Een aangepast classificatiemodel bouwen en trainen
Deze inhoud is van toepassing op:![]() v4.0 (preview) | Vorige versies:
v4.0 (preview) | Vorige versies: ![]() v3.1 (GA)
v3.1 (GA) ![]() v3.0 (GA)
v3.0 (GA)
Belangrijk
Het aangepaste classificatiemodel is momenteel beschikbaar als openbare preview. Functies, benaderingen en processen kunnen veranderen, vóór algemene beschikbaarheid (GA), op basis van feedback van gebruikers.
Aangepaste classificatiemodellen kunnen elke pagina in een invoerbestand classificeren om een of meer documenten binnen te identificeren. Classificatiemodellen kunnen ook meerdere documenten of meerdere exemplaren van één document in het invoerbestand identificeren. Aangepaste modellen voor Document Intelligence vereisen slechts vijf trainingsdocumenten per documentklasse om aan de slag te gaan. Als u aan de slag wilt gaan met het trainen van een aangepast classificatiemodel, hebt u ten minste vijf documenten nodig voor elke klasse en twee klassen documenten.
Invoervereisten voor aangepast classificatiemodel
Zorg ervoor dat uw trainingsgegevensset voldoet aan de invoervereisten voor Document Intelligence.
Ondersteunde bestandsindelingen:
Modelleren PDF Afbeelding: JPEG/JPG,PNG,BMP, ,TIFFHEIFMicrosoft Office:
Word (), Excel (XLSXDOCX), PowerPoint (PPTX), HTMLRead ✔ ✔ ✔ Indeling ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) Algemeen document ✔ ✔ Vooraf gebouwd ✔ ✔ Aangepaste extractie ✔ ✔ Aangepaste classificatie ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) Geef voor de beste resultaten één duidelijke foto of een hoogwaardige scan per document op.
Voor PDF en TIFF kunnen maximaal 2000 pagina's worden verwerkt (met een gratis abonnement worden alleen de eerste twee pagina's verwerkt).
De bestandsgrootte voor het analyseren van documenten is 500 MB voor betaalde (S0) laag en
4MB voor gratis (F0).De afmetingen van de afbeelding moeten tussen 50 x 50 pixels en 10.000 pixels x 10.000 pixels zijn.
Als uw PDF's zijn vergrendeld met een wachtwoord, moet u de vergrendeling verwijderen voordat u ze indient.
De minimale hoogte van de tekst die moet worden geëxtraheerd, is 12 pixels voor een afbeelding van 1024 x 768 pixels. Deze dimensie komt overeen met punttekst
8op 150 punten per inch (DPI).Voor aangepaste modeltraining is het maximum aantal pagina's voor trainingsgegevens 500 voor het aangepaste sjabloonmodel en 50.000 voor het aangepaste neurale model.
Voor het trainen van aangepaste extractiemodellen is de totale grootte van trainingsgegevens 50 MB voor het sjabloonmodel en
1GB voor het neurale model.Voor het trainen van aangepast classificatiemodel is
1de totale grootte van trainingsgegevens GB met maximaal 10.000 pagina's. Voor 2024-07-31-preview en hoger is2de totale grootte van trainingsgegevens GB met maximaal 10.000 pagina's.
Tips voor trainingsgegevens
Volg deze tips om uw gegevensset verder te optimaliseren voor training:
Gebruik indien mogelijk PDF-documenten op basis van tekst in plaats van op afbeeldingen gebaseerde documenten. Gescande PDF-bestanden worden verwerkt als afbeeldingen.
Als uw formulierafbeeldingen van lagere kwaliteit zijn, gebruikt u een grotere gegevensset (bijvoorbeeld 10-15 afbeeldingen).
Uw trainingsgegevens uploaden
Zodra u de set formulieren of documenten voor training hebt samengesteld, moet u deze uploaden naar een Azure Blob Storage-container. Als u niet weet hoe u een Azure-opslagaccount met een container maakt, volgt u de quickstart voor Azure Storage voor Azure Portal. U kunt de gratis prijscategorie (F0) gebruiken om de service uit te proberen en later upgraden naar een betaalde laag voor productie. Als uw gegevensset is ingedeeld als mappen, moet u die structuur behouden, omdat studio uw mapnamen voor labels kan gebruiken om het labelproces te vereenvoudigen.
Een classificatieproject maken in Document Intelligence Studio
Document Intelligence Studio biedt en organiseert alle API-aanroepen die nodig zijn om uw gegevensset te voltooien en uw model te trainen.
Ga eerst naar Document Intelligence Studio. De eerste keer dat u Studio gebruikt, moet u uw abonnement, resourcegroep en resource initialiseren. Volg vervolgens de vereisten voor aangepaste projecten om de Studio te configureren voor toegang tot uw trainingsgegevensset.
Selecteer in Studio de tegel Aangepast classificatiemodel , in de sectie aangepaste modellen van de pagina en selecteer de knop Een project maken.

Geef in het
Create Projectdialoogvenster een naam op voor uw project, eventueel een beschrijving en selecteer Doorgaan.Kies of selecteer vervolgens een Document Intelligence-resource voordat u doorgaat.
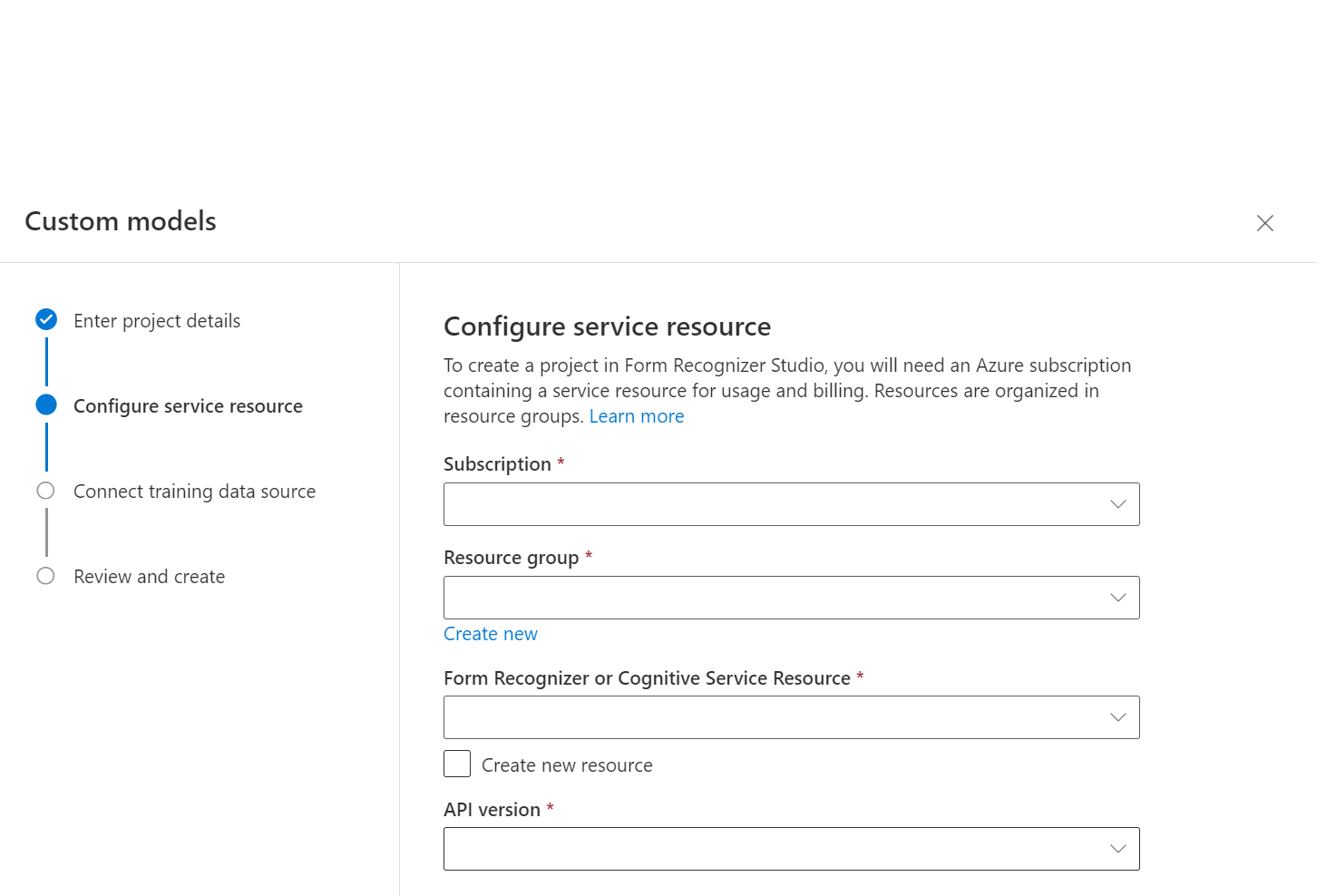
Selecteer vervolgens het opslagaccount dat u hebt gebruikt om uw aangepaste modeltrainingsgegevensset te uploaden. Het pad Map moet leeg zijn als uw trainingsdocumenten zich in de hoofdmap van de container bevinden. Als uw documenten zich in een submap bevinden, voert u het relatieve pad uit de hoofdmap van de container in het padveld Map in. Zodra uw opslagaccount is geconfigureerd, selecteert u Doorgaan.
Belangrijk
U kunt de trainingsgegevensset organiseren op mappen waar de mapnaam het label of de klasse voor documenten is of een platte lijst met documenten maken waaraan u een label kunt toewijzen in Studio.
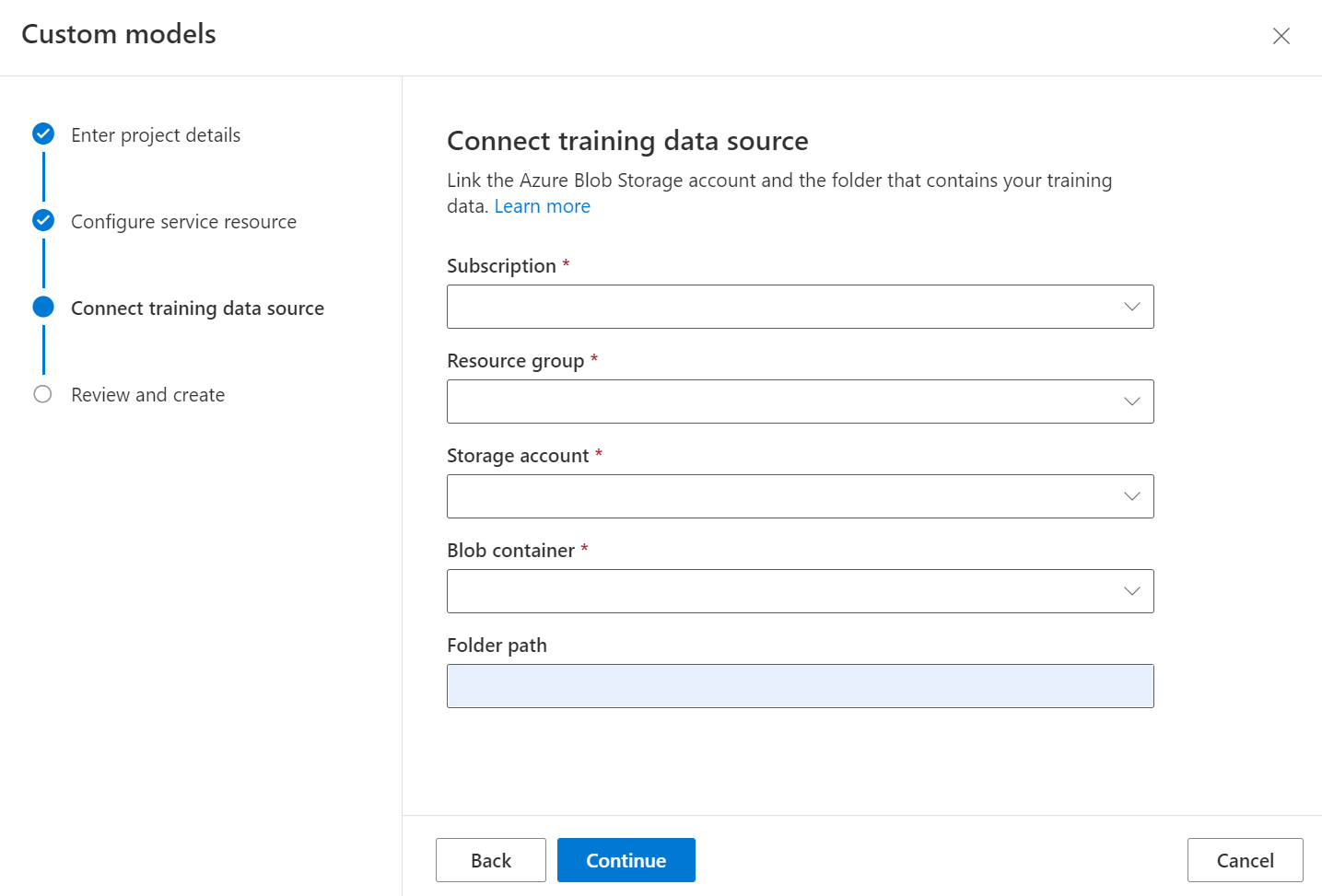
Voor het trainen van een aangepaste classificatie is de uitvoer van het indelingsmodel vereist voor elk document in uw gegevensset. Indeling uitvoeren op alle documenten vóór het modeltrainingsproces.
Controleer ten slotte de projectinstellingen en selecteer Project maken om een nieuw project te maken. U moet nu in het labelvenster staan en de bestanden in de lijst met gegevenssets zien.
Uw gegevens labelen
In uw project hoeft u alleen elk document te labelen met het juiste klasselabel.
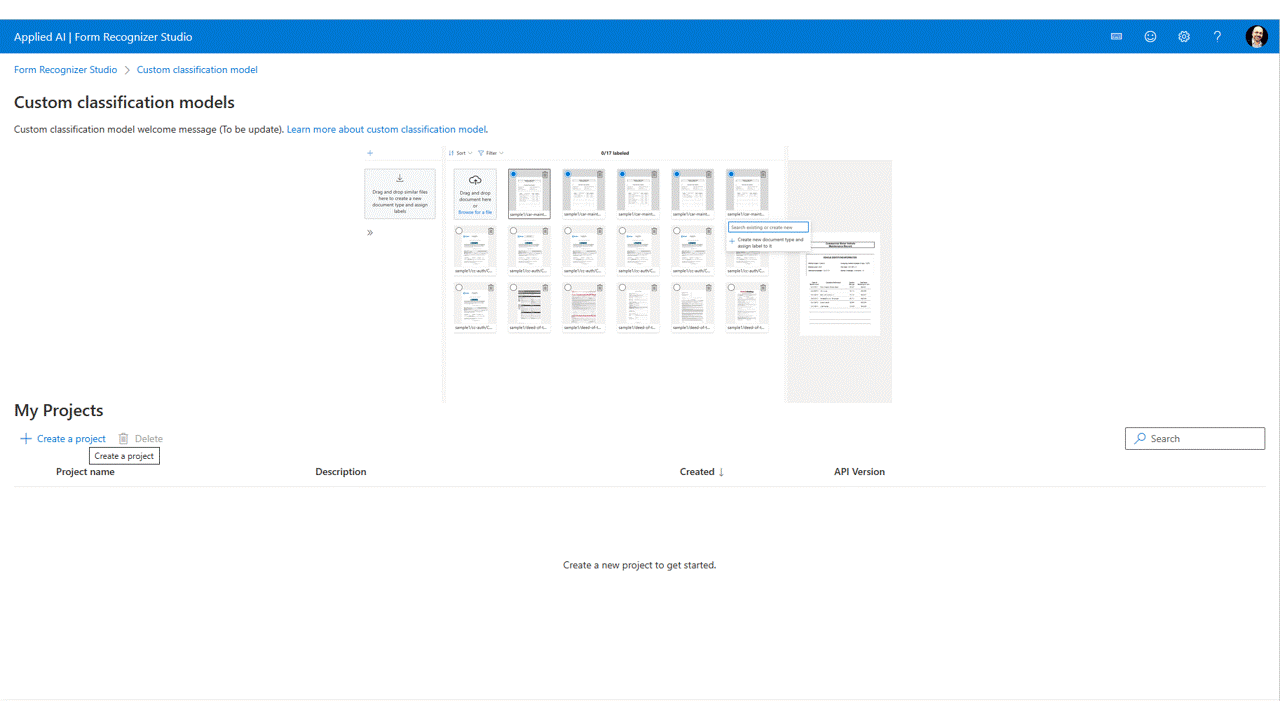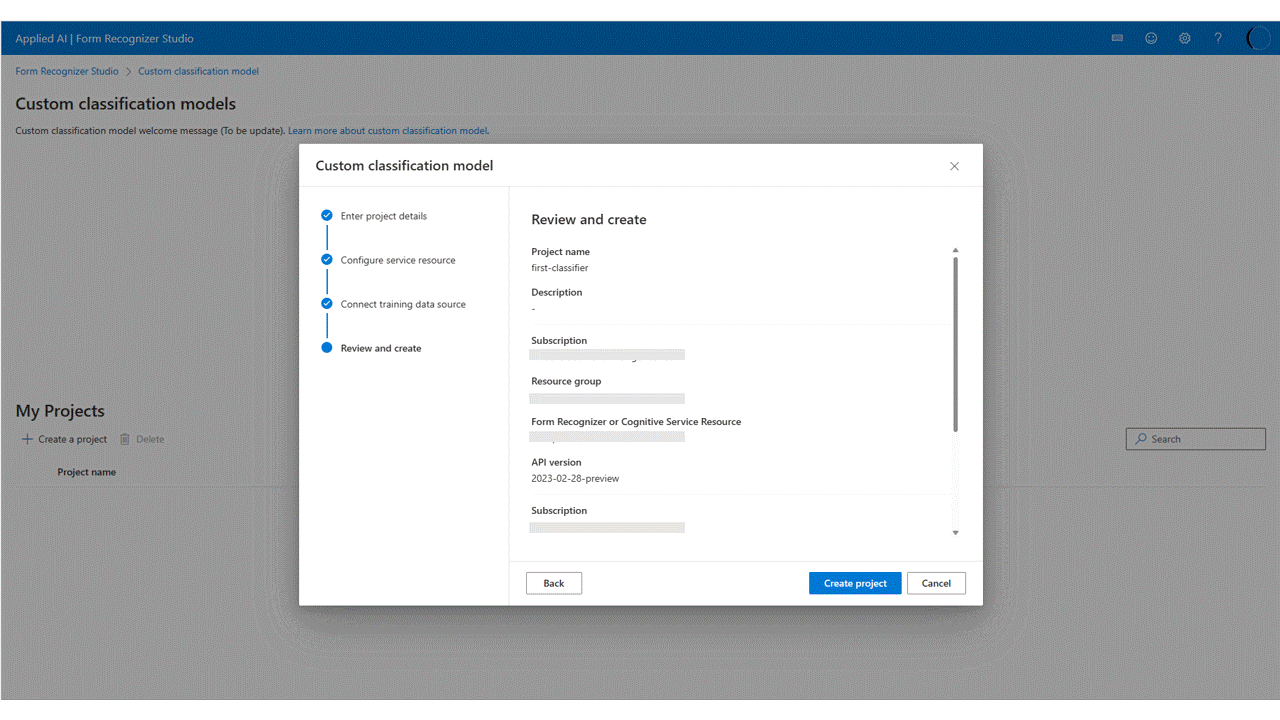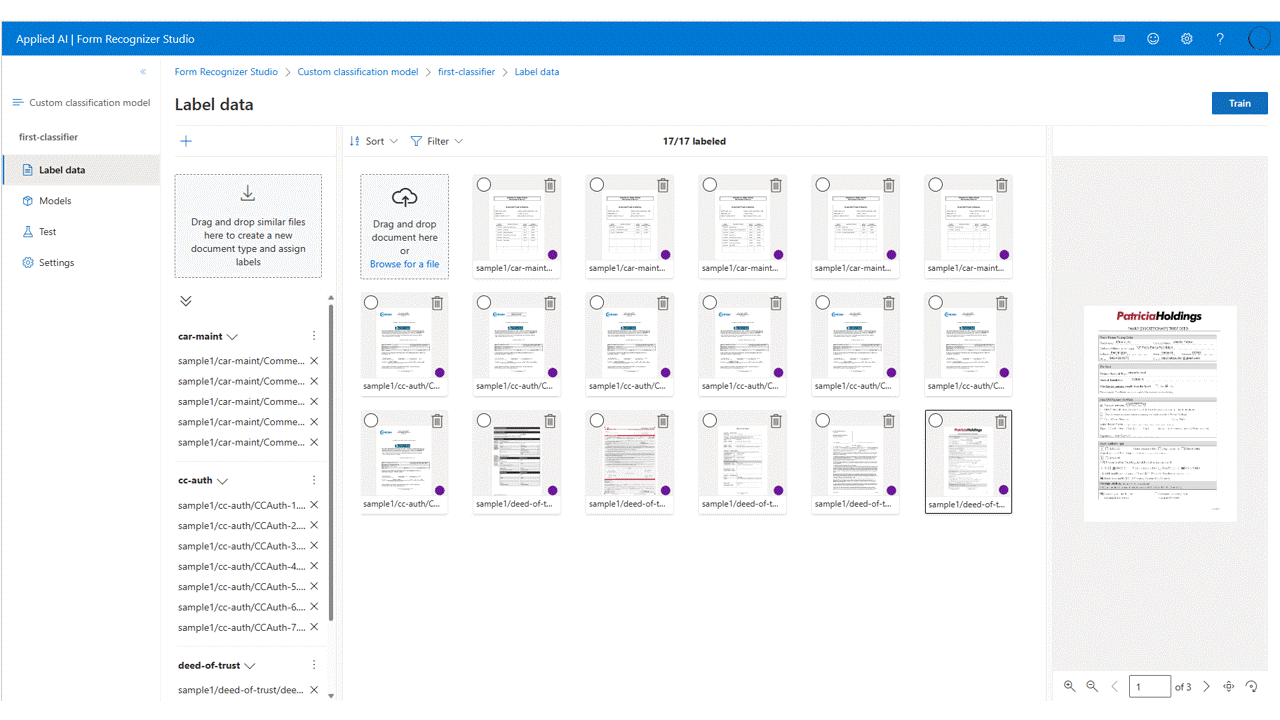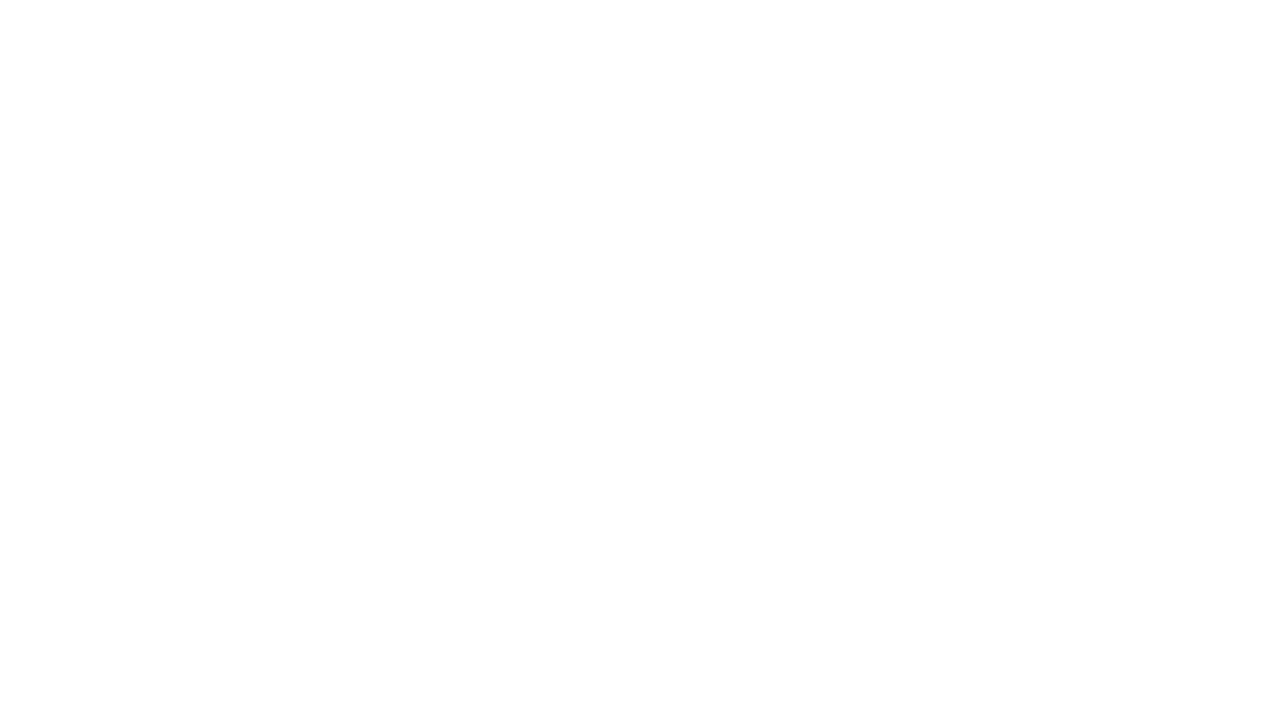
U ziet de bestanden die u hebt geüpload naar de opslag in de lijst met bestanden, klaar om te worden gelabeld. U hebt een aantal opties om uw gegevensset te labelen.
Als de documenten zijn ingedeeld in mappen, wordt u gevraagd de mapnamen als labels te gebruiken. Deze stap vereenvoudigt het labelen tot één selectie.
Als u een label aan een document wilt toewijzen, selecteert u de
add label selection markoptie om een label toe te wijzen.Besturingselement selecteren om documenten met meerdere selecties toe te wijzen om een label toe te wijzen
U moet nu alle documenten in uw gegevensset hebben gelabeld. Als u naar het opslagaccount kijkt, vindt u .ocr.json bestanden die overeenkomen met elk document in uw trainingsgegevensset en een nieuw class-name.jsonl-bestand voor elke klasse met het label. Deze trainingsgegevensset wordt verzonden om het model te trainen.
Uw model trainen
Nu uw gegevensset is gelabeld, kunt u uw model trainen. Selecteer de knop Trainen in de rechterbovenhoek.
Geef in het dialoogvenster trainmodel een unieke classificatie-id en eventueel een beschrijving op. De classificatie-id accepteert een gegevenstype tekenreeks.
Selecteer Trainen om het trainingsproces te starten.
Classificatiemodellen trainen over een paar minuten.
Navigeer naar het menu Modellen om de status van de treinbewerking weer te geven.
Het model testen
Zodra de modeltraining is voltooid, kunt u uw model testen door het model te selecteren op de pagina met de modellenlijst.
Selecteer het model en selecteer op de knop Testen .
Voeg een nieuw bestand toe door te bladeren naar een bestand of een bestand neer te zetten in de documentkiezer.
Als een bestand is geselecteerd, kiest u de knop Analyseren om het model te testen.
De modelresultaten worden weergegeven met de lijst met geïdentificeerde documenten, een betrouwbaarheidsscore voor elk geïdentificeerd document en het paginabereik voor elk van de geïdentificeerde documenten.
Valideer uw model door de resultaten te evalueren voor elk geïdentificeerd document.
Een aangepaste classificatie trainen met behulp van de SDK of API
In Studio worden de API-aanroepen voor u ingedeeld om een aangepaste classificatie te trainen. De classificatietrainingsgegevensset vereist de uitvoer van de indelings-API die overeenkomt met de versie van de API voor uw trainingsmodel. Het gebruik van indelingsresultaten van een oudere API-versie kan resulteren in een model met een lagere nauwkeurigheid.
Studio genereert de indelingsresultaten voor uw trainingsgegevensset als de gegevensset geen indelingsresultaten bevat. Wanneer u de API of SDK gebruikt om een classificatie te trainen, moet u de indelingsresultaten toevoegen aan de mappen met de afzonderlijke documenten. De indelingsresultaten moeten de indeling van het API-antwoord hebben bij het rechtstreeks aanroepen van de indeling. Het SDK-objectmodel is anders. Zorg ervoor dat dit layout results de API-resultaten zijn en niet de SDK response.
Problemen oplossen
Het classificatiemodel vereist resultaten van het indelingsmodel voor elk trainingsdocument. Als u de indelingsresultaten niet opgeeft, probeert Studio het indelingsmodel voor elk document uit te voeren voordat de classificatie wordt getraind. Dit proces wordt beperkt en kan resulteren in een 429-antwoord.
Voordat u in Studio met het classificatiemodel traint, voert u het indelingsmodel uit op elk document en uploadt u het naar dezelfde locatie als het oorspronkelijke document. Zodra de indelingsresultaten zijn toegevoegd, kunt u het classificatiemodel trainen met uw documenten.