Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
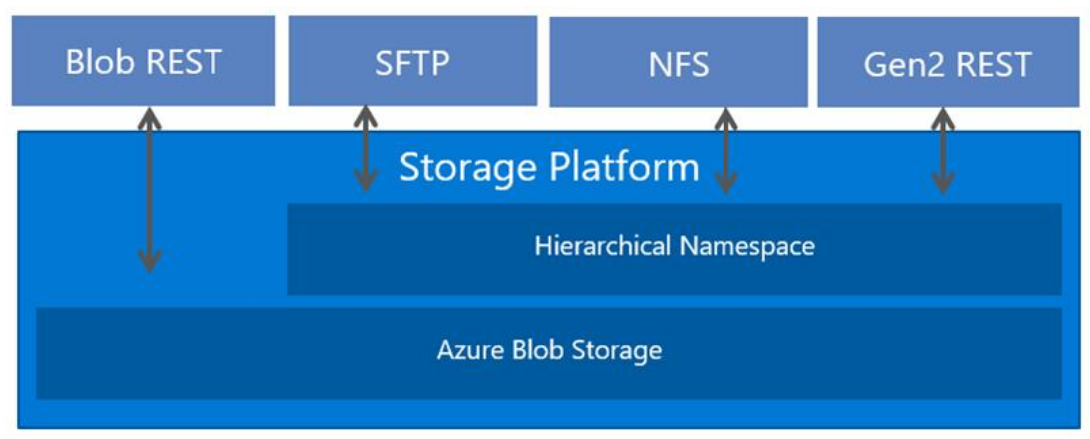
Azure Blob Storage ondersteunt nu het NFS-protocol (Network File System) 3.0. Deze ondersteuning biedt compatibiliteit van Linux-bestandssystemen op de schaal en met de kosten van objectopslag, en stelt Linux-clients in staat om een container in Blob Storage te mounten vanaf een virtuele Azure-machine (VM) of een on-premises computer.
Het is een uitdaging om grootschalige verouderde workloads, zoals High Performance Computing (HPC), uit te voeren in de cloud. Een van de redenen hiervoor is dat toepassingen vaak gebruikmaken van traditionele bestandsprotocollen, zoals NFS, om toegang te krijgen tot gegevens. Systeemeigen cloudopslagservices die zijn gericht op objectopslag, hebben ook een platte naamruimte en uitgebreide metagegevens in plaats van bestandssystemen die een hiërarchische naamruimte en efficiënte metagegevensbewerkingen bieden.
Blob Storage ondersteunt nu een hiërarchische naamruimte. In combinatie met ondersteuning voor NFS 3.0-protocollen maakt Azure het veel eenvoudiger om verouderde toepassingen uit te voeren op grootschalige cloudobjectopslag.
Toepassingen en workloads die geschikt zijn voor het gebruik van NFS 3.0 met Blob Storage
De NFS 3.0-protocolfunctie is geoptimaliseerd voor grootschalige, lezen-intensieve workloads met sequentiële invoer/uitvoer. Het is ideaal voor scenario's waarbij meerdere lezers en talloze threads nodig zijn waarbij doorvoer belangrijker is dan lage latentie. Dit zijn enkele veel voorkomende voorbeelden:
High performance computing: HPC-taken omvatten vaak duizenden kernen die dezelfde grote gegevenssets gelijktijdig lezen. De NFS 3.0-protocolfunctie maakt gebruik van objectopslagdoorvoer om knelpunten van traditionele bestandsservers te elimineren. Hieronder vindt u enkele voorbeelden:
- Genomische sequencing: Het bewerken van enorme DNA-gegevenssets.
- Modellering van financiële risico's: Monte Carlo-simulaties gebruiken op historische gegevens.
- Seismische analyse: Analyse van geologische gegevens voor olie- en gasverkenning.
- Weersvoorspelling: Atmosferische gegevens modelleren voor klimaat- en stormvoorspelling.
Big data en analyses (data lakes):veel analysehulpprogramma's vereisen hiërarchische mappen. BlobNFS (via Azure Data Lake Storage Gen2) levert deze structuur en ondersteunt standaardbestandsprotocollen. Hieronder vindt u enkele voorbeelden:
- Machine learning: trainingsgegevens invoeren voor GPU-clusters met behulp van standaardbestands-I/O.
- Log Analytics: Logboeken uit duizenden bronnen aggregeren.
Advanced Driver Assistance Systems (ADAS): ADAS-werkstromen produceren petabytes aan sequentiële sensorgegevens, zoals LiDAR-puntwolken en camerafeeds met hoge resolutie. De gegevens moeten efficiënt worden opgenomen en op schaal worden geanalyseerd voor simulatie- en modeltraining. Een voorbeeld is het opslaan van onbewerkte LiDAR-scans en videostreams met meerdere camera's van autonome testvoertuigen met behulp van NFS 3.0 en vervolgens grootschalige replaysimulaties uitvoeren op duizenden rekenknooppunten om waarnemingsalgoritmen te valideren.
Media en entertainment: Rendering farms hebben efficiënte toegang nodig tot grote asset-bibliotheken. NFS 3.0 via blob biedt een bestandsinterface voor verouderde renderinghulpprogramma's die bestandspaden verwachten. Hieronder vindt u enkele voorbeelden:
- Videorendering: Bron-assets lezen met gedistribueerde knooppunten.
- Transcodering: grote onbewerkte videobestanden converteren in streamingsformaten.
Databaseback-up: een rendabel NFS 3.0-doel met hoge doorvoer zonder complexe connectors of dure momentopnamen. Oracle RMAN kan grote back-upstukken rechtstreeks schrijven voor archivering op lange termijn en direct herstellen vanuit elke op NFS gekoppelde Linux-VM inschakelen.
Wanneer u NFS 3.0 niet moet gebruiken met Blob Storage
Vermijd gebruik voor bestandsshares voor algemeen gebruik of transactionele workloads vanwege de kenmerken van objectopslag:
| Werkbelastingtype | Reden | Beter alternatief |
|---|---|---|
| Transactionele databases | Vereist gedetailleerde vergrendeling, latentie van submilliseconden en frequente willekeurige schrijfbewerkingen. | Beheerde schijven of Azure NetApp Files of Azure Files |
| In situ bestandsbewerking | Het bewerken van bestanden dwingt volledige blob-herschrijven af, waardoor bewerkingen inefficiënt worden. | Azure Files |
NFS 3.0 en de hiërarchische naamruimte
Ondersteuning voor NFS 3.0-protocollen vereist dat blobs worden ingedeeld in een hiërarchische naamruimte. U kunt een hiërarchische naamruimte inschakelen wanneer u een opslagaccount maakt.
Azure Data Lake Storage heeft de mogelijkheid geïntroduceerd om een hiërarchische naamruimte te gebruiken. Het ordent objecten (bestanden) in een hiërarchie van mappen en submappen op dezelfde manier als het bestandssysteem op uw computer is georganiseerd. De hiërarchische naamruimte wordt lineair geschaald en verslechtert de gegevenscapaciteit of prestaties niet. Verschillende protocollen breiden zich uit van de hiërarchische naamruimte. Het NFS 3.0-protocol is een van de beschikbare protocollen.
Gegevens die zijn opgeslagen als blok-blobs
Wanneer uw toepassing een aanvraag indient met behulp van het NFS 3.0-protocol, wordt die aanvraag omgezet in een combinatie van blok-blobbewerkingen. NFS 3.0 leest bijvoorbeeld RPC-aanvragen (Remote Procedure Call) om in Get Blob-bewerkingen . RPC-schrijfanvragen van NFS 3.0 worden omgezet in een combinatie van Get Block List, Put Block en Put Block List.
Blok-blobs zijn geoptimaliseerd om grote hoeveelheden leesintensieve gegevens efficiënt te verwerken. Block blobs bestaan uit blokken. Een blok-id identificeert elk blok. Een blok-blob kan maximaal 50.000 blokken bevatten. Elk blok in een blok-blob kan een andere grootte hebben, tot de maximale grootte die is toegestaan voor de serviceversie die door uw account wordt gebruikt.
| NFSv3 RPC | REST API-bewerking |
|---|---|
| Metagegevens en kenmerken | |
Nfs3GetAttr |
Get Blob Properties |
Nfs3SetAttr |
Set Blob Properties (Als de bestandsgrootte is ingesteld, Nfs3Write wordt aangeroepen.) |
Nfs3Lookup |
Get Blob Properties |
Nfs3Access |
Get Blob Properties |
Nfs3Readlink |
Get Blob Properties |
Nfs3FsStat |
Get Blob Properties |
Nfs3Fsinfo |
Get Blob Properties |
Nfs3Pathconf |
Get Blob Properties |
| Opsomming van directory | |
Nfs3ReadDir |
List Blobs |
Nfs3ReadDirPlus |
List Blobs |
| Leesbewerkingen | |
Nfs3Read |
Get Blob |
Nfs3ReadLink |
Get Blob Properties
+
Get Blob van het onderliggende bestand. |
| Schrijfbewerkingen | |
NFs3Write |
Get Block List (1) + Put Block (x) + Put Block List (1) |
Nfs3Commit |
Geen bewerking. |
| Levenscyclus van bestanden | |
Nfs3Create |
Put Blob + Get Blob Properties |
Nfs3Remove |
Delete Blob |
Nfs3Rename |
Niet ondersteund (geen 1-1 toewijzing). |
Nfs3Link |
Wordt niet ondersteund. |
| Directorybeheer | |
Nfs3MkDir |
Put Blob + Get Blob Properties |
Nfs3RmDir |
Put Blob |
| Overige | |
Nfs3SymLink |
Put Blob + Get Blob Properties |
Nfs3MkNod |
Wordt niet ondersteund. |
Nfs3Null |
Geen bewerking. |
Resultaten van cachetreffers of missers kunnen andere Get Blob Properties aanvragen activeren om kenmerken vóór bewerking en na bewerking te verkrijgen. Verschillende variabelen zijn van invloed op het aantal Blob Storage-transacties voor end-to-endbewerkingen (bijvoorbeeld het lezen of schrijven van bestanden) en kunnen verschillen tussen iteraties. Als u het aantal transacties voor representatieve workloads wilt schatten, gebruikt u de Blob Storage logboeken voor voorbeeldscenario's.
Algemene werkstroom: Een opslagaccountcontainer koppelen
Uw Linux-clients kunnen een container in Blob Storage koppelen vanaf een Azure-VM of een on-premises computer. Voer de volgende taken uit om een container voor een opslagaccount te koppelen:
- Maak een virtueel netwerk van Azure.
- Netwerkbeveiliging configureren.
- Maak en configureer een opslagaccount dat alleen verkeer van het virtuele netwerk accepteert.
- Maak een container in het opslagaccount.
- Plaats de container.
Zie Blob Storage koppelen met behulp van het NFS-protocol (Network File System) 3.0 voor stapsgewijze instructies.
Netwerkbeveiliging
Verkeer moet afkomstig zijn van een virtueel netwerk. Met een virtueel netwerk kunnen clients veilig verbinding maken met uw opslagaccount. De enige manier om de gegevens in uw account te beveiligen, is door gebruik te maken van een virtueel netwerk en andere netwerkbeveiligingsinstellingen. Elk ander hulpprogramma dat wordt gebruikt voor het beveiligen van gegevens, waaronder autorisatie van accountsleutels, Microsoft Entra-beveiliging en toegangsbeheerlijsten (ACL's), kan niet worden gebruikt om een NFS 3.0-aanvraag te autoriseren.
Zie De aanbevelingen voor netwerkbeveiliging voor Blob Storage voor meer informatie.
Opmerking
Openbare IP-filtering voor toegang tot uw opslagaccount wordt niet ondersteund.
Ondersteunde netwerkverbindingen
Clients kunnen verbinding maken via een openbaar of privé-eindpunt als de verbinding afkomstig is van een van de volgende netwerklocaties:
Het virtuele netwerk dat u configureert voor uw opslagaccount.
In dit artikel verwijzen we naar dat virtuele netwerk als het primaire virtuele netwerk. Zie Toegang verlenen vanuit een virtueel netwerk voor meer informatie.
Een gekoppeld virtueel netwerk dat zich in dezelfde regio bevindt als het primaire virtuele netwerk.
U moet uw opslagaccount configureren om toegang tot dit gekoppelde virtuele netwerk toe te staan. Zie Toegang verlenen vanuit een virtueel netwerk voor meer informatie.
Een on-premises netwerk dat is verbonden met uw primaire virtuele netwerk met behulp van Azure VPN Gateway of een Azure ExpressRoute-gateway.
Zie Toegang configureren vanuit on-premises netwerken voor meer informatie.
Een on-premises netwerk dat is verbonden met een gekoppeld netwerk.
U kunt een VPN-gateway of een ExpressRoute-gateway gebruiken, samen met gatewaytransit.
Belangrijk
Het NFS 3.0-protocol maakt gebruik van poort 111 en 2048. Als u verbinding maakt vanuit een on-premises netwerk, moet u ervoor zorgen dat uw client uitgaande communicatie via deze poorten toestaat. Als u toegang hebt verleend tot specifieke virtuele netwerken, moet u ervoor zorgen dat alle netwerkbeveiligingsgroepen die zijn gekoppeld aan die virtuele netwerken geen beveiligingsregels bevatten die binnenkomende communicatie via deze poorten blokkeren.
Bekende problemen en beperkingen
Zie Bekende problemen voor een volledige lijst met problemen en beperkingen met de huidige versie van NFS 3.0-ondersteuning.
Prijzen
Zie de pagina met prijzen voor Azure Blob Storage voor gegevensopslag en transactiekosten.