Cloud computing guide for researchers – Understanding shipping behaviour with Microsoft Azure
Keeping track of global shipping has previously suffered from a lack of data. Current tracking technology has transformed the problem into one of an overabundance of information, as huge amounts of vessel tracking data are slowly becoming available, mostly due to the Automatic Identification System (AIS). Due to the volume of this data, traditional data mining and machine learning approaches are challenged when called upon to decipher the complexity of these environments. Scientists from the University of the Aegean, Dept. Product & Systems and Design Engineering and MarineTraffic (the leading vessel tracking website), are using data science in the cloud to transform billions of records of spatiotemporal (AIS) data into information for understanding the patterns of global trade by adopting distributed processing approaches. The research team led by Assoc Prof. Dimitris Zissis, is leveraging novel algorithmic approaches and Microsoft Azure, to transform Big Data into actionable information for a multitude of maritime stakeholders. Members of the team include: Giannis Spiliopoulos, Researcher at MarineTraffic; Konstantinos Chatzikokolakis, Senior Researcher at MarineTraffic; Elias Xidias, Senior Researcher at the University of the Aegean.

Why?
The importance of a well-developed understanding of the maritime traffic patterns and trade routes is critical to all seafarers and maritime stakeholders. Unlike roads, shipping lanes are not carved in stone. Their size, boundaries and content vary over space and time, under the influence of external sources. Today we only have a vague understanding of the specific routes vessels follow when travelling between ports, which is an essential metric for calculating any valid maritime statistics and indicators (e.g trade indicators, emissions and others). From a security perspective, it is necessary for understanding areas of high congestion, so that smaller vessels can avoid collisions with bigger ships. Moreover, an understanding of vessel patterns at scale can assist in the identification of anomalous behaviors and help predict the future location of vessels. Additionally, by combining ship routes with a model to estimate the emission of vessels (which depends on travel distance, speed, draught, weather conditions and characteristics of the vessel itself), emissions of e.g. CO2 and NOx can be estimated per ship and per national territory
From data to knowledge
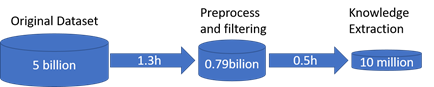
Data is received through the MarineTraffic system and for the purposes of this work we use a dataset of approximately 5 billion messages recorded from January to December 2016. As the amount of available spatiotemporal data grows to massive scales, it is becoming clear that applying traditional techniques to AIS data processing can lead to processing times of several days, if applied to global data sets of considerable size (current datset over 500G). Due to this, for the distributed processing tasks, we rely on a HDInsight Azure Spark (2.1.0 ver-sion) cluster made up by: 6 worker nodes (D4v2 Azure nodes), each one equipped with 8 processing cores and 28 GB RAM; and 2 head nodes (D12 v2 Azure nodes), each one equipped with 4 processing cores and 28 GB RAM, summing up to a total of 56 computing cores and 224 GB RAM.
The work is described in detail in Giannis Spiliopoulos, Dimitrios Zissis, Konstantinos Chatzikokolakis, A Big Data Driven Approach to Extracting Global Trade Patterns, Mobility Analytics for Spatio-temporal and Social Data with VLDB 2017, Munich 2017.
Global scale data analysis for researchers
Today, the growing number of distributed sensors and tracking systems are generating overwhelming amounts of high velocity spatiotemporal data. Processing these datasets is a highly complex task. Traditional state of the art techniques and technologies have proven incapable of dealing with such volumes of loosely structured spatiotemporal data. Towards building more efficient systems, methods of distributing processing and storage across a cluster of computers has been proposed. The trend towards more data (big data) is leading to changes in the computing paradigm, and in particular to the notion of computational approaches. A transition is currently taking place from a computing-centric model where data live on disk and are moved to a central processing unit for computational tasks towards a data-centric model, where computation is moved towards the data.
Using services from Microsoft's Azure, the project harnesses the power of the cloud to perform complex analytics on these datasets. Thanks to Microsoft Azure the researchers are able to reduce the processing time from several days to just a few hours. Find out more on our Cloud Computing Guide for Researchers.
Need access to Microsoft Azure?
There are several ways you can get access to Microsoft Azure for your research. Your university may already make Azure available to you, so first port of call is to speak to your research computing department. There are also other ways for you to start experimenting with the cloud: