Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Databricks Asset Bundles kan rechtstreeks in de werkruimte worden gemaakt en gewijzigd.
Zie vereisten voor Databricks Asset Bundles in de werkruimte voor de vereisten voor het gebruik van bundels in de werkruimte.
Zie Wat zijn Databricks Asset Bundles?voor meer informatie over bundels.
Een bundel maken
Een bundel maken in de Databricks-werkruimte:
Navigeer naar de Git-map waar u uw bundel wilt maken.
Klik op de knop Maken en klik vervolgens op Asset bundle. U kunt ook met de rechtermuisknop klikken op de Git-map of de bijbehorende kebab in de werkruimtestructuur en op Assetbundel maken> klikken:
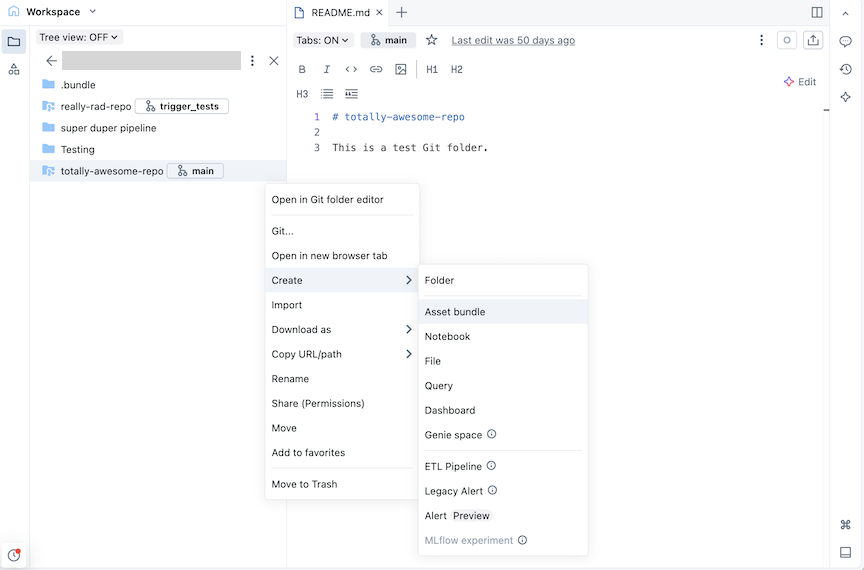
Geef in het dialoogvenster Maak een assetbundel een naam op voor de assetbundel, zoals totally-awesome-bundle. De bundelnaam mag alleen letters, cijfers, streepjes en onderstrepingstekens bevatten.
Kies voor Sjabloon of u een lege bundel wilt maken, een bundel met een Python-voorbeeldnotebook of een bundel waarop SQL wordt uitgevoerd. Als u de Lakeflow Pipelines Editor hebt ingeschakeld, ziet u ook een optie voor het maken van een ETL-pijplijnproject.
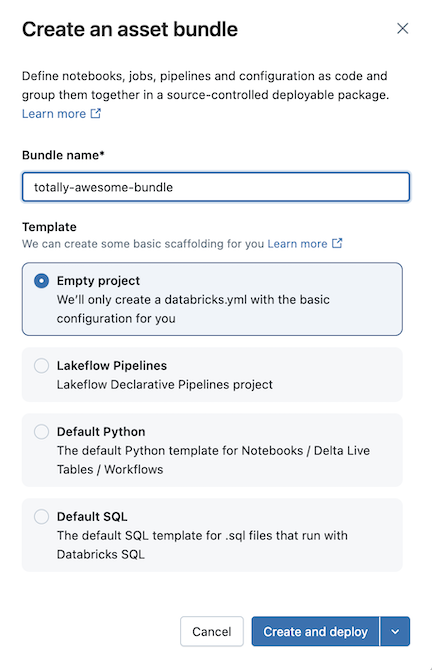
Voor sommige sjablonen is extra configuratie vereist. Klik op Volgende om het project te configureren.
Template Configuratieopties Declaratieve Pijplijnen van Lakeflow Spark - Standaardcatalogus die moet worden gebruikt voor de pijplijngegevens
- Persoonlijk schema gebruiken (aanbevolen) voor elke gebruiker die samenwerkt aan deze bundel
- Initiële taal voor de codebestanden in de pijplijn
Standaard Python - Een voorbeeldnotitieblok opnemen
- Een voorbeeldpijplijn opnemen
- Een Python-voorbeeldpakket opnemen
- Serverloze rekenkracht gebruiken
Standaard-SQL - SQL Warehouse-pad
- Initiële catalogus
- Persoonlijk schema gebruiken
- Eerste schema tijdens de ontwikkeling
Klik op Maken en implementeren.
Hiermee maakt u een eerste bundel in de Git-map, die de bestanden bevat voor de projectsjabloon die u hebt geselecteerd, een .gitignore Git-configuratiebestand en het vereiste Databricks Asset Bundles-bestand databricks.yml . Het databricks.yml bestand bevat de hoofdconfiguratie voor de bundel. Zie de configuratie van Databricks Asset Bundle voor meer informatie.
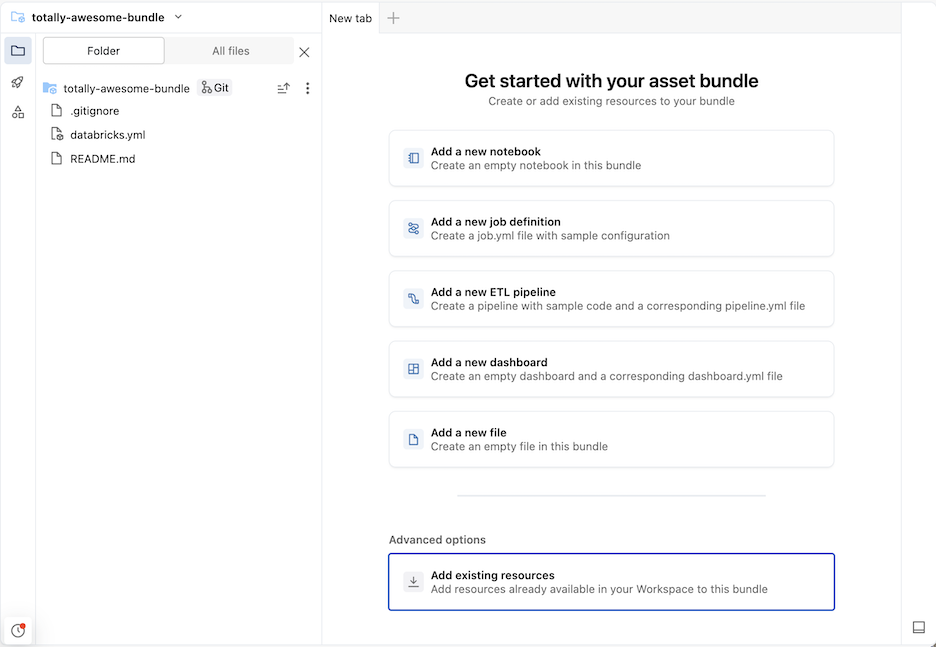
Wijzigingen in de bestanden in de bundel kunnen worden gesynchroniseerd met de externe opslagplaats die is gekoppeld aan de Git-map. Een Git-map kan veel bundels bevatten.
Nieuwe bestanden toevoegen aan een bundel
Een bundel bevat het databricks.yml bestand dat implementatie- en werkruimteconfiguraties definieert, bronbestanden, zoals notebooks, Python-bestanden en testbestanden, en definities en instellingen voor Databricks-resources, zoals Lakeflow-taken en Lakeflow Spark-declaratieve pijplijnen. Net als in elke werkruimtemap kunt u nieuwe bestanden toevoegen aan uw bundel.
Aanbeveling
Als u een nieuw tabblad wilt openen in de bundelweergave waarmee u bundelbestanden kunt wijzigen, gaat u naar de bundelmap in de werkruimte en klikt u vervolgens op Openen in editor rechts van de bundelnaam.
Broncodebestanden toevoegen
Als u nieuwe notitieblokken of andere bestanden wilt toevoegen aan een bundel in de gebruikersinterface van de werkruimte, gaat u naar de bundelmap en gaat u als volgt te werk:
- Klik in de rechterbovenhoek op Maken en kies een van de volgende bestandstypen die u wilt toevoegen aan uw bundel: Notebook, Bestand, Query, Dashboard.
- U kunt ook links van Delen op het kebabmenu klikken en een bestand importeren.
Opmerking
Als u wilt dat het bestand deel uitmaakt van de bundelimplementatie, moet u het bestand toevoegen aan de databricks.yml bundelconfiguratie of een taak- of pijplijndefinitiebestand maken dat het bestand bevat. Zie Een bestaande resource toevoegen aan een bundel.
Een resourcedefinitie maken
Bundels bevatten definities voor resources zoals taken en pijplijnen die moeten worden opgenomen in een implementatie. Wanneer de bundel wordt geïmplementeerd, worden resources die in de bundel zijn gedefinieerd, gemaakt in de werkruimte (of bijgewerkt als ze al zijn geïmplementeerd). Deze definities worden opgegeven in YAML of Python en u kunt deze configuraties rechtstreeks in de gebruikersinterface maken en bewerken.
Navigeer naar de bundelmap in de werkruimte waar u een nieuwe resource wilt definiëren.
Aanbeveling
Als u de bundel eerder hebt geopend in de editor in de werkruimte, kunt u de lijst met ontwerpcontexten van de werkruimtebrowser gebruiken om naar de bundelmap te navigeren. Zie Ontwerpcontexten.
Klik rechts van de bundelnaam op Openen in editor om naar de weergave bundeleditor te gaan.
Klik op het implementatiepictogram voor de bundel om over te schakelen naar het deelvenster Implementaties .
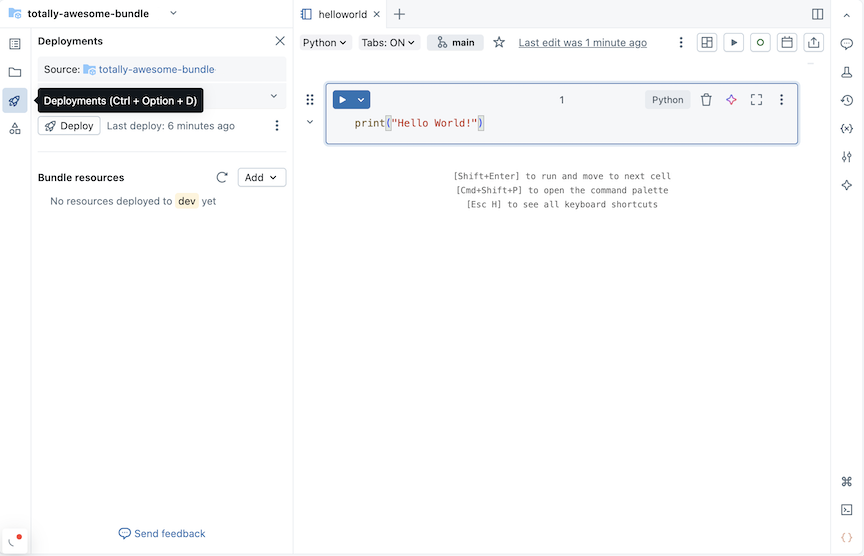
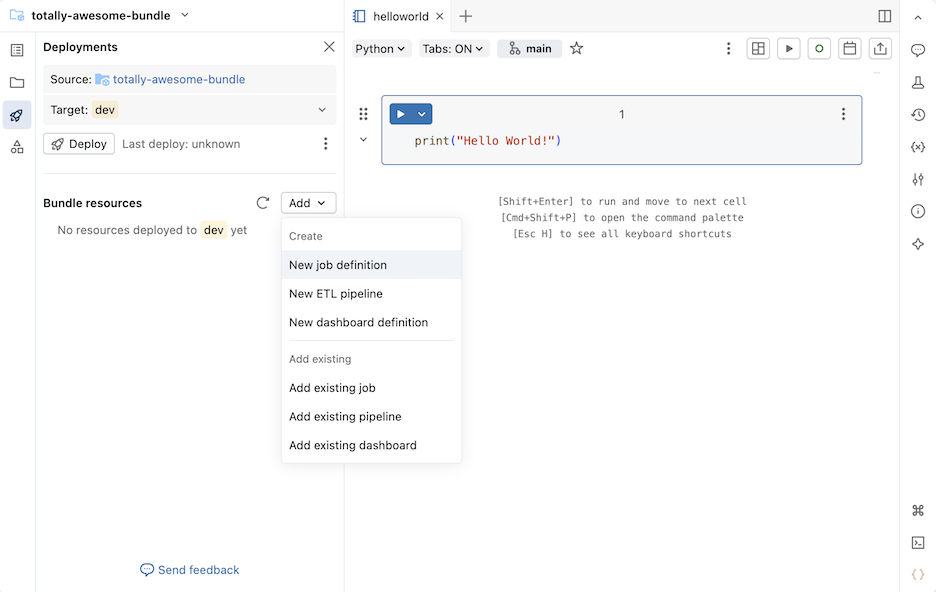
Klik in de sectie Bundelresources op Toevoegen en kies vervolgens een resourcedefinitie die u wilt maken.
Nieuwe taakdefinitie
Een bundelconfiguratiebestand maken waarmee een taak wordt gedefinieerd:
Klik in de sectie Bundelbronnen van het deelvenster Implementaties op Toevoegen en vervolgens op Nieuwe taakdefinitie.
Typ een naam voor de taak in het veld Taaknaam van het dialoogvenster Taakdefinitie maken . Klik op Create.
Voeg YAML toe aan het taakdefinitiebestand dat is gemaakt. In het volgende voorbeeld van YAML wordt een taak gedefinieerd waarmee een notebook wordt uitgevoerd:
resources: jobs: run_notebook: name: run-notebook queue: enabled: true tasks: - task_key: my-notebook-task notebook_task: notebook_path: ../helloworld.ipynb
Zie de taak voor meer informatie over het definiëren van een taak in YAML. Zie Taken toevoegen aan taken in Databricks Asset Bundles voor yamL-syntaxis voor andere ondersteunde taaktakentypen.
Nieuwe pijplijndefinitie
Opmerking
Als u de Lakeflow Pipelines Editor in uw werkruimte hebt ingeschakeld, raadpleegt u De nieuwe ETL-pijplijn.
Een pijplijndefinitie toevoegen aan uw bundel:
Klik in de sectie Bundelbronnen van het deelvenster Implementaties op Toevoegen en vervolgens op Nieuwe pijplijndefinitie.
Typ een naam voor de pijplijn in het veld Pijplijnnaam van het dialoogvenster Pijplijn toevoegen aan bestaande bundel .
Klik op Toevoegen en implementeren.
Voor een pijplijn met de naam test_pipeline die een notebook draait, wordt de volgende YAML in een bestand test_pipeline.pipeline.yml aangemaakt.
resources:
pipelines:
test_pipeline:
name: test_pipeline
libraries:
- notebook:
path: ../test_pipeline.ipynb
serverless: true
catalog: main
target: test_pipeline_${bundle.environment}
U kunt de configuratie wijzigen om een bestaand notebook uit te voeren. Zie de pijplijn voor meer informatie over het definiëren van een pijplijn in YAML.
Nieuwe ETL-pijplijn
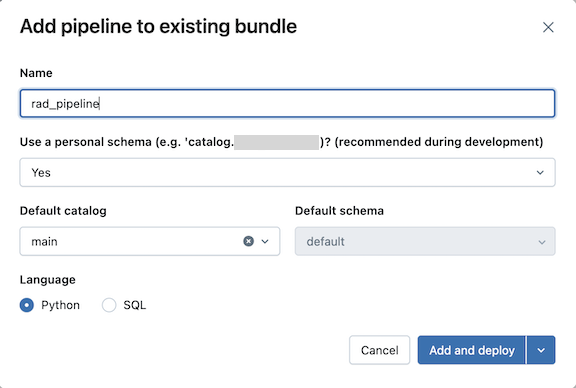
Een nieuwe ETL-pijplijndefinitie toevoegen:
Klik in de sectie Bundelbronnen van het deelvenster Implementaties op Toevoegen en vervolgens op Nieuwe ETL-pijplijn.
Typ een naam voor de pijplijn in het veld Naam van de pijplijn toevoegen aan een bestaand bundeldialoogvenster . De naam moet uniek zijn binnen de werkruimte.
Voor het veld Persoonlijk schema gebruiken selecteert u Ja voor ontwikkelingsscenario's en Nee voor productiescenario's.
Selecteer een standaardcatalogus en een standaardschema voor de pijplijn.
Kies een taal voor de broncode van de pijplijn.
Klik op Toevoegen en implementeren.
Controleer de details in het dialoogvenster Implementeren naar dev-bevestiging en klik vervolgens op Implementeren.
Er wordt een ETL-pijplijn gemaakt met voorbeeldtabellen voor verkennen en transformeren.
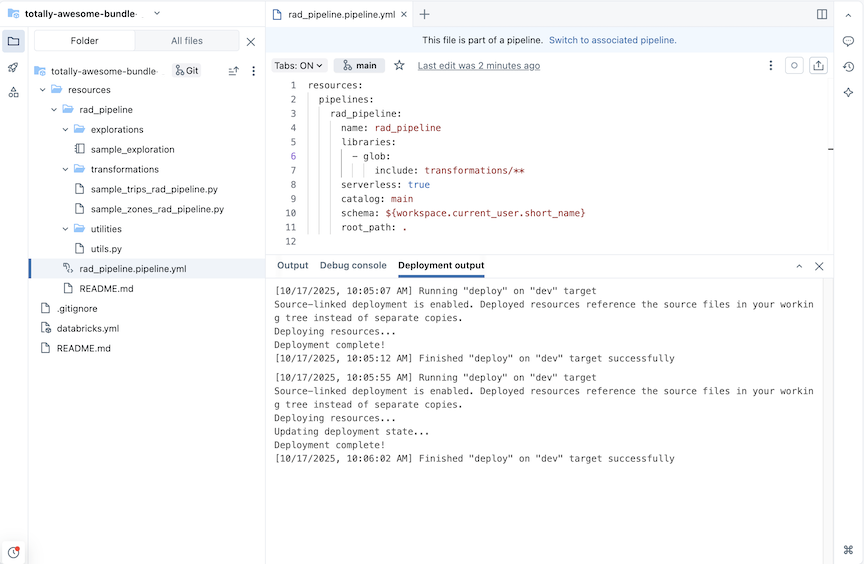
Voor een pijplijn met de naam rad_pipelinewordt de volgende YAML gemaakt in een bestand rad_pipeline.pipeline.yml. Deze pijplijn is geconfigureerd voor uitvoering op serverloze berekeningen. Zie pijplijn voor referentie met betrekking tot pijplijnconfiguratie.
resources:
pipelines:
rad_pipeline:
name: rad_pipeline
libraries:
- glob:
include: transformations/**
serverless: true
catalog: main
schema: ${workspace.current_user.short_name}
root_path: .
Nieuwe dashboarddefinitie
Een bundelconfiguratiebestand maken dat een dashboard definieert:
Klik in de sectie Bundelbronnen van het deelvenster Implementaties op Toevoegen en vervolgens op Nieuwe dashboarddefinitie.
Typ een naam voor het dashboard in het veld Dashboardnaam van het dialoogvenster Dashboard toevoegen aan een bestaand bundeldialoogvenster .
Selecteer een magazijn voor het dashboard. Klik op Toevoegen en implementeren.
Er wordt een nieuw leeg dashboard en een configuratiebestand *.dashboard.yml gemaakt in de bundel. Het dashboard wordt opgeslagen in het magazijn dat is opgegeven in het configuratiebestand.
Zie Dashboards voor meer informatie over dashboards. Voor YAML-syntaxis voor dashboardconfiguratie, zie dashboard.
Een bestaande resource toevoegen aan een bundel
U kunt bestaande resources aan uw bundel toevoegen met behulp van de gebruikersinterface van de werkruimte of door resourceconfiguratie toe te voegen aan uw bundel.
De gebruikersinterface van de bundelwerkruimte gebruiken
Een bestaande taak, pijplijn of dashboard toevoegen aan een bundel:
Navigeer naar de bundelmap in de werkruimte waar u een resource wilt toevoegen.
Aanbeveling
Als u de bundel eerder hebt geopend in de editor in de werkruimte, kunt u de lijst met ontwerpcontexten van de werkruimtebrowser gebruiken om naar de bundelmap te navigeren. Zie Auteurcontexten.
Klik rechts van de bundelnaam op Openen in editor om naar de weergave bundeleditor te gaan.
Klik op het implementatiepictogram voor de bundel om over te schakelen naar het deelvenster Implementaties .
Klik in de sectie Bundelbronnen op Toevoegen en klik vervolgens op Bestaande taak toevoegen, Bestaande pijplijn toevoegen of Bestaand dashboard toevoegen.
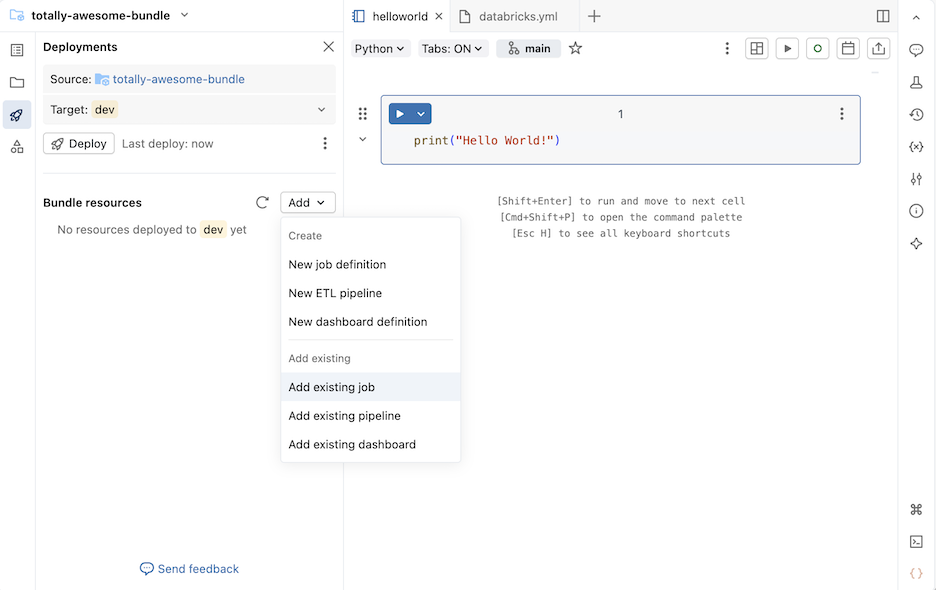
Selecteer in het dialoogvenster Bestaande toevoegen ... de bestaande bron uit de vervolgkeuzelijst.
Wanneer u een bestaande resource aan een bundel toevoegt, maakt Databricks een definitie in een bundelconfiguratiebestand voor deze resource. Omdat u deze definitie in de bundel kunt wijzigen, kan de resource die in de bundel is gedefinieerd, afwijken van de resource die wordt gebruikt om deze te maken.
Kies een optie voor het afhandelen van updates voor de configuratie van de bundelresource:
-
Update over productie-implementaties: de bestaande resource wordt gekoppeld aan de resource in de bundel en eventuele wijzigingen die u aanbrengt in de resource in de bundel, worden toegepast op de bestaande resource wanneer u implementeert op het
proddoel. -
Update over implementaties in ontwikkeling: de bestaande resource wordt gekoppeld aan de resource in de bundel, en eventuele wijzigingen die u aanbrengt in de resource in de bundel worden toegepast op de bestaande resource wanneer u uitvoert naar het
devdoelsysteem. - (Geavanceerd) Niet bijwerken: de bestaande resource is niet gekoppeld aan de bundel. Wijzigingen in de resource in de bundel worden nooit toegepast op de bestaande resource. In plaats daarvan wordt er een kopie gemaakt. Zie databricks bundle deployment bind voor meer informatie over het koppelen van bundelresources met de corresponderende werkruimteresource.
-
Update over productie-implementaties: de bestaande resource wordt gekoppeld aan de resource in de bundel en eventuele wijzigingen die u aanbrengt in de resource in de bundel, worden toegepast op de bestaande resource wanneer u implementeert op het
Klik op Toevoegen... om de bestaande resource toe te voegen aan de bundel.
Bundelconfiguratie toevoegen
Een bestaande resource kan ook aan uw bundel worden toegevoegd door de bundelconfiguratie te definiëren om deze op te nemen in uw bundelimplementatie. In het volgende voorbeeld wordt een bestaande pijplijn toegevoegd aan een bundel.
Ervan uitgaande dat u een pijplijn hebt met de naam taxifilter die het taxifilter.ipynb notebook uitvoert in uw gedeelde werkruimte:
Klik in de zijbalk van uw Azure Databricks-werkruimte op Jobs & Pipelines.
Optioneel kun je de Pijplijnen en de Mijn filters selecteren.
Selecteer de bestaande
taxifilterpijplijn.Klik op de pijplijnpagina aan de linkerkant van de knop Ontwikkelingsimplementatiemodus. Klik vervolgens op YAML-instellingen weergeven.
Klik op het kopieerpictogram om de bundelconfiguratie voor de pijplijn te kopiëren.
Navigeer naar uw bundel in Werkruimte.
Klik op het implementatiepictogram voor de bundel om over te schakelen naar het deelvenster Implementaties .
Klik in de sectie Bundelbronnen op Toevoegen en vervolgens op Nieuwe pijplijndefinitie.
Opmerking
Als u in plaats daarvan een menuopdracht nieuwe ETL-pijplijn ziet, hebt u de Lakeflow Pipelines Editor ingeschakeld. Zie Een brongestuurde pijplijn maken om een ETL-pijplijn toe te voegen aan een bundel.
Typ
taxifilterin het veld Pijplijnnaam van het dialoogvenster Pijplijn toevoegen aan bestaande bundel. Klik op Create.Plak de configuratie voor de bestaande pijplijn in het bestand. Deze voorbeeldpijplijn is gedefinieerd om het
taxifilternotebook uit te voeren:resources: pipelines: taxifilter: name: taxifilter catalog: main libraries: - notebook: path: /Workspace/Shared/taxifilter.ipynb target: taxifilter_${bundle.environment}
U kunt de bundel nu implementeren en vervolgens de pijplijnresource uitvoeren via de gebruikersinterface.