Quickstart: aangepaste Text Analytics voor status
Gebruik dit artikel om aan de slag te gaan met het maken van een aangepast Text Analytics voor statusproject, waar u aangepaste modellen kunt trainen boven op Text Analytics voor status voor aangepaste entiteitsherkenning. Een model is software voor kunstmatige intelligentie die is getraind om een bepaalde taak uit te voeren. Voor dit systeem worden de modellen gerelateerde entiteiten uit de gezondheidszorg geëxtraheerd en getraind door te leren van gelabelde gegevens.
In dit artikel gebruiken we Language Studio om de belangrijkste concepten van aangepaste Text Analytics voor de status te demonstreren. Als voorbeeld bouwen we een aangepast Text Analytics voor gezondheidsmodel om de faciliteit of behandelingslocatie te extraheren uit korte ontladingsnotities.
Vereisten
- Azure-abonnement: Krijg een gratis abonnement
Een nieuwe Azure AI-taalresource en een Azure-opslagaccount maken
Voordat u aangepaste Text Analytics voor de status kunt gebruiken, moet u een Azure AI Language-resource maken, waarmee u de referenties krijgt die u nodig hebt om een project te maken en een model te trainen. U hebt ook een Azure-opslagaccount nodig, waar u uw gegevensset kunt uploaden die wordt gebruikt om uw model te bouwen.
Belangrijk
Om snel aan de slag te gaan, raden we u aan om een nieuwe Azure AI-taalresource te maken met behulp van de stappen in dit artikel. Met behulp van de stappen in dit artikel kunt u tegelijkertijd de taalresource en het opslagaccount maken. Dit is eenvoudiger dan later.
Als u een bestaande resource hebt die u wilt gebruiken, moet u deze verbinden met het opslagaccount. Zie de richtlijnen voor het gebruik van een bestaande resource voor meer informatie.
Een nieuwe resource maken vanuit Azure Portal
Meld u aan bij Azure Portal om een nieuwe Azure AI Language-resource te maken.
Selecteer in het venster dat wordt weergegeven aangepaste tekstclassificatie en aangepaste entiteitsherkenning in de aangepaste functies. Selecteer Doorgaan om uw resource onder aan het scherm te maken.

Maak een taalresource met de volgende details.
Name Beschrijving Abonnement Uw Azure-abonnement. Resourcegroep Een resourcegroep die uw resource bevat. U kunt een bestaande gebruiken of een nieuwe maken. Regio De regio voor uw taalresource. Bijvoorbeeld 'VS - west 2'. Naam Een naam voor uw resource. Prijscategorie De prijscategorie voor uw taalresource. U kunt de gratis laag (F0) gebruiken om de service uit te proberen. Notitie
Als u een bericht krijgt met de tekst 'uw aanmeldingsaccount is geen eigenaar van de resourcegroep van het geselecteerde opslagaccount', moet voor uw account een eigenaarsrol zijn toegewezen aan de resourcegroep voordat u een taalresource kunt maken. Neem contact op met de eigenaar van uw Azure-abonnement voor hulp.
Selecteer in de sectie Aangepaste tekstclassificatie en aangepaste entiteitsherkenning een bestaand opslagaccount of selecteer Nieuw opslagaccount. Deze waarden zijn om u te helpen aan de slag te gaan en niet noodzakelijkerwijs de waarden van het opslagaccount die u wilt gebruiken in productieomgevingen. Om latentie te voorkomen tijdens het bouwen van uw project, maakt u verbinding met opslagaccounts in dezelfde regio als uw taalresource.
Waarde van opslagaccount Aanbevolen waarde Naam van het opslagaccount Elke naam Storage account type Standaard - LRS Zorg ervoor dat de verantwoordelijke AI-kennisgeving is ingeschakeld. Selecteer Beoordelen en maken onder aan de pagina en selecteer Vervolgens Maken.

Voorbeeldgegevens uploaden naar blobcontainer
Nadat u een Azure-opslagaccount hebt gemaakt en dit hebt verbonden met uw taalresource, moet u de documenten van de voorbeeldgegevensset uploaden naar de hoofdmap van uw container. Deze documenten worden later gebruikt om uw model te trainen.
Download de voorbeeldgegevensset van GitHub.
Open het ZIP-bestand en pak de map met de documenten uit.
Navigeer in Azure Portal naar het opslagaccount dat u hebt gemaakt en selecteer het.
Selecteer containers in het linkermenu in uw opslagaccount, onder Gegevensopslag. Selecteer + Container op het scherm dat wordt weergegeven. Geef de container de naam voorbeeldgegevens en laat het standaardniveau openbare toegang staan.
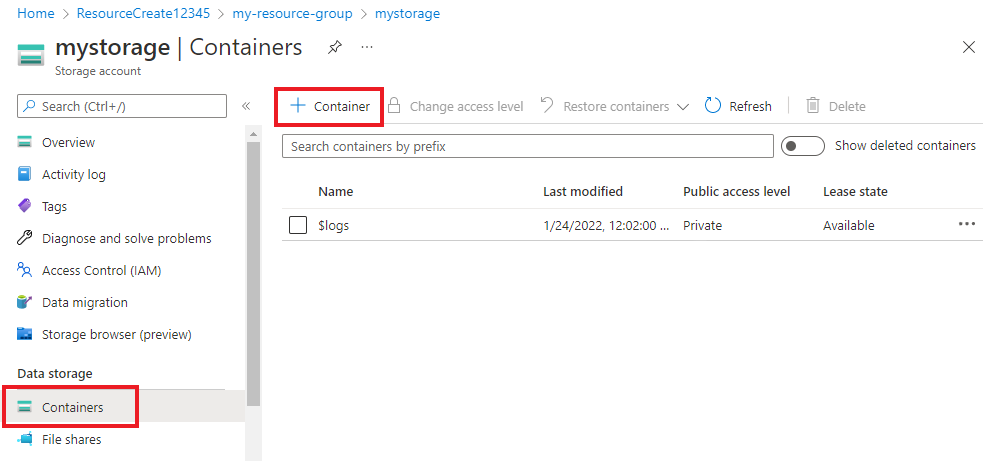
Nadat de container is gemaakt, selecteert u deze. Selecteer vervolgens de knop Uploaden om de
.txtbestanden te selecteren die.jsonu eerder hebt gedownload.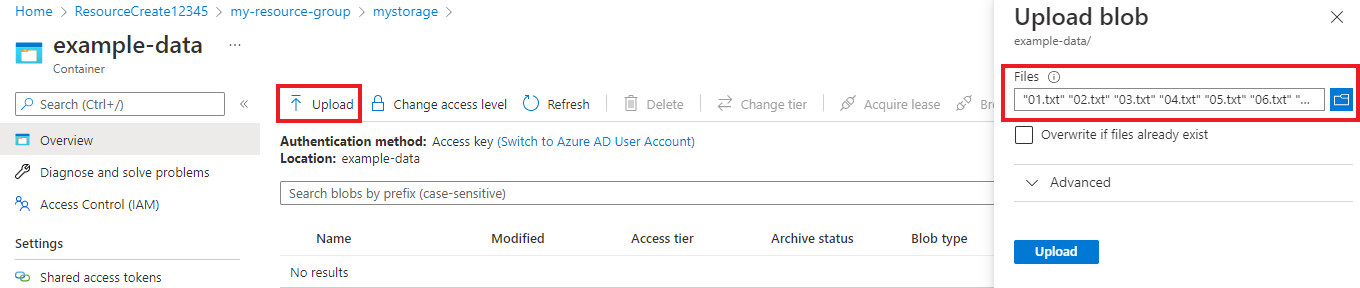


De opgegeven voorbeeldgegevensset bevat 12 klinische notities. Elke klinische noot omvat verschillende medische entiteiten en de behandelingslocatie. We gebruiken de vooraf gemaakte entiteiten om de medische entiteiten te extraheren en het aangepaste model te trainen om de behandellocatie te extraheren met behulp van de geleerde onderdelen van de entiteit en om onderdelen weer te geven.
Een aangepast Text Analytics-project voor statusproject maken
Zodra uw resource en opslagaccount zijn geconfigureerd, maakt u een nieuw aangepast Text Analytics voor het statusproject. Een project is een werkgebied voor het bouwen van uw aangepaste ML-modellen op basis van uw gegevens. Uw project kan alleen worden geopend door u en anderen die toegang hebben tot de taalresource die wordt gebruikt.
Meld u aan bij Language Studio. Er wordt een venster weergegeven waarmee u uw abonnement en taalresource kunt selecteren. Selecteer de taalresource die u in de bovenstaande stap hebt gemaakt.
Selecteer in de sectie Informatie extraheren van Language Studio de optie Custom Text Analytics voor de status.
Selecteer Nieuw project maken in het bovenste menu op de pagina Projecten. Door een project te maken, kunt u gegevens labelen, trainen, evalueren, verbeteren en implementeren.

Voer de projectgegevens in, inclusief een naam, beschrijving en de taal van de bestanden in uw project. Als u de voorbeeldgegevensset gebruikt, selecteert u Engels. U kunt de naam van uw project later niet meer wijzigen. Selecteer Volgende
Tip
Uw gegevensset hoeft zich niet volledig in dezelfde taal te bevinden. U kunt meerdere documenten hebben, elk met verschillende ondersteunde talen. Als uw gegevensset documenten van verschillende talen bevat of als u tijdens runtime tekst uit verschillende talen verwacht, schakelt u de optie voor meertalige gegevenssets in wanneer u de basisgegevens voor uw project invoert. Deze optie kan later worden ingeschakeld op de pagina Project-instellingen .
Nadat u Nieuw project maken hebt geselecteerd, wordt er een venster weergegeven waarmee u verbinding kunt maken met uw opslagaccount. Als u al een opslagaccount hebt verbonden, ziet u dat de opslagaccount is verbonden. Als dat niet het is, kiest u uw opslagaccount in de vervolgkeuzelijst die wordt weergegeven en selecteert u Verbinding maken opslagaccount. Hiermee worden de vereiste rollen voor uw opslagaccount ingesteld. Met deze stap wordt mogelijk een fout geretourneerd als u niet als eigenaar van het opslagaccount bent toegewezen.
Notitie
- U hoeft deze stap slechts één keer uit te voeren voor elke nieuwe resource die u gebruikt.
- Dit proces kan niet ongedaan worden gemaakt als u een opslagaccount verbindt met uw taalresource, kunt u het later niet loskoppelen.
- U kunt uw taalresource alleen verbinden met één opslagaccount.

Selecteer de container waar u uw gegevensset hebt geüpload.
Als u al gelabelde gegevens hebt, moet u ervoor zorgen dat deze de ondersteunde indeling volgt en Ja selecteert , zijn mijn bestanden al gelabeld en heb ik het JSON-labelsbestand opgemaakt en selecteer het labelbestand in de vervolgkeuzelijst. Selecteer Volgende. Als u de gegevensset uit de quickstart gebruikt, hoeft u de opmaak van het JSON-labelsbestand niet te controleren.
Controleer de gegevens die u hebt ingevoerd en selecteer Project maken.


Uw model trainen
Nadat u een project hebt gemaakt, begint u met het labelen van de documenten in de container die is verbonden met uw project. Voor deze quickstart hebt u een voorbeeldgegevensset met tags geïmporteerd en uw project geïnitialiseerd met het JSON-voorbeeldlabelbestand, zodat u geen extra labels hoeft toe te voegen.
Ga als volgende te werk om uw model te trainen vanuit Language Studio:
Selecteer Trainingstaken in het menu aan de linkerkant.
Selecteer Een trainingstaak starten in het bovenste menu.
Selecteer Een nieuw model trainen en typ de naam van het model in het tekstvak. U kunt ook een bestaand model overschrijven door deze optie te selecteren en het model te kiezen dat u wilt overschrijven in de vervolgkeuzelijst. Het overschrijven van een getraind model kan niet ongedaan worden gemaakt, maar dit heeft geen invloed op uw geïmplementeerde modellen totdat u het nieuwe model implementeert.

Selecteer de methode voor het splitsen van gegevens. U kunt ervoor kiezen om de testset automatisch te splitsen op basis van trainingsgegevens , waarbij het systeem uw gelabelde gegevens splitst tussen de trainings- en testsets, volgens de opgegeven percentages. U kunt ook een handmatige splitsing van trainings- en testgegevens gebruiken. Deze optie is alleen ingeschakeld als u documenten hebt toegevoegd aan uw testset. Zie gegevenslabels en hoe u een model traint voor informatie over het splitsen van gegevens.
Selecteer de knop Trainen .
Als u de id van de trainingstaak in de lijst selecteert, wordt er een zijvenster weergegeven waarin u de voortgang van de training, de taakstatus en andere details voor deze taak kunt controleren.
Notitie
- Alleen voltooide trainingstaken genereren modellen.
- Training kan enige tijd duren tussen een paar minuten en enkele uren op basis van de grootte van uw gelabelde gegevens.
- U kunt slechts één trainingstaak tegelijk uitvoeren. U kunt pas met een andere trainingstaak binnen hetzelfde project beginnen als de actieve taak is voltooid.

Uw model implementeren
Over het algemeen controleert u na het trainen van een model de evaluatiedetails en voert u indien nodig verbeteringen aan. In deze quickstart implementeert u uw model en stelt u het model beschikbaar om te proberen in Language Studio of kunt u de voorspellings-API aanroepen.
Uw model implementeren vanuit Language Studio:
Selecteer Een model implementeren in het menu aan de linkerkant.
Selecteer Implementatie toevoegen om een nieuwe implementatietaak te starten.
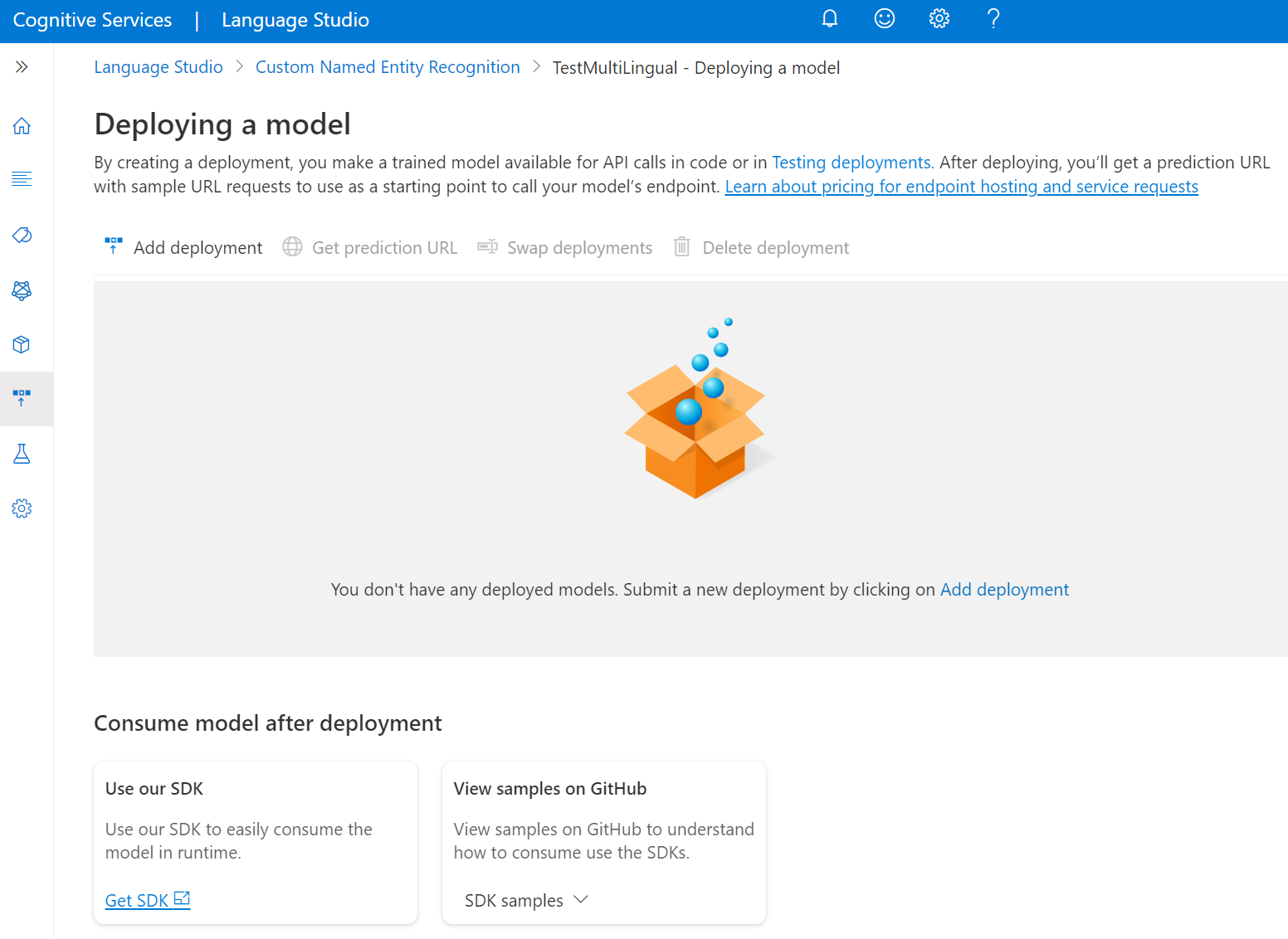
Selecteer Nieuwe implementatie maken om een nieuwe implementatie te maken en wijs een getraind model toe vanuit de vervolgkeuzelijst hieronder. U kunt een bestaande implementatie ook overschrijven door deze optie te selecteren en het getrainde model te selecteren dat u eraan wilt toewijzen in de vervolgkeuzelijst hieronder.
Notitie
Het overschrijven van een bestaande implementatie vereist geen wijzigingen in uw voorspellings-API-aanroep , maar de resultaten die u krijgt, zijn gebaseerd op het zojuist toegewezen model.

Selecteer Implementeren om de implementatietaak te starten.
Nadat de implementatie is voltooid, wordt er een vervaldatum weergegeven naast de implementatie. Het verloop van de implementatie is wanneer uw geïmplementeerde model niet beschikbaar is om te worden gebruikt voor voorspelling. Dit gebeurt meestal twaalf maanden nadat een trainingsconfiguratie is verlopen.


Uw model testen
Nadat uw model is geïmplementeerd, kunt u het gaan gebruiken om entiteiten uit uw tekst te extraheren via de voorspellings-API. Voor deze quickstart gebruikt u Language Studio om de aangepaste Text Analytics te verzenden voor de statusvoorspellingstaak en de resultaten te visualiseren. In de voorbeeldgegevensset die u eerder hebt gedownload, vindt u enkele testdocumenten die u in deze stap kunt gebruiken.
Uw geïmplementeerde modellen testen vanuit Language Studio:
Selecteer Implementaties testen in het menu aan de linkerkant.
Selecteer de implementatie die u wilt testen. U kunt alleen modellen testen die zijn toegewezen aan implementaties.
Selecteer de implementatie die u wilt opvragen/testen in de vervolgkeuzelijst.
U kunt de tekst invoeren die u wilt indienen bij de aanvraag of een
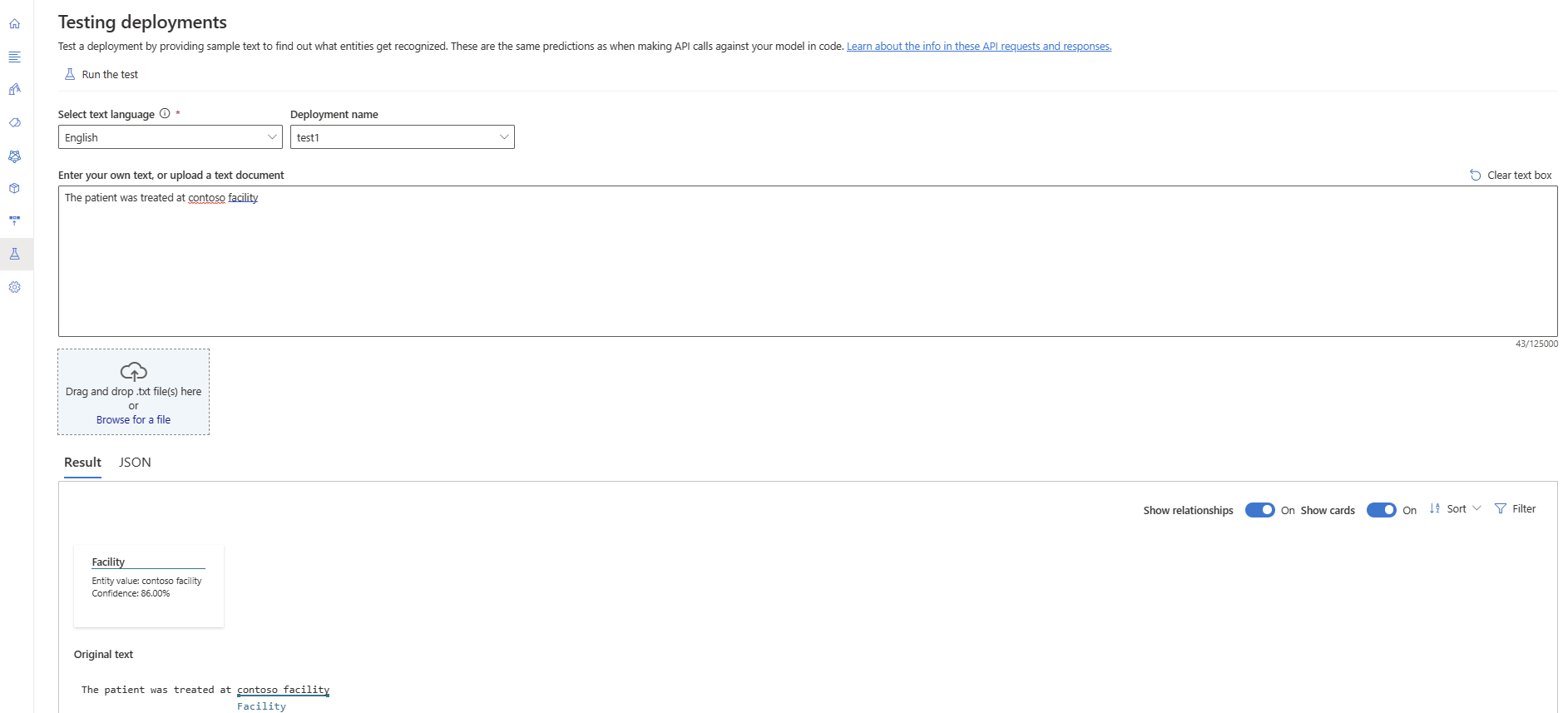
.txtbestand uploaden dat u wilt gebruiken.Selecteer De test uitvoeren in het bovenste menu.
Op het tabblad Resultaat ziet u de geëxtraheerde entiteiten uit uw tekst en de bijbehorende typen. U kunt het JSON-antwoord ook bekijken op het tabblad JSON .

Resources opschonen
Wanneer u uw project niet meer nodig hebt, kunt u uw project verwijderen met Behulp van Language Studio.
- Selecteer de taalservicefunctie die u boven aan de pagina gebruikt.
- Selecteer het project dat u wilt verwijderen
- Selecteer Verwijderen in het hoofdmenu.
Vereisten
- Azure-abonnement: Krijg een gratis abonnement
Een nieuwe Azure AI-taalresource en een Azure-opslagaccount maken
Voordat u aangepaste Text Analytics voor de status kunt gebruiken, moet u een Azure AI Language-resource maken, waarmee u de referenties krijgt die u nodig hebt om een project te maken en een model te trainen. U hebt ook een Azure-opslagaccount nodig, waar u uw gegevensset kunt uploaden die wordt gebruikt bij het bouwen van uw model.
Belangrijk
Om snel aan de slag te gaan, raden we u aan om een nieuwe Azure AI-taalresource te maken met behulp van de stappen in dit artikel, waarmee u de taalresource kunt maken en/of tegelijkertijd een opslagaccount kunt maken en/of verbinden, wat eenvoudiger is dan later.
Als u een bestaande resource hebt die u wilt gebruiken, moet u deze verbinden met het opslagaccount. Zie Project maken voor meer informatie.
Een nieuwe resource maken vanuit Azure Portal
Meld u aan bij Azure Portal om een nieuwe Azure AI Language-resource te maken.
Selecteer in het venster dat wordt weergegeven aangepaste tekstclassificatie en aangepaste entiteitsherkenning in de aangepaste functies. Selecteer Doorgaan om uw resource onder aan het scherm te maken.
Maak een taalresource met de volgende details.
Name Beschrijving Abonnement Uw Azure-abonnement. Resourcegroep Een resourcegroep die uw resource bevat. U kunt een bestaande gebruiken of een nieuwe maken. Regio De regio voor uw taalresource. Bijvoorbeeld 'VS - west 2'. Naam Een naam voor uw resource. Prijscategorie De prijscategorie voor uw taalresource. U kunt de gratis laag (F0) gebruiken om de service uit te proberen. Notitie
Als u een bericht krijgt met de tekst 'uw aanmeldingsaccount is geen eigenaar van de resourcegroep van het geselecteerde opslagaccount', moet voor uw account een eigenaarsrol zijn toegewezen aan de resourcegroep voordat u een taalresource kunt maken. Neem contact op met de eigenaar van uw Azure-abonnement voor hulp.
Selecteer in de sectie Aangepaste tekstclassificatie en aangepaste entiteitsherkenning een bestaand opslagaccount of selecteer Nieuw opslagaccount. Deze waarden zijn om u te helpen aan de slag te gaan en niet noodzakelijkerwijs de waarden van het opslagaccount die u wilt gebruiken in productieomgevingen. Om latentie te voorkomen tijdens het bouwen van uw project, maakt u verbinding met opslagaccounts in dezelfde regio als uw taalresource.
Waarde van opslagaccount Aanbevolen waarde Naam van het opslagaccount Elke naam Storage account type Standaard - LRS Zorg ervoor dat de verantwoordelijke AI-kennisgeving is ingeschakeld. Selecteer Beoordelen en maken onder aan de pagina en selecteer Vervolgens Maken.
Voorbeeldgegevens uploaden naar blobcontainer
Nadat u een Azure-opslagaccount hebt gemaakt en dit hebt verbonden met uw taalresource, moet u de documenten van de voorbeeldgegevensset uploaden naar de hoofdmap van uw container. Deze documenten worden later gebruikt om uw model te trainen.
Download de voorbeeldgegevensset van GitHub.
Open het ZIP-bestand en pak de map met de documenten uit.
Navigeer in Azure Portal naar het opslagaccount dat u hebt gemaakt en selecteer het.
Selecteer containers in het linkermenu in uw opslagaccount, onder Gegevensopslag. Selecteer + Container op het scherm dat wordt weergegeven. Geef de container de naam voorbeeldgegevens en laat het standaardniveau openbare toegang staan.
Nadat de container is gemaakt, selecteert u deze. Selecteer vervolgens de knop Uploaden om de
.txtbestanden te selecteren die.jsonu eerder hebt gedownload.
De opgegeven voorbeeldgegevensset bevat 12 klinische notities. Elke klinische noot omvat verschillende medische entiteiten en de behandelingslocatie. We gebruiken de vooraf gemaakte entiteiten om de medische entiteiten te extraheren en het aangepaste model te trainen om de behandellocatie te extraheren met behulp van de geleerde onderdelen van de entiteit en om onderdelen weer te geven.
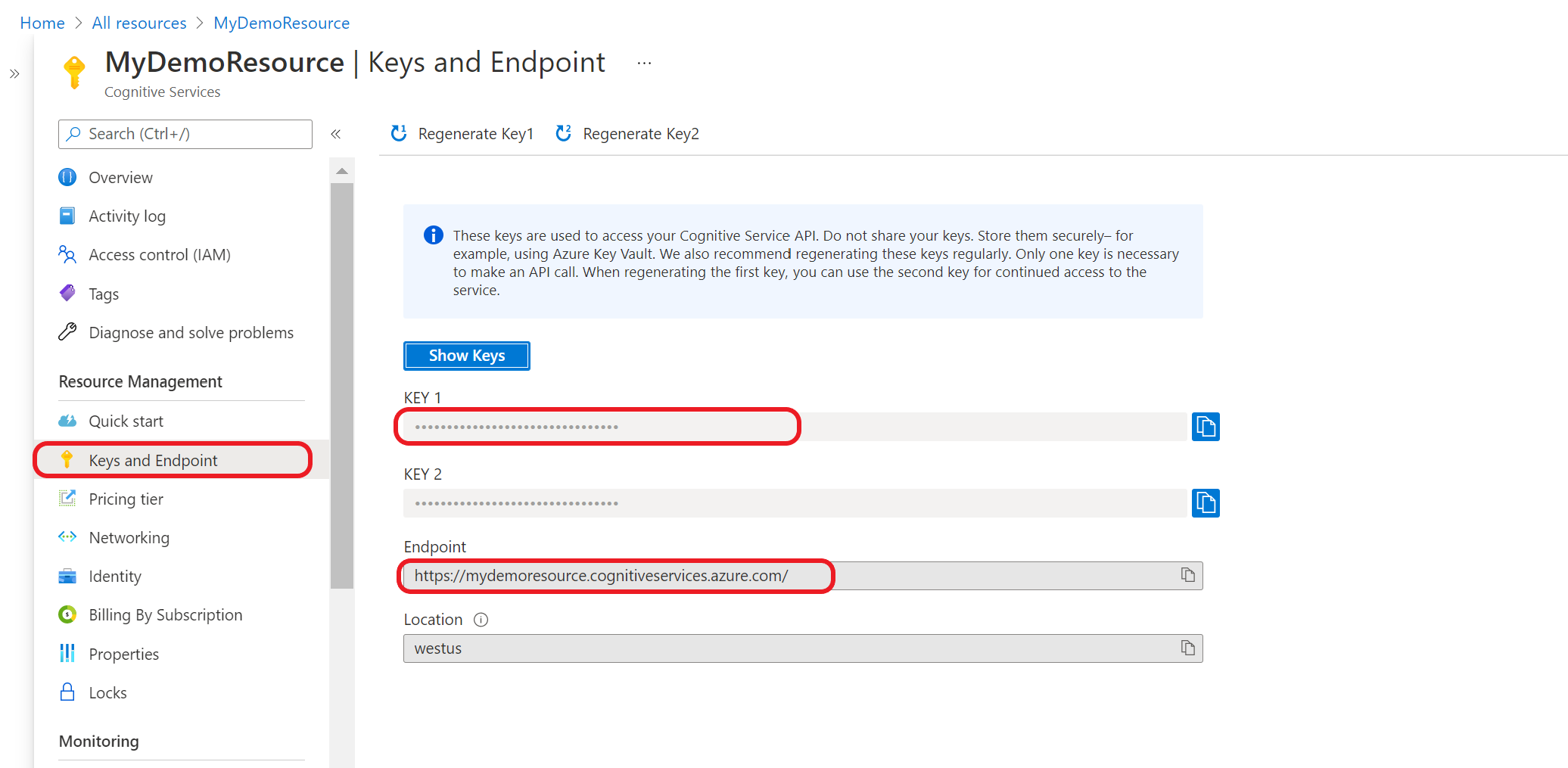
Uw resourcesleutels en eindpunt ophalen
Ga naar de overzichtspagina van uw resource in Azure Portal
Selecteer sleutels en eindpunt in het menu aan de linkerkant. U gebruikt het eindpunt en de sleutel voor de API-aanvragen

Een aangepast Text Analytics-project voor statusproject maken
Zodra uw resource en opslagaccount zijn geconfigureerd, maakt u een nieuw aangepast Text Analytics voor het statusproject. Een project is een werkgebied voor het bouwen van uw aangepaste ML-modellen op basis van uw gegevens. Uw project kan alleen worden geopend door u en anderen die toegang hebben tot de taalresource die wordt gebruikt.
Gebruik het labelsbestand dat u in de vorige stap hebt gedownload uit de voorbeeldgegevens en voeg het toe aan de hoofdtekst van de volgende aanvraag.
Importprojecttaak activeren
Verzend een POST-aanvraag met behulp van de volgende URL, headers en JSON-hoofdtekst om het labelbestand te importeren. Zorg ervoor dat het labelsbestand de geaccepteerde indeling volgt.
Als er al een project met dezelfde naam bestaat, worden de gegevens van dat project vervangen.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
| Tijdelijke aanduiding | Weergegeven als | Opmerking |
|---|---|---|
{ENDPOINT} |
Het eindpunt voor het verifiëren van uw API-aanvraag. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
De naam voor uw project. Deze waarde is hoofdlettergevoelig. | myProject |
{API-VERSION} |
De versie van de API die u aanroept. De waarde waarnaar hier wordt verwezen, is voor de nieuwste versie die is uitgebracht. Zie de levenscyclus van het model voor meer informatie over andere beschikbare API-versies. | 2022-05-01 |
Headers
Gebruik de volgende header om uw aanvraag te verifiëren.
| Sleutel | Weergegeven als |
|---|---|
Ocp-Apim-Subscription-Key |
De sleutel voor uw resource. Wordt gebruikt voor het verifiëren van uw API-aanvragen. |
Tekst
Gebruik de volgende JSON in uw aanvraag. Vervang de waarden van de tijdelijke aanduiding hieronder door uw eigen waarden.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"projectKind": "CustomHealthcare",
"description": "Trying out custom Text Analytics for health",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"storageInputContainerName": "{CONTAINER-NAME}",
"settings": {}
},
"assets": {
"projectKind": "CustomHealthcare",
"entities": [
{
"category": "Entity1",
"compositionSetting": "{COMPOSITION-SETTING}",
"list": {
"sublists": [
{
"listKey": "One",
"synonyms": [
{
"language": "en",
"values": [
"EntityNumberOne",
"FirstEntity"
]
}
]
}
]
}
},
{
"category": "Entity2"
},
{
"category": "MedicationName",
"list": {
"sublists": [
{
"listKey": "research drugs",
"synonyms": [
{
"language": "en",
"values": [
"rdrug a",
"rdrug b"
]
}
]
}
]
}
"prebuilts": "MedicationName"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"entities": [
{
"regionOffset": 0,
"regionLength": 500,
"labels": [
{
"category": "Entity1",
"offset": 25,
"length": 10
},
{
"category": "Entity2",
"offset": 120,
"length": 8
}
]
}
]
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"entities": [
{
"regionOffset": 0,
"regionLength": 100,
"labels": [
{
"category": "Entity2",
"offset": 20,
"length": 5
}
]
}
]
}
]
}
}
| Key | Tijdelijke aanduiding | Weergegeven als | Opmerking |
|---|---|---|---|
multilingual |
true |
Een Booleaanse waarde waarmee u documenten in meerdere talen in uw gegevensset kunt hebben en wanneer uw model wordt geïmplementeerd, kunt u een query uitvoeren op het model in elke ondersteunde taal (niet noodzakelijkerwijs opgenomen in uw trainingsdocumenten). Zie taalondersteuning voor meer informatie over meertalige ondersteuning. | true |
projectName |
{PROJECT-NAME} |
Projectnaam | myproject |
storageInputContainerName |
{CONTAINER-NAME} |
Containernaam | mycontainer |
entities |
Matrix met alle entiteitstypen die u in het project hebt. Dit zijn de entiteitstypen die uit uw documenten worden geëxtraheerd. | ||
category |
De naam van het entiteitstype, dat door de gebruiker kan worden gedefinieerd voor nieuwe entiteitsdefinities of vooraf gedefinieerd voor vooraf gedefinieerde entiteiten. | ||
compositionSetting |
{COMPOSITION-SETTING} |
Regel waarmee wordt gedefinieerd hoe u meerdere onderdelen in uw entiteit beheert. Opties zijn combineComponents of separateComponents. |
combineComponents |
list |
Matrix met alle sublijsten die u in het project voor een specifieke entiteit hebt. Lijsten kunnen worden toegevoegd aan vooraf gedefinieerde entiteiten of nieuwe entiteiten met geleerde onderdelen. | ||
sublists |
[] |
Matrix met sublijsten. Elke sublijst is een sleutel en de bijbehorende waarden. | [] |
listKey |
One |
Een genormaliseerde waarde voor de lijst met synoniemen waaraan moet worden toegewezen in voorspelling. | One |
synonyms |
[] |
Matrix met alle synoniemen | Synoniem |
language |
{LANGUAGE-CODE} |
Een tekenreeks die de taalcode voor het synoniem in uw sublijst opgeeft. Als uw project een meertalige project is en u uw lijst met synoniemen voor alle talen in uw project wilt ondersteunen, moet u uw synoniemen expliciet toevoegen aan elke taal. Zie Taalondersteuning voor meer informatie over ondersteunde taalcodes. | en |
values |
"EntityNumberone", "FirstEntity" |
Een lijst met door komma's gescheiden tekenreeksen die exact overeenkomen voor extractie en toewijzing aan de lijstsleutel. | "EntityNumberone", "FirstEntity" |
prebuilts |
MedicationName |
De naam van het vooraf gemaakte onderdeel dat de vooraf gedefinieerde entiteit invult. Vooraf gemaakte entiteiten worden standaard automatisch in uw project geladen, maar u kunt ze uitbreiden met lijstonderdelen in uw labelsbestand. | MedicationName |
documents |
Matrix met alle documenten in uw project en een lijst met de entiteiten die in elk document zijn gelabeld. | [] | |
location |
{DOCUMENT-NAME} |
De locatie van de documenten in de opslagcontainer. Omdat alle documenten zich in de hoofdmap van de container bevinden, moet dit de naam van het document zijn. | doc1.txt |
dataset |
{DATASET} |
De testset waarnaar dit bestand gaat wanneer het wordt gesplitst vóór de training. Mogelijke waarden voor dit veld zijn Train en Test. |
Train |
regionOffset |
De inclusieve tekenpositie van het begin van de tekst. | 0 |
|
regionLength |
De lengte van het begrenzingsvak in termen van UTF16-tekens. Training houdt alleen rekening met de gegevens in deze regio. | 500 |
|
category |
Het type entiteit dat is gekoppeld aan de opgegeven reeks tekst. | Entity1 |
|
offset |
De beginpositie voor de entiteitstekst. | 25 |
|
length |
De lengte van de entiteit in termen van UTF16-tekens. | 20 |
|
language |
{LANGUAGE-CODE} |
Een tekenreeks die de taalcode opgeeft voor het document dat in uw project wordt gebruikt. Als uw project een meertalige project is, kiest u de taalcode van het merendeel van de documenten. Zie Taalondersteuning voor meer informatie over ondersteunde taalcodes. | en |
Zodra u uw API-aanvraag hebt verzonden, ontvangt u een 202 antwoord dat aangeeft dat de taak correct is verzonden. Pak de operation-location waarde uit in de antwoordheaders. Deze wordt als volgt opgemaakt:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} wordt gebruikt om uw aanvraag te identificeren, omdat deze bewerking asynchroon is. U gebruikt deze URL om de status van de importtaak op te halen.
Mogelijke foutscenario's voor deze aanvraag:
- De geselecteerde resource beschikt niet over de juiste machtigingen voor het opslagaccount.
- De
storageInputContainerNameopgegeven bestaat niet. - Ongeldige taalcode wordt gebruikt of als het taalcodetype geen tekenreeks is.
multilingualwaarde is een tekenreeks en geen booleaanse waarde.
Status van importtaak ophalen
Gebruik de volgende GET-aanvraag om de status van het importeren van uw project op te halen. Vervang de waarden van de tijdelijke aanduiding hieronder door uw eigen waarden.
Aanvraag-URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| Tijdelijke aanduiding | Weergegeven als | Opmerking |
|---|---|---|
{ENDPOINT} |
Het eindpunt voor het verifiëren van uw API-aanvraag. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
De naam van uw project. Deze waarde is hoofdlettergevoelig. | myProject |
{JOB-ID} |
De id voor het zoeken naar de trainingsstatus van uw model. Deze waarde bevindt zich in de location headerwaarde die u in de vorige stap hebt ontvangen. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
De versie van de API die u aanroept. De waarde waarnaar hier wordt verwezen, is voor de nieuwste versie die is uitgebracht. Zie de levenscyclus van het model voor meer informatie over andere beschikbare API-versies. | 2022-05-01 |
Headers
Gebruik de volgende header om uw aanvraag te verifiëren.
| Sleutel | Weergegeven als |
|---|---|
Ocp-Apim-Subscription-Key |
De sleutel voor uw resource. Wordt gebruikt voor het verifiëren van uw API-aanvragen. |
Uw model trainen
Nadat u een project hebt gemaakt, begint u met het labelen van de documenten in de container die is verbonden met uw project. Voor deze quickstart hebt u een voorbeeldgegevensset met tags geïmporteerd en uw project geïnitialiseerd met het JSON-voorbeeldtagbestand.
Trainingstaak starten
Nadat uw project is geïmporteerd, kunt u beginnen met het trainen van uw model.
Dien een POST-aanvraag in met behulp van de volgende URL, headers en JSON-hoofdtekst om een trainingstaak te verzenden. Vervang de tijdelijke aanduidingen door uw eigen waarden.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| Tijdelijke aanduiding | Weergegeven als | Opmerking |
|---|---|---|
{ENDPOINT} |
Het eindpunt voor het verifiëren van uw API-aanvraag. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
De naam van uw project. Deze waarde is hoofdlettergevoelig. | myProject |
{API-VERSION} |
De versie van de API die u aanroept. De waarde waarnaar hier wordt verwezen, is voor de nieuwste versie die is uitgebracht. Zie de levenscyclus van het model voor meer informatie over andere beschikbare API-versies. | 2022-05-01 |
Headers
Gebruik de volgende header om uw aanvraag te verifiëren.
| Sleutel | Weergegeven als |
|---|---|
Ocp-Apim-Subscription-Key |
De sleutel voor uw resource. Wordt gebruikt voor het verifiëren van uw API-aanvragen. |
Aanvraagtekst
Gebruik de volgende JSON in de hoofdtekst van uw aanvraag. Het model krijgt het model zodra de {MODEL-NAME} training is voltooid. Alleen succesvolle trainingstaken produceren modellen.
{
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"trainingSplitPercentage": 80,
"testingSplitPercentage": 20
}
}
| Key | Tijdelijke aanduiding | Weergegeven als | Opmerking |
|---|---|---|---|
| modelLabel | {MODEL-NAME} |
De modelnaam die is toegewezen aan uw model nadat deze is getraind. | myModel |
| trainingConfigVersion | {CONFIG-VERSION} |
Dit is de modelversie die wordt gebruikt om het model te trainen. | 2022-05-01 |
| evaluationOptions | Optie voor het splitsen van uw gegevens in trainings- en testsets. | {} |
|
| soort | percentage |
Splitsmethoden. Mogelijke waarden zijn percentage en manual. Zie Hoe u een model traint voor meer informatie. |
percentage |
| trainingSplitPercentage | 80 |
Percentage van uw getagde gegevens die moeten worden opgenomen in de trainingsset. Aanbevolen waarde is 80. |
80 |
| testingSplitPercentage | 20 |
Percentage van uw getagde gegevens die moeten worden opgenomen in de testset. Aanbevolen waarde is 20. |
20 |
Notitie
De trainingSplitPercentage en testingSplitPercentage zijn alleen vereist als Kind deze is ingesteld percentage op en de som van beide percentages moet gelijk zijn aan 100.
Zodra u uw API-aanvraag hebt verzonden, ontvangt u een 202 antwoord dat aangeeft dat de taak correct is verzonden. Pak de location waarde uit in de antwoordheaders. De indeling is als volgt:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} wordt gebruikt om uw aanvraag te identificeren, omdat deze bewerking asynchroon is. U kunt deze URL gebruiken om de trainingsstatus op te halen.
Trainingstaakstatus ophalen
Training kan enige tijd duren tussen 10 en 30 minuten voor deze voorbeeldgegevensset. U kunt de volgende aanvraag gebruiken om de status van de trainingstaak te peilen totdat deze is voltooid.
Gebruik de volgende GET-aanvraag om de status van de trainingsvoortgang van uw model op te halen. Vervang de waarden van de tijdelijke aanduiding hieronder door uw eigen waarden.
Aanvraag-URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| Tijdelijke aanduiding | Weergegeven als | Opmerking |
|---|---|---|
{ENDPOINT} |
Het eindpunt voor het verifiëren van uw API-aanvraag. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
De naam van uw project. Deze waarde is hoofdlettergevoelig. | myProject |
{JOB-ID} |
De id voor het zoeken naar de trainingsstatus van uw model. Deze waarde bevindt zich in de location headerwaarde die u in de vorige stap hebt ontvangen. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
De versie van de API die u aanroept. De waarde waarnaar hier wordt verwezen, is voor de nieuwste versie die is uitgebracht. Zie de levenscyclus van het model voor meer informatie over andere beschikbare API-versies. | 2022-05-01 |
Headers
Gebruik de volgende header om uw aanvraag te verifiëren.
| Sleutel | Weergegeven als |
|---|---|
Ocp-Apim-Subscription-Key |
De sleutel voor uw resource. Wordt gebruikt voor het verifiëren van uw API-aanvragen. |
Hoofdtekst van antwoord
Nadat u de aanvraag hebt verzonden, krijgt u het volgende antwoord.
{
"result": {
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "{JOB-ID}",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
Uw model implementeren
Over het algemeen controleert u na het trainen van een model de evaluatiedetails en voert u indien nodig verbeteringen aan. In deze quickstart implementeert u uw model en stelt u het model beschikbaar om te proberen in Language Studio of kunt u de voorspellings-API aanroepen.
Implementatietaak starten
Dien een PUT-aanvraag in met behulp van de volgende URL, headers en JSON-hoofdtekst om een implementatietaak te verzenden. Vervang de waarden van de tijdelijke aanduiding hieronder door uw eigen waarden.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/deployments/{deploymentName}?api-version={API-VERSION}
| Tijdelijke aanduiding | Weergegeven als | Opmerking |
|---|---|---|
{ENDPOINT} |
Het eindpunt voor het verifiëren van uw API-aanvraag. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
De naam van uw project. Deze waarde is hoofdlettergevoelig. | myProject |
{DEPLOYMENT-NAME} |
De naam van uw implementatie. Deze waarde is hoofdlettergevoelig. | staging |
{API-VERSION} |
De versie van de API die u aanroept. De waarde waarnaar hier wordt verwezen, is voor de nieuwste versie die is uitgebracht. Zie de levenscyclus van het model voor meer informatie over andere beschikbare API-versies. | 2022-05-01 |
Headers
Gebruik de volgende header om uw aanvraag te verifiëren.
| Sleutel | Weergegeven als |
|---|---|
Ocp-Apim-Subscription-Key |
De sleutel voor uw resource. Wordt gebruikt voor het verifiëren van uw API-aanvragen. |
Aanvraagtekst
Gebruik de volgende JSON in de hoofdtekst van uw aanvraag. Gebruik de naam van het model dat u aan de implementatie wilt toewijzen.
{
"trainedModelLabel": "{MODEL-NAME}"
}
| Key | Tijdelijke aanduiding | Weergegeven als | Opmerking |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
De modelnaam die wordt toegewezen aan uw implementatie. U kunt alleen getrainde modellen toewijzen. Deze waarde is hoofdlettergevoelig. | myModel |
Zodra u uw API-aanvraag hebt verzonden, ontvangt u een 202 antwoord dat aangeeft dat de taak correct is verzonden. Pak de operation-location waarde uit in de antwoordheaders. Deze wordt als volgt opgemaakt:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} wordt gebruikt om uw aanvraag te identificeren, omdat deze bewerking asynchroon is. U kunt deze URL gebruiken om de implementatiestatus op te halen.
Status van implementatietaak ophalen
Gebruik de volgende GET-aanvraag om de status van de implementatietaak op te vragen. U kunt de URL die u hebt ontvangen uit de vorige stap gebruiken of de onderstaande tijdelijke aanduidingen vervangen door uw eigen waarden.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| Tijdelijke aanduiding | Weergegeven als | Opmerking |
|---|---|---|
{ENDPOINT} |
Het eindpunt voor het verifiëren van uw API-aanvraag. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
De naam van uw project. Deze waarde is hoofdlettergevoelig. | myProject |
{DEPLOYMENT-NAME} |
De naam van uw implementatie. Deze waarde is hoofdlettergevoelig. | staging |
{JOB-ID} |
De id voor het zoeken naar de trainingsstatus van uw model. Dit is de location headerwaarde die u in de vorige stap hebt ontvangen. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
De versie van de API die u aanroept. De waarde waarnaar hier wordt verwezen, is voor de nieuwste versie die is uitgebracht. Zie de levenscyclus van het model voor meer informatie over andere beschikbare API-versies. | 2022-05-01 |
Headers
Gebruik de volgende header om uw aanvraag te verifiëren.
| Sleutel | Weergegeven als |
|---|---|
Ocp-Apim-Subscription-Key |
De sleutel voor uw resource. Wordt gebruikt voor het verifiëren van uw API-aanvragen. |
Hoofdtekst van antwoord
U ontvangt de volgende aanvraag wanneer u de aanvraag verzendt. Blijf dit eindpunt peilen totdat de statusparameter is gewijzigd in 'geslaagd'. U moet een 200 code ophalen om het succes van de aanvraag aan te geven.
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Voorspellingen doen met uw getrainde model
Nadat uw model is geïmplementeerd, kunt u het gaan gebruiken om entiteiten uit uw tekst te extraheren met behulp van de voorspellings-API. In de voorbeeldgegevensset die u eerder hebt gedownload, vindt u enkele testdocumenten die u in deze stap kunt gebruiken.
Een aangepaste Text Analytics verzenden voor statustaak
Gebruik deze POST-aanvraag om een aangepaste Text Analytics-taak te starten voor statusextractie.
{ENDPOINT}/language/analyze-text/jobs?api-version={API-VERSION}
| Tijdelijke aanduiding | Weergegeven als | Opmerking |
|---|---|---|
{ENDPOINT} |
Het eindpunt voor het verifiëren van uw API-aanvraag. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
De versie van de API die u aanroept. De waarde waarnaar hier wordt verwezen, is voor de nieuwste versie die is uitgebracht. Zie de levenscyclus van het model voor meer informatie over andere beschikbare API-versies. | 2022-05-01 |
Headers
| Sleutel | Weergegeven als |
|---|---|
| Ocp-Apim-Subscription-Key | Uw sleutel die toegang biedt tot deze API. |
Tekst
{
"displayName": "Extracting entities",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "{LANGUAGE-CODE}",
"text": "Text1"
},
{
"id": "2",
"language": "{LANGUAGE-CODE}",
"text": "Text2"
}
]
},
"tasks": [
{
"kind": "CustomHealthcare",
"taskName": "Custom TextAnalytics for Health Test",
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}"
}
}
]
}
| Key | Tijdelijke aanduiding | Weergegeven als | Opmerking |
|---|---|---|---|
displayName |
{JOB-NAME} |
Uw taaknaam. | MyJobName |
documents |
[{},{}] | Lijst met documenten waarop taken moeten worden uitgevoerd. | [{},{}] |
id |
{DOC-ID} |
Documentnaam of id. | doc1 |
language |
{LANGUAGE-CODE} |
Een tekenreeks die de taalcode voor het document opgeeft. Als deze sleutel niet is opgegeven, wordt door de service uitgegaan van de standaardtaal van het project dat is geselecteerd tijdens het maken van het project. Zie taalondersteuning voor een lijst met ondersteunde taalcodes. | en-us |
text |
{DOC-TEXT} |
Documenteer de taak waarop de taken moeten worden uitgevoerd. | Lorem ipsum dolor sit amet |
tasks |
Lijst met taken die we willen uitvoeren. | [] |
|
taskName |
Custom Text Analytics for Health Test |
De taaknaam | Custom Text Analytics for Health Test |
kind |
CustomHealthcare |
Het project- of taaktype dat we proberen uit te voeren | CustomHealthcare |
parameters |
Lijst met parameters die aan de taak moeten worden doorgegeven. | ||
project-name |
{PROJECT-NAME} |
De naam voor uw project. Deze waarde is hoofdlettergevoelig. | myProject |
deployment-name |
{DEPLOYMENT-NAME} |
De naam van uw implementatie. Deze waarde is hoofdlettergevoelig. | prod |
Respons
U ontvangt een 202-antwoord dat aangeeft dat uw taak is verzonden. Pak in de antwoordheaders het uitoperation-location.
operation-location is als volgt opgemaakt:
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
U kunt deze URL gebruiken om de voltooiingsstatus van de taak op te vragen en de resultaten op te halen wanneer de taak is voltooid.
Taakresultaten ophalen
Gebruik de volgende GET-aanvraag om de status/resultaten van de aangepaste entiteitsherkenningstaak op te vragen.
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
| Tijdelijke aanduiding | Weergegeven als | Opmerking |
|---|---|---|
{ENDPOINT} |
Het eindpunt voor het verifiëren van uw API-aanvraag. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
De versie van de API die u aanroept. De waarde waarnaar hier wordt verwezen, is voor de nieuwste versie die is uitgebracht. Zie de levenscyclus van het model voor meer informatie over andere beschikbare API-versies. | 2022-05-01 |
Headers
| Sleutel | Weergegeven als |
|---|---|
| Ocp-Apim-Subscription-Key | Uw sleutel die toegang biedt tot deze API. |
Hoofdtekst van antwoord
Het antwoord is een JSON-document met de volgende parameters
{
"createdDateTime": "2021-05-19T14:32:25.578Z",
"displayName": "MyJobName",
"expirationDateTime": "2021-05-19T14:32:25.578Z",
"jobId": "xxxx-xxxx-xxxxx-xxxxx",
"lastUpdateDateTime": "2021-05-19T14:32:25.578Z",
"status": "succeeded",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "CustomHealthcareLROResults",
"taskName": "Custom Text Analytics for Health Test",
"lastUpdateDateTime": "2020-10-01T15:01:03Z",
"status": "succeeded",
"results": {
"documents": [
{
"entities": [
{
"entityComponentInformation": [
{
"entityComponentKind": "learnedComponent"
}
],
"offset": 0,
"length": 11,
"text": "first entity",
"category": "Entity1",
"confidenceScore": 0.98
},
{
"entityComponentInformation": [
{
"entityComponentKind": "listComponent"
}
],
"offset": 0,
"length": 11,
"text": "first entity",
"category": "Entity1.Dictionary",
"confidenceScore": 1.0
},
{
"entityComponentInformation": [
{
"entityComponentKind": "learnedComponent"
}
],
"offset": 16,
"length": 9,
"text": "entity two",
"category": "Entity2",
"confidenceScore": 1.0
},
{
"entityComponentInformation": [
{
"entityComponentKind": "prebuiltComponent"
}
],
"offset": 37,
"length": 9,
"text": "ibuprofen",
"category": "MedicationName",
"confidenceScore": 1,
"assertion": {
"certainty": "negative"
},
"name": "ibuprofen",
"links": [
{
"dataSource": "UMLS",
"id": "C0020740"
},
{
"dataSource": "AOD",
"id": "0000019879"
},
{
"dataSource": "ATC",
"id": "M01AE01"
},
{
"dataSource": "CCPSS",
"id": "0046165"
},
{
"dataSource": "CHV",
"id": "0000006519"
},
{
"dataSource": "CSP",
"id": "2270-2077"
},
{
"dataSource": "DRUGBANK",
"id": "DB01050"
},
{
"dataSource": "GS",
"id": "1611"
},
{
"dataSource": "LCH_NW",
"id": "sh97005926"
},
{
"dataSource": "LNC",
"id": "LP16165-0"
},
{
"dataSource": "MEDCIN",
"id": "40458"
},
{
"dataSource": "MMSL",
"id": "d00015"
},
{
"dataSource": "MSH",
"id": "D007052"
},
{
"dataSource": "MTHSPL",
"id": "WK2XYI10QM"
},
{
"dataSource": "NCI",
"id": "C561"
},
{
"dataSource": "NCI_CTRP",
"id": "C561"
},
{
"dataSource": "NCI_DCP",
"id": "00803"
},
{
"dataSource": "NCI_DTP",
"id": "NSC0256857"
},
{
"dataSource": "NCI_FDA",
"id": "WK2XYI10QM"
},
{
"dataSource": "NCI_NCI-GLOSS",
"id": "CDR0000613511"
},
{
"dataSource": "NDDF",
"id": "002377"
},
{
"dataSource": "PDQ",
"id": "CDR0000040475"
},
{
"dataSource": "RCD",
"id": "x02MO"
},
{
"dataSource": "RXNORM",
"id": "5640"
},
{
"dataSource": "SNM",
"id": "E-7772"
},
{
"dataSource": "SNMI",
"id": "C-603C0"
},
{
"dataSource": "SNOMEDCT_US",
"id": "387207008"
},
{
"dataSource": "USP",
"id": "m39860"
},
{
"dataSource": "USPMG",
"id": "MTHU000060"
},
{
"dataSource": "VANDF",
"id": "4017840"
}
]
},
{
"entityComponentInformation": [
{
"entityComponentKind": "prebuiltComponent"
}
],
"offset": 30,
"length": 6,
"text": "100 mg",
"category": "Dosage",
"confidenceScore": 0.98
}
],
"relations": [
{
"confidenceScore": 1,
"relationType": "DosageOfMedication",
"entities": [
{
"ref": "#/documents/0/entities/1",
"role": "Dosage"
},
{
"ref": "#/documents/0/entities/0",
"role": "Medication"
}
]
}
],
"id": "1",
"warnings": []
}
],
"errors": [],
"modelVersion": "2020-04-01"
}
}
]
}
}
| Key | Voorbeeldwaarde | Beschrijving |
|---|---|---|
| entiteiten | [] | Een matrix met alle geëxtraheerde entiteiten. |
| entityComponentKind | prebuiltComponent |
Een variabele die aangeeft welk onderdeel de specifieke entiteit heeft geretourneerd. Mogelijke waarden: prebuiltComponent, learnedComponent, listComponent |
| offset | 0 |
Een getal dat het beginpunt van de geëxtraheerde entiteit aangeeft door de tekens te indexeren |
| length | 10 |
Een getal dat de lengte aangeeft van de geëxtraheerde entiteit in het aantal tekens. |
| sms verzenden | first entity |
De tekst die is geëxtraheerd voor een specifieke entiteit. |
| category | MedicationName |
De naam van het entiteitstype of de categorie die overeenkomt met de geëxtraheerde tekst. |
| confidenceScore | 0.9 |
Een getal dat het zekerheidsniveau van het model aangeeft van de geëxtraheerde entiteit, variërend van 0 tot 1, met een hoger getal dat een hogere zekerheid aangeeft. |
| assertion | certainty |
Asserties die zijn gekoppeld aan de geëxtraheerde entiteit. Asserties worden alleen ondersteund voor vooraf samengestelde Text Analytics voor statusentiteiten. |
| name | Ibuprofen |
De genormaliseerde naam voor de entiteit die is gekoppeld aan de geëxtraheerde entiteit. Entiteitskoppeling wordt alleen ondersteund voor vooraf samengestelde Text Analytics voor statusentiteiten. |
| koppelingen | [] | Een matrix met alle resultaten van de entiteit die is gekoppeld aan de geëxtraheerde entiteit. Entiteitskoppeling wordt alleen ondersteund voor vooraf samengestelde Text Analytics voor statusentiteiten. |
| Datasource | UMLS |
De referentiestandaard die voortvloeit uit de entiteit die is gekoppeld aan de geëxtraheerde entiteit. Entiteitskoppeling wordt alleen ondersteund voor vooraf samengestelde Text Analytics voor statusentiteiten. |
| Id | C0020740 |
De referentiecode die het resultaat is van de entiteit die is gekoppeld aan de geëxtraheerde entiteit die hoort bij de geëxtraheerde gegevensbron. Entiteitskoppeling wordt alleen ondersteund voor vooraf samengestelde Text Analytics voor statusentiteiten. |
| Betrekkingen | [] | Matrix met alle geëxtraheerde relaties. Relatieextractie wordt alleen ondersteund voor vooraf samengestelde Text Analytics voor statusentiteiten. |
| relationType | DosageOfMedication |
De categorie van de geëxtraheerde relatie. Relatieextractie wordt alleen ondersteund voor vooraf samengestelde Text Analytics voor statusentiteiten. |
| entities | "Dosage", "Medication" |
De entiteiten die zijn gekoppeld aan de geëxtraheerde relatie. Relatieextractie wordt alleen ondersteund voor vooraf samengestelde Text Analytics voor statusentiteiten. |
Resources opschonen
Wanneer u uw project niet meer nodig hebt, kunt u het verwijderen met de volgende DELETE-aanvraag . Vervang de tijdelijke aanduidingen door uw eigen waarden.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| Tijdelijke aanduiding | Weergegeven als | Opmerking |
|---|---|---|
{ENDPOINT} |
Het eindpunt voor het verifiëren van uw API-aanvraag. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
De naam voor uw project. Deze waarde is hoofdlettergevoelig. | myProject |
{API-VERSION} |
De versie van de API die u aanroept. De waarde waarnaar hier wordt verwezen, is voor de nieuwste versie die is uitgebracht. Zie de levenscyclus van het model voor meer informatie over andere beschikbare API-versies. | 2022-05-01 |
Headers
Gebruik de volgende header om uw aanvraag te verifiëren.
| Sleutel | Weergegeven als |
|---|---|
| Ocp-Apim-Subscription-Key | De sleutel voor uw resource. Wordt gebruikt voor het verifiëren van uw API-aanvragen. |
Zodra u uw API-aanvraag hebt verzonden, ontvangt u een 202 antwoord dat aangeeft dat uw project is verwijderd. Een geslaagde aanroepresultaten met een header Operation-Location die wordt gebruikt om de status van de taak te controleren.
Volgende stappen
Nadat u het model voor entiteitextractie hebt gemaakt, kunt u het volgende doen:
Wanneer u begint met het maken van uw eigen aangepaste Text Analytics voor statusprojecten, gebruikt u de artikelen met procedures voor meer informatie over het labelen van gegevens, het trainen en gebruiken van uw model in meer detail:
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor