Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
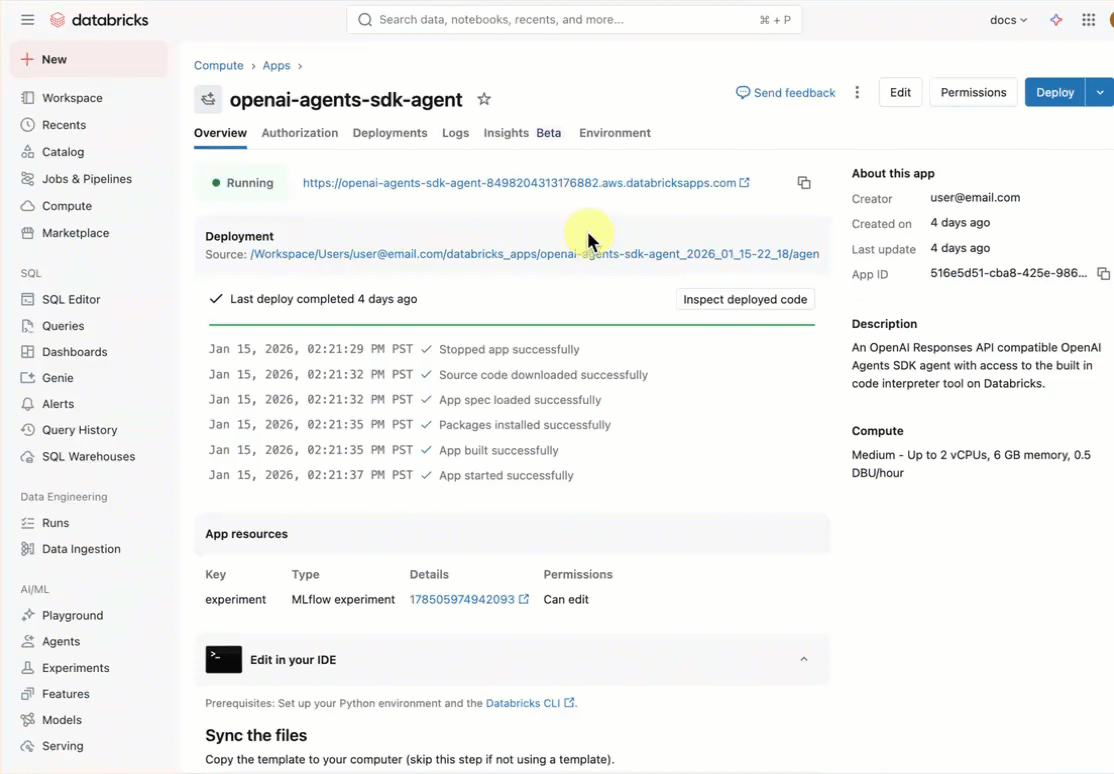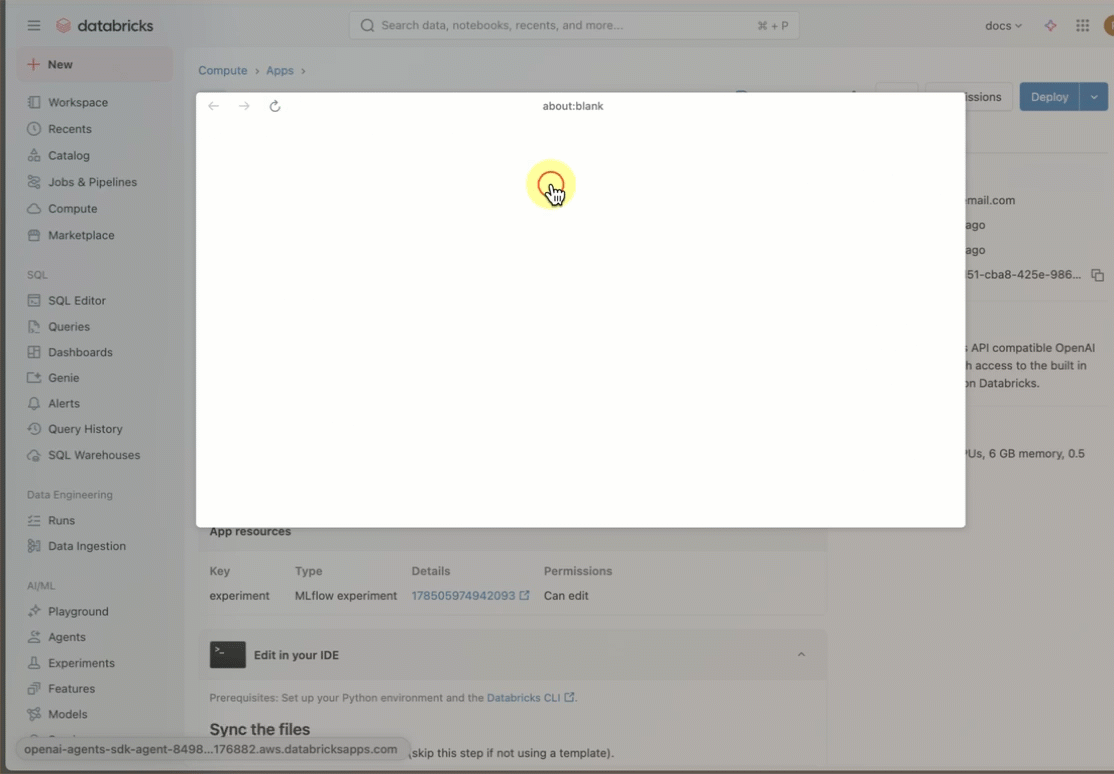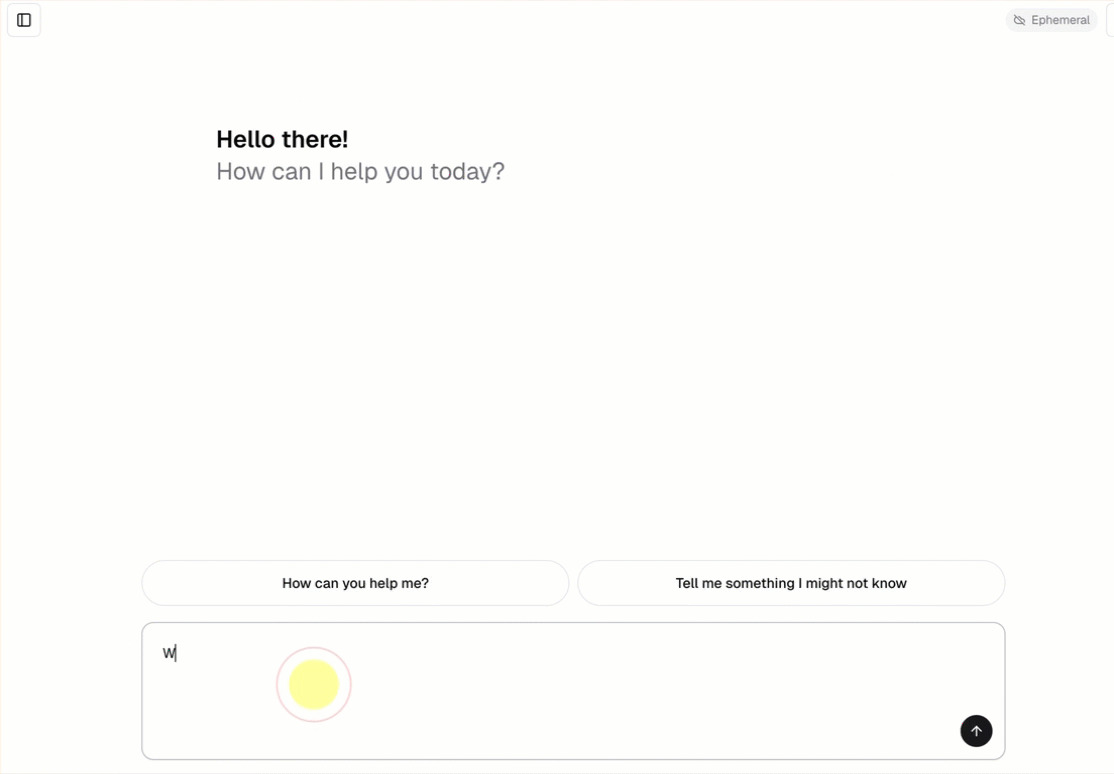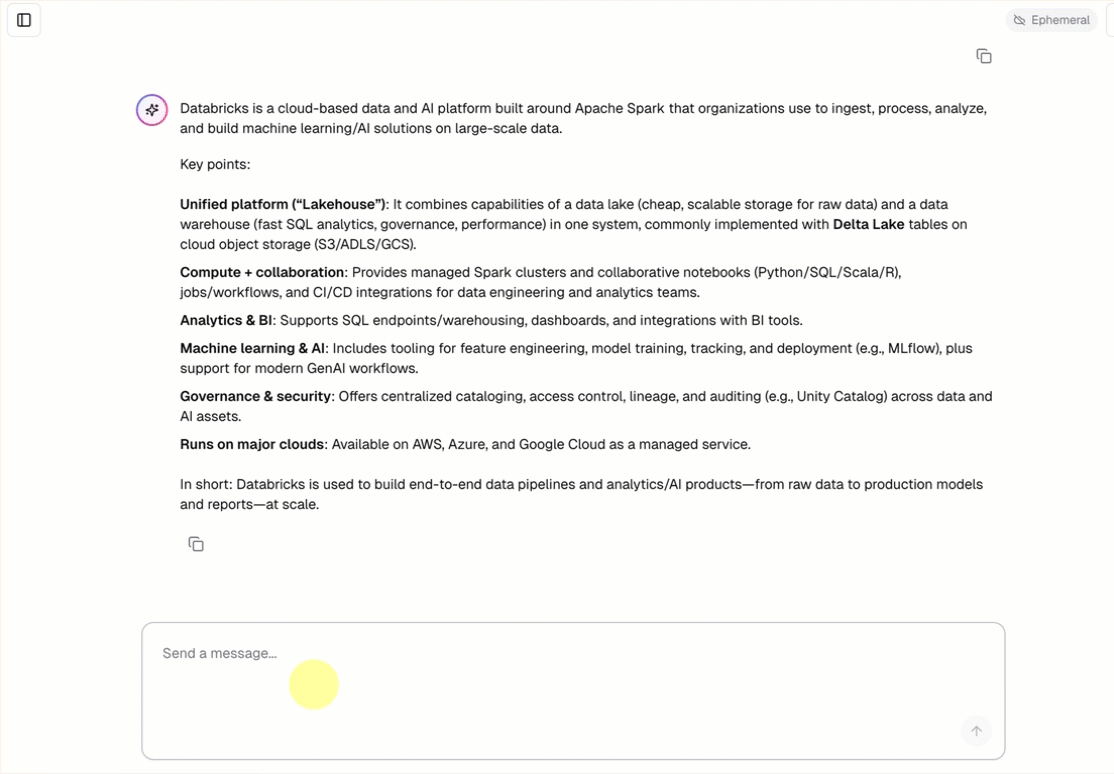
Bouw een AI-agent en implementeer deze met databricks-apps. Databricks Apps biedt u volledige controle over de agentcode, serverconfiguratie en implementatiewerkstroom. Deze benadering is ideaal wanneer u aangepast servergedrag, git-versiebeheer of lokale IDE-ontwikkeling nodig hebt.
Eisen
Databricks-apps inschakelen in uw werkruimte. Zie Uw Databricks Apps-werkruimte en -ontwikkelomgeving instellen.
Stap 1. De sjabloon voor de agent-app klonen
Ga aan de slag met behulp van een vooraf samengestelde agentsjabloon vanuit de databricks-app-sjablonenopslagplaats.
In deze zelfstudie wordt gebruikgemaakt van de agent-openai-agents-sdk sjabloon, waaronder:
- Een agent die is gemaakt met de OpenAI Agent SDK
- Starterscode voor een agenttoepassing met een conversationele REST API en een interactieve chatinterface
- Code voor het evalueren van de agent met behulp van MLflow
Kies een van de volgende paden om de sjabloon in te stellen:
Gebruikersinterface van werkruimte
Installeer de app-sjabloon met behulp van de gebruikersinterface van de werkruimte. Hiermee wordt de app geïnstalleerd en geïmplementeerd in een rekenresource in uw werkruimte. Vervolgens kunt u de toepassingsbestanden synchroniseren met uw lokale omgeving voor verdere ontwikkeling.
Klik in uw Databricks-werkruimte op + Nieuwe>app.
Klik op Agents>Agent - OpenAI Agents SDK.
Maak een nieuw MLflow-experiment met de naam
openai-agents-templateen voltooi de rest van de set om de sjabloon te installeren.Nadat u de app hebt gemaakt, klikt u op de APP-URL om de chatgebruikersinterface te openen.
Nadat u de app hebt gemaakt, downloadt u de broncode naar uw lokale computer om deze aan te passen:
Kopieer de eerste opdracht onder De bestanden synchroniseren
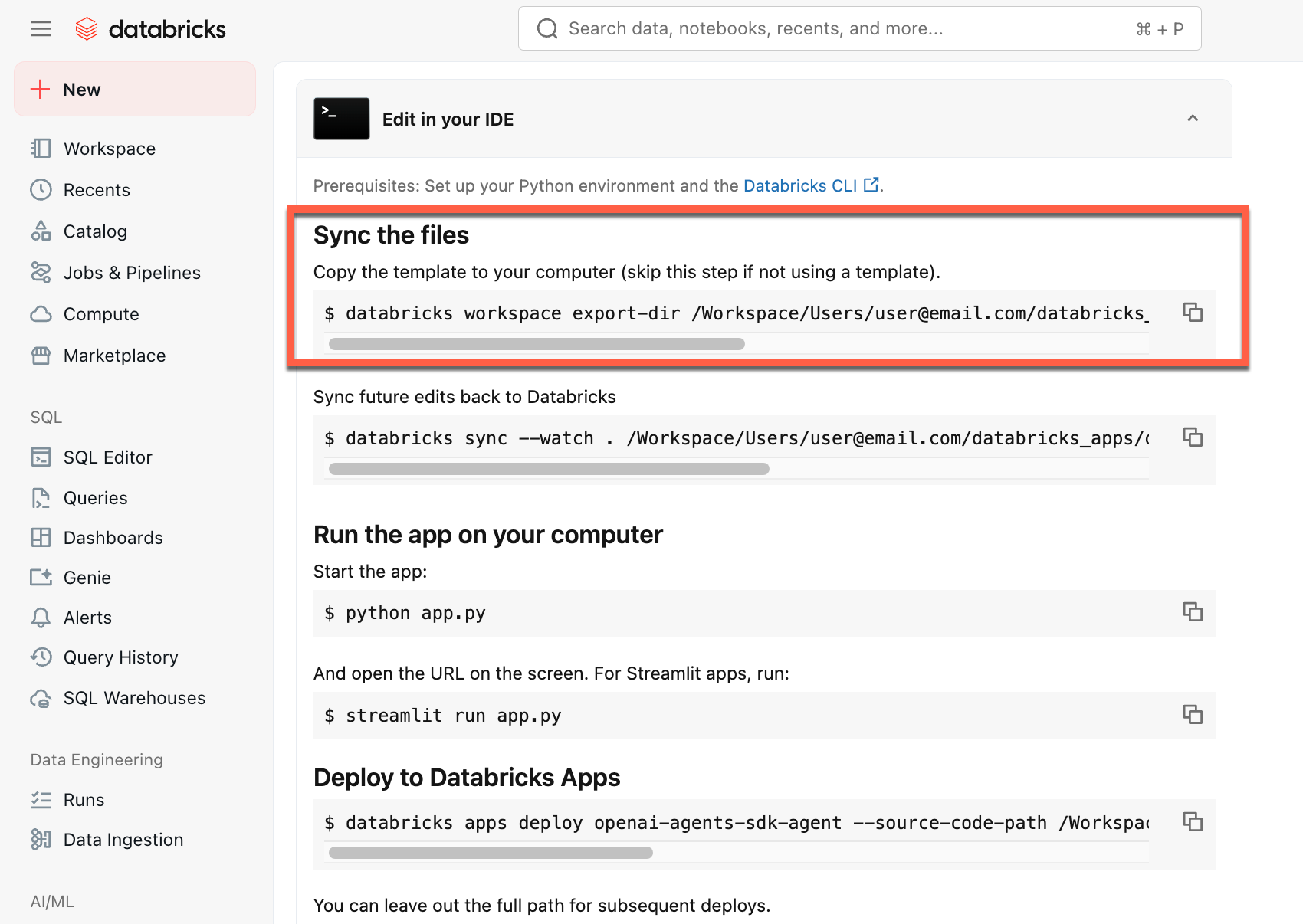
Voer in een lokale terminal de gekopieerde opdracht uit.
Klonen vanuit GitHub
Als u vanuit een lokale omgeving wilt beginnen, kloont u de opslagplaats van de agentsjabloon en opent u de agent-openai-agents-sdk map:
git clone https://github.com/databricks/app-templates.git
cd app-templates/agent-openai-agents-sdk
Stap 2. Inzicht in de agenttoepassing
De agentsjabloon demonstreert een architectuur die gereed is voor productie met deze belangrijke onderdelen. Open de volgende secties voor meer informatie over elk onderdeel:

Open de volgende secties voor meer informatie over elk onderdeel:
 MLflow AgentServer
MLflow AgentServer
Een asynchrone FastAPI-server die agentaanvragen verwerkt met ingebouwde tracering en waarneembaarheid. De AgentServer biedt het eindpunt voor het /invocations uitvoeren van query's op uw agent en beheert automatisch aanvraagroutering, logboekregistratie en foutafhandeling.

ResponsesAgent interface
Databricks raadt MLflow ResponsesAgent aan om agents te bouwen.
ResponsesAgent hiermee kunt u agents bouwen met elk framework van derden en deze vervolgens integreren met Ai-functies van Databricks voor robuuste logboekregistratie, tracering, evaluatie, implementatie en bewakingsmogelijkheden.

Zie de voorbeelden in de ResponsesAgent voor meer informatie over hoe u een kunt maken.
ResponsesAgent biedt de volgende voordelen:
Geavanceerde agentmogelijkheden
- Ondersteuning voor meerdere agents
- Streaming-uitvoer: Stream de uitvoer in kleinere brokken.
- Uitgebreide berichtgeschiedenis voor het aanroepen van hulpprogramma's: Meerdere berichten retourneren, inclusief tussenliggende berichten voor bellen via hulpprogramma's, voor verbeterde kwaliteit en gespreksbeheer.
- Bevestigingsondersteuning bij oproep van tools
- Ondersteuning voor langdurig werkende tools
Gestroomlijnde ontwikkeling, implementatie en bewaking
-
Agents creëren met elk framework: Omwikkel een bestaande agent met de
ResponsesAgentinterface voor directe compatibiliteit met AI Playground, Agent Evaluation en Agent Monitoring. - Getypte ontwerpinterfaces: Agentcode schrijven met behulp van getypte Python-klassen en profiteren van automatisch aanvullen van IDE en notebook.
- Automatische tracering: Met MLflow worden gestreamde antwoorden automatisch samengevoegd in traceringen voor een eenvoudigere evaluatie en weergave.
-
Compatibel met het OpenAI-schema: Zie OpenAI
Responses: Antwoorden versus ChatCompletion.
-
Agents creëren met elk framework: Omwikkel een bestaande agent met de
 OpenAI Agents SDK
OpenAI Agents SDK
De sjabloon maakt gebruik van de OpenAI Agents SDK als agentframework voor gespreksbeheer en indeling van hulpprogramma's. U kunt agents ontwerpen met elk framework. De sleutel is het verpakken van uw agent met de MLflow-interface ResponsesAgent .
 MCP-servers (Model Context Protocol)
MCP-servers (Model Context Protocol)
De sjabloon maakt verbinding met Databricks MCP-servers om agents toegang te geven tot hulpprogramma's en gegevensbronnen. Zie McP (Model Context Protocol) op Databricks.
Agents ontwikkelen met AI-coderingsassistenten
Databricks raadt aan ai-coderingsassistenten zoals Claude, Cursor en Copilot te gebruiken om agents te ontwerpen. Gebruik de opgegeven agentvaardigheden in /.claude/skillsen het AGENTS.md bestand om AI-assistenten inzicht te geven in de projectstructuur, beschikbare hulpprogramma's en best practices. Agents kunnen deze bestanden automatisch lezen om de Databricks-apps te ontwikkelen en te implementeren.
Geavanceerde auteurschapsonderwerpen
Streaming-antwoorden
Streamingantwoorden
Met streaming kunnen agents antwoorden in realtime segmenten verzenden in plaats van te wachten op het volledige antwoord. Als u streaming wilt implementeren met ResponsesAgent, verzendt u een reeks delta-gebeurtenissen, gevolgd door een laatste voltooiingsevenement:
-
Deltagebeurtenissen verzenden: meerdere
output_text.deltagebeurtenissen met hetzelfdeitem_idverzenden om tekstsegmenten in realtime te streamen. -
Eindigen met voltooide gebeurtenis: verzend een laatste
response.output_item.donegebeurtenis met hetzelfdeitem_idals de delta-gebeurtenissen die de volledige uiteindelijke uitvoertekst bevatten.
Elke delta-gebeurtenis streamt een stuk tekst naar de client. De laatste voltooide gebeurtenis bevat de volledige antwoordtekst en signalen Databricks om het volgende te doen:
- De uitvoer van uw agent traceren met MLflow-tracering
- Samengevoegde reacties van streaming in AI Gateway-inferentietabellen
- De volledige uitvoer weergeven in de gebruikersinterface van AI Playground
Streamingfoutpropagatie
Mosaic AI geeft eventuele fouten die zich tijdens het streamen voordoen door met het laatste token onder databricks_output.error. Het is aan de aanroepende client om deze fout correct te verwerken en weer te geven.
{
"delta": …,
"databricks_output": {
"trace": {...},
"error": {
"error_code": BAD_REQUEST,
"message": "TimeoutException: Tool XYZ failed to execute."
}
}
}
Aangepaste invoer en uitvoer
Aangepaste invoer en uitvoer
Voor sommige scenario's zijn mogelijk extra agentinvoer vereist, zoals client_type en session_id, of uitvoer zoals bronkoppelingen ophalen die niet moeten worden opgenomen in de chatgeschiedenis voor toekomstige interacties.
Voor deze scenario's biedt MLflow ResponsesAgent systeemeigen ondersteuning voor de velden custom_inputs en custom_outputs. U hebt toegang tot de aangepaste invoer via request.custom_inputs in de frameworkvoorbeelden hierboven.
De Agent Evaluation beoordelingsapp biedt geen ondersteuning voor rendering van sporen voor agents met extra invoervelden.
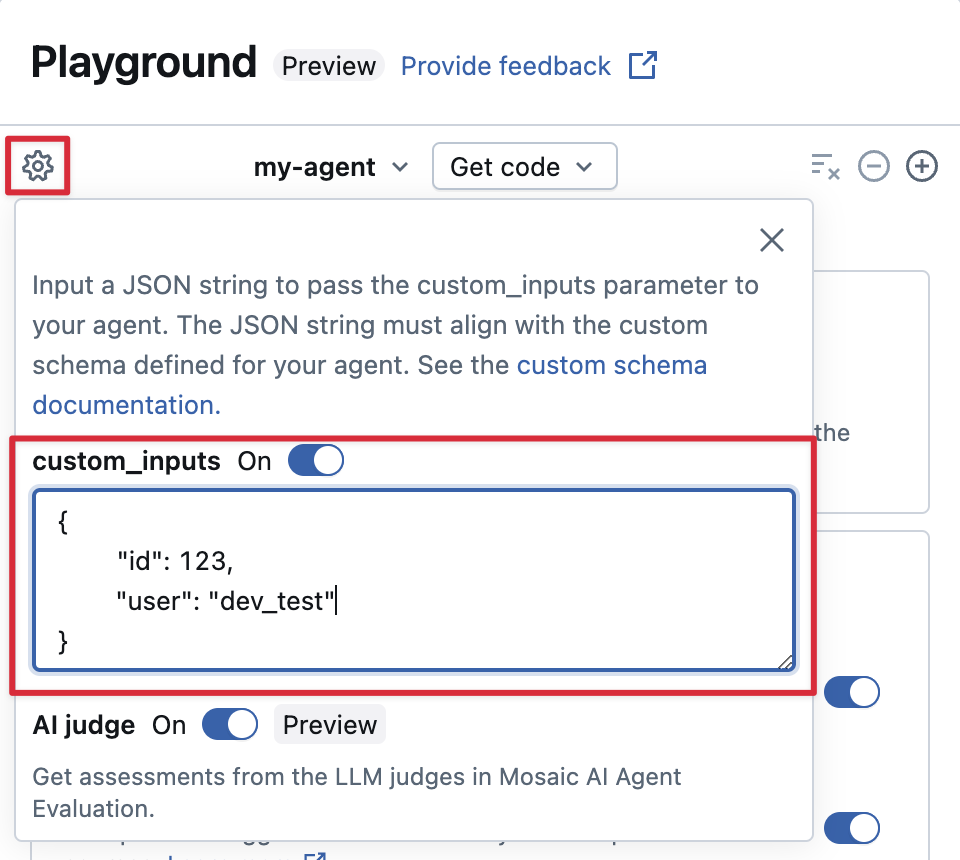
Aanbieden custom_inputs in de AI Playground en de app beoordelen
Als uw agent aanvullende invoer accepteert met behulp van het custom_inputs veld, kunt u deze invoer handmatig opgeven in zowel de AI Playground als de beoordelings-app.
Selecteer in de AI Playground of de Agent Review App het

Schakel custom_inputs in.
Geef een JSON-object op dat overeenkomt met het gedefinieerde invoerschema van uw agent.
Aangepaste retriever-schema's
Aangepaste retriever-schema's
AI-agents gebruiken vaak retrievers om ongestructureerde gegevens te zoeken en op te vragen uit vectorzoekindexen. Zie voor hulpprogramma's voor retriever Agents verbinden met ongestructureerde gegevens.
Traceer deze retrievers binnen uw agent met MLflow RETRIEVER-overspanningen om Databricks-productfuncties in te schakelen, waaronder:
- Automatisch koppelingen weergeven naar opgehaalde brondocumenten in de gebruikersinterface van AI Playground
- Het automatisch uitvoeren van ophaal- en beoordelingsprocessen voor onderbouwing en relevantie bij agentenevaluatie.
Notitie
Databricks raadt het gebruik van retriever-hulpprogramma's aan die worden geleverd door Databricks AI Bridge-pakketten, zoals databricks_langchain.VectorSearchRetrieverTool en databricks_openai.VectorSearchRetrieverTool, omdat ze al voldoen aan het MLflow-retrieverschema. Zie Hulpprogramma's voor vectorzoekopdrachten lokaal ontwikkelen met AI Bridge.
Als uw agent retriever spans met een aangepast schema omvat, roep mlflow.models.set_retriever_schema aan wanneer u uw agent in code definieert. Hiermee worden de uitvoerkolommen van de retriever toegewezen aan de verwachte velden van MLflow (primary_key, text_column, doc_uri).
import mlflow
# Define the retriever's schema by providing your column names
# For example, the following call specifies the schema of a retriever that returns a list of objects like
# [
# {
# 'document_id': '9a8292da3a9d4005a988bf0bfdd0024c',
# 'chunk_text': 'MLflow is an open-source platform, purpose-built to assist machine learning practitioners...',
# 'doc_uri': 'https://mlflow.org/docs/latest/index.html',
# 'title': 'MLflow: A Tool for Managing the Machine Learning Lifecycle'
# },
# {
# 'document_id': '7537fe93c97f4fdb9867412e9c1f9e5b',
# 'chunk_text': 'A great way to get started with MLflow is to use the autologging feature. Autologging automatically logs your model...',
# 'doc_uri': 'https://mlflow.org/docs/latest/getting-started/',
# 'title': 'Getting Started with MLflow'
# },
# ...
# ]
mlflow.models.set_retriever_schema(
# Specify the name of your retriever span
name="mlflow_docs_vector_search",
# Specify the output column name to treat as the primary key (ID) of each retrieved document
primary_key="document_id",
# Specify the output column name to treat as the text content (page content) of each retrieved document
text_column="chunk_text",
# Specify the output column name to treat as the document URI of each retrieved document
doc_uri="doc_uri",
# Specify any other columns returned by the retriever
other_columns=["title"],
)
Notitie
De doc_uri kolom is vooral belangrijk bij het evalueren van de prestaties van de retriever.
doc_uri is de belangrijkste identificatie voor documenten die door de retriever worden geretourneerd, zodat u ze kunt vergelijken met grondwaarheidsevaluatiesets. Zie Evaluatiesets (MLflow 2).
Stap 3. De agent-app lokaal uitvoeren
Uw lokale omgeving instellen:
Installeren
uv(Python-pakketbeheer),nvm(Node-versiebeheer) en de Databricks CLI:-
uvInstallatie -
nvmInstallatie - Voer het volgende uit om Node 20 LTS te gebruiken:
nvm use 20 -
databricks CLIInstallatie
-
Wijzig de map in de
agent-openai-agents-sdkmap.Voer de opgegeven quickstartscripts uit om afhankelijkheden te installeren, uw omgeving in te stellen en de app te starten.
uv run quickstart uv run start-app
Open in een browser de pagina http://localhost:8000 om met de agent te chatten.
Stap 4. Verificatie configureren
Uw agent heeft verificatie nodig voor toegang tot Databricks-resources. Databricks Apps biedt twee verificatiemethoden:
App-autorisatie (standaard)
App-autorisatie maakt gebruik van een service-principal die automatisch door Azure Databricks voor uw app wordt gemaakt. Alle gebruikers delen dezelfde machtigingen.
Machtigingen verlenen aan het MLflow-experiment:
- Klik op Bewerken op de startpagina van uw app.
- Navigeer naar de stap Configureren .
- Voeg in de sectie App-resources de MLflow-experimentresource met
Can Editmachtiging toe.
Voor andere resources (Vector Search, Genie-ruimten, service-eindpunten) voegt u ze op dezelfde manier toe in de sectie App-resources.
Zie App-autorisatie voor meer informatie.
Gebruikersautorisatie
Met gebruikersautorisatie kan uw agent handelen met de afzonderlijke machtigingen van elke gebruiker. Gebruik deze optie wanneer u toegangsbeheer per gebruiker of audittrails nodig hebt.
Voeg deze code toe aan uw agent:
from agent_server.utils import get_user_workspace_client
# In your agent code (inside @invoke or @stream)
user_workspace = get_user_workspace_client()
# Access resources with the user's permissions
response = user_workspace.serving_endpoints.query(name="my-endpoint", inputs=inputs)
Belangrijk: Initialiseer get_user_workspace_client() binnen uw @invoke of @stream functies, niet tijdens het opstarten van de app. Gebruikersreferenties bestaan alleen bij het verwerken van een aanvraag.
Bereiken configureren: Voeg autorisatiebereiken toe in de gebruikersinterface van Databricks Apps om te definiëren welke API's uw agent namens gebruikers kan openen.
Zie Gebruikersautorisatie voor volledige installatie-instructies.
Stap 5. De agent evalueren
De sjabloon bevat agentevaluatiecode. Zie agent_server/evaluate_agent.py voor meer informatie. Evalueer de relevantie en veiligheid van de reacties van uw agent door het volgende uit te voeren in een terminal:
uv run agent-evaluate
Stap 6. De agent implementeren in Databricks-apps
Nadat u verificatie hebt geconfigureerd, implementeert u uw agent in Databricks. Zorg ervoor dat de Databricks CLI is geïnstalleerd en geconfigureerd.
Als u de opslagplaats lokaal hebt gekloond, maakt u de Databricks-app voordat u deze implementeert. Als u uw app hebt gemaakt via de gebruikersinterface van de werkruimte, slaat u deze stap over wanneer het app- en MLflow-experiment al is geconfigureerd.
databricks apps create agent-openai-agents-sdkLokale bestanden synchroniseren met uw werkruimte. Zie De app implementeren.
DATABRICKS_USERNAME=$(databricks current-user me | jq -r .userName) databricks sync . "/Users/$DATABRICKS_USERNAME/agent-openai-agents-sdk"Implementeer uw Databricks-app.
databricks apps deploy agent-openai-agents-sdk --source-code-path /Workspace/Users/$DATABRICKS_USERNAME/agent-openai-agents-sdk
Synchroniseer en implementeer uw agent voor toekomstige updates voor de agent.
Stap 7. Een query uitvoeren op de ingezette agent
Gebruikers voeren een query uit op uw geïmplementeerde agent met behulp van OAuth-tokens. Persoonlijke toegangstokens (PAT's) worden niet ondersteund voor Databricks-apps.
Genereer een OAuth-token met behulp van de Databricks CLI:
databricks auth login --host <https://host.databricks.com>
databricks auth token
Gebruik het token om een query uit te voeren op de agent:
curl -X POST <app-url.databricksapps.com>/invocations \
-H "Authorization: Bearer <oauth token>" \
-H "Content-Type: application/json" \
-d '{ "input": [{ "role": "user", "content": "hi" }], "stream": true }'
Beperkingen
Alleen middelgrote en grote computergrootten worden ondersteund. Zie De rekenkracht voor een Databricks-app configureren.