1+1 Redundancy Just Isn't Good Enough
1+1 redundancy for production services is a flawed design approach.
+1 redundancy is like the kind of logic my wife uses with me when I go on an overnight business trip. She will insist that I take at least two pairs of socks in my bag even though I plan to be home the very next evening. The logic is that I might accidently step in a puddle and would need a clean pair of socks. Yes, she also wants me to take an extra pair of shoes but let’s just stick with the socks for now. Certainly there is a chance that I might step in a puddle and need an extra pair of dry socks but I find that when such and incident does occur and I need my extra pair of socks something else tends to happen like my flight getting canceled and me being forced to stay over an extra night.
To be clear I am very pleased that my wife insisted on the extra pair of socks and I wish I’d listened to her about the shoe thing too but the real problem was that when given a chance, more than one thing will eventually go wrong and then you find yourself in a long line in the airport waiting to go standby on a flight that only gets you half way to your destination and you wonder where that awful smell is coming from. Then you realize you are the one wearing the dirty socks from the day before and you are stinking up the place.
When I talk about 1+1 redundancy, it is usually in terms of two servers performing the same role like a pair of SQL Servers doing log shipping to keep each one up to date or a pair of routers with redundant routing tables. There is a great paper on flatter network architecture from Microsoft Research on the Monsoon project that you can find here. Whatever device or service you want to imagine is just fine. The key point is that they are a pair doing the same job and they are designed in such a way that if one should fail the other will pick up and charge forward. Unfortunately that just isn’t good enough.
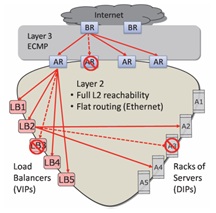
Figure 1: The Monsoon project (see paper here) flattens the network architecture and moves networking to commodity hardware. This reduces cost and spreads risk.
In services 1+1 redundancy does not equal 2
The thing about 1+1 redundancy that people often forget is that when the 1 goes down you have lost your safety net and now you must react quickly in case the +1 should also fail. If this was the only exposure we had, then maybe we could live with it, but the reality is that due to ongoing maintenance and patching our 1+1 is down to just the +1 far more often than just failure scenarios. If you add up all the maintenance windows for a service, you will probably find something on the order of .005% of a year is spent in maintenance. In other words, we are at 1+1 redundancy just 99.995% of a year.
Even the best of our services struggle to maintain four 9’s of availability. It is therefore reasonable to expect that over the course of several years both units in a 1+1 configuration will experience coinciding down times. In my reviews of scores of critical outage summary reports, I have seen this pattern of cascading failures in 1+1 redundant topologies time and again.
1+1 is hard on operations and adds to the COGS (Cost of Goods Sold) for a production service.
We’ve established that due to maintenance windows and cascading failures 1+1 is at an above average risk of having both units fail at the same time. To date our automation for repair and failback in these situations is not very high so most services make up for this by increasing staffing levels in operations. Of course, this increases COGS.
Since I have managed operations teams, I can say confidently that this architecture bears a heavy burden for the on-call Operations and Product Engineers. The added cost is not when both fail, but when just one device fails. Every engineer immediately knows that the safety net is now gone and the risk of a second failure is looming. It becomes an urgent rush to get back to 1+1 redundancy as quickly as possible. This is true even in maintenance.
We hire smart engineers to be good at quickly performing repetitive manual tasks because risk of a customer impacting outage is high. That is not the most efficient use of our engineering talent.
The solution to the problems of 1+1 is 1+N.
For me, 1+N is the right solution as long as N is >= 3 and all 3 are fully active. I have had debates with individuals that had 1+1 topologies with a warm pair of warm spares. They would insist that the warm spares should count. In another posting I’ll go deeper into the problems with non-active backup solutions.
If everyone agrees that 1+N is the right way to go and most services launch with some portions of their service in a 1+N configuration, then why do we have so many places where we truncate down to 1+1? The answer is simple is as simple as dollars and cents. The answer is a bad assessment of COGS and risk. The answer is a poor application of the phrase “high availability”.
Everyone knows to avoid any single point of failure in a service so we design to eliminate them. The mistake in going with 1+1 usually occurs around the very expensive devices and the decisions folks make there to “save” money.
Big routers are very expensive. Big load balancers are very expensive. SQL Servers with multi-terabytes of unique user data are very expensive. We can’t have a single point of failure but we can’t afford more than one extra of any device in the system or the COGS model will be too high. That leads to the 1+1 mistake. Perceived cost and a need for some kind of redundancy cause teams to make this mistake time and again.

Figure 2: Portion of a physical topology diagram stacked by rack. Note SQL Servers are spread across 2 racks to reduce risk of power failure to both however they are being launched as pairs.
Operations and Test need to drive out 1+1 during design reviews
In my role I do a lot of service topology reviews. I love the big Visio diagrams printed on a large plotter with all the little pictures of servers, machine names and IP addresses listed all over the place, and lines for logical network connections. Don’t get me started. One of the things I do in these reviews is look for places in the diagram where there are two instances of something. In some cases where it is, say, an edge server for copying bits from corpnet and not really part of production two of that machine “role” makes economic sense but that is rare for these reviews. Here are some questions I like to ask when going through one of these topology reviews.
1. How can you say we are blocked by a technology limitation when we picked the technology? Can we pick something new or write it our self?
2. We could run this on lower end hardware couldn’t we? That would give us more instances of the same device wouldn’t it? Would this get us at least to 1+3?
3. Test to see if we can combine this machine role with another. If we can combine them then we can flatten the architecture.
4. Software can automate many processes. Can we automate the replication of data so we have more than two instances?
5. At least look at how we can we break the data store down to smaller stores with a hashing algorithm? Can we then get our 1+1 exposure down to less than 5% of our user base per pair?
6. Microsoft engineers, operations and product team are on the hook if we have a production outage. If one of these devices goes down in the middle, will you simply roll over and go back to sleep or will you immediately begin to troubleshoot? If not, why not? Are you willing to be on call for the next 365 days to respond to any outage? Fine. You wear the pager and you can keep your design.
When I do these reviews I don’t like answers such as “the technology won’t let us do it that way” or “team X does it this way so we should too” or the worst is “we just don’t have time to do it right.” Those answers ring hollow. 1+1 just isn’t redundant enough and everyone should stop defending it and get on to good design.
As a parting thought, consider the reliability of the US Space Shuttle program where they have five computers involved in making critical decisions for takeoff and landing.
Four identical machines, running identical software, pull information from thousands of sensors, make hundreds of milli-second decisions, vote on every decision, check with each other 250 times a second. A fifth computer, with different software, stands by to take control should the other four malfunction.
Charles Fishman, “They Write the Right Stuff,” Dec 18 2007
Despite being at 1+4 redundancy, billions of dollars in hardware, software, fuel and human lives at stake the Space Shuttle program has had 2 major disasters. One disaster occurred during takeoff in 1986 and the other upon re-entry in 2003. If you calculate the reliability of the program as 2/132 Flights this gives the program a 98.5% reliability rating. Please don’t think that I’m denigrating the space program as I have been a fan since my father worked with the shuttle astronauts at the Houston space center decades ago.
The takeaway here is that virtually all of our services aim for 99.75% or higher availability but NASA with 1+4 redundancy has not been able to achieve that level. Yes space flight is much more risky than services but my point is that critical systems need more than one level of redundancy and this is just one of many examples from multiple industries we can cite.
I fully and firmly believe 1+1 redundancy will not produce high availability and will be higher cost than a 1+N solution.
In the end, it really is like the dirty sock analogy. It’s nice to have an extra pair, but if you travel enough, you will probably run into a situation where you will have both wet feet and a canceled flight. In the case of socks, it’s just about a bit of discomfort and rude odors. In the case of services though we have customer impact and wear and tear on our staff struggling to keep a flawed design functioning and when our customers experience poor service due to bad design they are left smelling our foul stench.
This is the first of what I hope to be a regular set of blog postings. The focus of this bog will be on topics that intersect service design, testing and operations. I have many ideas for future posts but I’d like to hear from you. If you’ve read this post and found it useful and would like information on another topic please send your suggestion directly to me. Thank you in advance for any comments you may have on this post (even disagreements) and suggestions you send my way.
For more content on testing Software Plus Services see chapter 14 of “How We Test Software at Microsoft.”
Comments
Anonymous
October 26, 2010
We need to add more power to our small data center, I recieved a quote for 1 x 60KVA DSTS ( Digital Static Transfer Switch ) it has 2 inputs from 2 differant UPS's, is this 1+1?Anonymous
October 27, 2010
Wow, this is a super old Blog post. I'm a software guy, not a power guy but as I'm now in Bing and we have dealt with DC power I'll see what I can do to answer your question. 1+1 is a way of expressing the relative risk footprint. If your service is to have even three 9s of availability you can't really go with 1+1 redundancy at any point in your all up service or DC architechture. But how you derive 1+1 is relative. In Bing we use cargo containers for thousands of servers. Each Cargo container has some redundancy in power - essentually pulling power from two different systems within the data center with each on seperate diesel generator backups. So I would say that is 1+1 at the cargo container level. The thing is we have a lot of cargo containers and we do not run a single major service of Bing (say Bing Video) inside of a single cargo container and for an important service element it always has instances in multiple DCs. In that way our services have greater than 1+1 redundancy despite the cargo container chokepoint. Here is an example I've read about in the past 12 months happening at Twitter, Google, Facebook, Yahoo, and Bing. All have had errant deployments that hit a large % of production all at once. What typically happens here is that a change that is considered safe is made to say one or more Data Center's worth of machines all at once. The change causes all of those machines to fail. They may be only 25% of the total machines supporting the service but they are substantial enough that they cause cascading failures across the entire service. In this sense the automated deployment has created a risk point. One more example of risk chokepoints tends to be networks at a datacenter or regional hub. Edge routers for a DC are often pairs to provide 1+1 redundancy. One is taken out of rotation for an OS upgrade or a config change and the other is left active. Far too often during maintenance the one in active rotation fails while the other is in maintenance. Another way I have seen failures is when the one that was in maintenance is put back into rotation as primary and the secondary router is immediately taken offline for maintenance. Well the recently upgraded router looks good for a few minutes and we go into upgrade on the other one. While we are in the middle of the upgrade on the second router the one we recently put into active rotation begins to show failure symptoms. Now we don't have our failover option anymore because we are in the middle of upgrading. Boom, outage. That's not such a big deal though if you have multiple data centers and you can fail traffic over to another redundant system. Of course you have to be as big as Bing to have that level of redundancy. Wow, long answer. Maybe I should have just made it a blog post. Anyhow, hope it helped a little.