Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Deze inhoud is van toepassing op:![]() v4.0 (GA) | Vorige versies:
v4.0 (GA) | Vorige versies:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (buiten gebruik stellen)
v3.0 (buiten gebruik stellen)![]() v2.1 (buiten gebruik stellen)
v2.1 (buiten gebruik stellen)
::: moniker-end
Deze inhoud is van toepassing op:![]() v3.0 (buiten gebruik stellen) | Nieuwste versies:
v3.0 (buiten gebruik stellen) | Nieuwste versies:![]() v4.0 (GA)
v4.0 (GA)![]() v3.1 | Vorige versie:
v3.1 | Vorige versie:![]() v2.1 (buiten gebruik stellen)
v2.1 (buiten gebruik stellen)
Deze inhoud is van toepassing op:![]() v2.1 | Latest version:
v2.1 | Latest version:![]() v4.0 (GA)
v4.0 (GA)
Opmerking
Document Intelligence-API v4.0 2024-11-30 (GA) voor het vooraf samengestelde identiteitsdocumentmodel (ID) ondersteunt nu identificatiedocumenten uit alle regio's wereldwijd, waaronder uitgebreide dekking in Noord-Amerika, Zuid-Amerika, Azië, Europa, Afrika en Oceanië.
Document Intelligence Identity Document -model (ID) combineert Optical Character Recognition (OCR) met Deep Learning-modellen om belangrijke informatie uit identiteitsdocumenten te analyseren en te extraheren. De API analyseert identiteitsdocumenten (inclusief de volgende) en retourneert een gestructureerde JSON-gegevensweergave.
| Regio | Documenttypen |
|---|---|
| Wereldwijd | Paspoortboek, Paspoortkaart |
| Verenigde Staten | Rijbewijs, identificatiekaart, verblijfsvergunning (groene kaart), burgerservicekaart, militaire id |
| India | Rijbewijs, PAN-kaart, Aadhaar-kaart |
| Australië | Rijbewijs, fotokaart, sleutelpas-id (inclusief digitale versie) |
| Andere | Rijbewijs, identificatiekaart, verblijfsvergunning |
Document Intelligence kan informatie analyseren en extraheren uit door de overheid uitgegeven identificatiedocumenten (ID's) met behulp van het vooraf gedefinieerde id-model. Het combineert onze krachtige OCR-mogelijkheden (Optical Character Recognition) met ID-herkenningsmogelijkheden om belangrijke informatie te extraheren uit Worldwide Passports en U.S. Driver's Licenses (alle 50 staten en D.C.). De API voor id's extraheert belangrijke informatie uit deze identiteitsdocumenten, zoals voornaam, achternaam, geboortedatum, documentnummer en meer. Deze API is beschikbaar in Document Intelligence v2.1 als een cloudservice.
Verwerking van identiteitsdocument
Identiteitsdocumentverwerking omvat het extraheren van gegevens uit identiteitsdocumenten handmatig of met behulp van op OCR gebaseerde technologie. Id-documentverwerking is een belangrijke stap in elke bedrijfsbewerking waarvoor een bewijs van identiteit is vereist. Voorbeelden hiervan zijn klantverificatie in banken en andere financiële instellingen, hypotheekaanvragen, medische bezoeken, claimverwerking, horeca en meer. Personen bieden een bewijs van hun identiteit via rijbewijs, paspoorten en andere vergelijkbare documenten, zodat het bedrijf ze efficiënt kan verifiëren voordat ze services en voordelen bieden.
Voorbeeld van een U.S. Driver's License verwerkt met Document Intelligence Studio
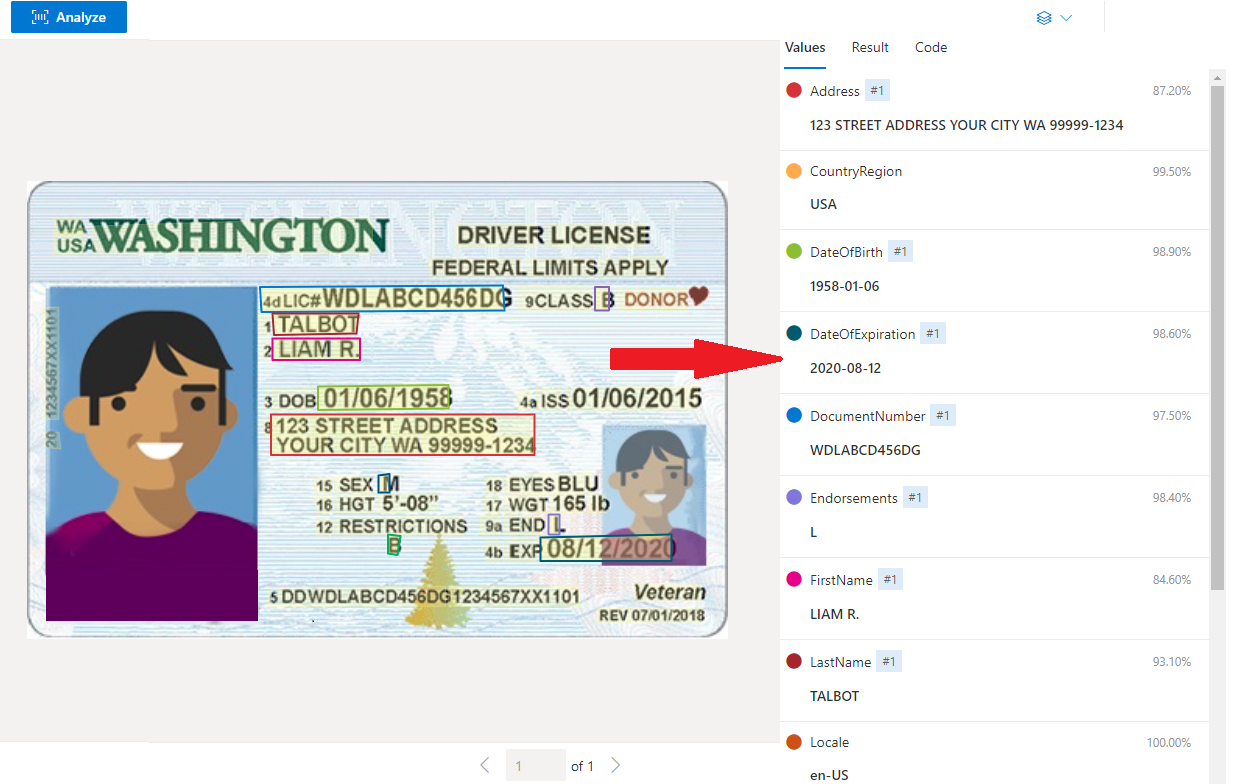
Gegevensextractie
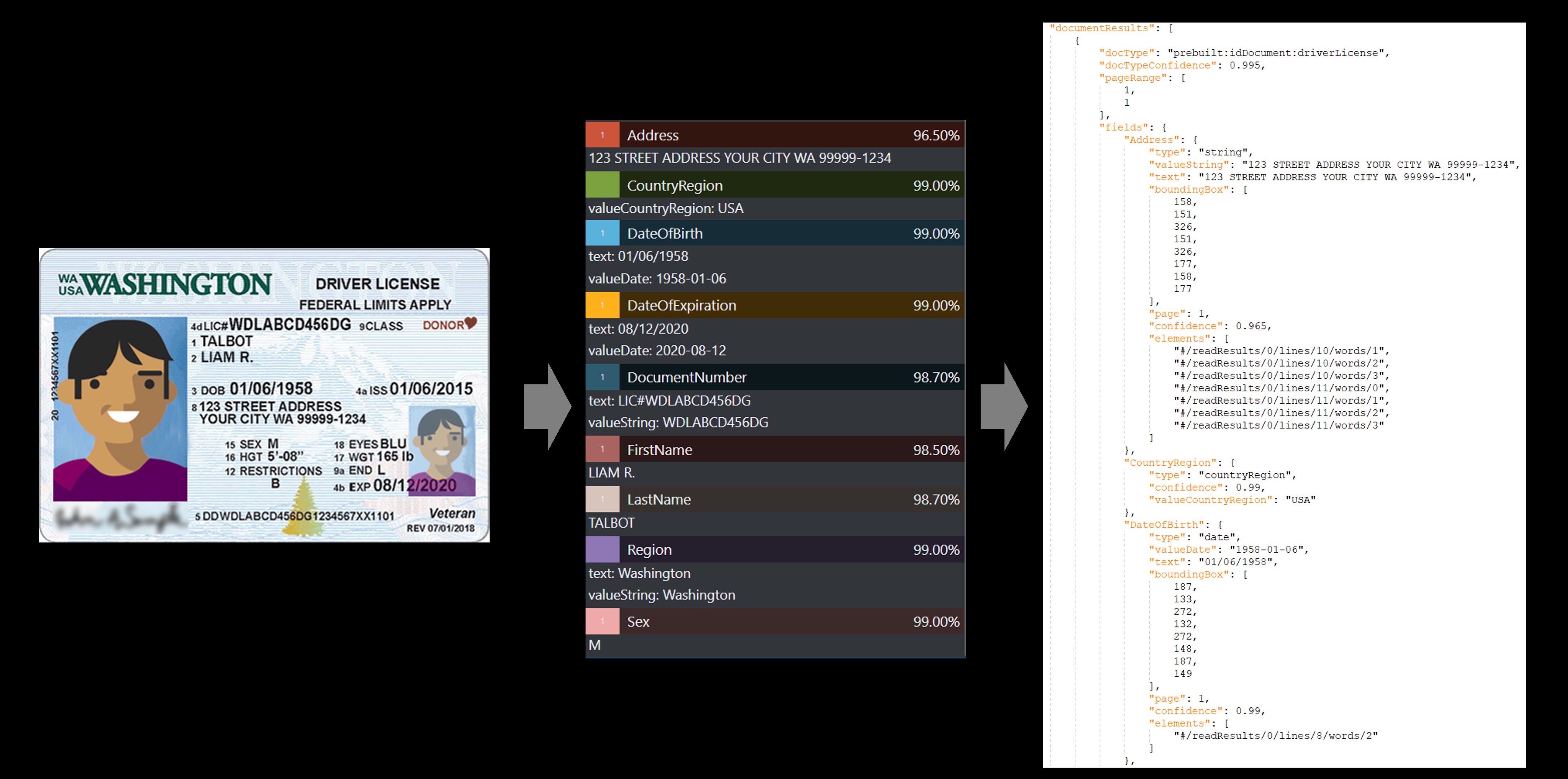
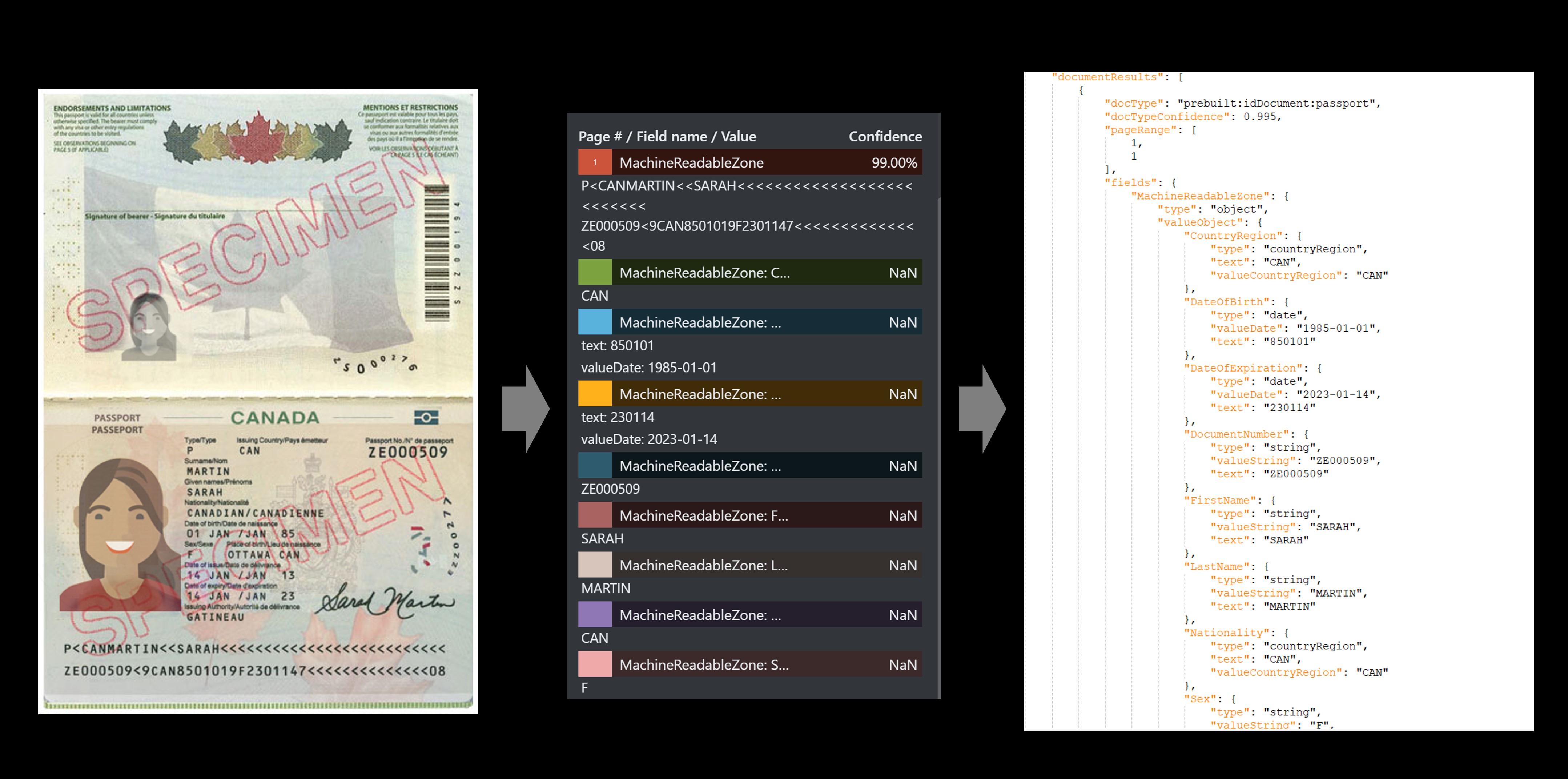
De vooraf gemaakte id's-service haalt de belangrijkste waarden op uit wereldwijde paspoorten en Amerikaanse rijbewijs's en retourneert deze in een georganiseerd gestructureerd JSON-antwoord.
Voorbeeld van rijbewijs
Passport-voorbeeld
Ontwikkelopties
Document Intelligence v4.0: 2024-11-30 (GA) ondersteunt de volgende hulpprogramma's, toepassingen en bibliotheken:
| Functie | Middelen | Model-ID |
|---|---|---|
| ID-documentmodel | • Document Intelligence Studio • REST API • C#SDK • Python SDK • Java SDK • JavaScript SDK |
vooraf samengesteld-idDocument |
Document Intelligence v3.1 ondersteunt de volgende hulpprogramma's, toepassingen en bibliotheken:
| Functie | Middelen | Model-ID |
|---|---|---|
| ID-documentmodel | • Document Intelligence Studio • REST API • C#SDK • Python SDK • Java SDK • JavaScript SDK |
vooraf samengesteld-idDocument |
Document Intelligence v3.0 ondersteunt de volgende hulpprogramma's, toepassingen en bibliotheken:
| Functie | Middelen | Model-ID |
|---|---|---|
| ID-documentmodel | • Document Intelligence Studio • REST API • C#SDK • Python SDK • Java SDK • JavaScript SDK |
vooraf samengesteld-idDocument |
Document Intelligence v2.1 ondersteunt de volgende hulpprogramma's, toepassingen en bibliotheken:
| Functie | Middelen |
|---|---|
| ID-documentmodel | • Document Intelligence-labelingstool • REST API • Client-library SDK • Document Intelligence Docker-container |
Invoervereisten
De volgende bestandsindelingen worden ondersteund.
| Model | Afbeelding: JPEG/JPG, PNG, BMP, TIFF, HEIF |
Office: Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTML |
|
|---|---|---|---|
| Lezen | ✔ | ✔ | ✔ |
| Indeling | ✔ | ✔ | ✔ |
| Algemeen document | ✔ | ✔ | |
| Voorgebouwd | ✔ | ✔ | |
| Aangepaste extractie | ✔ | ✔ | |
| Aangepaste classificatie | ✔ | ✔ | ✔ |
- Foto's en scans: geef één duidelijke foto of een hoogwaardige scan per document op voor de beste resultaten.
- PDF's en TIFF's: Voor PDF-bestanden en TIFF's kunnen maximaal 2000 pagina's worden verwerkt. (Met een abonnement op de gratis laag worden alleen de eerste twee pagina's verwerkt.)
- Bestandsgrootte: de bestandsgrootte voor het analyseren van documenten is 500 MB voor de betaalde laag (S0) en 4 MB voor de gratis laag (F0).
- Afbeeldingsafmetingen: De afmetingen moeten tussen 50 pixels x 50 pixels en 10.000 pixels x 10.000 pixels zijn.
- Wachtwoordvergrendelingen: als uw PDF-bestanden zijn vergrendeld met een wachtwoord, moet u de vergrendeling verwijderen voordat u ze inzendt.
- Teksthoogte: de minimale hoogte van de tekst die moet worden geëxtraheerd, is 12 pixels voor een afbeelding van 1024 x 768 pixels. Deze dimensie komt overeen met ongeveer 8-punts tekst bij 150 punten per inch.
- Aangepaste modeltraining: Het maximum aantal pagina's voor trainingsgegevens is 500 voor het aangepaste sjabloonmodel en 50.000 voor het aangepaste neurale model.
- Aangepaste extractiemodeltraining: de totale grootte van trainingsgegevens is 50 MB voor het sjabloonmodel en 1 GB voor het neurale model.
- Training voor aangepast classificatiemodel: de totale grootte van trainingsgegevens is 1 GB met maximaal 10.000 pagina's. Voor 2024-11-30 (GA) is de totale grootte van trainingsgegevens 2 GB met maximaal 10.000 pagina's.
- Office-bestandstypen (DOCX, XLSX, PPTX): de maximale tekenreekslengte is 8 miljoen tekens.
Ondersteunde bestandsindelingen: JPEG, PNG, PDF en TIFF.
Ondersteund aantal pagina's voor PDF- en TIFF-bestanden: maximaal 2000 pagina's of alleen de eerste twee pagina's voor abonnees in de gratis laag.
Ondersteunde bestandsgrootte: minder dan 50 MB TOTAAL; minimum pixels: 50 x 50 px; maximum pixels 10.000 x 10.000 px.
Id-documentmodelgegevensextractie
Gegevens extraheren, inclusief naam, geboortedatum en vervaldatum, uit id-documenten. U hebt de volgende resources nodig:
Een Azure-abonnement: u kunt gratis een abonnement maken.
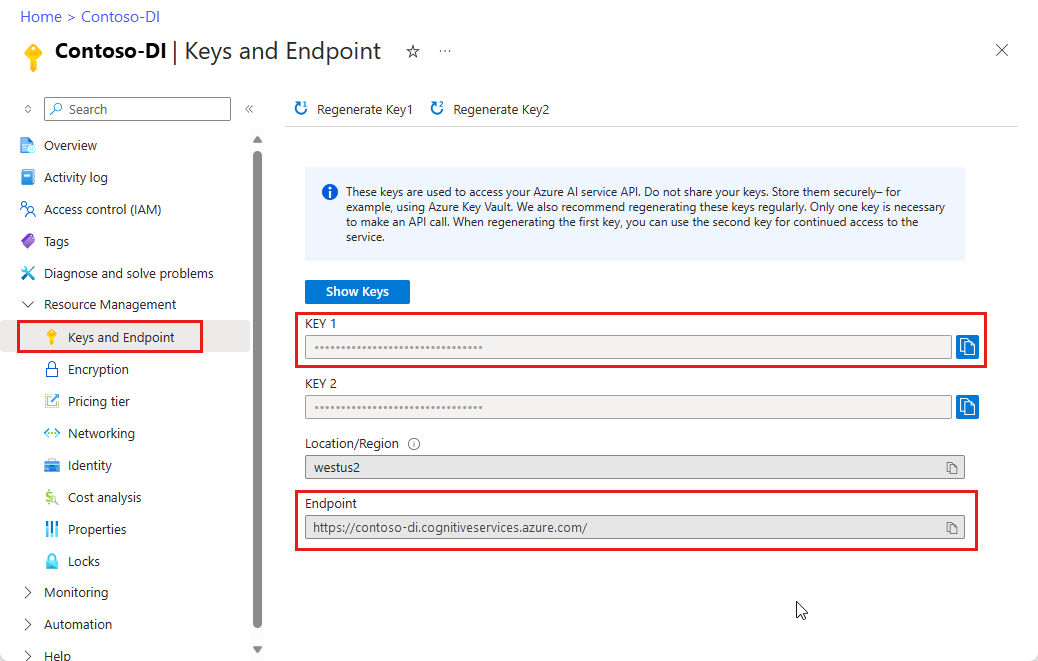
Een Document Intelligence-exemplaar in de Azure-portal. U kunt de gratis prijscategorie (
F0) gebruiken om de service uit te proberen. Nadat uw resource is geïmplementeerd, selecteert u Ga naar de resource om uw sleutel en eindpunt op te halen.
Opmerking
Document Intelligence Studio is beschikbaar met v3.1- en v3.0-API's en latere versies.
Selecteer identiteitsdocumenten op de startpagina van Document Intelligence Studio.
U kunt de voorbeeldfactuur analyseren of uw eigen bestanden uploaden.
Selecteer de knop Analyse uitvoeren en configureer indien nodig de opties analyseren:

Document Intelligence-hulpprogramma voor het labelen van voorbeelden
Navigeer naar het Documentintelligentie Voorbeeldprogramma.
Selecteer op de startpagina van het voorbeeldhulpprogramma de tegel Gebruik vooraf gebouwd model om gegevens op te halen.
Selecteer het formuliertype dat u wilt analyseren in de vervolgkeuzelijst.
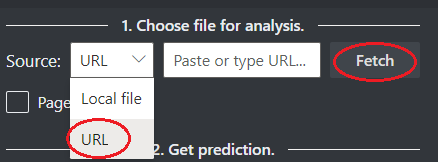
Kies een URL voor het bestand dat u wilt analyseren uit de onderstaande opties:
Selecteer in het veld Bron 'URL' in de vervolgkeuzelijst, plak de geselecteerde URL, en klik op de knop Ophalen.
Plak in het veld Eindpunt van de Document Intelligence-service het eindpunt dat u hebt verkregen met uw Document Intelligence-abonnement.
Plak in het sleutelveld de sleutel die u hebt verkregen uit uw Document Intelligence-resource.
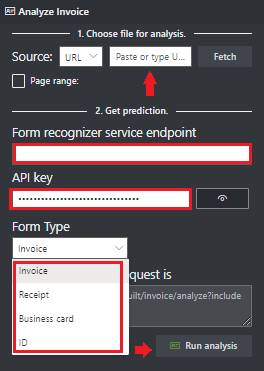
Selecteer Analyse uitvoeren. Het Document Intelligence-voorbeeldlabelhulpprogramma roept de vooraf samengestelde API analyseren aan en voert een analyse van het document uit.
Bekijk de resultaten: bekijk de sleutel-waardeparen die zijn geëxtraheerd, regelitems, gemarkeerde tekst geëxtraheerd en tabellen gedetecteerd.
Download het JSON-uitvoerbestand om de gedetailleerde resultaten weer te geven.
- De node readResults bevat elke tekstregel met de bijbehorende positie van het begrenzingsvak op de pagina.
- Het knooppunt SelectionMarks toont elk selectieteken (selectievakje, keuzerondje) en of de status is geselecteerd of niet is geselecteerd.
- De sectie pageResults bevat de geëxtraheerde tabellen. Voor elke tabel extraheert Document Intelligence de tekst, rij en kolomindex, rij- en kolomspanning, begrenzingsvak en meer.
- Het veld documentResults bevat informatie over sleutel-waardeparen en regelitems voor de meest relevante onderdelen van het document.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Opmerking
Het hulpprogramma Voorbeeldlabels biedt geen ondersteuning voor de BMP-bestandsindeling. Deze beperking is een beperking van het hulpprogramma niet van de Document Intelligence Service.
Velduitvoeringen
Voor de ondersteunde documentextractievelden, zie de pagina ID documentmodelschema in onze GitHub-voorbeeldenopslag.
Ondersteunde documenttypen
Het ID-documentmodel ondersteunt momenteel de extractie van Amerikaanse rijbewijzen en de biografische pagina van internationale paspoorten (met uitzondering van visa's en andere reisdocumenten).
Uitgepakte velden
| Naam | Type | Beschrijving | Waarde |
|---|---|---|---|
| Land | Land | Landcode conform ISO 3166-standaard | "VS" |
| Geboortedatum | Datum | Geboortedatum in JJJJ-MM-DD-formaat | "1980-01-01" |
| Vervaldatum | Datum | Vervaldatum in JJJJ-MM-DD-indeling | "2019-05-05" |
| DocumentNummer | Tekenreeks | Relevant paspoortnummer, rijbewijsnummer, enz. | "340020013" |
| Voornaam | Tekenreeks | De voornaam en het initiaal van de tweede naam, indien van toepassing, zijn geëxtraheerd. | "JENNIFER" |
| Achternaam | Tekenreeks | Uitgesplitste achternaam | BROOKS |
| Nationaliteit | Land | Landcode conform ISO 3166-standaard | "VS" |
| Sex | Geslacht | Mogelijke geëxtraheerde waarden zijn 'M' 'F' 'X' | "F" |
| MachineLeesbareZone | Object | Geëxtraheerd paspoort MRZ, inclusief twee regels met elk 44 tekens |
"P<USABROOKS<<JENNIFER<<<<<<<<<<<<<<<<<<<<<<< 3400200135USA8001014F1905054710000307<715816" |
| DocumentType | Tekenreeks | Documenttype, bijvoorbeeld Passport, Rijbewijs | "paspoort" |
| Adres | Tekenreeks | Geëxtraheerd adres (alleen rijbewijs) | "123 STRAATADRES UW STAD WA 99999-1234" |
| Regio | Tekenreeks | Geëxtraheerde regio, staat, provincie, enz. (alleen voor het rijbewijs) | "Washington" |
Migratiehandleiding
- Volg onze migratiehandleiding voor Document Intelligence v3.1 voor meer informatie over het gebruik van de versie v3.0 in uw toepassingen en werkstromen.
Volgende stappen
Probeer uw eigen formulieren en documenten te verwerken met Document Intelligence Studio.
Voltooi een quickstart voor Document Intelligence en ga aan de slag met het maken van een app voor documentverwerking in de ontwikkeltaal van uw keuze.
Probeer uw eigen formulieren en documenten te verwerken met het hulpprogramma Document Intelligence Sample Labeling.
Voltooi een quickstart voor Document Intelligence en ga aan de slag met het maken van een app voor documentverwerking in de ontwikkeltaal van uw keuze.