Ophalen van augmented generation met Azure AI-documentinformatie
Deze inhoud is van toepassing op: ![]() v4.0 (preview)
v4.0 (preview)
Inleiding
Retrieval-Augmented Generation (RAG) is een ontwerppatroon dat een vooraf getraind Large Language Model (LLM) combineert zoals ChatGPT met een systeem voor het ophalen van externe gegevens om een verbeterd antwoord te genereren met nieuwe gegevens buiten de oorspronkelijke trainingsgegevens. Door een systeem voor het ophalen van gegevens toe te voegen aan uw toepassingen, kunt u chatten met uw documenten, boeiende inhoud genereren en toegang krijgen tot de kracht van Azure OpenAI-modellen voor uw gegevens. U hebt ook meer controle over de gegevens die door de LLM worden gebruikt tijdens het formuleren van een antwoord.
Het document intelligence-indelingsmodel is een geavanceerde op machine learning gebaseerde documentanalyse-API. Het indelingsmodel biedt een uitgebreide oplossing voor geavanceerde mogelijkheden voor het extraheren van inhoud en analyse van documentstructuur. Met het indelingsmodel kunt u eenvoudig tekst en structurele elementen extraheren om grote tekstteksten te verdelen in kleinere, zinvolle segmenten op basis van semantische inhoud in plaats van willekeurige splitsingen. De geëxtraheerde informatie kan gemakkelijk worden uitgevoerd naar de Markdown-indeling, zodat u uw semantische segmenteringsstrategie kunt definiëren op basis van opgegeven bouwstenen.
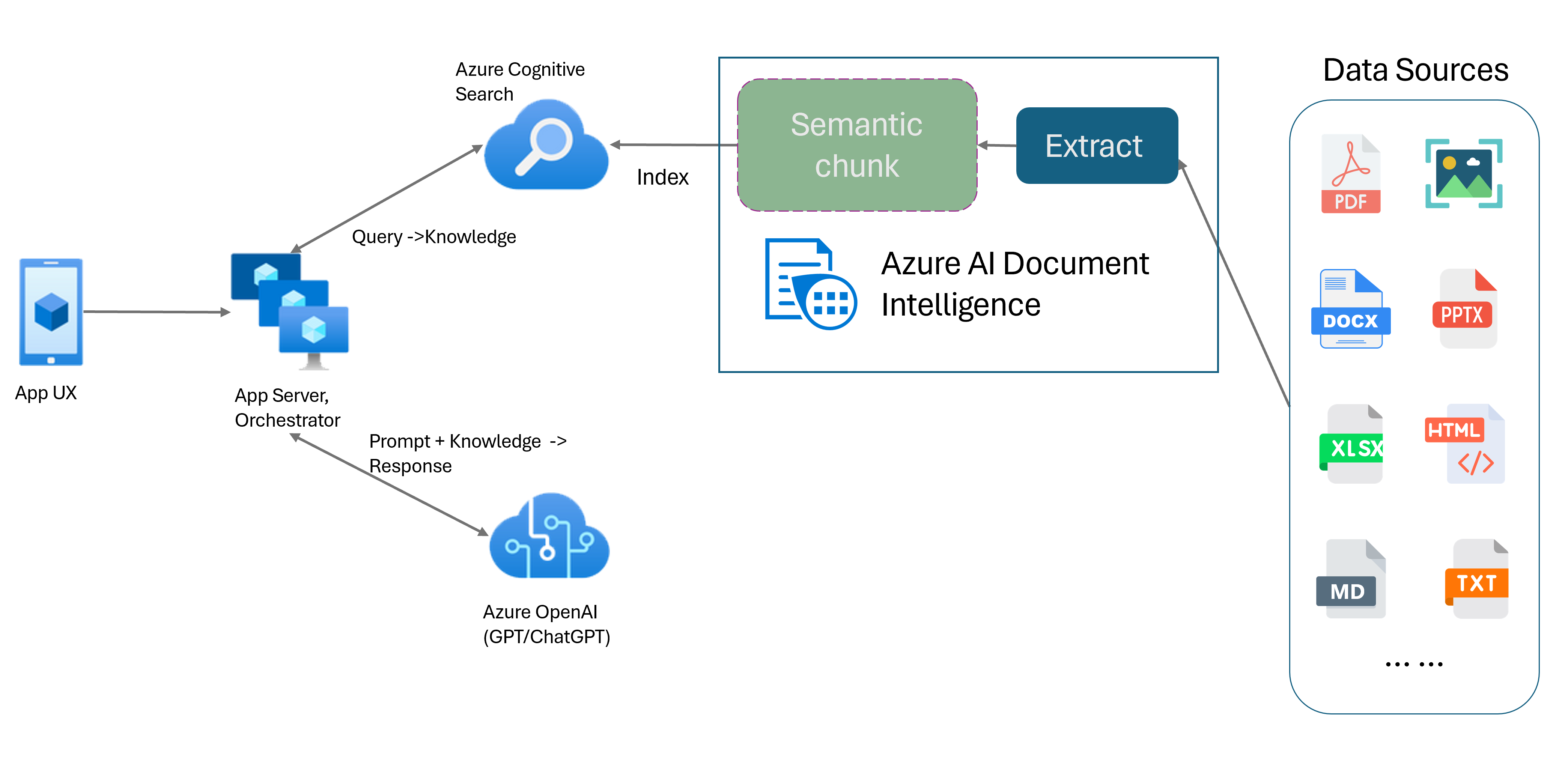
Semantische segmentering
Lange zinnen zijn lastig voor NLP-toepassingen (Natural Language Processing). Vooral wanneer ze bestaan uit meerdere componenten, complexe zelfstandig naamwoorden of werkwoordzinnen, relatieve componenten en haakje-groeperingen. Net als de menselijke aanduiding moet een NLP-systeem ook alle gepresenteerde afhankelijkheden bijhouden. Het doel van semantische segmentering is om semantisch coherente fragmenten van een zinsdeelweergave te vinden. Deze fragmenten kunnen vervolgens onafhankelijk worden verwerkt en opnieuw worden gecombineerd als semantische representaties zonder verlies van informatie, interpretatie of semantische relevantie. De inherente betekenis van de tekst wordt gebruikt als richtlijn voor het segmenteringsproces.
Segmenteringsstrategieën voor tekstgegevens spelen een belangrijke rol bij het optimaliseren van het RAG-antwoord en de prestaties. Vaste grootte en semantisch zijn twee verschillende chunkingmethoden:
Segmentering met vaste grootte. De meeste chunkingstrategieën die momenteel in RAG worden gebruikt, zijn gebaseerd op tekstsegmenten met een fix-grootte, ook wel segmenten genoemd. Segmentering met vaste grootte is snel, eenvoudig en effectief met tekst die geen sterke semantische structuur heeft, zoals logboeken en gegevens. Het wordt echter niet aanbevolen voor tekst waarvoor semantisch begrip en nauwkeurige context is vereist. De aard van het venster met een vaste grootte kan leiden tot het scheiden van woorden, zinnen of alinea's die het begrijpen en verstoren van de stroom van informatie en begrip belemmeren.
Semantisch segmenteren. Deze methode verdeelt de tekst in segmenten op basis van semantisch begrip. Scheidingsgrenzen zijn gericht op zinsonderwerp en gebruiken aanzienlijke rekenalgoritme complexe resources. Het heeft echter het unieke voordeel van het handhaven van semantische consistentie binnen elk segment. Dit is handig voor tekstsamenvatting, sentimentanalyse en documentclassificatietaken.
Semantisch segmenteren met document intelligence-indelingsmodel
Markdown is een gestructureerde en opgemaakte opmaaktaal en een populaire invoer voor het inschakelen van semantische segmenten in RAG (Ophalen-Augmented Generation). U kunt de Markdown-inhoud van het indelingsmodel gebruiken om documenten te splitsen op basis van alineagrenzen, specifieke segmenten voor tabellen te maken en uw segmenteringsstrategie af te stemmen om de kwaliteit van de gegenereerde antwoorden te verbeteren.
Voordelen van het gebruik van het indelingsmodel
Vereenvoudigde verwerking. U kunt verschillende documenttypen parseren, zoals digitale en gescande PDF's, afbeeldingen, Office-bestanden (docx, xlsx, pptx) en HTML, met slechts één API-aanroep.
Schaalbaarheid en AI-kwaliteit. Het indelingsmodel is zeer schaalbaar in OCR (Optical Character Recognition), tabelextractie en documentstructuuranalyse. Het biedt ondersteuning voor 309 afgedrukte en 12 handgeschreven talen, en zorgt voor hoogwaardige resultaten op basis van AI-mogelijkheden.
Llm-compatibiliteit (Large Language Model). De met Markdown opgemaakte uitvoer van het indelingsmodel is geschikt voor LLM en vereenvoudigt naadloze integratie in uw werkstromen. U kunt elke tabel in een document omzetten in Markdown-indeling en veel moeite voorkomen om de documenten te parseren voor meer informatie over LLM.
Tekstafbeelding verwerkt met Document Intelligence Studio en uitvoer naar MarkDown met behulp van indelingsmodel

Tabelafbeelding verwerkt met Document Intelligence Studio met behulp van indelingsmodel
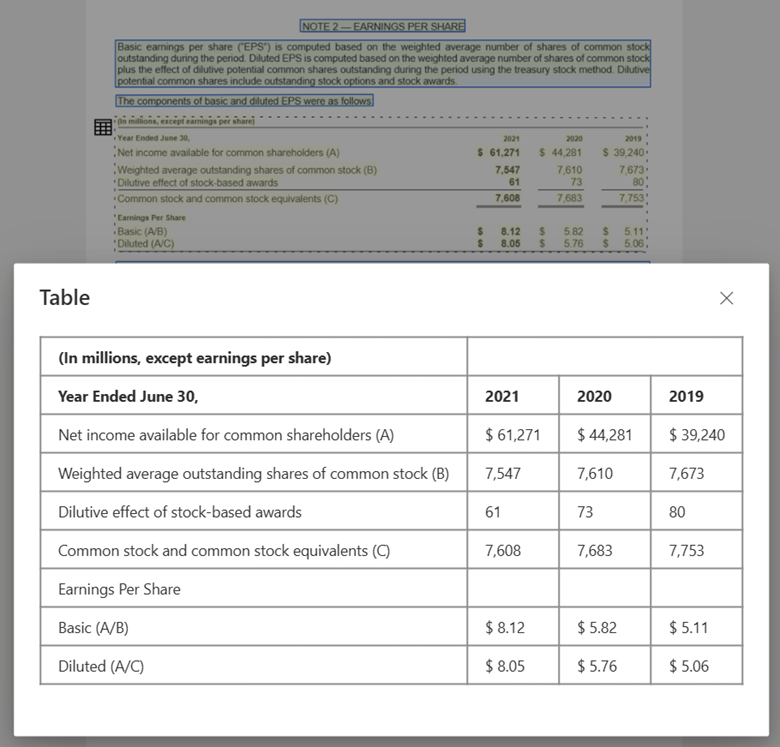
Aan de slag
Het document intelligence-indelingsmodel 2024-02-29-preview en 2023-10-31-preview ondersteunt de volgende ontwikkelopties:
Klaar om te beginnen?
Document Intelligence Studio
U kunt de quickstart van Document Intelligence Studio volgen om aan de slag te gaan. Vervolgens kunt u Document Intelligence-functies integreren met uw eigen toepassing met behulp van de meegeleverde voorbeeldcode.
Begin met het indelingsmodel. U moet de volgende analyseopties selecteren om RAG te gebruiken in de studio:
**Required**- Analysebereik uitvoeren → huidig document.
- Paginabereik → Alle pagina's.
- Stijl voor uitvoerindeling → Markdown.
**Optional**- U kunt ook relevante optionele detectieparameters selecteren.
Selecteer Opslaan.
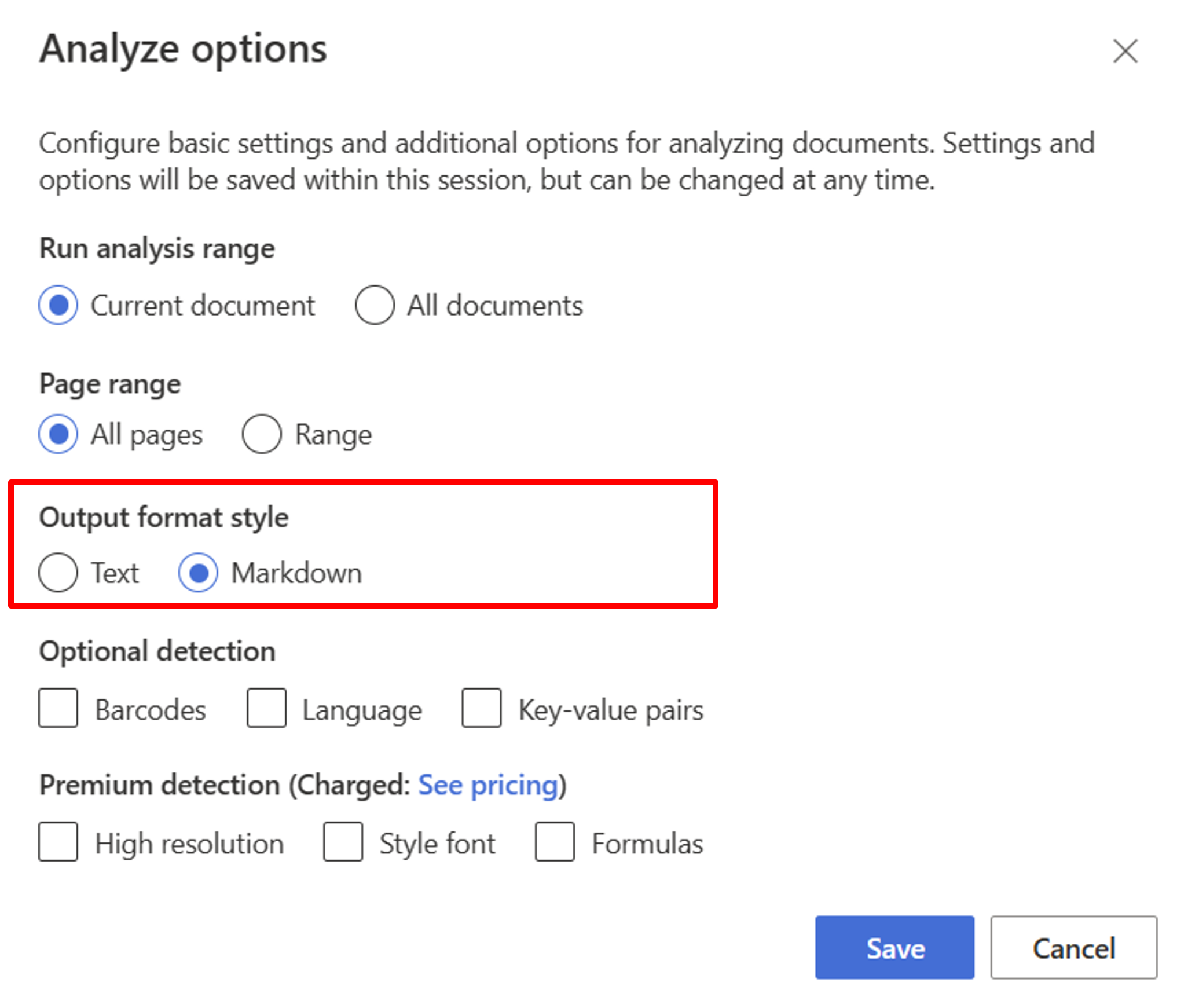
Selecteer de knop Analyse uitvoeren om de uitvoer weer te geven.

SDK of REST API
U kunt de quickstart voor Document Intelligence volgen voor de SDK voor de programmeertaal of REST API van uw voorkeur. Gebruik het indelingsmodel om inhoud en structuur uit uw documenten te extraheren.
U kunt gitHub-opslagplaatsen ook bekijken voor codevoorbeelden en tips voor het analyseren van een document in markdown-uitvoerindeling.
Documentchat maken met semantische segmenten
Met Azure OpenAI op uw gegevens kunt u ondersteunde chats uitvoeren op uw documenten. Azure OpenAI op uw gegevens past het document intelligence-indelingsmodel toe om documentgegevens te extraheren en te parseren door lange tekst te segmenteren op basis van tabellen en alinea's. U kunt uw segmenteringsstrategie ook aanpassen met behulp van Azure OpenAI-voorbeeldscripts in onze GitHub-opslagplaats.
Azure AI Document Intelligence is nu geïntegreerd met LangChain als een van de documentlaadders. U kunt deze gebruiken om de gegevens en uitvoer eenvoudig te laden in markdown-indeling. Zie onze voorbeeldcode met een eenvoudige demo voor RAG-patroon met Azure AI Document Intelligence als documentlaadprogramma en Azure Search als retriever in LangChain voor meer informatie.
In het voorbeeld van de chat met uw codevoorbeeld voor de gegevensoplossingsversneller ziet u een voorbeeld van een end-to-end rag-basislijnpatroon. Azure AI Search wordt gebruikt als retriever en Azure AI Document Intelligence voor het laden van documenten en semantische segmenten.
Gebruiksscenario
Als u op zoek bent naar een specifieke sectie in een document, kunt u semantische segmenten gebruiken om het document te verdelen in kleinere segmenten op basis van de sectiekoppen waarmee u de sectie kunt vinden die u snel en eenvoudig zoekt:
# Using SDK targeting 2024-02-29-preview or 2023-10-31-preview, make sure your resource is in one of these regions: East US, West US2, West Europe
# pip install azure-ai-documentintelligence==1.0.0b1
# pip install langchain langchain-community azure-ai-documentintelligence
from azure.ai.documentintelligence import DocumentIntelligenceClient
endpoint = "https://<my-custom-subdomain>.cognitiveservices.azure.com/"
key = "<api_key>"
from langchain_community.document_loaders import AzureAIDocumentIntelligenceLoader
from langchain.text_splitter import MarkdownHeaderTextSplitter
# Initiate Azure AI Document Intelligence to load the document. You can either specify file_path or url_path to load the document.
loader = AzureAIDocumentIntelligenceLoader(file_path="<path to your file>", api_key = key, api_endpoint = endpoint, api_model="prebuilt-layout")
docs = loader.load()
# Split the document into chunks base on markdown headers.
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
text_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
docs_string = docs[0].page_content
splits = text_splitter.split_text(docs_string)
splits
Volgende stappen
Meer informatie over Azure AI Document Intelligence.
Meer informatie over het verwerken van uw eigen formulieren en documenten met Document Intelligence Studio.
Voltooi een quickstart voor Document Intelligence en ga aan de slag met het maken van een app voor documentverwerking in de ontwikkeltaal van uw keuze.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor