Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Met Azure OpenAI in Azure AI Foundry Models kunt u onze modellen aanpassen aan uw persoonlijke gegevenssets met behulp van een proces dat bekend staat als fine-tuning. Met deze aanpassingsstap kunt u meer uit de service halen door het volgende te bieden:
- Resultaten van hogere kwaliteit dan wat u kunt krijgen van prompt engineering
- De mogelijkheid om meer voorbeelden te trainen dan in de maximale aanvraagcontextlimiet van een model past.
- Tokenbesparingen vanwege kortere prompts
- Aanvragen met een lagere latentie, met name bij het gebruik van kleinere modellen.
In tegenstelling tot weinig-shot learning verbetert het aanpassen van het model door het model te trainen op veel meer voorbeelden dan in een prompt past, zodat u betere resultaten kunt bereiken voor een groot aantal taken. Omdat de gewichten van het basismodel worden aangepast om de prestaties van de specifieke taak te verbeteren, hoeft u niet zoveel voorbeelden of instructies in uw prompt op te nemen. Dit betekent dat er minder tekst wordt verzonden en dat er minder tokens worden verwerkt voor elke API-aanroep, waardoor mogelijk kosten worden bespaard en de latentie van aanvragen wordt verbeterd.
We gebruiken LoRA of een lage rangschikking om modellen op een manier af te stemmen die hun complexiteit vermindert zonder de prestaties aanzienlijk te beïnvloeden. Deze methode werkt door de oorspronkelijke matrix met hoge rang te benaderen met een lagere rang, waardoor alleen een kleinere subset van belangrijke parameters tijdens de begeleide trainingsfase wordt verfijnd, waardoor het model beter beheersbaar en efficiënter wordt. Voor gebruikers maakt dit training sneller en betaalbaarer dan andere technieken.
Er zijn twee unieke verfijningservaringen in de Azure AI Foundry-portal:
- Hub-/projectweergave : biedt ondersteuning voor het verfijnen van modellen van meerdere providers, waaronder Azure OpenAI, Meta Llama, Microsoft Phi, enzovoort.
- Azure OpenAI-gerichte weergave : biedt alleen ondersteuning voor het verfijnen van Azure OpenAI-modellen, maar biedt ondersteuning voor aanvullende functies zoals de W&B-preview-integratie (Weights & Biases).
Als u alleen Azure OpenAI-modellen verfijnt, raden we u aan om de op Azure OpenAI gerichte verfijningservaring te gebruiken die beschikbaar is door naar te https://ai.azure.com/resource/overviewnavigeren.
Belangrijk
Items die in dit artikel zijn gemarkeerd (preview) zijn momenteel beschikbaar als openbare preview. Deze preview wordt aangeboden zonder een service level agreement en we raden deze niet aan voor productieworkloads. Bepaalde functies worden mogelijk niet ondersteund of hebben mogelijk beperkte mogelijkheden. Voor meer informatie, zie Aanvullende Gebruiksvoorwaarden voor Microsoft Azure Previews.
Vereiste voorwaarden
- Lees de handleiding Wanneer u Azure OpenAI-afstemming gebruikt.
- Een Azure-abonnement. Maak gratis een account.
- Een Azure OpenAI-resource die zich in een regio bevindt die ondersteuning biedt voor het afstemmen van het Azure OpenAI-model. Controleer de overzichtstabel model en de beschikbaarheid van regio's voor de lijst met beschikbare modellen per regio en ondersteunde functionaliteit. Zie Een resource maken en een model implementeren met Azure OpenAI voor meer informatie.
- Voor het afstemmen van de toegang is Cognitive Services OpenAI-inzender vereist.
- Als u nog geen toegang hebt om quota weer te geven en modellen implementeert in de Azure AI Foundry-portal, hebt u aanvullende machtigingen nodig.
Ondersteunde modellen
Raadpleeg de modellenpagina om te controleren welke regio's momenteel ondersteuning bieden voor afstemming.
U kunt ook een eerder afgestemd model verfijnen, opgemaakt als base-model.ft-{jobid}.
De werkstroom controleren voor azure AI Foundry Portal
Neem even de tijd om de werkstroom voor het afstemmen van de Azure AI Foundry-portal te bekijken:
- Bereid uw training en validatiegegevens voor.
- Gebruik het dialoogvenster Een nauwkeurig afgestemd model maken in azure AI Foundry Portal om uw aangepaste model te trainen.
- Selecteer een trainingsmethode.
- Selecteer een basismodel.
- Kies uw trainingstype
- Kies uw trainingsgegevens.
- Kies desgewenst uw validatiegegevens.
- Configureer desgewenst taakparameters voor uw taakafstemming.
- Schakel desgewenst automatische implementatie in voor het resulterende aangepaste model.
- Controleer uw keuzes en train uw nieuwe aangepaste model.
- Controleer de status van uw aangepaste aangepaste model.
- Implementeer uw aangepaste model voor gebruik.
- Gebruik uw aangepaste model.
- Analyseer eventueel uw aangepaste model voor prestaties en fit.
Uw training en validatiegegevens voorbereiden
Uw trainingsgegevens en validatiegegevenssets bestaan uit voorbeelden van invoer en uitvoer voor hoe u het model wilt laten presteren.
De trainings- en validatiegegevens die u gebruikt , moeten worden opgemaakt als een JSON Lines-document (JSONL) en moeten worden opgemaakt in de gespreksindeling die wordt gebruikt door de API voor voltooiing van chats.
Het wordt over het algemeen aanbevolen om de instructies en aanwijzingen te gebruiken die u het beste hebt gevonden in elk trainingsvoorbeeld. Dit helpt u de beste resultaten te krijgen, vooral als u minder dan honderd voorbeelden hebt.
Voorbeeld van bestandsindeling
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who discovered Antarctica?"}, {"role": "assistant", "content": "Some chaps named Fabian Gottlieb von Bellingshausen and Mikhail Lazarev, as if they don't teach that in every school!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the biggest ocean?"}, {"role": "assistant", "content": "The Pacific Ocean. It's not like it's a small pond or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest planet?"}, {"role": "assistant", "content": "It's called Jupiter, you might have heard of it...or not."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who painted the Mona Lisa?"}, {"role": "assistant", "content": "Oh, some obscure artist named Leonardo da Vinci. Not that he is famous or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the boiling point of water?"}, {"role": "assistant", "content": "Exciting fact of the day: it's 100 degrees Celsius. Life-changing, isn't it?"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'The Odyssey'?"}, {"role": "assistant", "content": "Oh, just some poet named Homer. Nothing special, really."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest mammal?"}, {"role": "assistant", "content": "Blue Whale. Quite a big fish isn't it? Oh wait, it's not a fish!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the highest mountain peak?"}, {"role": "assistant", "content": "Everest. Brace yourself, it's not a walk in the park."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who invented the telephone?"}, {"role": "assistant", "content": "A guy named Alexander Graham Bell. Bet you didn't guess that one!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the distance from Earth to the Sun?"}, {"role": "assistant", "content": "About 93 million miles. Just a quick drive, really."}]}
Multi-turn chat-bestandsindeling Azure OpenAI
Meerdere beurten van een gesprek in één regel van uw jsonl-trainingsbestand worden ook ondersteund. Als u het afstemmen van specifieke assistentberichten wilt overslaan, voegt u het optionele weight sleutelwaardepaar toe. Momenteel weight kan worden ingesteld op 0 of 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Chatvoltooiingen met visie
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Naast de JSONL-indeling moeten trainings- en validatiegegevensbestanden worden gecodeerd in UTF-8 en een byte-ordermarkering (BOM) bevatten. Het bestand moet kleiner zijn dan 512 MB.
Overwegingen over de grootte van gegevenssets
Hoe meer trainingsvoorbeelden u hebt, hoe beter. Het verfijnen van taken gaat niet verder zonder ten minste 10 trainingsvoorbeelden, maar een dergelijk klein aantal is niet voldoende om merkbare invloed te hebben op modelreacties. Het is raadzaam honderden, zo niet duizenden, trainingsvoorbeelden te bieden om succesvol te zijn. Het is raadzaam om te beginnen met 50 goed samengestelde trainingsgegevens.
Over het algemeen kan het verdubbelen van de grootte van de gegevensset leiden tot een lineaire toename van de modelkwaliteit. Maar houd er rekening mee dat voorbeelden van lage kwaliteit een negatieve invloed kunnen hebben op de prestaties. Als u het model traint op een grote hoeveelheid interne gegevens, zonder eerst de gegevensset te verwijderen voor alleen de voorbeelden van de hoogste kwaliteit, zou u kunnen eindigen met een model dat veel slechter presteert dan verwacht.
Een nauwkeurig afgestemd model maken
Azure AI Foundry Portal biedt het dialoogvenster Een nauwkeurig afgestemd model maken , zodat u op één plek eenvoudig een nauwkeurig afgestemd model voor uw Azure-resource kunt maken en trainen.
Ga naar de Azure AI Foundry-portal op https://ai.azure.com/ en meld u aan met inloggegevens die toegang hebben tot uw Azure OpenAI-resource. Selecteer tijdens de aanmeldingswerkstroom de juiste map, het Azure-abonnement en de Azure OpenAI-resource.
Blader in de Azure AI Foundry-portal naar het deelvenster Hulpprogramma's > afstemmen en selecteer Het model verfijnen.

Selecteer een model om af te stemmen en selecteer vervolgens Volgende om door te gaan.


U ziet nu het dialoogvenster Een nauwkeurig afgestemd model maken .

Kies uw trainingsmethode
De eerste stap is het bevestigen van uw modelkeuze en de trainingsmethode. Niet alle modellen ondersteunen alle trainingsmethoden.
- SFT (Fine Tuning onder supervisie ): ondersteund door alle niet-redenerende modellen.
- Direct Preference Optimization (Preview) (DPO): ondersteund door GPT-4o.
- Versterking Fijnafstelling (Preview) (RFT): ondersteund door redeneringsmodellen, zoals o4-mini.
Wanneer u het model selecteert, kunt u ook een eerder afgestemd model selecteren.
Uw trainingstype kiezen
Selecteer de trainingslaag die u wilt gebruiken voor uw taak voor het afstemmen:
- Standaard: training vindt plaats in de regio van de huidige Azure OpenAI-resource, waar gegevensresidentie wordt gegarandeerd.
- Global (preview): meer betaalbare training per token, biedt geen data residency.
Als u geen vereisten voor gegevenslocatie hebt, is Global een goede keuze om te profiteren van trainingscapaciteit buiten uw huidige regio. In openbare preview is Global mogelijk niet beschikbaar in uw huidige regio. Overleg
In sommige gevallen is Standard mogelijk niet beschikbaar in uw huidige regio. U kunt de regio's die worden vermeld in de beschikbaarheid van het model voor uw gekozen model raadplegen als u gegevensopslaglocatie vereist.
Uw trainingsgegevens kiezen
De volgende stap bestaat uit het kiezen van bestaande voorbereide trainingsgegevens of het uploaden van nieuwe voorbereide trainingsgegevens die moeten worden gebruikt bij het aanpassen van uw model door trainingsgegevens toevoegen te selecteren.
Het dialoogvenster Trainingsgegevens bevat bestaande, eerder geüploade gegevenssets en biedt ook opties voor het uploaden van nieuwe trainingsgegevens.
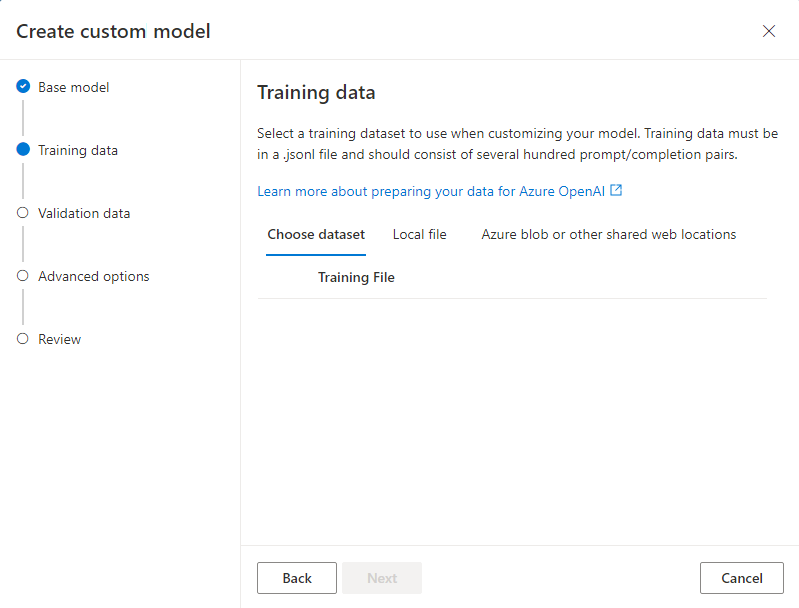
Als uw trainingsgegevens al naar de service zijn geüpload, selecteert u Bestanden uit de verbonden AI-resource.
- Selecteer het bestand in de vervolgkeuzelijst die wordt weergegeven.
Als u nieuwe trainingsgegevens wilt uploaden, gebruikt u een van de volgende opties:
- Selecteer Bestanden uploaden om trainingsgegevens uit een lokaal bestand te uploaden.
- Selecteer Azure Blob of andere gedeelde weblocaties om trainingsgegevens te importeren uit Azure Blob of een andere gedeelde weblocatie.
Voor grote gegevensbestanden raden we u aan om te importeren uit een Azure Blob-archief. Grote bestanden kunnen instabiel worden wanneer ze worden geüpload via formulieren met meerdere onderdelen, omdat de aanvragen atomisch zijn en niet opnieuw kunnen worden geprobeerd of hervat. Voor meer informatie over Azure Blob Storage, zie Wat is Azure Blob Storage?
Opmerking
Trainingsgegevensbestanden moeten worden opgemaakt als JSONL-bestanden, gecodeerd in UTF-8 met een byte-ordermarkering (BOM). Het bestand moet kleiner zijn dan 512 MB.
Uw validatiegegevens kiezen (optioneel)
Als u een validatiegegevensset hebt, selecteert u Trainingsgegevens toevoegen. U kunt bestaande voorbereide validatiegegevens kiezen of nieuwe voorbereide validatiegegevens uploaden om te gebruiken bij het aanpassen van uw model.
In het dialoogvenster Validatiegegevens worden bestaande, eerder geüploade trainings- en validatiegegevenssets weergegeven en worden opties geboden waarmee u nieuwe validatiegegevens kunt uploaden.
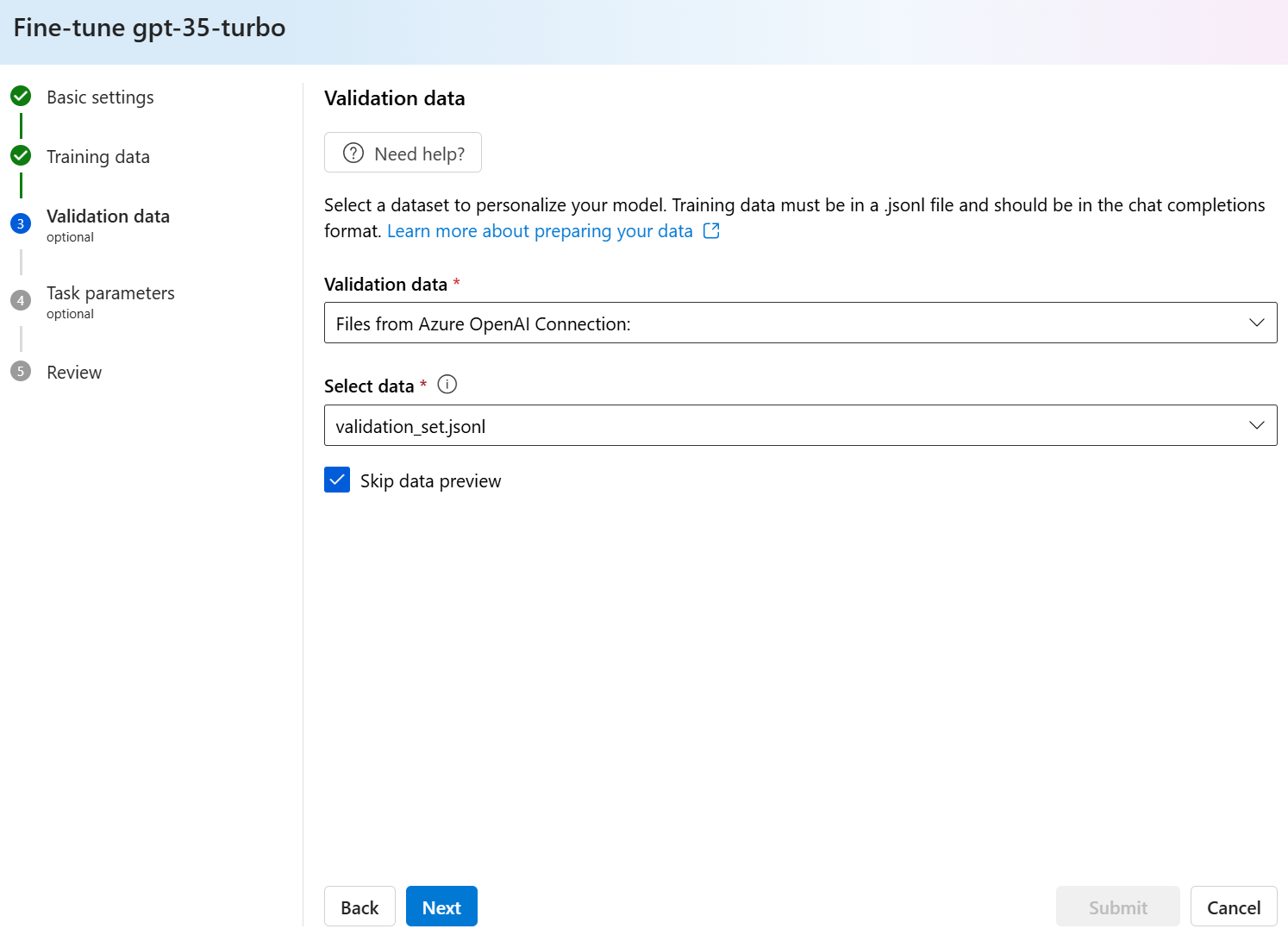
Als uw validatiegegevens al naar de service zijn geüpload, selecteert u Gegevensset kiezen.
- Selecteer het bestand in de lijst die wordt weergegeven in het deelvenster Validatiegegevens .
Als u nieuwe validatiegegevens wilt uploaden, gebruikt u een van de volgende opties:
- Selecteer Lokaal bestand om validatiegegevens uit een lokaal bestand te uploaden.
- Selecteer Azure Blob of andere gedeelde weblocaties om validatiegegevens te importeren uit Azure Blob of een andere gedeelde weblocatie.
Voor grote gegevensbestanden raden we u aan om te importeren uit een Azure Blob-archief. Grote bestanden kunnen instabiel worden wanneer ze worden geüpload via formulieren met meerdere onderdelen, omdat de aanvragen atomisch zijn en niet opnieuw kunnen worden geprobeerd of hervat.
Opmerking
Net als bij trainingsgegevensbestanden moeten validatiegegevensbestanden worden opgemaakt als JSONL-bestanden, gecodeerd in UTF-8 met een bytevolgordemarkering (BOM). Het bestand moet kleiner zijn dan 512 MB.
Uw model identificeerbaar maken (optioneel)
We raden u ook aan een suffix parameter op te geven, zodat u gemakkelijker onderscheid kunt maken tussen verschillende iteraties van uw nauwkeurig afgestemde model. A suffix neemt een tekenreeks van maximaal 18 tekens in beslag en wordt gebruikt bij het benoemen van het resulterende verfijnde model.
Trainingsparameters configureren (optioneel)
U kunt een optioneel seed opgeven en aanvullende hyperparameters afstemmen.
Het zaad bepaalt de reproduceerbaarheid van de taak. Het doorgeven van dezelfde seed- en taakparameters moet dezelfde resultaten opleveren, maar kan in zeldzame gevallen verschillen. Als er geen seed is opgegeven, wordt er een willekeurig voor u gegenereerd.

De volgende hyperparameters zijn beschikbaar voor afstemming via de Azure AI Foundry-portal:
| Naam | Typ | Beschrijving |
|---|---|---|
| Batchgrootte | integer | De batchgrootte die moet worden gebruikt voor training. De batchgrootte is het aantal trainingsvoorbeelden dat wordt gebruikt voor het trainen van één vooruit- en achterwaartse pass. Over het algemeen hebben we vastgesteld dat grotere batchgrootten meestal beter werken voor grotere gegevenssets. De standaardwaarde en de maximumwaarde voor deze eigenschap zijn specifiek voor een basismodel. Een grotere batchgrootte betekent dat modelparameters minder vaak worden bijgewerkt, maar met een lagere variantie. |
| Vermenigvuldiger van leersnelheid | nummer | De vermenigvuldiger van het leerpercentage die moet worden gebruikt voor training. De fijnafstemmingsleertempo is het oorspronkelijke leertempo dat wordt gebruikt voor pretraining vermenigvuldigd met deze waarde. Grotere leersnelheden presteren meestal beter met grotere batchgrootten. We raden u aan te experimenteren met waarden in het bereik 0,02 tot 0,2 om te zien wat de beste resultaten oplevert. Een kleiner leerpercentage kan nuttig zijn om overfitting te voorkomen. |
| Aantal epochs | integer | Het aantal tijdvakken waarvoor het model moet worden getraind. Een tijdsperiode verwijst naar één volledige cyclus door de trainingsgegevensset. |
Automatische implementatie inschakelen (optioneel)
Als u tijd wilt besparen, kunt u desgewenst automatische implementatie inschakelen voor uw resulterende model. Als de training is voltooid, wordt het model geïmplementeerd met het geselecteerde implementatietype. De implementatie krijgt een naam op basis van de unieke naam die is gegenereerd voor uw aangepaste model en het optionele achtervoegsel dat u mogelijk eerder hebt opgegeven.

Opmerking
Alleen globale standaard- en ontwikkelaarsimplementaties worden momenteel ondersteund voor automatische implementatie. Geen van deze opties biedt gegevenslocatie. Raadpleeg de documentatie voor het implementatietype voor meer informatie.
Uw keuzes controleren en uw model trainen
Controleer uw keuzes en selecteer Verzenden om te beginnen met het trainen van uw nieuwe aangepaste model.
De status van uw aangepaste model controleren
Nadat u uw fijninstellingstaak hebt ingediend, ziet u een pagina met details over uw gefine-tuned model. U kunt de status en meer informatie over uw fijnafgestelde model vinden op de "Fijnafstelling"-pagina in het Azure AI Foundry Portal.
Uw taak wordt mogelijk in de wachtrij geplaatst achter andere taken in het systeem. Het trainen van uw model kan enkele minuten of uren duren, afhankelijk van de grootte van het model en de gegevensset.
Controlepunten
Wanneer elke trainingsperiode voltooid is, wordt er een controlepunt gegenereerd. Een controlepunt is een volledig functionele versie van een model dat zowel kan worden geïmplementeerd als gebruikt als het doelmodel voor volgende taakafstemming. Controlepunten zijn met name nuttig, omdat ze momentopnamen kunnen bieden voordat overfitting optreedt. Wanneer een taak voor het afstemmen is voltooid, beschikt u over de drie meest recente versies van het model die u kunt implementeren.
Uw aangepaste model analyseren
Azure OpenAI voegt een resultaatbestand met de naam results.csv toe aan elke taak voor het afstemmen nadat deze is voltooid. U kunt het resultaatbestand gebruiken om de trainings- en validatieprestaties van uw aangepaste model te analyseren. De bestands-id voor het resultaatbestand wordt weergegeven voor elk aangepast model in de kolom Resultaatbestand-id in het deelvenster Modellen voor de Azure AI Foundry-portal. U kunt de bestands-id gebruiken om het resultaatbestand te identificeren en te downloaden vanuit het deelvenster Gegevensbestanden van de Azure AI Foundry-portal.
Het resultaatbestand is een CSV-bestand dat een veldnamenrij en een rij bevat voor elke trainingsstap die wordt uitgevoerd door de taak voor het afstemmen. Het resultaatbestand bevat de volgende kolommen:
| Kolomnaam | Beschrijving |
|---|---|
step |
Het nummer van de trainingsstap. Een trainingsstap vertegenwoordigt één pas, vooruit en achteruit, op een batch trainingsgegevens. |
train_loss |
Het verlies voor de trainingsbatch. |
train_mean_token_accuracy |
Het percentage tokens in de trainingsbatch correct voorspeld door het model. Als de batchgrootte bijvoorbeeld is ingesteld op 3 en uw gegevens voltooiingen [[1, 2], [0, 5], [4, 2]]bevatten, wordt deze waarde ingesteld op 0,83 (5 van 6) als het model is voorspeld [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
Het verlies voor de validatiebatch. |
validation_mean_token_accuracy |
Het percentage tokens in de validatiebatch correct voorspeld door het model. Als de batchgrootte bijvoorbeeld is ingesteld op 3 en uw gegevens voltooiingen [[1, 2], [0, 5], [4, 2]]bevatten, wordt deze waarde ingesteld op 0,83 (5 van 6) als het model is voorspeld [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
Het validatieverlies dat aan het einde van elk tijdvak wordt berekend. Wanneer de training goed gaat, moet verlies afnemen. |
full_valid_mean_token_accuracy |
De geldige gemiddelde tokennauwkeurigheid die aan het einde van elk tijdvak wordt berekend. Wanneer de training goed gaat, moet de nauwkeurigheid van tokens toenemen. |
U kunt de gegevens in uw results.csv-bestand ook weergeven als plots in de Azure AI Foundry-portal. Selecteer de koppeling voor uw getrainde model en u ziet drie grafieken: verlies, gemiddelde tokennauwkeurigheid en tokennauwkeurigheid. Als u validatiegegevens hebt opgegeven, worden beide gegevenssets weergegeven op dezelfde plot.
Zoek naar uw verlies om in de loop van de tijd te verminderen en uw nauwkeurigheid om te verhogen. Als u een verschil ziet tussen uw training en validatiegegevens, kan dit erop wijzen dat u overfitting gebruikt. Probeer training met minder tijdvakken of een kleinere vermenigvuldiging van leersnelheid.
Een nauwkeurig afgestemd model implementeren
Zodra u tevreden bent met de statistieken van uw fijnsluitingsopdracht, of als u gewoon naar inferentie wilt doorgaan, moet u het model implementeren.
Als u implementeert voor verdere validatie, kunt u overwegen om te implementeren voor testen met behulp van een ontwikkelaarsimplementatie.
Als u klaar bent om te implementeren voor productie of als u specifieke gegevenslocatiebehoeften hebt, volgt u onze implementatiehandleiding.
Een geïmplementeerd, nauwkeurig afgestemd model gebruiken
Nadat uw nauwkeurig afgestemde model is geïmplementeerd, kunt u het net als elk ander geïmplementeerd model gebruiken. U kunt de Playground in Azure AI Foundry gebruiken om te experimenteren met uw nieuwe implementatie. U kunt ook de REST API gebruiken om uw nauwkeurig afgestemde model aan te roepen vanuit uw eigen toepassing. U kunt zelfs beginnen met het gebruik van dit nieuwe verfijnde model in uw promptstroom om uw generatieve AI-toepassing te bouwen.
Opmerking
Voor chatmodellen moet het systeembericht dat u gebruikt om uw afgestemde model te begeleiden (of het nu is geïmplementeerd of beschikbaar is voor testen in de speeltuin) hetzelfde zijn als het systeembericht dat u hebt gebruikt voor training. Als u een ander systeembericht gebruikt, werkt het model mogelijk niet zoals verwacht.
Continue afstemming
Zodra u een nauwkeurig afgestemd model hebt gemaakt, kunt u het model na verloop van tijd verder verfijnen door verder af te stemmen. Continue afstemming is het iteratieve proces van het selecteren van een al afgestemd model als basismodel en het verder afstemmen op nieuwe sets trainingsvoorbeelden.
Als u een model wilt verfijnen dat u eerder hebt afgestemd, zou u hetzelfde proces gebruiken als beschreven bij het maken van een nauwkeurig afgestemd model , maar in plaats van de naam van een algemeen basismodel op te geven, geeft u het al afgestemde model op. Een aangepast aangepast model ziet er als volgt uit gpt-4o-2024-08-06.ft-d93dda6110004b4da3472d96f4dd4777-ft

Uw implementaties, aangepaste modellen en trainingsbestanden opschonen
Wanneer u klaar bent met uw aangepaste model, kunt u de implementatie en het model verwijderen. U kunt ook de trainings- en validatiebestanden verwijderen die u naar de service hebt geüpload, indien nodig.
Uw modelimplementatie verwijderen
Belangrijk
Nadat u een aangepast model hebt geïmplementeerd, wordt de implementatie verwijderd als de implementatie langer dan vijftien (15) dagen inactief blijft. De uitrol van een aangepast model is inactief als het model meer dan vijftien (15) dagen geleden is uitgerold en er tijdens een aaneengesloten periode van 15 dagen geen voltooiingsoproepen of chatvoltooiingsoproepen zijn gedaan.
Het verwijderen van een inactieve implementatie is niet van invloed op het onderliggende aangepaste model en het aangepaste model kan op elk gewenst moment opnieuw worden geïmplementeerd. Zoals beschreven in Prijzen van Azure OpenAI in Azure AI Foundry Models brengt elk aangepast (fijn afgestemd) model dat wordt geïmplementeerd, een uurlijkse hostingkost met zich mee, ongeacht of er aanvragen voor voltooien of chatvoltooien naar het model worden gedaan. Raadpleeg de richtlijnen in Plan voor het beheren van kosten voor Azure OpenAI voor meer informatie over het plannen en beheren van kosten voor Azure OpenAI.
U kunt de implementatie voor uw aangepaste model verwijderen in het deelvenster Implementaties in de Azure AI Foundry-portal. Selecteer de implementatie die u wilt verwijderen en selecteer vervolgens Verwijderen om de implementatie te verwijderen.
Uw aangepaste model verwijderen
U kunt een aangepast model verwijderen in het deelvenster Modellen in de Azure AI Foundry-portal. Selecteer het aangepaste model dat u wilt verwijderen op het tabblad Aangepaste modellen en selecteer vervolgens Verwijderen om het aangepaste model te verwijderen.
Opmerking
U kunt een aangepast model niet verwijderen als het een bestaande implementatie heeft. U moet eerst uw modelimplementatie verwijderen voordat u uw aangepaste model kunt verwijderen.
Uw trainingsbestanden verwijderen
U kunt eventueel trainings- en validatiebestanden verwijderen die u hebt geüpload voor training, en resultaatbestanden die tijdens de training zijn gegenereerd, in het deelvenster Beheergegevens>en indexen in de Azure AI Foundry-portal. Selecteer het bestand dat u wilt verwijderen en selecteer vervolgens Verwijderen om het bestand te verwijderen.






Vereiste voorwaarden
- Lees de handleiding Wanneer u Azure OpenAI-afstemming gebruikt.
- Een Azure-abonnement. Maak gratis een account.
- Een Azure OpenAI-resource. Zie Een resource maken en een model implementeren met Azure OpenAI voor meer informatie.
- De volgende Python-bibliotheken:
os,json,requests,openai. - De OpenAI Python-bibliotheek moet ten minste versie 0.28.1 zijn.
- Voor het afstemmen van de toegang is Cognitive Services OpenAI-inzender vereist.
- Als u nog geen toegang hebt om quota weer te geven en modellen implementeert in de Azure AI Foundry-portal, hebt u aanvullende machtigingen nodig.
Opmerking
De REST API biedt momenteel geen ondersteuning voor globale trainingstaken. Het inspecteren van globale trainingstaken via de API kan onjuiste informatie retourneren.
Ondersteunde modellen
Raadpleeg de modellenpagina om te controleren welke regio's momenteel ondersteuning bieden voor afstemming.
Of u kunt een eerder afgestemd model, opgemaakt als base-model.ft-{jobid}.
De werkstroom voor de Python SDK controleren
Neem even de tijd om de werkstroom voor afstemming te bekijken voor het gebruik van de Python SDK met Azure OpenAI:
- Bereid uw training en validatiegegevens voor.
- Selecteer een basismodel.
- Upload uw trainingsgegevens.
- Train uw nieuwe aangepaste model.
- Controleer de status van uw aangepaste model.
- Implementeer uw aangepaste model voor gebruik.
- Gebruik uw aangepaste model.
- Analyseer eventueel uw aangepaste model voor prestaties en fit.
Uw training en validatiegegevens voorbereiden
Uw trainingsgegevens en validatiegegevenssets bestaan uit voorbeelden van invoer en uitvoer voor hoe u het model wilt laten presteren.
De trainings- en validatiegegevens die u gebruikt , moeten worden opgemaakt als een JSON Lines-document (JSONL) en moeten worden opgemaakt in de gespreksindeling die wordt gebruikt door de API voor voltooiing van chats.
Als u een stapsgewijze procedure voor het afstemmen wilt, gpt-4o-mini-2024-07-18 raadpleegt u de zelfstudie over het afstemmen van Azure OpenAI
Voorbeeld van bestandsindeling
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who discovered Antarctica?"}, {"role": "assistant", "content": "Some chaps named Fabian Gottlieb von Bellingshausen and Mikhail Lazarev, as if they don't teach that in every school!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the biggest ocean?"}, {"role": "assistant", "content": "The Pacific Ocean. It's not like it's a small pond or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest planet?"}, {"role": "assistant", "content": "It's called Jupiter, you might have heard of it...or not."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who painted the Mona Lisa?"}, {"role": "assistant", "content": "Oh, some obscure artist named Leonardo da Vinci. Not that he is famous or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the boiling point of water?"}, {"role": "assistant", "content": "Exciting fact of the day: it's 100 degrees Celsius. Life-changing, isn't it?"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'The Odyssey'?"}, {"role": "assistant", "content": "Oh, just some poet named Homer. Nothing special, really."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest mammal?"}, {"role": "assistant", "content": "Blue Whale. Quite a big fish isn't it? Oh wait, it's not a fish!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the highest mountain peak?"}, {"role": "assistant", "content": "Everest. Brace yourself, it's not a walk in the park."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who invented the telephone?"}, {"role": "assistant", "content": "A guy named Alexander Graham Bell. Bet you didn't guess that one!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the distance from Earth to the Sun?"}, {"role": "assistant", "content": "About 93 million miles. Just a quick drive, really."}]}
Chatbestandsindeling met meerdere draaiing
Meerdere beurten van een gesprek in één regel van uw jsonl-trainingsbestand worden ook ondersteund. Als u het afstemmen van specifieke assistentberichten wilt overslaan, voegt u het optionele weight sleutelwaardepaar toe. Momenteel weight kan worden ingesteld op 0 of 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Chatvoltooiingen met visie
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Naast de JSONL-indeling moeten trainings- en validatiegegevensbestanden worden gecodeerd in UTF-8 en een byte-ordermarkering (BOM) bevatten. Het bestand moet kleiner zijn dan 512 MB.
Uw trainings- en validatiegegevenssets maken
Hoe meer trainingsvoorbeelden u hebt, hoe beter. Het afstemmen van taken gaat niet verder zonder ten minste 10 trainingsvoorbeelden, maar zo'n klein aantal is niet voldoende om merkbare invloed te hebben op modelreacties. Het is raadzaam honderden, zo niet duizenden, trainingsvoorbeelden te bieden om succesvol te zijn.
Over het algemeen kan het verdubbelen van de grootte van de gegevensset leiden tot een lineaire toename van de modelkwaliteit. Maar houd er rekening mee dat voorbeelden van lage kwaliteit een negatieve invloed kunnen hebben op de prestaties. Als u het model traint op een grote hoeveelheid interne gegevens, zonder eerst de gegevensset te verwijderen voor alleen de voorbeelden van de hoogste kwaliteit, zou u kunnen eindigen met een model dat veel slechter presteert dan verwacht.
Uw trainingsgegevens uploaden
De volgende stap bestaat uit het kiezen van bestaande voorbereide trainingsgegevens of het uploaden van nieuwe voorbereide trainingsgegevens die moeten worden gebruikt bij het aanpassen van uw model. Nadat u uw trainingsgegevens hebt voorbereid, kunt u uw bestanden uploaden naar de service. Er zijn twee manieren om trainingsgegevens te uploaden:
Voor grote gegevensbestanden raden we u aan om te importeren uit een Azure Blob-archief. Grote bestanden kunnen instabiel worden wanneer ze worden geüpload via formulieren met meerdere onderdelen, omdat de aanvragen atomisch zijn en niet opnieuw kunnen worden geprobeerd of hervat. Zie Wat is Azure Blob Storage?
Opmerking
Trainingsgegevensbestanden moeten worden opgemaakt als JSONL-bestanden, gecodeerd in UTF-8 met een byte-ordermarkering (BOM). Het bestand moet kleiner zijn dan 512 MB.
In het volgende Python-voorbeeld worden lokale trainings- en validatiebestanden geüpload met behulp van de Python SDK en worden de geretourneerde bestands-id's opgehaald.
# Upload fine-tuning files
import os
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-10-21" # This API version or later is required to access seed/events/checkpoint capabilities
)
training_file_name = 'training_set.jsonl'
validation_file_name = 'validation_set.jsonl'
# Upload the training and validation dataset files to Azure OpenAI with the SDK.
training_response = client.files.create(
file=open(training_file_name, "rb"), purpose="fine-tune"
)
training_file_id = training_response.id
validation_response = client.files.create(
file=open(validation_file_name, "rb"), purpose="fine-tune"
)
validation_file_id = validation_response.id
print("Training file ID:", training_file_id)
print("Validation file ID:", validation_file_id)
Een aangepast model maken
Nadat u uw trainings- en validatiebestanden hebt geüpload, bent u klaar om de taak voor het afstemmen te starten.
In de volgende Python-code ziet u een voorbeeld van hoe u een nieuwe taak maakt met de Python SDK:
In dit voorbeeld geven we ook de seed-parameter door. Het zaad bepaalt de reproduceerbaarheid van de taak. Het doorgeven van dezelfde seed- en taakparameters moet dezelfde resultaten opleveren, maar kan in zeldzame gevallen verschillen. Als er geen seed is opgegeven, wordt er een voor u gegenereerd.
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-4.1-2025-04-14", # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
seed = 105 # seed parameter controls reproducibility of the fine-tuning job. If no seed is specified one will be generated automatically.
)
job_id = response.id
# You can use the job ID to monitor the status of the fine-tuning job.
# The fine-tuning job will take some time to start and complete.
print("Job ID:", response.id)
print("Status:", response.id)
print(response.model_dump_json(indent=2))
U kunt ook aanvullende optionele parameters, zoals hyperparameters, doorgeven om meer controle te hebben over het proces voor het afstemmen. Voor de eerste training raden we u aan de automatische standaardinstellingen te gebruiken die aanwezig zijn zonder deze parameters op te geven.
De huidige ondersteunde hyperparameters voor het afstemmen zijn:
| Naam | Typ | Beschrijving |
|---|---|---|
batch_size |
integer | De batchgrootte die moet worden gebruikt voor training. De batchgrootte is het aantal trainingsvoorbeelden dat wordt gebruikt voor het trainen van één vooruit- en achterwaartse pass. Over het algemeen hebben we vastgesteld dat grotere batchgrootten meestal beter werken voor grotere gegevenssets. De standaardwaarde en de maximumwaarde voor deze eigenschap zijn specifiek voor een basismodel. Een grotere batchgrootte betekent dat modelparameters minder vaak worden bijgewerkt, maar met een lagere variantie. |
learning_rate_multiplier |
nummer | De vermenigvuldiger van het leerpercentage die moet worden gebruikt voor training. De fijnafstemmingsleertempo is het oorspronkelijke leertempo dat wordt gebruikt voor pretraining vermenigvuldigd met deze waarde. Grotere leersnelheden presteren meestal beter met grotere batchgrootten. We raden u aan te experimenteren met waarden in het bereik 0,02 tot 0,2 om te zien wat de beste resultaten oplevert. Een kleiner leerpercentage kan nuttig zijn om overfitting te voorkomen. |
n_epochs |
integer | Het aantal tijdvakken waarvoor het model moet worden getraind. Een tijdsperiode verwijst naar één volledige cyclus door de trainingsgegevensset. |
seed |
integer | Het zaad bepaalt de reproduceerbaarheid van de taak. Het doorgeven van dezelfde seed- en taakparameters moet dezelfde resultaten opleveren, maar kan in zeldzame gevallen verschillen. Als er geen seed is opgegeven, wordt er een voor u gegenereerd. |
Aangepaste hyperparameters instellen met de 1.x-versie van de OpenAI Python-API:
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-10-21" # This API version or later is required
)
client.fine_tuning.jobs.create(
training_file="file-abc123",
model="gpt-4.1-2025-04-14", # Enter base model name. Note that in Azure OpenAI the model name contains dashes and cannot contain dot/period characters.
hyperparameters={
"n_epochs":2
}
)
Taakstatus afstemmen controleren
response = client.fine_tuning.jobs.retrieve(job_id)
print("Job ID:", response.id)
print("Status:", response.status)
print(response.model_dump_json(indent=2))
Evenementen voor fijn afstemmen weergeven
Als u de afzonderlijke afstemmingsgebeurtenissen die tijdens de training zijn gegenereerd wilt onderzoeken, moet u mogelijk uw OpenAI-clientbibliotheek upgraden naar de nieuwste versie om deze opdracht met pip install openai --upgrade uit te voeren.
response = client.fine_tuning.jobs.list_events(fine_tuning_job_id=job_id, limit=10)
print(response.model_dump_json(indent=2))
Controlepunten
Wanneer elke trainingsperiode voltooid is, wordt er een controlepunt gegenereerd. Een controlepunt is een volledig functionele versie van een model dat zowel kan worden geïmplementeerd als gebruikt als het doelmodel voor volgende taakafstemming. Controlepunten zijn met name nuttig, omdat ze momentopnamen kunnen bieden voordat overfitting optreedt. Wanneer een taak voor het afstemmen is voltooid, beschikt u over de drie meest recente versies van het model die u kunt implementeren. De laatste periode wordt vertegenwoordigd door uw nauwkeurig afgestemde model, de vorige twee epochs zijn beschikbaar als controlepunten.
U kunt de opdracht lijst controlepunten uitvoeren om de lijst met controlepunten op te halen die zijn gekoppeld aan een afzonderlijke fijnafstemmingstaak. Mogelijk moet u uw OpenAI-clientbibliotheek upgraden naar de nieuwste versie om pip install openai --upgrade deze opdracht uit te voeren.
response = client.fine_tuning.jobs.checkpoints.list(job_id)
print(response.model_dump_json(indent=2))
Uw aangepaste model analyseren
Azure OpenAI voegt een resultaatbestand met de naam results.csv toe aan elke taak voor het afstemmen nadat deze is voltooid. U kunt het resultaatbestand gebruiken om de trainings- en validatieprestaties van uw aangepaste model te analyseren. De bestands-id voor het resultaatbestand wordt vermeld voor elk aangepast model en u kunt de Python SDK gebruiken om de bestands-id op te halen en het resultaatbestand voor analyse te downloaden.
In het volgende Python-voorbeeld wordt de bestands-id opgehaald van het eerste resultaatbestand dat is gekoppeld aan de taak voor het aanpassen van uw aangepaste model. Vervolgens wordt de Python SDK gebruikt om het bestand te downloaden naar uw huidige werkmap voor analyse.
# Retrieve the file ID of the first result file from the fine-tuning job
# for the customized model.
response = client.fine_tuning.jobs.retrieve(job_id)
if response.status == 'succeeded':
result_file_id = response.result_files[0]
retrieve = client.files.retrieve(result_file_id)
# Download the result file.
print(f'Downloading result file: {result_file_id}')
with open(retrieve.filename, "wb") as file:
result = client.files.content(result_file_id).read()
file.write(result)
Het resultaatbestand is een CSV-bestand dat een veldnamenrij en een rij bevat voor elke trainingsstap die wordt uitgevoerd door de taak voor het afstemmen. Het resultaatbestand bevat de volgende kolommen:
| Kolomnaam | Beschrijving |
|---|---|
step |
Het nummer van de trainingsstap. Een trainingsstap vertegenwoordigt één pas, vooruit en achteruit, op een batch trainingsgegevens. |
train_loss |
Het verlies voor de trainingsbatch. |
train_mean_token_accuracy |
Het percentage tokens in de trainingsbatch correct voorspeld door het model. Als de batchgrootte bijvoorbeeld is ingesteld op 3 en uw gegevens voltooiingen [[1, 2], [0, 5], [4, 2]]bevatten, wordt deze waarde ingesteld op 0,83 (5 van 6) als het model is voorspeld [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
Het verlies voor de validatiebatch. |
validation_mean_token_accuracy |
Het percentage tokens in de validatiebatch correct voorspeld door het model. Als de batchgrootte bijvoorbeeld is ingesteld op 3 en uw gegevens voltooiingen [[1, 2], [0, 5], [4, 2]]bevatten, wordt deze waarde ingesteld op 0,83 (5 van 6) als het model is voorspeld [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
Het validatieverlies dat aan het einde van elk tijdvak wordt berekend. Wanneer de training goed gaat, moet verlies afnemen. |
full_valid_mean_token_accuracy |
De geldige gemiddelde tokennauwkeurigheid die aan het einde van elk tijdvak wordt berekend. Wanneer de training goed gaat, moet de nauwkeurigheid van tokens toenemen. |
U kunt de gegevens in uw results.csv-bestand ook weergeven als plots in de Azure AI Foundry-portal. Selecteer de koppeling voor uw getrainde model en u ziet drie grafieken: verlies, gemiddelde tokennauwkeurigheid en tokennauwkeurigheid. Als u validatiegegevens hebt opgegeven, worden beide gegevenssets weergegeven op dezelfde plot.
Zoek naar uw verlies om in de loop van de tijd te verminderen en uw nauwkeurigheid om te verhogen. Als u een verschil ziet tussen uw training en validatiegegevens die erop kunnen wijzen dat u overfitting gebruikt. Probeer training met minder tijdvakken of een kleinere vermenigvuldiging van leersnelheid.
Een nauwkeurig afgestemd model implementeren
Zodra u tevreden bent met de metrieken van uw fijn-afstemmingsproces, of als u alleen wilt overgaan tot voorspelling, moet u het model implementeren.
Als u implementeert voor verdere validatie, kunt u overwegen om te implementeren voor testen met behulp van een ontwikkelaarsimplementatie.
In tegenstelling tot de vorige SDK-opdrachten moet de implementatie worden uitgevoerd met behulp van de besturingsvlak-API waarvoor afzonderlijke autorisatie, een ander API-pad en een andere API-versie is vereist.
| veranderlijk | Definitie |
|---|---|
| token | Er zijn meerdere manieren om een autorisatietoken te genereren. De eenvoudigste methode voor eerste tests is het starten van Cloud Shell vanuit Azure Portal. Voer vervolgens az account get-access-tokenuit. U kunt dit token gebruiken als uw tijdelijke autorisatietoken voor API-tests. We raden u aan dit op te slaan in een nieuwe omgevingsvariabele. |
| abonnement | De abonnements-id voor de bijbehorende Azure OpenAI-resource. |
| resourcegroep | De naam van de resourcegroep voor uw Azure OpenAI-resource. |
| bron_naam | De naam van de Azure OpenAI-resource. |
| modelinzetnaam | De aangepaste naam voor de nieuwe uitrol van je fijn afgestelde model. Dit is de naam waarnaar wordt verwezen in uw code bij het maken van chat-voltooiingsgesprekken. |
| fijn-afgesteld model | Haal deze waarde op uit je verfijningstaakresultaten in de vorige stap. Het zal eruitzien als gpt-4.1-2025-04-14.ft-b044a9d3cf9c4228b5d393567f693b83. U moet die waarde toevoegen aan de deploy_data json. Als alternatief kunt u ook een controlepunt implementeren door de controlepunt-id door te geven die in het formaat ftchkpt-e559c011ecc04fc68eaa339d8227d02d verschijnt. |
import json
import os
import requests
token= os.getenv("<TOKEN>")
subscription = "<YOUR_SUBSCRIPTION_ID>"
resource_group = "<YOUR_RESOURCE_GROUP_NAME>"
resource_name = "<YOUR_AZURE_OPENAI_RESOURCE_NAME>"
model_deployment_name ="gpt-41-ft" # custom deployment name that you will use to reference the model when making inference calls.
deploy_params = {'api-version': "2024-10-01"} # control plane API version rather than dataplane API for this call
deploy_headers = {'Authorization': 'Bearer {}'.format(token), 'Content-Type': 'application/json'}
deploy_data = {
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": <"fine_tuned_model">, #retrieve this value from the previous call, it will look like gpt-4.1-2025-04-14.ft-b044a9d3cf9c4228b5d393567f693b83
"version": "1"
}
}
}
deploy_data = json.dumps(deploy_data)
request_url = f'https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}'
print('Creating a new deployment...')
r = requests.put(request_url, params=deploy_params, headers=deploy_headers, data=deploy_data)
print(r)
print(r.reason)
print(r.json())
Meer informatie over implementatie tussen regio's en het geïmplementeerde model hier gebruiken.
Als u klaar bent om te implementeren voor productie of als u specifieke gegevenslocatiebehoeften hebt, volgt u onze implementatiehandleiding.
Continue afstemming
Zodra u een nauwkeurig afgestemd model hebt gemaakt, wilt u het model misschien na verloop van tijd verder verfijnen door verder af te stemmen. Continue afstemming is het iteratieve proces van het selecteren van een al afgestemd model als basismodel en het verder afstemmen op nieuwe sets trainingsvoorbeelden.
Als u een model wilt verfijnen dat u eerder hebt afgestemd, zou u hetzelfde proces gebruiken als beschreven in het maken van een aangepast model , maar in plaats van de naam van een algemeen basismodel op te geven, geeft u de id van het reeds afgestemde model op. De aangepaste model-id ziet er als volgt uit gpt-4.1-2025-04-14.ft-5fd1918ee65d4cd38a5dcf6835066ed7
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
api_key=os.getenv("AZURE_OPENAI_API_KEY"),
api_version="2024-10-21"
)
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-4.1-2025-04-14.ft-5fd1918ee65d4cd38a5dcf6835066ed7"
)
job_id = response.id
# You can use the job ID to monitor the status of the fine-tuning job.
# The fine-tuning job will take some time to start and complete.
print("Job ID:", response.id)
print("Status:", response.id)
print(response.model_dump_json(indent=2))
We raden u ook aan de suffix parameter op te geven om onderscheid te maken tussen verschillende iteraties van uw nauwkeurig afgestemde model.
suffix neemt een tekenreeks en wordt ingesteld om het nauwkeurig afgestemde model te identificeren. Met de OpenAI Python-API wordt een tekenreeks van maximaal 18 tekens ondersteund die wordt toegevoegd aan de aangepaste modelnaam.
Als u niet zeker weet wat de id van uw bestaande nauwkeurig afgestemde model is, kunt u deze informatie vinden op de pagina Modellen van Azure AI Foundry of u kunt een lijst met modellen genereren voor een bepaalde Azure OpenAI-resource met behulp van de REST API.
Uw implementaties, aangepaste modellen en trainingsbestanden opschonen
Wanneer u klaar bent met uw aangepaste model, kunt u de implementatie en het model verwijderen. U kunt ook de trainings- en validatiebestanden verwijderen die u naar de service hebt geüpload, indien nodig.
Uw modelimplementatie verwijderen
Belangrijk
Nadat u een aangepast model hebt geïmplementeerd, wordt de implementatie verwijderd als de implementatie langer dan vijftien (15) dagen inactief blijft. De uitrol van een aangepast model is inactief als het model meer dan vijftien (15) dagen geleden is uitgerold en er tijdens een aaneengesloten periode van 15 dagen geen voltooiingsoproepen of chatvoltooiingsoproepen zijn gedaan.
Het verwijderen van een inactieve implementatie is niet van invloed op het onderliggende aangepaste model en het aangepaste model kan op elk gewenst moment opnieuw worden geïmplementeerd. Zoals beschreven in Prijzen van Azure OpenAI in Azure AI Foundry Models brengt elk aangepast (fijn afgestemd) model dat wordt geïmplementeerd, een uurlijkse hostingkost met zich mee, ongeacht of er aanvragen voor voltooien of chatvoltooien naar het model worden gedaan. Raadpleeg de richtlijnen in Plan voor het beheren van kosten voor Azure OpenAI voor meer informatie over het plannen en beheren van kosten voor Azure OpenAI.
U kunt verschillende methoden gebruiken om de implementatie voor uw aangepaste model te verwijderen:
Uw aangepaste model verwijderen
Op dezelfde manier kunt u verschillende methoden gebruiken om uw aangepaste model te verwijderen:
Opmerking
U kunt een aangepast model niet verwijderen als het een bestaande implementatie heeft. U moet eerst uw modelimplementatie verwijderen voordat u het aangepaste model kunt verwijderen.
Uw trainingsbestanden verwijderen
U kunt eventueel trainings- en validatiebestanden verwijderen die u hebt geüpload voor training, en resultaatbestanden die tijdens de training zijn gegenereerd, uit uw Azure OpenAI-abonnement. U kunt de volgende methoden gebruiken om uw trainings-, validatie- en resultaatbestanden te verwijderen:
- Azure AI Foundry
- De REST API's
- De Python-SDK
In het volgende Python-voorbeeld wordt de Python SDK gebruikt om de trainings-, validatie- en resultaatbestanden voor uw aangepaste model te verwijderen:
print('Checking for existing uploaded files.')
results = []
# Get the complete list of uploaded files in our subscription.
files = openai.File.list().data
print(f'Found {len(files)} total uploaded files in the subscription.')
# Enumerate all uploaded files, extracting the file IDs for the
# files with file names that match your training dataset file and
# validation dataset file names.
for item in files:
if item["filename"] in [training_file_name, validation_file_name, result_file_name]:
results.append(item["id"])
print(f'Found {len(results)} already uploaded files that match our files')
# Enumerate the file IDs for our files and delete each file.
print(f'Deleting already uploaded files.')
for id in results:
openai.File.delete(sid = id)
Vereiste voorwaarden
- Lees de handleiding Wanneer u Azure OpenAI-afstemming gebruikt.
- Een Azure-abonnement. Maak gratis een account.
- Een Azure OpenAI-resource. Zie Een resource maken en een model implementeren met Azure OpenAI voor meer informatie.
- Voor het afstemmen van de toegang is Cognitive Services OpenAI-inzender vereist.
- Als u nog geen toegang hebt om quota weer te geven en modellen implementeert in de Azure AI Foundry-portal, hebt u aanvullende machtigingen nodig.
Opmerking
De REST API biedt momenteel geen ondersteuning voor globale trainingstaken. Het inspecteren van globale trainingstaken via de API kan onjuiste informatie retourneren.
Ondersteunde modellen
Raadpleeg de modellenpagina om te controleren welke regio's momenteel ondersteuning bieden voor afstemming.
U kunt ook een eerder afgestemd model verfijnen, opgemaakt als base-model.ft-{jobid}.
De werkstroom voor de REST API controleren
Neem even de tijd om de werkstroom voor het afstemmen van de REST API's en Python te bekijken met Azure OpenAI:
- Bereid uw training en validatiegegevens voor.
- Selecteer een basismodel.
- Upload uw trainingsgegevens.
- Train uw nieuwe aangepaste model.
- Controleer de status van uw aangepaste model.
- Implementeer uw aangepaste model voor gebruik.
- Gebruik uw aangepaste model.
- Analyseer eventueel uw aangepaste model voor prestaties en fit.
Uw training en validatiegegevens voorbereiden
Uw trainingsgegevens en validatiegegevenssets bestaan uit voorbeelden van invoer en uitvoer voor hoe u het model wilt laten presteren.
De trainings- en validatiegegevens die u gebruikt , moeten worden opgemaakt als een JSON Lines-document (JSONL) en moeten worden opgemaakt in de gespreksindeling die wordt gebruikt door de API voor voltooiing van chats.
Als u een stapsgewijze procedure voor het afstemmen wilt, gpt-4o-mini-2024-07-18 raadpleegt u de zelfstudie over het afstemmen van Azure OpenAI.
Voorbeeld van bestandsindeling
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who discovered Antarctica?"}, {"role": "assistant", "content": "Some chaps named Fabian Gottlieb von Bellingshausen and Mikhail Lazarev, as if they don't teach that in every school!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the biggest ocean?"}, {"role": "assistant", "content": "The Pacific Ocean. It's not like it's a small pond or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest planet?"}, {"role": "assistant", "content": "It's called Jupiter, you might have heard of it...or not."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who painted the Mona Lisa?"}, {"role": "assistant", "content": "Oh, some obscure artist named Leonardo da Vinci. Not that he is famous or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the boiling point of water?"}, {"role": "assistant", "content": "Exciting fact of the day: it's 100 degrees Celsius. Life-changing, isn't it?"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'The Odyssey'?"}, {"role": "assistant", "content": "Oh, just some poet named Homer. Nothing special, really."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest mammal?"}, {"role": "assistant", "content": "Blue Whale. Quite a big fish isn't it? Oh wait, it's not a fish!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the highest mountain peak?"}, {"role": "assistant", "content": "Everest. Brace yourself, it's not a walk in the park."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who invented the telephone?"}, {"role": "assistant", "content": "A guy named Alexander Graham Bell. Bet you didn't guess that one!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the distance from Earth to the Sun?"}, {"role": "assistant", "content": "About 93 million miles. Just a quick drive, really."}]}
Chatbestandsindeling met meerdere draaiing
Meerdere beurten van een gesprek in één regel van uw jsonl-trainingsbestand worden ook ondersteund. Als u het afstemmen van specifieke assistentberichten wilt overslaan, voegt u het optionele weight sleutelwaardepaar toe. Momenteel weight kan worden ingesteld op 0 of 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Chatvoltooiingen met visie
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Naast de JSONL-indeling moeten trainings- en validatiegegevensbestanden worden gecodeerd in UTF-8 en een byte-ordermarkering (BOM) bevatten. Het bestand moet kleiner zijn dan 512 MB.
Uw trainings- en validatiegegevenssets maken
Hoe meer trainingsvoorbeelden u hebt, hoe beter. Het afstemmen van taken gaat niet verder zonder ten minste 10 trainingsvoorbeelden, maar zo'n klein aantal is niet voldoende om merkbare invloed te hebben op modelreacties. Het is raadzaam honderden, zo niet duizenden, trainingsvoorbeelden te bieden om succesvol te zijn.
Over het algemeen kan het verdubbelen van de grootte van de gegevensset leiden tot een lineaire toename van de modelkwaliteit. Maar houd er rekening mee dat voorbeelden van lage kwaliteit een negatieve invloed kunnen hebben op de prestaties. Als u het model traint op een grote hoeveelheid interne gegevens zonder eerst de gegevensset te verwijderen voor alleen de hoogste kwaliteitsvoorbeelden, kunt u eindigen met een model dat veel slechter presteert dan verwacht.
Uw trainingsgegevens uploaden
De volgende stap bestaat uit het kiezen van bestaande voorbereide trainingsgegevens of het uploaden van nieuwe voorbereide trainingsgegevens die moeten worden gebruikt bij het afstemmen van uw model. Nadat u uw trainingsgegevens hebt voorbereid, kunt u uw bestanden uploaden naar de service. Er zijn twee manieren om trainingsgegevens te uploaden:
Voor grote gegevensbestanden raden we u aan om te importeren uit een Azure Blob-archief. Grote bestanden kunnen instabiel worden wanneer ze worden geüpload via formulieren met meerdere onderdelen, omdat de aanvragen atomisch zijn en niet opnieuw kunnen worden geprobeerd of hervat. Zie Wat is Azure Blob Storage?
Opmerking
Trainingsgegevensbestanden moeten worden opgemaakt als JSONL-bestanden, gecodeerd in UTF-8 met een byte-ordermarkering (BOM). Het bestand moet kleiner zijn dan 512 MB.
Trainingsgegevens uploaden
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/files?api-version=2023-12-01-preview \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@C:\\fine-tuning\\training_set.jsonl;type=application/json"
Validatiegegevens uploaden
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/files?api-version=2023-12-01-preview \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@C:\\fine-tuning\\validation_set.jsonl;type=application/json"
Een aangepast model maken
Nadat u uw trainings- en validatiebestanden hebt geüpload, bent u klaar om de taak voor het afstemmen te starten. In de volgende code ziet u een voorbeeld van het maken van een nieuwe taak voor het afstemmen met de REST API.
In dit voorbeeld geven we ook de seed-parameter door. Het zaad bepaalt de reproduceerbaarheid van de taak. Het doorgeven van dezelfde seed- en taakparameters zou dezelfde resultaten moeten opleveren, maar kan in zeldzame gevallen toch verschillen. Als er geen seed is opgegeven, wordt er een voor u gegenereerd.
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs?api-version=2024-10-21 \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-4.1-2025-04-14",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"seed": 105
}'
U kunt ook aanvullende optionele parameters, zoals hyperparameters , doorgeven om meer controle te hebben over het proces voor het afstemmen. Voor de eerste training raden we u aan de automatische standaardinstellingen te gebruiken die aanwezig zijn zonder deze parameters op te geven.
De huidige ondersteunde hyperparameters voor het afstemmen zijn:
| Naam | Typ | Beschrijving |
|---|---|---|
batch_size |
integer | De batchgrootte die moet worden gebruikt voor training. De batchgrootte is het aantal trainingsvoorbeelden dat wordt gebruikt voor het trainen van één vooruit- en achterwaartse pass. Over het algemeen hebben we vastgesteld dat grotere batchgrootten meestal beter werken voor grotere gegevenssets. De standaardwaarde en de maximumwaarde voor deze eigenschap zijn specifiek voor een basismodel. Een grotere batchgrootte betekent dat modelparameters minder vaak worden bijgewerkt, maar met een lagere variantie. |
learning_rate_multiplier |
nummer | De vermenigvuldiger van het leerpercentage die moet worden gebruikt voor training. De fijnafstemmingsleertempo is het oorspronkelijke leertempo dat wordt gebruikt voor pretraining vermenigvuldigd met deze waarde. Grotere leersnelheden presteren meestal beter met grotere batchgrootten. We raden u aan te experimenteren met waarden in het bereik 0,02 tot 0,2 om te zien wat de beste resultaten oplevert. Een kleiner leerpercentage kan nuttig zijn om overfitting te voorkomen. |
n_epochs |
integer | Het aantal tijdvakken waarvoor het model moet worden getraind. Een tijdsperiode verwijst naar één volledige cyclus door de trainingsgegevensset. |
seed |
integer | Het zaad bepaalt de reproduceerbaarheid van de taak. Het doorgeven van dezelfde seed- en taakparameters moet dezelfde resultaten opleveren, maar kan in zeldzame gevallen verschillen. Als er geen seed is opgegeven, wordt er een voor u gegenereerd. |
De status van uw aangepaste model controleren
Nadat u een taak hebt gemaakt, kan het enige tijd duren voordat de taak is voltooid. Uw taak wordt mogelijk in de wachtrij geplaatst achter andere taken in het systeem. Het trainen van uw model kan enkele minuten of uren duren, afhankelijk van de grootte van het model en de gegevensset. In het volgende voorbeeld wordt de REST API gebruikt om de status van uw taak voor het afstemmen te controleren. In het voorbeeld wordt informatie over uw taak opgehaald met behulp van de taak-id die is geretourneerd uit het vorige voorbeeld:
curl -X GET $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/<YOUR-JOB-ID>?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY"
Evenementen voor fijn afstemmen weergeven
De afzonderlijke afstemmingsgebeurtenissen onderzoeken die zijn gegenereerd tijdens de training:
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/{fine_tuning_job_id}/events?api-version=2024-10-21 \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Controlepunten
Wanneer elke trainingsperiode voltooid is, wordt er een controlepunt gegenereerd. Een controlepunt is een volledig functionele versie van een model dat zowel kan worden geïmplementeerd als gebruikt als het doelmodel voor volgende taakafstemming. Controlepunten zijn met name nuttig, omdat ze momentopnamen kunnen bieden voordat overfitting optreedt. Wanneer een taak voor het afstemmen is voltooid, beschikt u over de drie meest recente versies van het model die u kunt implementeren. De laatste periode wordt vertegenwoordigd door uw nauwkeurig afgestemde model, de vorige twee epochs zijn beschikbaar als controlepunten.
U kunt de opdracht lijstcontrolepunten uitvoeren om de lijst met controlepunten op te halen die zijn gekoppeld aan een afzonderlijke taak voor het afstemmen van taken:
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/{fine_tuning_job_id}/checkpoints?api-version=2024-10-21 \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Uw aangepaste model analyseren
Azure OpenAI voegt een resultaatbestand met de naam results.csv toe aan elke taak voor het afstemmen nadat deze is voltooid. U kunt het resultaatbestand gebruiken om de trainings- en validatieprestaties van uw aangepaste model te analyseren. De bestands-id voor het resultaatbestand wordt vermeld voor elk aangepast model en u kunt de REST API gebruiken om de bestands-id op te halen en het resultaatbestand voor analyse te downloaden.
In het volgende Python-voorbeeld wordt de REST API gebruikt om de bestands-id op te halen van het eerste resultaatbestand dat is gekoppeld aan de taak voor het afstemmen van uw aangepaste model en downloadt het bestand vervolgens naar uw werkmap voor analyse.
curl -X GET "$AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs/<JOB_ID>?api-version=2023-12-01-preview" \
-H "api-key: $AZURE_OPENAI_API_KEY")
curl -X GET "$AZURE_OPENAI_ENDPOINT/openai/files/<RESULT_FILE_ID>/content?api-version=2023-12-01-preview" \
-H "api-key: $AZURE_OPENAI_API_KEY" > <RESULT_FILENAME>
Het resultaatbestand is een CSV-bestand dat een veldnamenrij en een rij bevat voor elke trainingsstap die wordt uitgevoerd door de taak voor het afstemmen. Het resultaatbestand bevat de volgende kolommen:
| Kolomnaam | Beschrijving |
|---|---|
step |
Het nummer van de trainingsstap. Een trainingsstap vertegenwoordigt één pas, vooruit en achteruit, op een batch trainingsgegevens. |
train_loss |
Het verlies voor de trainingsbatch. |
train_mean_token_accuracy |
Het percentage tokens in de trainingsbatch correct voorspeld door het model. Als de batchgrootte bijvoorbeeld is ingesteld op 3 en uw gegevens voltooiingen [[1, 2], [0, 5], [4, 2]]bevatten, wordt deze waarde ingesteld op 0,83 (5 van 6) als het model is voorspeld [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
Het verlies voor de validatiebatch. |
validation_mean_token_accuracy |
Het percentage tokens in de validatiebatch correct voorspeld door het model. Als de batchgrootte bijvoorbeeld is ingesteld op 3 en uw gegevens voltooiingen [[1, 2], [0, 5], [4, 2]]bevatten, wordt deze waarde ingesteld op 0,83 (5 van 6) als het model is voorspeld [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
Het validatieverlies dat aan het einde van elk tijdvak wordt berekend. Wanneer de training goed gaat, moet verlies afnemen. |
full_valid_mean_token_accuracy |
De geldige gemiddelde tokennauwkeurigheid die aan het einde van elk tijdvak wordt berekend. Wanneer de training goed gaat, moet de nauwkeurigheid van tokens toenemen. |
U kunt de gegevens in uw results.csv-bestand ook weergeven als plots in de Azure AI Foundry-portal. Selecteer de koppeling voor uw getrainde model en u ziet drie grafieken: verlies, gemiddelde tokennauwkeurigheid en tokennauwkeurigheid. Als u validatiegegevens hebt opgegeven, worden beide gegevenssets weergegeven op dezelfde plot.
Zoek naar uw verlies om in de loop van de tijd te verminderen en uw nauwkeurigheid om te verhogen. Als u een verschil ziet tussen uw trainingsgegevens en validatiegegevens die erop kunnen wijzen dat u overfitting gebruikt. Probeer training met minder tijdvakken of een kleinere vermenigvuldiging van leersnelheid.
Een nauwkeurig afgestemd model implementeren
Zodra u tevreden bent met de metrieken van uw fijn-afstemmingsproces, of als u alleen wilt overgaan tot voorspelling, moet u het model implementeren.
Als u implementeert voor verdere validatie, kunt u overwegen om te implementeren voor testen met behulp van een ontwikkelaarsimplementatie.
Als u klaar bent om te implementeren voor productie of als u specifieke gegevenslocatiebehoeften hebt, volgt u onze implementatiehandleiding.
| veranderlijk | Definitie |
|---|---|
| token | Er zijn meerdere manieren om een autorisatietoken te genereren. De eenvoudigste methode voor eerste tests is het starten van Cloud Shell vanuit Azure Portal. Voer vervolgens az account get-access-tokenuit. U kunt dit token gebruiken als uw tijdelijke autorisatietoken voor API-tests. We raden u aan dit op te slaan in een nieuwe omgevingsvariabele. |
| abonnement | De abonnements-id voor de bijbehorende Azure OpenAI-resource. |
| resourcegroep | De naam van de resourcegroep voor uw Azure OpenAI-resource. |
| bron_naam | De naam van de Azure OpenAI-resource. |
| modelinzetnaam | De aangepaste naam voor de nieuwe uitrol van je fijn afgestelde model. Dit is de naam waarnaar wordt verwezen in uw code bij het maken van chat-voltooiingsgesprekken. |
| fijn-afgesteld model | Haal deze waarde op uit je verfijningstaakresultaten in de vorige stap. Het zal eruitzien als gpt-4.1-2025-04-14.ft-b044a9d3cf9c4228b5d393567f693b83. U moet die waarde toevoegen aan de deploy_data json. Als alternatief kunt u ook een controlepunt implementeren door de controlepunt-id door te geven die in het formaat ftchkpt-e559c011ecc04fc68eaa339d8227d02d verschijnt. |
curl -X POST "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>api-version=2024-10-21" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1"
}
}
}'
Meer informatie over implementatie tussen regio's en het geïmplementeerde model hier gebruiken.
Continue afstemming
Zodra u een nauwkeurig afgestemd model hebt gemaakt, kunt u het model na verloop van tijd verder verfijnen door verder af te stemmen. Continue afstemming is het iteratieve proces van het selecteren van een al afgestemd model als basismodel en het verder afstemmen op nieuwe sets trainingsvoorbeelden.
Als u een model wilt verfijnen dat u eerder hebt afgestemd, gebruikt u hetzelfde proces als beschreven in het maken van een aangepast model , maar in plaats van de naam van een algemeen basismodel op te geven, geeft u de id van het al afgestemde model op. De aangepaste model-id ziet er als volgt uit gpt-4.1-2025-04-14.ft-5fd1918ee65d4cd38a5dcf6835066ed7
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs?api-version=2023-12-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-4.1-2025-04-14.ft-5fd1918ee65d4cd38a5dcf6835066ed7",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"suffix": "<additional text used to help identify fine-tuned models>"
}'
We raden u ook aan de suffix parameter op te geven om onderscheid te maken tussen verschillende iteraties van uw nauwkeurig afgestemde model.
suffix neemt een tekenreeks en wordt ingesteld om het nauwkeurig afgestemde model te identificeren. Het achtervoegsel mag maximaal 40 tekens (a-z, A-Z, 0-9 en _) bevatten die worden toegevoegd aan de naam van het aangepaste model.
Als u niet zeker weet wat de id van uw nauwkeurig afgestemde model is, vindt u deze informatie op de pagina Modellen van Azure AI Foundry of kunt u een lijst met modellen genereren voor een bepaalde Azure OpenAI-resource met behulp van de REST API.
Uw implementaties, aangepaste modellen en trainingsbestanden opschonen
Wanneer u klaar bent met uw aangepaste model, kunt u de implementatie en het model verwijderen. U kunt ook de trainings- en validatiebestanden verwijderen die u naar de service hebt geüpload, indien nodig.
Uw modelimplementatie verwijderen
U kunt verschillende methoden gebruiken om de implementatie voor uw aangepaste model te verwijderen:
Uw aangepaste model verwijderen
Op dezelfde manier kunt u verschillende methoden gebruiken om uw aangepaste model te verwijderen:
Opmerking
U kunt een aangepast model niet verwijderen als het een bestaande implementatie heeft. U moet eerst uw modelimplementatie verwijderen voordat u het aangepaste model kunt verwijderen.
Uw trainingsbestanden verwijderen
U kunt eventueel trainings- en validatiebestanden verwijderen die u hebt geüpload voor training, en resultaatbestanden die tijdens de training zijn gegenereerd, uit uw Azure OpenAI-abonnement. U kunt de volgende methoden gebruiken om uw trainings-, validatie- en resultaatbestanden te verwijderen:
Volgende stappen
- Verken de mogelijkheden voor het afstemmen van de Azure OpenAI in de zelfstudie voor het verfijnen van Azure OpenAI.
- De regionale beschikbaarheid van het model controleren
- Meer informatie over Azure OpenAI-quota