SQL Server-exemplaar en de Spark-omgeving. Alle gegevens over gegevensverbindingen en de code-cutover moeten minimaal zijn.
Als u een herschrijfversie van uw huidige functionaliteit wilt maken, wijst u de nieuwe bibliotheken, pakketten en DLL's toe aan de architectuur die u voor uw migratie hebt gekozen. U vindt een lijst met alle bibliotheken, talen en functies die elke oplossing biedt in de documentatieverwijzingen die in de vorige secties worden weergegeven. Wijs verdachte of niet-ondersteunde talen toe en plan de vervanging met de gekozen architectuur.
Opties voor gegevensmigratie
Er zijn twee algemene benaderingen voor gegevensverplaatsing in een grootschalig analysesysteem. De eerste is het maken van een cutover-proces waarbij het oorspronkelijke systeem gegevens blijft verwerken en die gegevens worden samengeteld in een kleinere set geaggregeerde rapportgegevensbron. Het nieuwe systeem begint vervolgens met nieuwe gegevens en wordt vanaf de migratiedatum gebruikt.
In sommige gevallen moeten alle gegevens van het verouderde systeem naar het nieuwe systeem worden verplaatst. In dit geval kunt u de oorspronkelijke bestandsarchieven van SQL Server Big Data Clusters koppelen als het nieuwe systeem dit ondersteunt en de gegevens vervolgens naar het nieuwe systeem kopiëren, of u kunt een fysieke verplaatsing maken.
Het migreren van uw huidige gegevens van SQL Server 2019 Big Data Clusters naar een ander systeem is sterk afhankelijk van twee factoren: de locatie van uw huidige gegevens en de bestemming on-premises of naar de cloud.
Gegevensmigratie op locatie
Voor on-premises naar on-premises migraties kunt u de SQL Server-gegevens migreren met een back-up- en herstelstrategie, of u kunt replicatie instellen om sommige of al uw relationele gegevens te verplaatsen. SQL Server Integration Services kan ook worden gebruikt om gegevens van SQL Server naar een andere locatie te kopiëren. Zie SQL Server Integration Services voor meer informatie over het verplaatsen van gegevens met SSIS.
Voor de HDFS-gegevens in uw huidige SQL Server Big Data Cluster-omgeving is de standaardmethode om de gegevens te koppelen aan een zelfstandig Spark-cluster en het objectopslagproces te gebruiken om de gegevens te verplaatsen, zodat een SQL Server 2022-exemplaar (16.x) er toegang toe heeft of het as-is en deze met Spark-taken kan blijven verwerken.
Gegevensmigratie in de cloud
Voor gegevens die zich in de cloudopslag of on-premises bevinden, kunt u Azure Data Factory gebruiken, met meer dan 90 connectors voor een volledige pijplijn voor overdracht, met planning, bewaking, waarschuwingen en andere services. Voor meer informatie over Azure Data Factory, zie Wat is Azure Data Factory?
Als u grote hoeveelheden gegevens veilig en snel van uw lokale gegevensomgeving naar Microsoft Azure wilt verplaatsen, kunt u de Azure Import/Export-service gebruiken. De Azure Import/Export-service wordt gebruikt om grote hoeveelheden gegevens veilig te importeren in Azure Blob Storage en Azure Files door schijfstations naar een Azure-datacenter te verzenden. Deze service kan ook worden gebruikt om gegevens over te dragen van Azure Blob-opslag naar schijfstations, en te verzenden naar uw on-premises locaties. Gegevens van een of meer schijfstations kunnen worden geïmporteerd in Azure Blob Storage of Azure Files. Voor extreem grote hoeveelheden gegevens kan het gebruik van deze service het snelste pad zijn.
Als u gegevens wilt overdragen met behulp van schijfstations die door Microsoft worden geleverd, kunt u Azure Data Box Disk gebruiken om gegevens in Azure te importeren. Zie Wat is de Azure Import/Export-service voor meer informatie?
Zie Azure Data Lake Storage Gen1 gebruiken voor big data-vereisten voor meer informatie over deze keuzes en de bijbehorende beslissingen.