Een Multivariate Anomaly Detection-model trainen
Belangrijk
Vanaf 20 september 2023 kunt u geen nieuwe Anomaly Detector-resources maken. De Anomaly Detector-service wordt op 1 oktober 2026 buiten gebruik gesteld.
Als u Multivariate Anomaliedetectie snel wilt testen, probeert u het codevoorbeeld. Raadpleeg een Jupyter-notebook installeren en uitvoeren voor meer instructies over het uitvoeren van een Jupyter-notebook.
API-overzicht
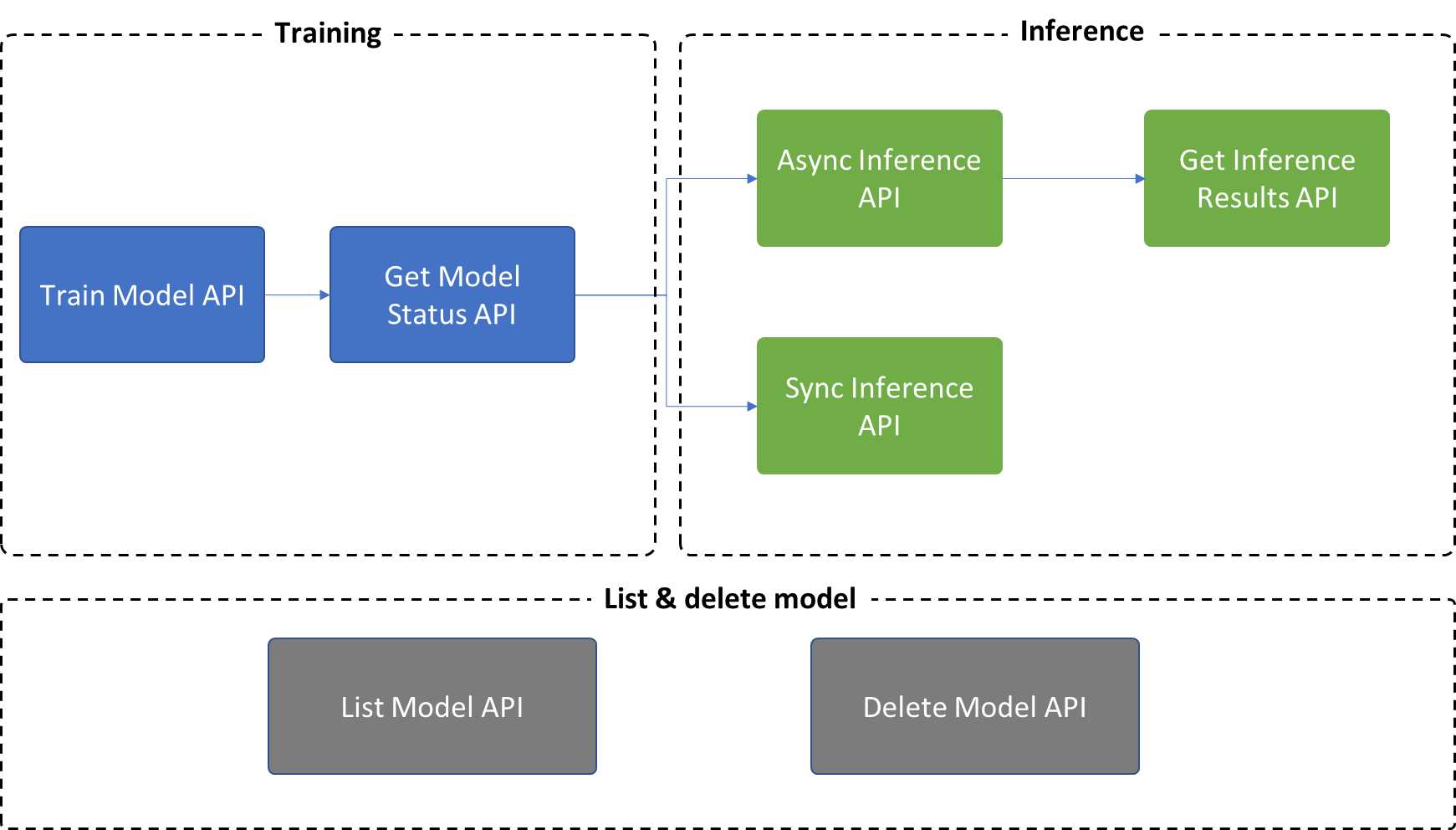
Er zijn 7 API's beschikbaar in Multivariate Anomaly Detection:
- Training: Gebruik
Train Model APIdit om een model te maken en te trainen en vervolgensGet Model Status APIom de status en modelmetagegevens op te halen. - Deductie:
- Gebruik
Async Inference APIdit om een asynchroon deductieproces te activeren en omGet Inference results APIdetectieresultaten op te halen voor een batch met gegevens. - U kunt ook elke
Sync Inference APIkeer een detectie op één tijdstempel activeren.
- Gebruik
- Andere bewerkingen:
List Model APIenDelete Model APIworden ondersteund in het Multivariate Anomaly Detection-model voor modelbeheer.
| API-naam | Wijze | Pad | Beschrijving |
|---|---|---|---|
| Trainingsmodel | POSTEN | {endpoint}/anomalydetector/v1.1/multivariate/models |
Een model maken en trainen |
| Modelstatus ophalen | GET | {endpoint}anomalydetector/v1.1/multivariate/models/{modelId} |
Modelstatus en modelmetagegevens ophalen met modelId |
| Batchdeductie | POSTEN | {endpoint}/anomalydetector/v1.1/multivariate/models/{modelId}: detect-batch |
Een asynchrone deductie activeren met modelId, die werkt in een batchscenario |
| Resultaten van batchdeductie ophalen | GET | {endpoint}/anomalydetector/v1.1/multivariate/detect-batch/{resultId} |
Resultaten van batchdeductie ophalen met resultId |
| Streamingdeductie | POSTEN | {endpoint}/anomalydetector/v1.1/multivariate/models/{modelId}: detect-last |
Een synchrone deductie activeren met modelId, die werkt in een streamingscenario |
| Lijstmodel | GET | {endpoint}/anomalydetector/v1.1/multivariate/models |
Alle modellen weergeven |
| Model verwijderen | VERWIJDEREN | {endpoint}/anomalydetector/v1.1/multivariate/models/{modelId} |
Model verwijderen met modelId |
Een model trainen
In dit proces gebruikt u de volgende informatie die u eerder hebt gemaakt:
- Sleutel van Anomaly Detector-resource
- Eindpunt van Anomaly Detector-resource
- Blob-URL van uw gegevens in opslagaccount
Voor de grootte van trainingsgegevens is het maximum aantal tijdstempels 1000000 en een aanbevolen minimumaantal is 5000 tijdstempels.
Aanvragen
Hier volgt een voorbeeld van een aanvraagbody voor het trainen van een Multivariate Anomaly Detection-model.
{
"slidingWindow": 200,
"alignPolicy": {
"alignMode": "Outer",
"fillNAMethod": "Linear",
"paddingValue": 0
},
"dataSource": "{{dataSource}}", //Example: https://mvaddataset.blob.core.windows.net/sample-onetable/sample_data_5_3000.csv
"dataSchema": "OneTable",
"startTime": "2021-01-01T00:00:00Z",
"endTime": "2021-01-02T09:19:00Z",
"displayName": "SampleRequest"
}
Vereiste parameters
Deze drie parameters zijn vereist voor trainings- en deductie-API-aanvragen:
- dataSource: dit is de Blob-URL die is gekoppeld aan uw map of CSV-bestand in Azure Blob Storage.
- dataSchema: Dit geeft het schema aan dat u gebruikt:
OneTableofMultiTable. - startTime: de begintijd van gegevens die worden gebruikt voor training of deductie. Als het eerder is dan de werkelijke vroegste tijdstempel in de gegevens, wordt de werkelijke vroegste tijdstempel gebruikt als het beginpunt.
- endTime: de eindtijd van gegevens die worden gebruikt voor training of deductie, die later dan of gelijk aan
startTimemoet zijn. AlsendTimedit later is dan de werkelijke laatste tijdstempel in de gegevens, wordt de werkelijke laatste tijdstempel gebruikt als het eindpunt. AlsendTimedit gelijk is aanstartTime, betekent dit deductie van één gegevenspunt, dat vaak wordt gebruikt in streamingscenario's.
Optionele parameters
Andere parameters voor de trainings-API zijn optioneel:
slidingWindow: Hoeveel gegevenspunten worden gebruikt om afwijkingen te bepalen. Een geheel getal tussen 28 en 2.880. De standaardwaarde is 300. Als
slidingWindowdit het geval iskvoor modeltraining, moeten ten minstekpunten toegankelijk zijn vanuit het bronbestand tijdens deductie om geldige resultaten te verkrijgen.Multivariate Anomaly Detection neemt een segment van gegevenspunten om te bepalen of het volgende gegevenspunt een anomalie is. De lengte van het segment is de
slidingWindow. Houd rekening met twee dingen bij het kiezen van eenslidingWindowwaarde:- De eigenschappen van uw gegevens: of deze periodiek en de steekproeffrequentie zijn. Wanneer uw gegevens periodiek zijn, kunt u de lengte van 1 - 3 cycli instellen als de
slidingWindow. Wanneer uw gegevens een hoge frequentie hebben (kleine granulariteit), zoals minuutniveau of tweede niveau, kunt u een relatief hogere waardeslidingWindowinstellen. - De afweging tussen trainings-/deductietijd en mogelijke invloed op de prestaties. Een grotere
slidingWindowkan leiden tot langere trainings-/deductietijd. Er is geen garantie dat grotereslidingWindows leiden tot nauwkeurigheidswinsten. Een kleinslidingWindowmodel kan het lastig maken om te convergeren op een optimale oplossing. Het is bijvoorbeeld moeilijk om afwijkingen te detecteren wanneerslidingWindower slechts twee punten zijn.
- De eigenschappen van uw gegevens: of deze periodiek en de steekproeffrequentie zijn. Wanneer uw gegevens periodiek zijn, kunt u de lengte van 1 - 3 cycli instellen als de
alignMode: Meerdere variabelen (tijdreeksen) uitlijnen op tijdstempels. Er zijn twee opties voor deze parameter en
Inner, enOuterde standaardwaarde isOuter.Deze parameter is essentieel wanneer er sprake is van een onjuiste uitlijning tussen tijdstempelreeksen van de variabelen. Het model moet de variabelen uitlijnen op dezelfde tijdstempelreeks voordat het verder wordt verwerkt.
Innerbetekent dat het model alleen detectieresultaten rapporteert op tijdstempels waarop elke variabele een waarde heeft, dat wil zeggen het snijpunt van alle variabelen.Outerbetekent dat het model detectieresultaten rapporteert op tijdstempels waarop een variabele een waarde heeft, dat wil zeggen, de samenvoeging van alle variabelen.Hier volgt een voorbeeld om verschillende
alignModelwaarden uit te leggen.Variabele-1
timestamp waarde 2020-11-01 1 2020-11-02 2 2020-11-04 4 2020-11-05 5 Variabele-2
timestamp waarde 2020-11-01 1 2020-11-02 2 2020-11-03 3 2020-11-04 4 Innertwee variabelen samenvoegentimestamp Variabele-1 Variabele-2 2020-11-01 1 1 2020-11-02 2 2 2020-11-04 4 4 Outertwee variabelen samenvoegentimestamp Variabele-1 Variabele-2 2020-11-01 1 1 2020-11-02 2 2 2020-11-03 nan3 2020-11-04 4 4 2020-11-05 5 nanfillNAMethod: De samengevoegde tabel invullen
nan. Er ontbreken mogelijk waarden in de samengevoegde tabel en deze moeten correct worden verwerkt. We bieden verschillende methoden om ze op te vullen. De opties zijnLinear,Previous, ,SubsequentenZeroenFixedde standaardwaarde isLinear.Optie Wijze LinearWaarden doorvoeren nandoor lineaire interpolatiePreviousGeef de laatste geldige waarde door om hiaten te vullen. Voorbeeld: [1, 2, nan, 3, nan, 4]->[1, 2, 2, 3, 3, 4]SubsequentGebruik de volgende geldige waarde om hiaten te vullen. Voorbeeld: [1, 2, nan, 3, nan, 4]->[1, 2, 3, 3, 4, 4]ZeroVul nanwaarden in met 0.FixedVul nanwaarden in met een opgegeven geldige waarde die moet worden opgegeven inpaddingValue.paddingValue: Opvullingswaarde wordt gebruikt om op te vullen
nanwanneerfillNAMethodFixeden moet in dat geval worden opgegeven. In andere gevallen is dit optioneel.displayName: dit is een optionele parameter die wordt gebruikt om modellen te identificeren. U kunt deze bijvoorbeeld gebruiken om parameters, gegevensbronnen en andere metagegevens over het model en de bijbehorende invoergegevens te markeren. De standaardwaarde is een lege tekenreeks.
Respons
Binnen het antwoord is modelIdhet belangrijkste dat u gebruikt om de API Voor modelstatus ophalen te activeren.
Een voorbeeld van een antwoord:
{
"modelId": "09c01f3e-5558-11ed-bd35-36f8cdfb3365",
"createdTime": "2022-11-01T00:00:00Z",
"lastUpdatedTime": "2022-11-01T00:00:00Z",
"modelInfo": {
"dataSource": "https://mvaddataset.blob.core.windows.net/sample-onetable/sample_data_5_3000.csv",
"dataSchema": "OneTable",
"startTime": "2021-01-01T00:00:00Z",
"endTime": "2021-01-02T09:19:00Z",
"displayName": "SampleRequest",
"slidingWindow": 200,
"alignPolicy": {
"alignMode": "Outer",
"fillNAMethod": "Linear",
"paddingValue": 0.0
},
"status": "CREATED",
"errors": [],
"diagnosticsInfo": {
"modelState": {
"epochIds": [],
"trainLosses": [],
"validationLosses": [],
"latenciesInSeconds": []
},
"variableStates": []
}
}
}
Modelstatus ophalen
U kunt de bovenstaande API gebruiken om een training te activeren en de API voor modelstatus ophalen te gebruiken om te weten of het model al dan niet is getraind.
Aanvragen
Er is geen inhoud in de aanvraagbody, wat alleen vereist is om de model-id in het API-pad te plaatsen. Dit heeft de volgende indeling: {{endpoint}}anomalydetector/v1.1/multivariate/models/{{modelId}}
Respons
- status: De
statushoofdtekst van het antwoord geeft de modelstatus aan met deze categorie: GEMAAKT, ACTIEF, GEREED, MISLUKT. - trainLosses & validationLosses: dit zijn twee machine learning-concepten die de modelprestaties aangeven. Als de getallen afnemen en uiteindelijk tot een relatief klein getal, zoals 0,2, 0,3, betekent dit dat de modelprestaties in zekere mate goed zijn. De modelprestaties moeten echter nog steeds worden gevalideerd via deductie en de vergelijking met labels, indien van toepassing.
- epochIds: geeft aan hoeveel epochs het model is getraind uit in totaal 100 epochs. Als het model bijvoorbeeld nog steeds de trainingsstatus heeft, kan dit zijn
[10, 20, 30, 40, 50],epochIdwat betekent dat het de 50e trainingstijdperk heeft voltooid en daarom halverwege voltooid is. - latenciesInSeconds: bevat de tijdskosten voor elk tijdvak en wordt elke 10 epochs geregistreerd. In dit voorbeeld duurt het 10e tijdvak ongeveer 0,34 seconde. Dit zou handig zijn om de voltooiingstijd van de training te schatten.
- variableStates: geeft een overzicht van de informatie over elke variabele. Het is een lijst gerangschikt
filledNARatioop in aflopende volgorde. Er wordt aangegeven hoeveel gegevenspunten worden gebruikt voor elke variabele enfilledNARatiowordt aangegeven hoeveel punten er ontbreken. Meestal moeten we zoveel mogelijk verminderenfilledNARatio. Te veel ontbrekende gegevenspunten verslechteren de nauwkeurigheid van het model. - fouten: fouten tijdens gegevensverwerking worden opgenomen in het
errorsveld.
Een voorbeeld van een antwoord:
{
"modelId": "09c01f3e-5558-11ed-bd35-36f8cdfb3365",
"createdTime": "2022-11-01T00:00:12Z",
"lastUpdatedTime": "2022-11-01T00:00:12Z",
"modelInfo": {
"dataSource": "https://mvaddataset.blob.core.windows.net/sample-onetable/sample_data_5_3000.csv",
"dataSchema": "OneTable",
"startTime": "2021-01-01T00:00:00Z",
"endTime": "2021-01-02T09:19:00Z",
"displayName": "SampleRequest",
"slidingWindow": 200,
"alignPolicy": {
"alignMode": "Outer",
"fillNAMethod": "Linear",
"paddingValue": 0.0
},
"status": "READY",
"errors": [],
"diagnosticsInfo": {
"modelState": {
"epochIds": [
10,
20,
30,
40,
50,
60,
70,
80,
90,
100
],
"trainLosses": [
0.30325182933699,
0.24335388161919333,
0.22876543213020673,
0.2439815090461211,
0.22489577260884372,
0.22305156764659015,
0.22466289590705524,
0.22133831883018668,
0.2214335961775346,
0.22268397090109912
],
"validationLosses": [
0.29047123109451445,
0.263965221366497,
0.2510373182971068,
0.27116744686858824,
0.2518718700216274,
0.24802495975687047,
0.24790137705176768,
0.24640804830223623,
0.2463938973166726,
0.24831805566344597
],
"latenciesInSeconds": [
2.1662967205047607,
2.0658926963806152,
2.112030029296875,
2.130472183227539,
2.183091640472412,
2.1442034244537354,
2.117824077606201,
2.1345198154449463,
2.0993552207946777,
2.1198465824127197
]
},
"variableStates": [
{
"variable": "series_0",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_1",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_2",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_3",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_4",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
}
]
}
}
}
Modellen weergeven
U kunt naar deze pagina verwijzen voor informatie over de aanvraag-URL en aanvraagheaders. U ziet dat we slechts 10 modellen retourneren die op updatetijd zijn besteld, maar u kunt andere modellen bezoeken door de $skip en de $top parameters in de aanvraag-URL in te stellen. Als uw aanvraag-URL bijvoorbeeld is https://{endpoint}/anomalydetector/v1.1/multivariate/models?$skip=10&$top=20, slaan we de nieuwste 10 modellen over en retourneren we de volgende 20 modellen.
Een voorbeeldantwoord is
{
"models": [
{
"modelId": "09c01f3e-5558-11ed-bd35-36f8cdfb3365",
"createdTime": "2022-10-26T18:00:12Z",
"lastUpdatedTime": "2022-10-26T18:03:53Z",
"modelInfo": {
"dataSource": "https://mvaddataset.blob.core.windows.net/sample-onetable/sample_data_5_3000.csv",
"dataSchema": "OneTable",
"startTime": "2021-01-01T00:00:00Z",
"endTime": "2021-01-02T09:19:00Z",
"displayName": "SampleRequest",
"slidingWindow": 200,
"alignPolicy": {
"alignMode": "Outer",
"fillNAMethod": "Linear",
"paddingValue": 0.0
},
"status": "READY",
"errors": [],
"diagnosticsInfo": {
"modelState": {
"epochIds": [
10,
20,
30,
40,
50,
60,
70,
80,
90,
100
],
"trainLosses": [
0.30325182933699,
0.24335388161919333,
0.22876543213020673,
0.2439815090461211,
0.22489577260884372,
0.22305156764659015,
0.22466289590705524,
0.22133831883018668,
0.2214335961775346,
0.22268397090109912
],
"validationLosses": [
0.29047123109451445,
0.263965221366497,
0.2510373182971068,
0.27116744686858824,
0.2518718700216274,
0.24802495975687047,
0.24790137705176768,
0.24640804830223623,
0.2463938973166726,
0.24831805566344597
],
"latenciesInSeconds": [
2.1662967205047607,
2.0658926963806152,
2.112030029296875,
2.130472183227539,
2.183091640472412,
2.1442034244537354,
2.117824077606201,
2.1345198154449463,
2.0993552207946777,
2.1198465824127197
]
},
"variableStates": [
{
"variable": "series_0",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_1",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_2",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_3",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_4",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
}
]
}
}
}
],
"currentCount": 42,
"maxCount": 1000,
"nextLink": ""
}
Het antwoord bevat vier velden, models, currentCount, en maxCountnextLink.
- modellen: dit bevat de gemaakte tijd, de laatst bijgewerkte tijd, de model-id, de weergavenaam, het aantal variabelen en de status van elk model.
- currentCount: Dit bevat het aantal getrainde multivariate-modellen in uw Anomaly Detector-resource.
- maxCount: het maximum aantal modellen dat wordt ondersteund door uw Anomaly Detector-resource, die wordt onderscheiden door de prijscategorie die u kiest.
- nextLink: Dit kan worden gebruikt om meer modellen op te halen, omdat het maximum aantal modellen dat wordt vermeld in dit API-antwoord 10 is.