Quickstart: Begrip van gesprekstaal
Gebruik dit artikel om aan de slag te gaan met Conversational Language Understanding met behulp van Language Studio en de REST API. Volg deze stappen om een voorbeeld uit te proberen.
Vereisten
- Azure-abonnement: Maak een gratis abonnement aan.
Aanmelden bij Language Studio
Ga naar Language Studio en meld u aan met uw Azure-account.
Zoek uw Azure-abonnement in het venster Kies een taalresource die wordt weergegeven en kies uw taalresource. Als u geen resource hebt, kunt u een nieuwe maken.
Instantiedetails Vereiste waarde Azure-abonnement Uw Azure-abonnement. Azure-resourcegroep De naam van uw Azure-resourcegroep. Azure-resourcenaam De naam van uw Azure-resource. Locatie Een van de ondersteunde regio's voor uw taalresource. Bijvoorbeeld US - west 2. Prijscategorie Een van de geldige prijscategorieën voor uw taalresource. U kunt de gratis laag (F0) gebruiken om de service uit te proberen. 

Een gesprekstaalkennisproject maken
Zodra u een taalresource hebt geselecteerd, maakt u een gesprekstaalkennisproject. Een project is een werkgebied voor het bouwen van uw aangepaste ML-modellen op basis van uw gegevens. Uw project kan alleen worden geopend door u en anderen die toegang hebben tot de taalresource die wordt gebruikt.
Voor deze quickstart kunt u dit voorbeeldprojectbestand downloaden en importeren. Dit project kan de beoogde opdrachten voorspellen van gebruikersinvoer, zoals het lezen van e-mailberichten, het verwijderen van e-mailberichten en het toevoegen van een document aan een e-mailbericht.
Selecteer Onder de sectie Vragen begrijpen en gesprekstaal van Language Studio de optie Begrip van conversationele taal.

Hiermee gaat u naar de pagina Conversational Language Understanding-projecten . Selecteer Importeren naast de knop Nieuw project maken.
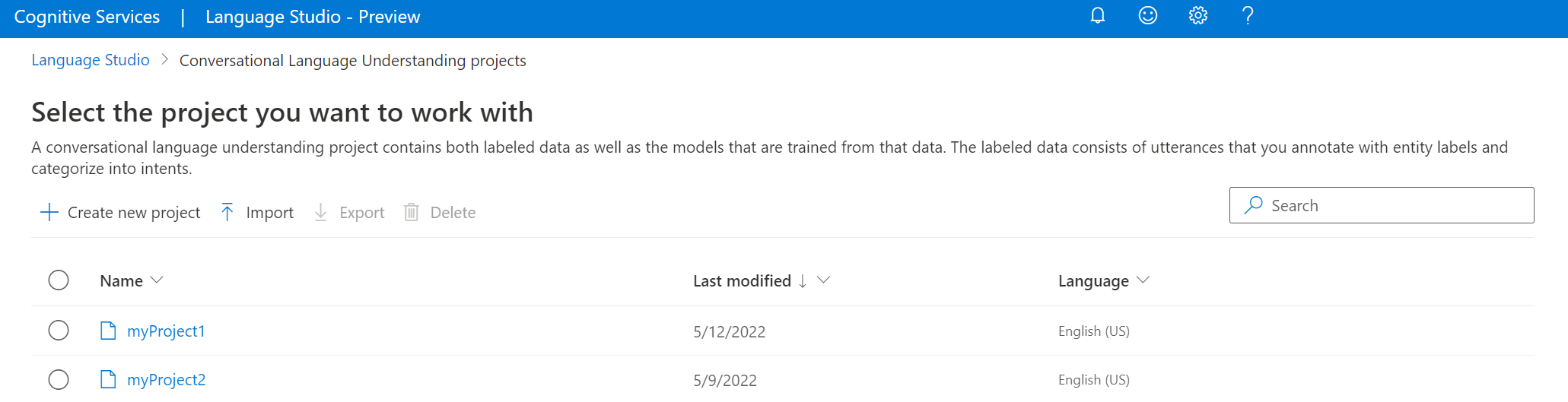
Upload het JSON-bestand dat u wilt importeren in het venster dat wordt weergegeven. Zorg ervoor dat uw bestand de ondersteunde JSON-indeling volgt.


Zodra het uploaden is voltooid, komt u terecht op de pagina Schemadefinitie . Voor deze quickstart is het schema al gebouwd en zijn utterances al gelabeld met intenties en entiteiten.
Uw model trainen
Wanneer u een project hebt gemaakt, moet u doorgaans een schema maken en utterances labelen. Voor deze quickstart hebben we al een gereed project geïmporteerd met een gebouwd schema en gelabelde utterances.
Als u een model wilt trainen, moet u een trainingstaak starten. De uitvoer van een geslaagde trainingstaak is uw getrainde model.
Ga als volgende te werk om uw model te trainen vanuit Language Studio:
Selecteer Model trainen in het menu aan de linkerkant.
Selecteer Een trainingstaak starten in het bovenste menu.
Selecteer Een nieuw model trainen en voer een nieuwe modelnaam in het tekstvak in. Als u een bestaand model anders wilt vervangen door een model dat is getraind op de nieuwe gegevens, selecteert u Een bestaand model overschrijven en selecteert u vervolgens een bestaand model . Het overschrijven van een getraind model kan niet ongedaan worden gemaakt, maar dit heeft geen invloed op uw geïmplementeerde modellen totdat u het nieuwe model implementeert.
Selecteer de trainingsmodus. U kunt Standard-training kiezen voor een snellere training, maar deze is alleen beschikbaar voor engels. U kunt ook geavanceerde training kiezen die wordt ondersteund voor andere talen en meertalige projecten, maar het gaat om langere trainingstijden. Meer informatie over trainingsmodi.
Selecteer een methode voor gegevenssplitsing . U kunt de testset automatisch splitsen op basis van trainingsgegevens , waarbij het systeem uw uitingen splitst tussen de trainings- en testsets, volgens de opgegeven percentages. Of u kunt een handmatige splitsing van trainings- en testgegevens gebruiken. Deze optie is alleen ingeschakeld als u uitingen hebt toegevoegd aan uw testset wanneer u uw utterances hebt gelabeld.
Selecteer de knop Trainen .

Selecteer de id van de trainingstaak in de lijst. Er wordt een deelvenster weergegeven waarin u de voortgang van de training, de taakstatus en andere details voor deze taak kunt controleren.
Notitie
- Alleen voltooide trainingstaken genereren modellen.
- Training kan enige tijd duren tussen een paar minuten en een paar uur op basis van het aantal uitingen.
- U kunt slechts één trainingstaak tegelijk uitvoeren. U kunt pas andere trainingstaken binnen hetzelfde project starten als de actieve taak is voltooid.
- De machine learning die wordt gebruikt om modellen te trainen, wordt regelmatig bijgewerkt. Als u wilt trainen op een eerdere configuratieversie, selecteert u hier om te wijzigen op de pagina Een trainingstaak starten en kiest u een eerdere versie.

Uw model implementeren
Over het algemeen controleert u na het trainen van een model de evaluatiedetails. In deze quickstart implementeert u uw model en stelt u het model beschikbaar om te proberen in Language Studio of kunt u de voorspellings-API aanroepen.
Uw model implementeren vanuit Language Studio:
Selecteer Een model implementeren in het menu aan de linkerkant.
Selecteer Implementatie toevoegen om de wizard Implementatie toevoegen te starten.
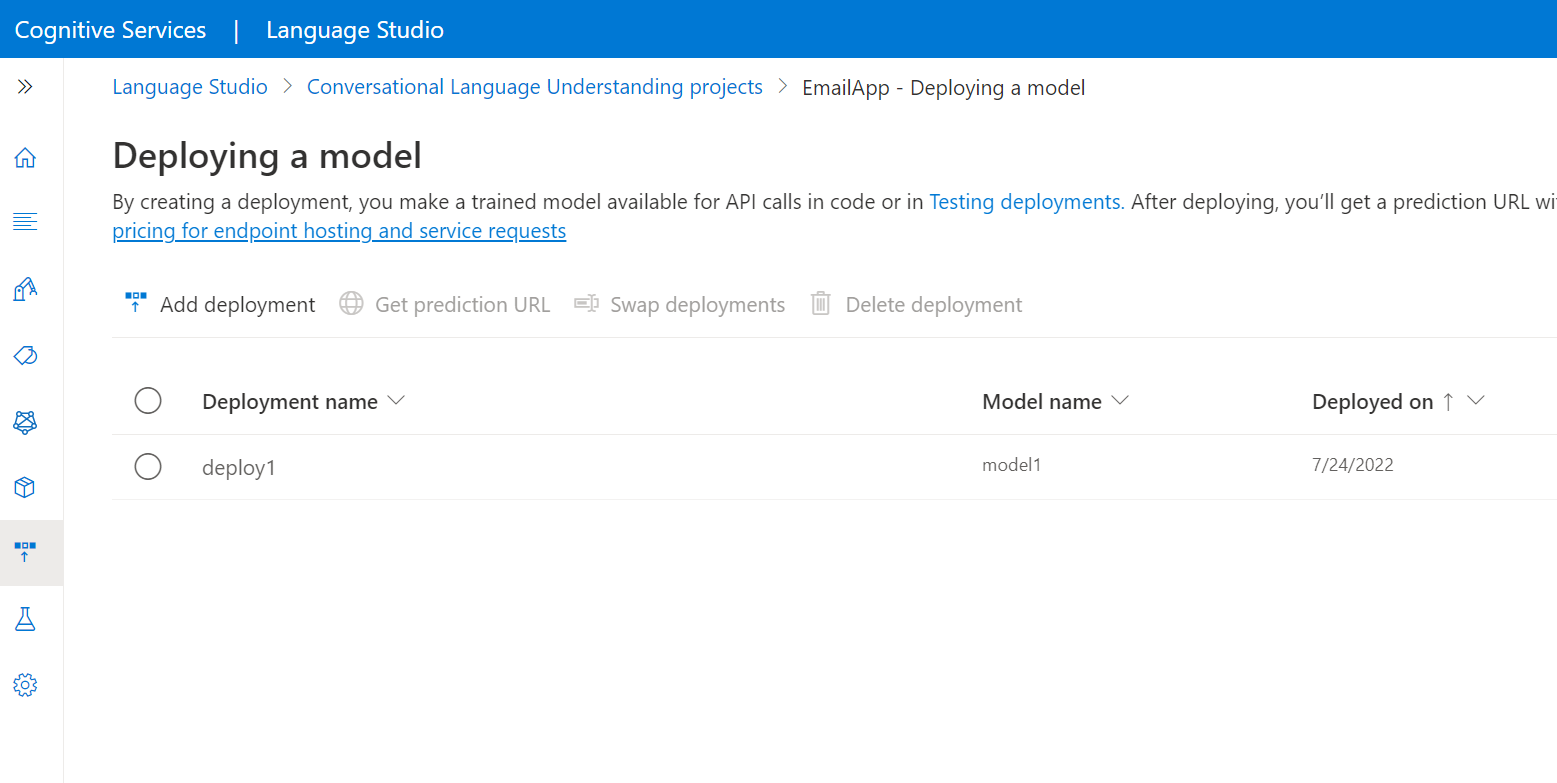
Selecteer Een nieuwe implementatienaam maken om een nieuwe implementatie te maken en wijs een getraind model toe vanuit de vervolgkeuzelijst hieronder. U kunt anders een bestaande implementatienaam overschrijven selecteren om het model dat wordt gebruikt door een bestaande implementatie effectief te vervangen.
Notitie
Het overschrijven van een bestaande implementatie vereist geen wijzigingen in uw voorspellings-API-aanroep , maar de resultaten die u krijgt, zijn gebaseerd op het zojuist toegewezen model.
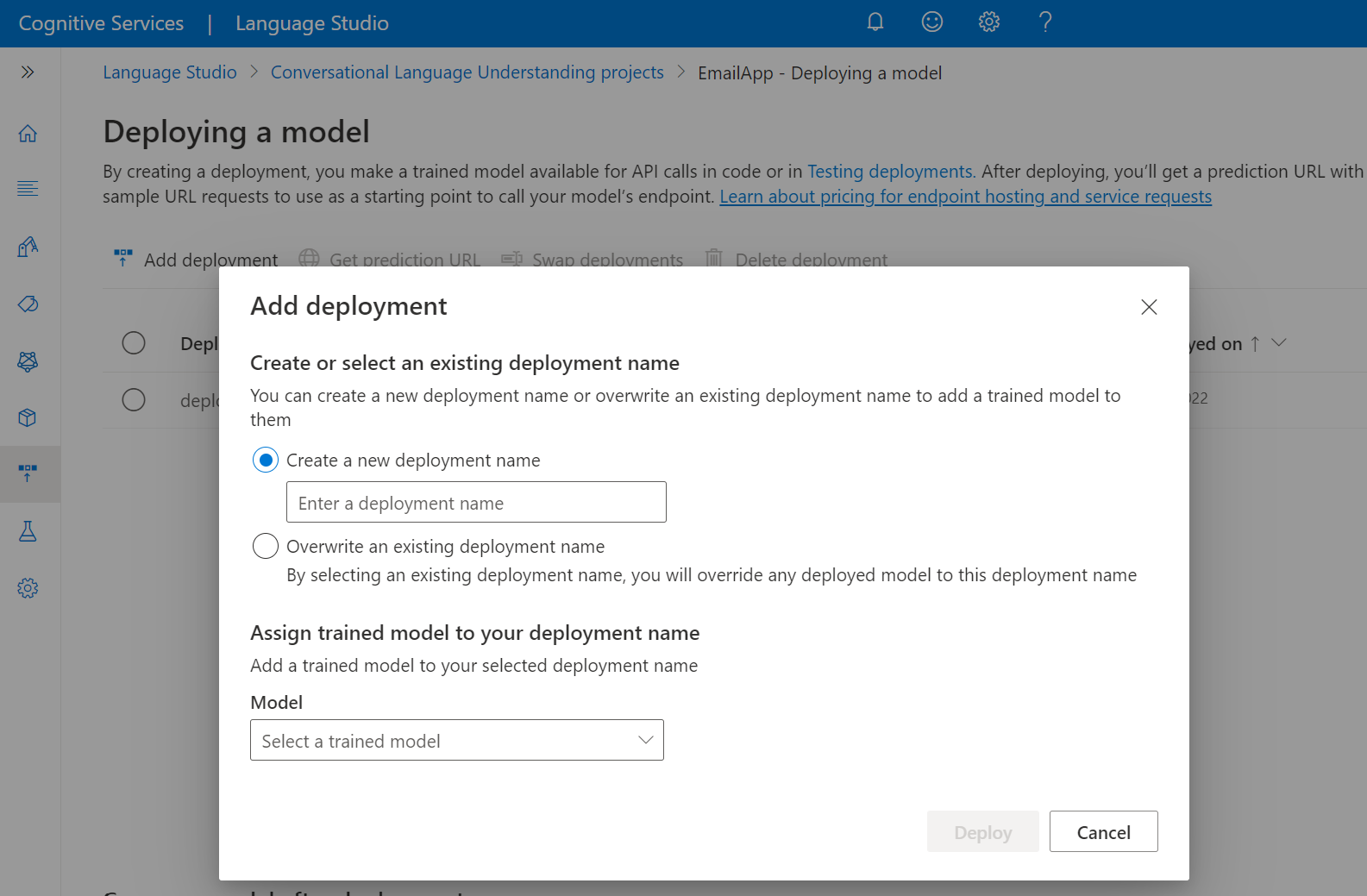
Selecteer een getraind model in de vervolgkeuzelijst Model .
Selecteer Implementeren om de implementatietaak te starten.
Nadat de implementatie is voltooid, wordt er een vervaldatum weergegeven naast de implementatie. Het verloop van de implementatie is wanneer uw geïmplementeerde model niet beschikbaar is om te worden gebruikt voor voorspelling. Dit gebeurt meestal twaalf maanden nadat een trainingsconfiguratie is verlopen.


Geïmplementeerd model testen
Uw geïmplementeerde modellen testen vanuit Language Studio:
Selecteer Implementaties testen in het menu aan de linkerkant.
Voor meertalige projecten selecteert u in de vervolgkeuzelijst Teksttaal selecteren de taal van de uiting die u test.
Selecteer in de vervolgkeuzelijst Implementatienaam de implementatienaam die overeenkomt met het model dat u wilt testen. U kunt alleen modellen testen die zijn toegewezen aan implementaties.
Voer in het tekstvak een uiting in die u wilt testen. Als u bijvoorbeeld een toepassing hebt gemaakt voor e-mailgerelateerde utterances, kunt u dit e-mailbericht verwijderen invoeren.
Selecteer De test uitvoeren boven aan de pagina.
Nadat u de test hebt uitgevoerd, ziet u het antwoord van het model in het resultaat. U kunt de resultaten weergeven in de kaartenweergave van entiteiten of weergeven in JSON-indeling.
Resources opschonen
Wanneer u uw project niet meer nodig hebt, kunt u uw project verwijderen met Behulp van Language Studio. Selecteer Projecten in het linkernavigatiemenu, selecteer het project dat u wilt verwijderen en selecteer vervolgens Verwijderen in het bovenste menu.
Vereisten
- Azure-abonnement: Maak een gratis abonnement aan.
Een nieuwe resource maken vanuit Azure Portal
Meld u aan bij Azure Portal om een nieuwe Azure AI Language-resource te maken.
Selecteer Een nieuwe resource maken
Zoek in het venster dat wordt weergegeven naar taalservice
Selecteer Maken.
Maak een taalresource met de volgende details.
Instantiedetails Vereiste waarde Regio Een van de ondersteunde regio's voor uw taalresource. Naam Vereiste naam voor uw taalresource Prijscategorie Een van de ondersteunde prijscategorieën voor uw taalresource.
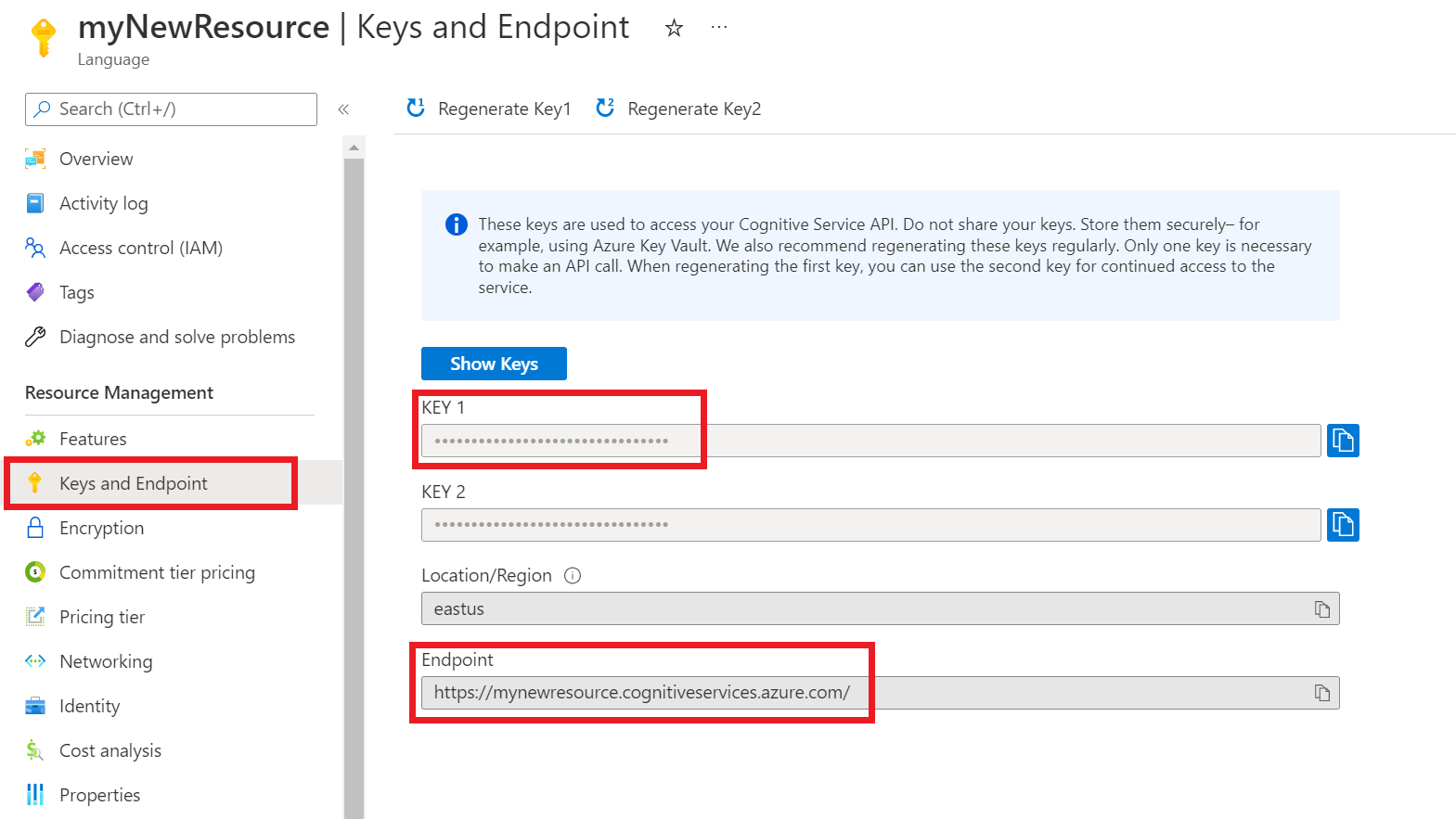
Uw resourcesleutels en eindpunt ophalen
Ga naar de overzichtspagina van uw resource in Azure Portal.
Selecteer sleutels en eindpunt in het menu aan de linkerkant. U gebruikt het eindpunt en de sleutel voor de API-aanvragen

Een nieuw CLU-voorbeeldproject importeren
Zodra u een taalresource hebt gemaakt, maakt u een gesprekstaalkennisproject. Een project is een werkgebied voor het bouwen van uw aangepaste ML-modellen op basis van uw gegevens. Uw project kan alleen worden geopend door u en anderen die toegang hebben tot de taalresource die wordt gebruikt.
Voor deze quickstart kunt u dit voorbeeldproject downloaden en importeren. Dit project kan de beoogde opdrachten voorspellen van gebruikersinvoer, zoals het lezen van e-mailberichten, het verwijderen van e-mailberichten en het toevoegen van een document aan een e-mailbericht.
De importprojecttaak activeren
Verzend een POST-aanvraag met behulp van de volgende URL, headers en JSON-hoofdtekst om uw project te importeren.
Aanvraag-URL
Gebruik de volgende URL bij het maken van uw API-aanvraag. Vervang de tijdelijke aanduidingen door uw eigen waarden.
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/:import?api-version={API-VERSION}
| Tijdelijke aanduiding | Weergegeven als | Opmerking |
|---|---|---|
{ENDPOINT} |
Het eindpunt voor het verifiëren van uw API-aanvraag. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
De naam voor uw project. Deze waarde is hoofdlettergevoelig en moet overeenkomen met de projectnaam in het JSON-bestand dat u importeert. | EmailAppDemo |
{API-VERSION} |
De versie van de API die u aanroept. | 2023-04-01 |
Kopteksten
Gebruik de volgende header om uw aanvraag te verifiëren.
| Sleutel | Weergegeven als |
|---|---|
Ocp-Apim-Subscription-Key |
De sleutel voor uw resource. Wordt gebruikt voor het verifiëren van uw API-aanvragen. |
Hoofdtekst
De JSON-hoofdtekst die u verzendt, is vergelijkbaar met het volgende voorbeeld. Raadpleeg de referentiedocumentatie voor meer informatie over het JSON-object.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectKind": "Conversation",
"settings": {
"confidenceThreshold": 0.7
},
"projectName": "{PROJECT-NAME}",
"multilingual": true,
"description": "Trying out CLU",
"language": "{LANGUAGE-CODE}"
},
"assets": {
"projectKind": "Conversation",
"intents": [
{
"category": "intent1"
},
{
"category": "intent2"
}
],
"entities": [
{
"category": "entity1"
}
],
"utterances": [
{
"text": "text1",
"dataset": "{DATASET}",
"intent": "intent1",
"entities": [
{
"category": "entity1",
"offset": 5,
"length": 5
}
]
},
{
"text": "text2",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"intent": "intent2",
"entities": []
}
]
}
}
| Sleutel | Tijdelijke aanduiding | Weergegeven als | Opmerking |
|---|---|---|---|
{API-VERSION} |
De versie van de API die u aanroept. | 2023-04-01 |
|
projectName |
{PROJECT-NAME} |
De naam van uw project. Deze waarde is hoofdlettergevoelig. | EmailAppDemo |
language |
{LANGUAGE-CODE} |
Een tekenreeks die de taalcode opgeeft voor de uitingen die in uw project worden gebruikt. Als uw project een meertalige project is, kiest u de taalcode van het merendeel van de uitingen. | en-us |
multilingual |
true |
Een booleaanse waarde waarmee u documenten in meerdere talen in uw gegevensset kunt hebben. Wanneer uw model is geïmplementeerd, kunt u een query uitvoeren op het model in elke ondersteunde taal , inclusief talen die niet zijn opgenomen in uw trainingsdocumenten. | true |
dataset |
{DATASET} |
Lees hoe u een model traint voor informatie over het splitsen van uw gegevens tussen een test- en trainingsset. Mogelijke waarden voor dit veld zijn Train en Test. |
Train |
Na een geslaagde aanvraag bevat het API-antwoord een operation-location header met een URL die u kunt gebruiken om de status van de importtaak te controleren. De indeling is als volgt:
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
De status van de importtaak ophalen
Wanneer u een geslaagde aanvraag voor het importeren van een project verzendt, wordt de volledige aanvraag-URL voor het controleren van de status van de importtaak (inclusief uw eindpunt, projectnaam en taak-id) opgenomen in de header van operation-location het antwoord.
Gebruik de volgende GET-aanvraag om een query uit te voeren op de status van uw importtaak. U kunt de URL die u hebt ontvangen uit de vorige stap gebruiken of de tijdelijke aanduidingen vervangen door uw eigen waarden.
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| Tijdelijke aanduiding | Weergegeven als | Opmerking |
|---|---|---|
{ENDPOINT} |
Het eindpunt voor het verifiëren van uw API-aanvraag. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
De naam voor uw project. Deze waarde is hoofdlettergevoelig. | myProject |
{JOB-ID} |
De id voor het zoeken naar de status van uw importtaak. | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
De versie van de API die u aanroept. | 2023-04-01 |
Kopteksten
Gebruik de volgende header om uw aanvraag te verifiëren.
| Toets | Beschrijving | Waarde |
|---|---|---|
Ocp-Apim-Subscription-Key |
De sleutel voor uw resource. Wordt gebruikt voor het verifiëren van uw API-aanvragen. | {YOUR-PRIMARY-RESOURCE-KEY} |
Hoofdtekst van de reactie
Zodra u de aanvraag hebt verzonden, krijgt u het volgende antwoord. Blijf dit eindpunt peilen totdat de statusparameter is gewijzigd in 'geslaagd'.
{
"jobId": "xxxxx-xxxxx-xxxx-xxxxx",
"createdDateTime": "2022-04-18T15:17:20Z",
"lastUpdatedDateTime": "2022-04-18T15:17:22Z",
"expirationDateTime": "2022-04-25T15:17:20Z",
"status": "succeeded"
}
Uw model trainen
Normaal gesproken moet u, nadat u een project hebt gemaakt, schema's maken en uitingen taggen. Voor deze quickstart hebben we al een gereed project geïmporteerd met een gebouwd schema en gelabelde utterances.
Maak een POST-aanvraag met behulp van de volgende URL, headers en JSON-hoofdtekst om een trainingstaak te verzenden.
Aanvraag-URL
Gebruik de volgende URL bij het maken van uw API-aanvraag. Vervang de tijdelijke aanduidingen door uw eigen waarden.
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| Tijdelijke aanduiding | Weergegeven als | Opmerking |
|---|---|---|
{ENDPOINT} |
Het eindpunt voor het verifiëren van uw API-aanvraag. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
De naam voor uw project. Deze waarde is hoofdlettergevoelig. | EmailApp |
{API-VERSION} |
De versie van de API die u aanroept. | 2023-04-01 |
Kopteksten
Gebruik de volgende header om uw aanvraag te verifiëren.
| Sleutel | Weergegeven als |
|---|---|
Ocp-Apim-Subscription-Key |
De sleutel voor uw resource. Wordt gebruikt voor het verifiëren van uw API-aanvragen. |
Aanvraagtekst
Gebruik het volgende object in uw aanvraag. Het model krijgt de naam van de waarde die u voor de parameter gebruikt zodra de modelLabel training is voltooid.
{
"modelLabel": "{MODEL-NAME}",
"trainingMode": "{TRAINING-MODE}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"testingSplitPercentage": 20,
"trainingSplitPercentage": 80
}
}
| Sleutel | Tijdelijke aanduiding | Weergegeven als | Opmerking |
|---|---|---|---|
modelLabel |
{MODEL-NAME} |
De naam van uw model. | Model1 |
trainingConfigVersion |
{CONFIG-VERSION} |
De versie van het trainingsconfiguratiemodel. Standaard wordt de nieuwste modelversie gebruikt. | 2022-05-01 |
trainingMode |
{TRAINING-MODE} |
De trainingsmodus die moet worden gebruikt voor training. Ondersteunde modi zijn Standaardtraining, snellere training, maar alleen beschikbaar voor Engels en Geavanceerde training die wordt ondersteund voor andere talen en meertalige projecten, maar omvat langere trainingstijden. Meer informatie over trainingsmodi. | standard |
kind |
percentage |
Splitsmethoden. Mogelijke waarden zijn percentage of manual. Zie hoe u een model traint voor meer informatie. |
percentage |
trainingSplitPercentage |
80 |
Percentage van uw getagde gegevens die moeten worden opgenomen in de trainingsset. Aanbevolen waarde is 80. |
80 |
testingSplitPercentage |
20 |
Percentage van uw getagde gegevens die moeten worden opgenomen in de testset. Aanbevolen waarde is 20. |
20 |
Notitie
De trainingSplitPercentage en testingSplitPercentage zijn alleen vereist als Kind deze is ingesteld percentage op en de som van beide percentages moet gelijk zijn aan 100.
Zodra u uw API-aanvraag hebt verzonden, ontvangt u een 202 antwoord dat aangeeft dat het is gelukt. Pak de operation-location waarde uit in de antwoordheaders. Deze wordt als volgt opgemaakt:
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
U kunt deze URL gebruiken om de status van de trainingstaak op te halen.
De status van de trainingstaak ophalen
Training kan enige tijd in beslag nemen, soms tussen 10 en 30 minuten. U kunt de volgende aanvraag gebruiken om de status van de trainingstaak te peilen totdat deze is voltooid.
Wanneer u een geslaagde trainingsaanvraag verzendt, wordt de volledige aanvraag-URL voor het controleren van de status van de taak (inclusief uw eindpunt, projectnaam en taak-id) opgenomen in de header van operation-location het antwoord.
Gebruik de volgende GET-aanvraag om de status van de trainingsvoortgang van uw model op te halen. Vervang de waarden van de tijdelijke aanduiding hieronder door uw eigen waarden.
Aanvraag-URL
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| Tijdelijke aanduiding | Weergegeven als | Opmerking |
|---|---|---|
{YOUR-ENDPOINT} |
Het eindpunt voor het verifiëren van uw API-aanvraag. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
De naam voor uw project. Deze waarde is hoofdlettergevoelig. | EmailApp |
{JOB-ID} |
De id voor het zoeken naar de trainingsstatus van uw model. | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
De versie van de API die u aanroept. | 2023-04-01 |
Kopteksten
Gebruik de volgende header om uw aanvraag te verifiëren.
| Sleutel | Weergegeven als |
|---|---|
Ocp-Apim-Subscription-Key |
De sleutel voor uw resource. Wordt gebruikt voor het verifiëren van uw API-aanvragen. |
Hoofdtekst van antwoord
Zodra u de aanvraag hebt verzonden, krijgt u het volgende antwoord. Blijf dit eindpunt peilen totdat de statusparameter is gewijzigd in 'geslaagd'.
{
"result": {
"modelLabel": "{MODEL-LABEL}",
"trainingConfigVersion": "{TRAINING-CONFIG-VERSION}",
"trainingMode": "{TRAINING-MODE}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "xxxxx-xxxxx-xxxx-xxxxx-xxxx",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
| Sleutel | Weergegeven als | Opmerking |
|---|---|---|
modelLabel |
De modelnaam | Model1 |
trainingConfigVersion |
De configuratieversie van de training. Standaard wordt de nieuwste versie gebruikt. | 2022-05-01 |
trainingMode |
De geselecteerde trainingsmodus. | standard |
startDateTime |
De tijd waarop de training is gestart | 2022-04-14T10:23:04.2598544Z |
status |
De status van de trainingstaak | running |
estimatedEndDateTime |
Geschatte tijd voor het voltooien van de trainingstaak | 2022-04-14T10:29:38.2598544Z |
jobId |
Uw trainingstaak-id | xxxxx-xxxx-xxxx-xxxx-xxxxxxxxx |
createdDateTime |
Aanmaakdatum en -tijd van trainingstaak | 2022-04-14T10:22:42Z |
lastUpdatedDateTime |
Laatst bijgewerkte datum en tijd voor trainingstaak | 2022-04-14T10:23:45Z |
expirationDateTime |
Verloopdatum en -tijd van trainingstaak | 2022-04-14T10:22:42Z |
Uw model implementeren
Over het algemeen controleert u na het trainen van een model de evaluatiedetails. In deze quickstart implementeert u uw model en roept u de voorspellings-API aan om een query uit te voeren op de resultaten.
Implementatietaak verzenden
Maak een PUT-aanvraag met behulp van de volgende URL, headers en JSON-hoofdtekst om te beginnen met het implementeren van een conversational language understanding-model.
Aanvraag-URL
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}?api-version={API-VERSION}
| Tijdelijke aanduiding | Weergegeven als | Opmerking |
|---|---|---|
{ENDPOINT} |
Het eindpunt voor het verifiëren van uw API-aanvraag. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
De naam voor uw project. Deze waarde is hoofdlettergevoelig. | myProject |
{DEPLOYMENT-NAME} |
De naam voor uw implementatie. Deze waarde is hoofdlettergevoelig. | staging |
{API-VERSION} |
De versie van de API die u aanroept. | 2023-04-01 |
Kopteksten
Gebruik de volgende header om uw aanvraag te verifiëren.
| Sleutel | Weergegeven als |
|---|---|
Ocp-Apim-Subscription-Key |
De sleutel voor uw resource. Wordt gebruikt voor het verifiëren van uw API-aanvragen. |
Aanvraagbody
{
"trainedModelLabel": "{MODEL-NAME}",
}
| Sleutel | Tijdelijke aanduiding | Weergegeven als | Opmerking |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
De modelnaam die wordt toegewezen aan uw implementatie. U kunt alleen getrainde modellen toewijzen. Deze waarde is hoofdlettergevoelig. | myModel |
Zodra u uw API-aanvraag hebt verzonden, ontvangt u een 202 antwoord dat aangeeft dat het is gelukt. Pak de operation-location waarde uit in de antwoordheaders. Deze wordt als volgt opgemaakt:
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
U kunt deze URL gebruiken om de status van de implementatietaak op te halen.
Status van implementatietaak ophalen
Wanneer u een geslaagde implementatieaanvraag verzendt, wordt de volledige aanvraag-URL voor het controleren van de status van de taak (inclusief uw eindpunt, projectnaam en taak-id) opgenomen in de header van operation-location het antwoord.
Gebruik de volgende GET-aanvraag om de status van uw implementatietaak op te halen. Vervang de tijdelijke aanduidingen door uw eigen waarden.
Aanvraag-URL
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| Tijdelijke aanduiding | Weergegeven als | Opmerking |
|---|---|---|
{ENDPOINT} |
Het eindpunt voor het verifiëren van uw API-aanvraag. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
De naam voor uw project. Deze waarde is hoofdlettergevoelig. | myProject |
{DEPLOYMENT-NAME} |
De naam voor uw implementatie. Deze waarde is hoofdlettergevoelig. | staging |
{JOB-ID} |
De id voor het zoeken naar de trainingsstatus van uw model. | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
De versie van de API die u aanroept. | 2023-04-01 |
Kopteksten
Gebruik de volgende header om uw aanvraag te verifiëren.
| Sleutel | Weergegeven als |
|---|---|
Ocp-Apim-Subscription-Key |
De sleutel voor uw resource. Wordt gebruikt voor het verifiëren van uw API-aanvragen. |
Hoofdtekst van antwoord
Zodra u de aanvraag hebt verzonden, krijgt u het volgende antwoord. Blijf dit eindpunt peilen totdat de statusparameter is gewijzigd in 'geslaagd'.
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Querymodel
Nadat uw model is geïmplementeerd, kunt u het gaan gebruiken om voorspellingen te doen via de voorspellings-API.
Zodra de implementatie is voltooid, kunt u beginnen met het uitvoeren van query's op uw geïmplementeerde model voor voorspellingen.
Maak een POST-aanvraag met behulp van de volgende URL, headers en JSON-hoofdtekst om te beginnen met het testen van een model voor het begrijpen van gesprekstaal.
Aanvraag-URL
{ENDPOINT}/language/:analyze-conversations?api-version={API-VERSION}
| Tijdelijke aanduiding | Weergegeven als | Opmerking |
|---|---|---|
{ENDPOINT} |
Het eindpunt voor het verifiëren van uw API-aanvraag. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
De versie van de API die u aanroept. | 2023-04-01 |
Kopteksten
Gebruik de volgende header om uw aanvraag te verifiëren.
| Sleutel | Weergegeven als |
|---|---|
Ocp-Apim-Subscription-Key |
De sleutel voor uw resource. Wordt gebruikt voor het verifiëren van uw API-aanvragen. |
Aanvraagtekst
{
"kind": "Conversation",
"analysisInput": {
"conversationItem": {
"id": "1",
"participantId": "1",
"text": "Text 1"
}
},
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}",
"stringIndexType": "TextElement_V8"
}
}
| Sleutel | Tijdelijke aanduiding | Weergegeven als | Opmerking |
|---|---|---|---|
participantId |
{JOB-NAME} |
"MyJobName |
|
id |
{JOB-NAME} |
"MyJobName |
|
text |
{TEST-UTTERANCE} |
De uiting waaruit u de intentie wilt voorspellen en extraheren uit entiteiten. | "Read Matt's email |
projectName |
{PROJECT-NAME} |
De naam van uw project. Deze waarde is hoofdlettergevoelig. | myProject |
deploymentName |
{DEPLOYMENT-NAME} |
De naam van uw implementatie. Deze waarde is hoofdlettergevoelig. | staging |
Zodra u de aanvraag hebt verzonden, krijgt u het volgende antwoord voor de voorspelling
Hoofdtekst van de reactie
{
"kind": "ConversationResult",
"result": {
"query": "Text1",
"prediction": {
"topIntent": "inten1",
"projectKind": "Conversation",
"intents": [
{
"category": "intent1",
"confidenceScore": 1
},
{
"category": "intent2",
"confidenceScore": 0
},
{
"category": "intent3",
"confidenceScore": 0
}
],
"entities": [
{
"category": "entity1",
"text": "text1",
"offset": 29,
"length": 12,
"confidenceScore": 1
}
]
}
}
}
| Sleutel | Voorbeeldwaarde | Beschrijving |
|---|---|---|
| query | "E-mail van Matt lezen" | de tekst die u hebt verzonden voor een query. |
| topIntent | "Lezen" | De voorspelde intentie met de hoogste betrouwbaarheidsscore. |
| intents | [] | Een lijst met alle intenties die zijn voorspeld voor de querytekst, elk met een betrouwbaarheidsscore. |
| entities | [] | matrix met een lijst met geëxtraheerde entiteiten uit de querytekst. |
API-antwoord voor een gespreksproject
In een gespreksproject krijgt u voorspellingen voor zowel uw intenties als entiteiten die aanwezig zijn in uw project.
- De intenties en entiteiten bevatten een betrouwbaarheidsscore tussen 0,0 en 1.0 die zijn gekoppeld aan hoe zeker het model is om een bepaald element in uw project te voorspellen.
- De meest scorende intentie bevindt zich in een eigen parameter.
- Alleen voorspelde entiteiten worden weergegeven in uw antwoord.
- Entiteiten geven aan:
- De tekst van de entiteit die is geëxtraheerd
- De beginlocatie die wordt aangegeven door een offsetwaarde
- De lengte van de entiteitstekst die wordt aangeduid met een lengtewaarde.
Resources opschonen
Wanneer u uw project niet meer nodig hebt, kunt u uw project verwijderen met behulp van de API's.
Maak een DELETE-aanvraag met behulp van de volgende URL, headers en JSON-hoofdtekst om een conversationele taalkennisproject te verwijderen.
Aanvraag-URL
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}?api-version={API-VERSION}
| Tijdelijke aanduiding | Weergegeven als | Opmerking |
|---|---|---|
{ENDPOINT} |
Het eindpunt voor het verifiëren van uw API-aanvraag. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
De naam voor uw project. Deze waarde is hoofdlettergevoelig. | myProject |
{API-VERSION} |
De versie van de API die u aanroept. | 2023-04-01 |
Kopteksten
Gebruik de volgende header om uw aanvraag te verifiëren.
| Sleutel | Weergegeven als |
|---|---|
Ocp-Apim-Subscription-Key |
De sleutel voor uw resource. Wordt gebruikt voor het verifiëren van uw API-aanvragen. |
Zodra u uw API-aanvraag hebt verzonden, ontvangt u een 202 antwoord dat aangeeft dat uw project is verwijderd.